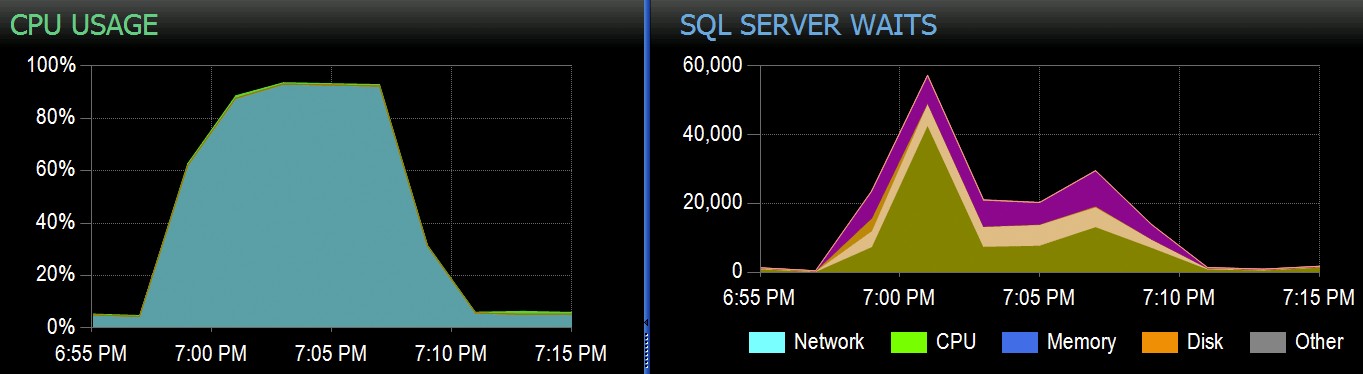
En Stack Overflow, tenemos algunas tablas que usan índices de almacén de columnas agrupados, y estos funcionan muy bien para la mayoría de nuestra carga de trabajo. Pero recientemente nos encontramos con una situación en la que las "tormentas perfectas" (múltiples procesos que intentaban eliminar del mismo CCI) abrumaban a la CPU, ya que todos iban en paralelo y luchaban para completar su operación. Así es como se veía en SolarWinds SQL Sentry:
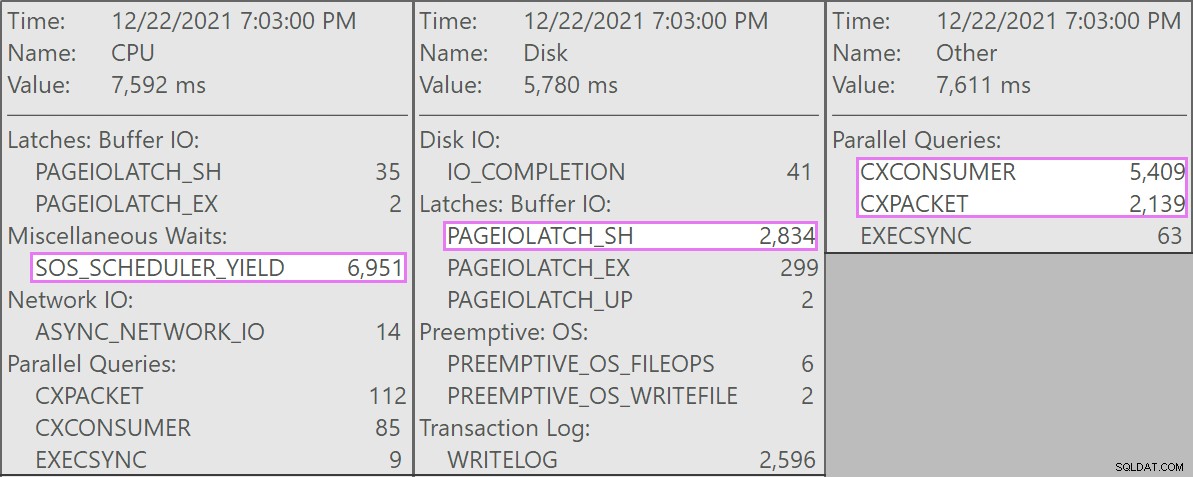
Y aquí están las esperas interesantes asociadas con estas consultas:
Las consultas que competían eran todas de esta forma:
DELETE dbo.LargeColumnstoreTable WHERE col1 = @p1 AND col2 = @p2;
El plan se veía así:

Y la advertencia en el escaneo nos avisó de algunas E/S residuales bastante extremas:

La tabla tiene 1900 millones de filas, pero solo tiene 32 GB (¡gracias, almacenamiento en columnas!). Aún así, estas eliminaciones de una sola fila tomarían entre 10 y 15 segundos cada una, y la mayor parte de este tiempo se dedicaría a SOS_SCHEDULER_YIELD .
