SQL Server 2014 SP2 y versiones posteriores producen planes de ejecución en tiempo de ejecución ("reales") que pueden incluir tiempo transcurrido y uso de CPU para cada operador del plan de ejecución (ver KB3170113 y esta publicación de blog de Pedro Lopes).
Interpretar estos números no siempre es tan sencillo como cabría esperar. Existen diferencias importantes entre el modo fila y modo por lotes ejecución, así como problemas complicados con el modo de fila paralelismo . SQL Server hace algunos ajustes de tiempo en planes paralelos para promover la consistencia, pero no están perfectamente implementados. Esto puede dificultar la obtención de conclusiones sólidas sobre el ajuste del rendimiento.
Este artículo tiene como objetivo ayudarlo a comprender de dónde provienen los tiempos en cada caso y cómo se pueden interpretar mejor en contexto.
Configuración
Los siguientes ejemplos usan el Stack Overflow 2013 público base de datos (descargar detalles), con un solo índice agregado:
CREATE INDEX PP ON dbo.Posts (PostTypeId ASC, CreationDate ASC) INCLUDE (AcceptedAnswerId);
Las consultas de prueba devuelven el número de preguntas con respuesta aceptada, agrupadas por mes y año. Se ejecutan en SQL Server 2019 CU9 , en una computadora portátil con 8 núcleos y 16 GB de memoria asignados a la instancia de SQL Server 2019. Nivel de compatibilidad 150 es de uso exclusivo.
Ejecución en serie en modo por lotes
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
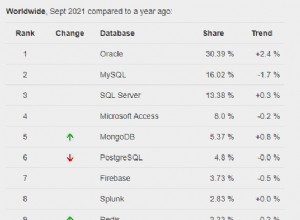
); El plan de ejecución es (haga clic para ampliar):
Todos los operadores de este plan se ejecutan en modo por lotes, gracias al modo por lotes en el almacén de filas Función de procesamiento inteligente de consultas en SQL Server 2019 (no se necesita un índice de almacén de columnas). La consulta se ejecuta durante 2523 ms con 2522 ms de tiempo de CPU utilizado, cuando todos los datos necesarios ya están en el grupo de búfer.
Como señala Pedro Lopes en la publicación de blog vinculada anteriormente, los tiempos de CPU transcurridos informados para el modo por lotes individual los operadores representan el tiempo utilizado por ese operador solo .
SSMS muestra tiempo transcurrido en la representación gráfica. Para ver los tiempos de CPU , seleccione un operador de plan, luego busque en las Propiedades ventana. Esta vista detallada muestra el tiempo transcurrido y el tiempo de CPU, por operador y por subproceso.