Afortunadamente, dado que en este escenario la operación de eliminación podría ser asíncrona, pudimos resolver el problema con dos cambios (aunque aquí estoy simplificando demasiado):
- Limitamos
MAXDOPen el nivel de la base de datos, por lo que estas eliminaciones no pueden ir tan paralelas - Mejoramos la serialización de los procesos provenientes de la aplicación (básicamente, pusimos en cola las eliminaciones a través de un solo despachador)
Como DBA, podemos controlar fácilmente MAXDOP , a menos que se anule en el nivel de consulta (otra madriguera para otro día). No necesariamente podemos controlar la aplicación hasta este punto, especialmente si se distribuye o no es nuestra. ¿Cómo podemos serializar las escrituras en este caso sin cambiar drásticamente la lógica de la aplicación?
Una configuración simulada
No voy a intentar crear una tabla de dos mil millones de filas localmente, no importa la tabla exacta, pero podemos aproximarnos a algo en una escala más pequeña e intentar reproducir el mismo problema.
Supongamos que estas son las SuggestedEdits mesa (en realidad, no lo es). Pero es un ejemplo fácil de usar porque podemos extraer el esquema del Explorador de datos de Stack Exchange. Usando esto como base, podemos crear una tabla equivalente (con algunos cambios menores para que sea más fácil de completar) y agregarle un índice de almacén de columnas agrupado:
CREATE TABLE dbo.FakeSuggestedEdits ( Id int IDENTITY(1,1), PostId int NOT NULL DEFAULT CONVERT(int, ABS(CHECKSUM(NEWID()))) % 200, CreationDate datetime2 NOT NULL DEFAULT sysdatetime(), ApprovalDate datetime2 NOT NULL DEFAULT sysdatetime(), RejectionDate datetime2 NULL, OwnerUserId int NOT NULL DEFAULT 7, Comment nvarchar (800) NOT NULL DEFAULT NEWID(), Text nvarchar (max) NOT NULL DEFAULT NEWID(), Title nvarchar (250) NOT NULL DEFAULT NEWID(), Tags nvarchar (250) NOT NULL DEFAULT NEWID(), RevisionGUID uniqueidentifier NOT NULL DEFAULT NEWSEQUENTIALID(), INDEX CCI_FSE CLUSTERED COLUMNSTORE );
Para llenarlo con 100 millones de filas, podemos cruzar unir sys.all_objects y sys.all_columns cinco veces (en mi sistema, esto producirá 2,68 millones de filas cada vez, pero YMMV):
-- 2680350 * 5 ~ 3 minutes INSERT dbo.FakeSuggestedEdits(CreationDate) SELECT TOP (10) /*(2000000) */ modify_date FROM sys.all_objects AS o CROSS JOIN sys.columns AS c; GO 5>
Luego, podemos verificar el espacio:
EXEC sys.sp_spaceused @objname = N'dbo.FakeSuggestedEdits';
Son solo 1,3 GB, pero esto debería ser suficiente:

Imitar nuestra eliminación de almacén de columnas agrupado
Aquí hay una consulta simple que coincide aproximadamente con lo que nuestra aplicación estaba haciendo en la tabla:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; DELETE dbo.FakeSuggestedEdits WHERE Id = @p1 AND OwnerUserId = @p2;
Sin embargo, el plan no es una combinación perfecta:
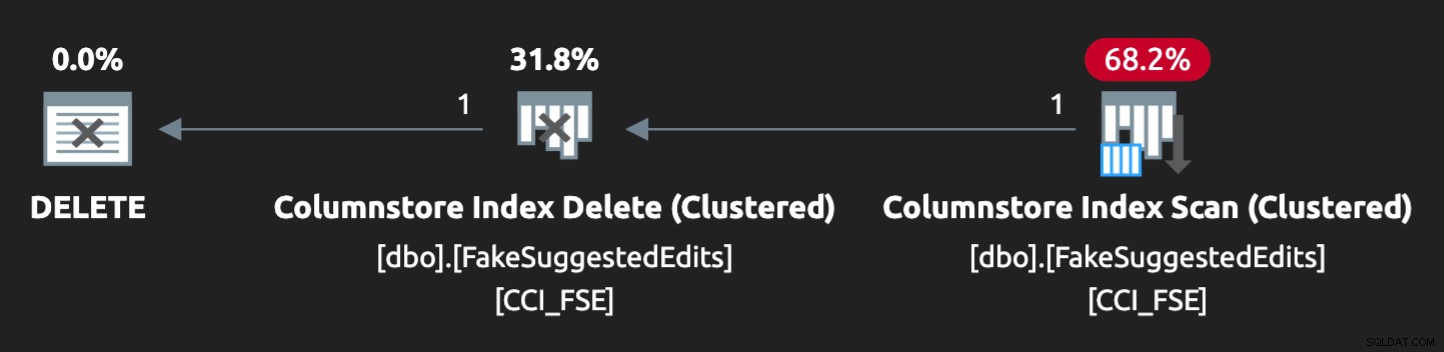
Para lograr que vaya en paralelo y produzca una contención similar en mi exigua computadora portátil, tuve que forzar un poco al optimizador con esta sugerencia:
OPTION (QUERYTRACEON 8649);
Ahora, se ve bien:

Reproduciendo el Problema
Luego, podemos crear una oleada de actividad de eliminación simultánea usando SqlStressCmd para eliminar 1000 filas aleatorias usando 16 y 32 subprocesos:
sqlstresscmd -s docs/ColumnStore.json -t 16 sqlstresscmd -s docs/ColumnStore.json -t 32
Podemos observar la tensión que esto ejerce sobre la CPU:
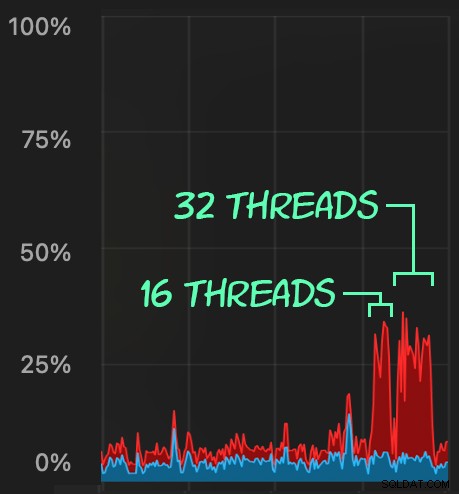
La tensión en la CPU dura a lo largo de los lotes de aproximadamente 64 y 130 segundos, respectivamente:
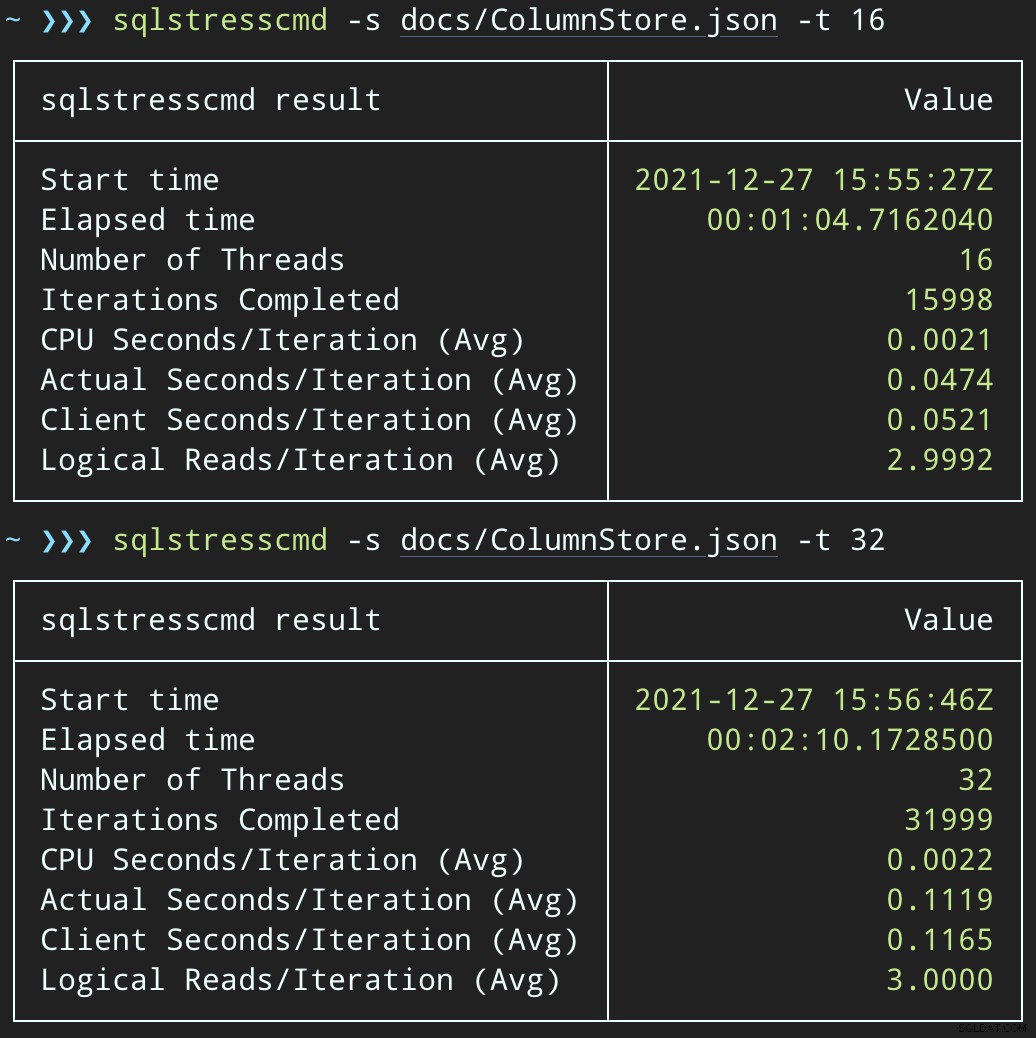
Nota:el resultado de SQLQueryStress a veces está un poco fuera de lugar en las iteraciones, pero he confirmado que el trabajo que le pides que haga se hace con precisión.
Una posible solución alternativa:una cola de eliminación
Inicialmente, pensé en introducir una tabla de cola en la base de datos, que podríamos usar para descargar la actividad de eliminación:
CREATE TABLE dbo.SuggestedEditDeleteQueue ( QueueID int IDENTITY(1,1) PRIMARY KEY, EnqueuedDate datetime2 NOT NULL DEFAULT sysdatetime(), ProcessedDate datetime2 NULL, Id int NOT NULL, OwnerUserId int NOT NULL );
Todo lo que necesitamos es un activador INSTEAD OF para interceptar estas eliminaciones no autorizadas provenientes de la aplicación y colocarlas en la cola para el procesamiento en segundo plano. Desafortunadamente, no puede crear un activador en una tabla con un índice de almacén de columnas agrupado:
Mensaje 35358, Nivel 16, Estado 1CREATE TRIGGER en la tabla 'dbo.FakeSuggestedEdits' falló porque no puede crear un desencadenador en una tabla con un índice de almacén de columnas agrupado. Considere aplicar la lógica del disparador de alguna otra manera, o si debe usar un disparador, use un índice de montón o de árbol B en su lugar.
Necesitaremos un cambio mínimo en el código de la aplicación, para que llame a un procedimiento almacenado para manejar la eliminación:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; DELETE dbo.FakeSuggestedEdits WHERE Id = @Id AND OwnerUserId = @OwnerUserId; END
Este no es un estado permanente; esto es solo para mantener el mismo comportamiento mientras cambia solo una cosa en la aplicación. Una vez que se cambia la aplicación y llama correctamente a este procedimiento almacenado en lugar de enviar consultas de eliminación ad hoc, el procedimiento almacenado puede cambiar:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; INSERT dbo.SuggestedEditDeleteQueue(Id, OwnerUserId) SELECT @Id, @OwnerUserId; END
Prueba del impacto de la cola
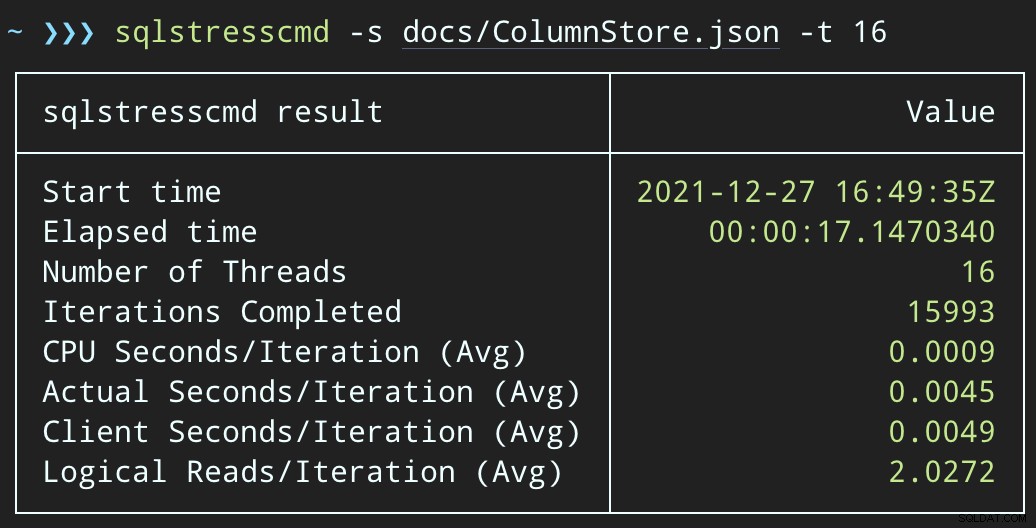
Ahora, si cambiamos SqlQueryStress para llamar al procedimiento almacenado en su lugar:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.DeleteSuggestedEdit @Id = @p1, @OwnerUserId = @p2;
Y envíe lotes similares (colocando 16 000 o 32 000 filas en la cola):
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.@Id = @p1 AND OwnerUserId = @p2;
El impacto de la CPU es ligeramente mayor:
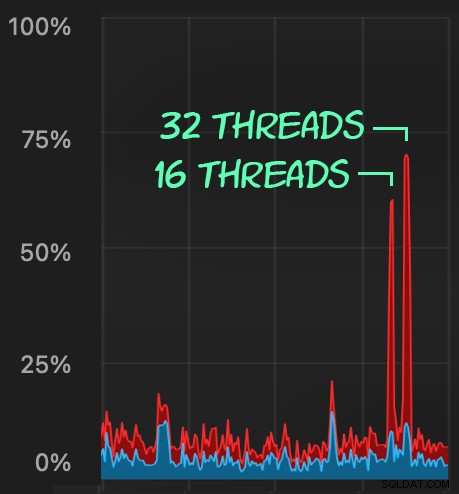
Pero las cargas de trabajo terminan mucho más rápido:16 y 23 segundos, respectivamente:
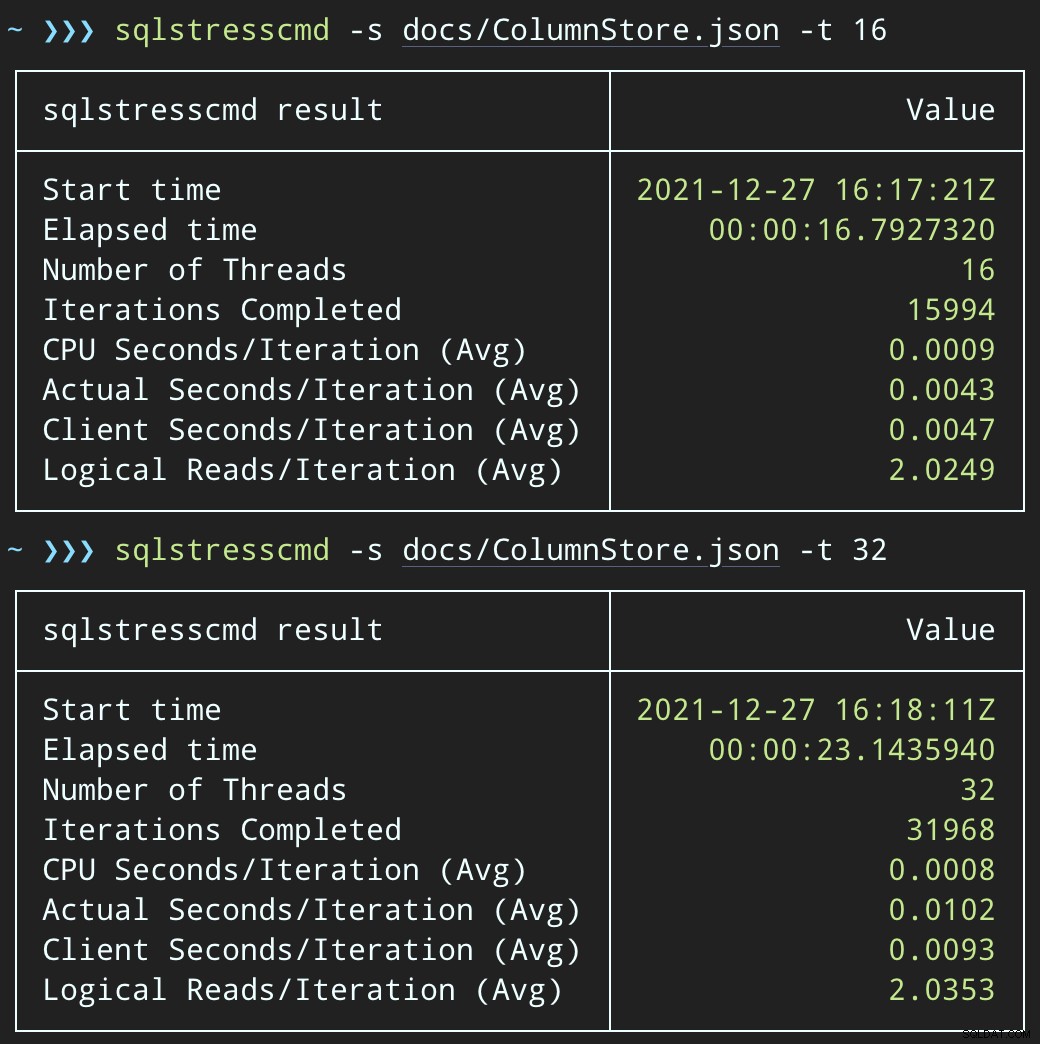
Esta es una reducción significativa en el dolor que sentirán las aplicaciones cuando entren en períodos de alta concurrencia.
Todavía tenemos que realizar la eliminación, aunque
Todavía tenemos que procesar esas eliminaciones en segundo plano, pero ahora podemos introducir el procesamiento por lotes y tener un control total sobre la tasa y cualquier retraso que queramos inyectar entre operaciones. Esta es la estructura muy básica de un procedimiento almacenado para procesar la cola (ciertamente sin control transaccional totalmente adquirido, manejo de errores o limpieza de la tabla de cola):
CREATE PROCEDURE dbo.ProcessSuggestedEditQueue
@JobSize int = 10000,
@BatchSize int = 100,
@DelayInSeconds int = 2 -- must be between 1 and 59
AS
BEGIN
SET NOCOUNT ON;
DECLARE @d TABLE(Id int, OwnerUserId int);
DECLARE @rc int = 1,
@jc int = 0,
@wf nvarchar(100) = N'WAITFOR DELAY ' + CHAR(39)
+ '00:00:' + RIGHT('0' + CONVERT(varchar(2),
@DelayInSeconds), 2) + CHAR(39);
WHILE @rc > 0 AND @jc < @JobSize
BEGIN
DELETE @d;
UPDATE TOP (@BatchSize) q SET ProcessedDate = sysdatetime()
OUTPUT inserted.Id, inserted.OwnerUserId INTO @d
FROM dbo.SuggestedEditDeleteQueue AS q WITH (UPDLOCK, READPAST)
WHERE ProcessedDate IS NULL;
SET @rc = @@ROWCOUNT;
IF @rc = 0 BREAK;
DELETE fse
FROM dbo.FakeSuggestedEdits AS fse
INNER JOIN @d AS d
ON fse.Id = d.Id
AND fse.OwnerUserId = d.OwnerUserId;
SET @jc += @rc;
IF @jc > @JobSize BREAK;
EXEC sys.sp_executesql @wf;
END
RAISERROR('Deleted %d rows.', 0, 1, @jc) WITH NOWAIT;
END Ahora, eliminar filas llevará más tiempo:el promedio de 10 000 filas es de 223 segundos, de los cuales ~100 son demoras intencionales. Pero ningún usuario está esperando, entonces, ¿a quién le importa? El perfil de la CPU es casi nulo y la aplicación puede continuar agregando elementos en la cola con tanta concurrencia como desee, casi sin conflictos con el trabajo en segundo plano. Mientras procesaba 10 000 filas, agregué otras 16 000 filas a la cola y usó la misma CPU que antes, lo que tomó solo un segundo más que cuando el trabajo no se estaba ejecutando:
Y el plan ahora se ve así, con filas estimadas/reales mucho mejores:
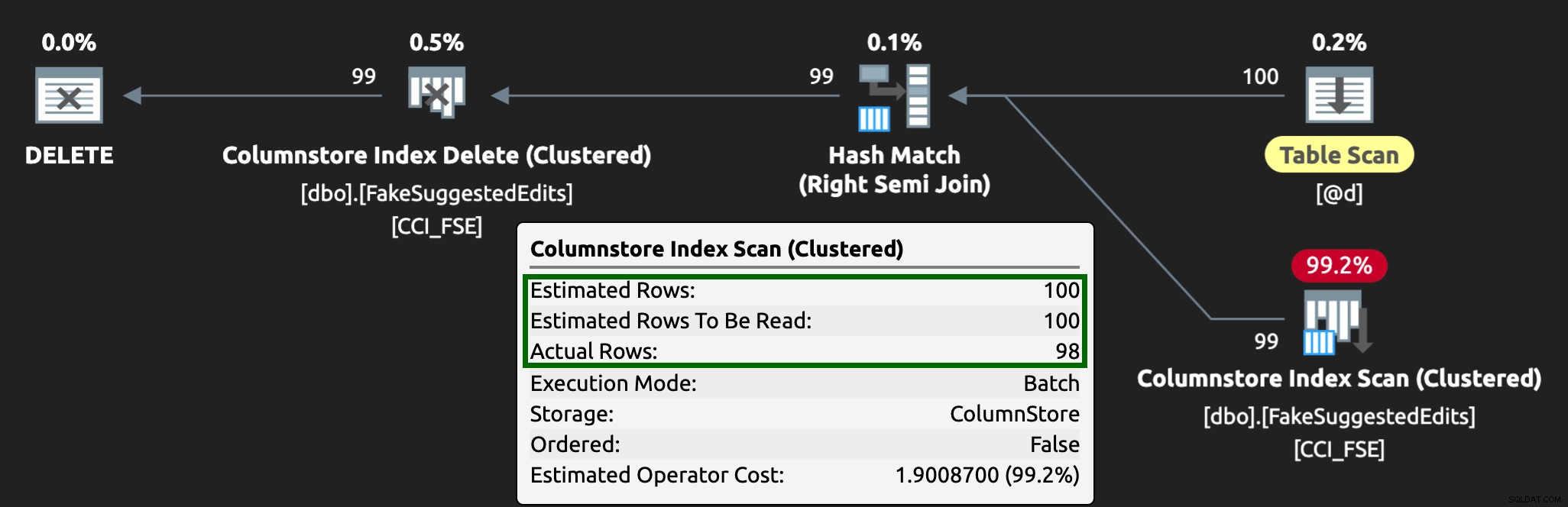
Puedo ver que este enfoque de tabla de cola es una forma efectiva de lidiar con la alta concurrencia de DML, pero requiere al menos un poco de flexibilidad con las aplicaciones que envían DML; esta es una de las razones por las que realmente me gusta que las aplicaciones llamen a procedimientos almacenados, ya que darnos mucho más control más cerca de los datos.
Otras opciones
Si no tiene la capacidad de cambiar las consultas de eliminación que provienen de la aplicación, o si no puede aplazar las eliminaciones a un proceso en segundo plano, puede considerar otras opciones para reducir el impacto de las eliminaciones:
- Un índice no agrupado en las columnas predicadas para admitir búsquedas de puntos (podemos hacer esto de forma aislada sin cambiar la aplicación)
- Usar solo eliminaciones temporales (todavía requiere cambios en la aplicación)
Será interesante ver si estas opciones ofrecen beneficios similares, pero las guardaré para una publicación futura.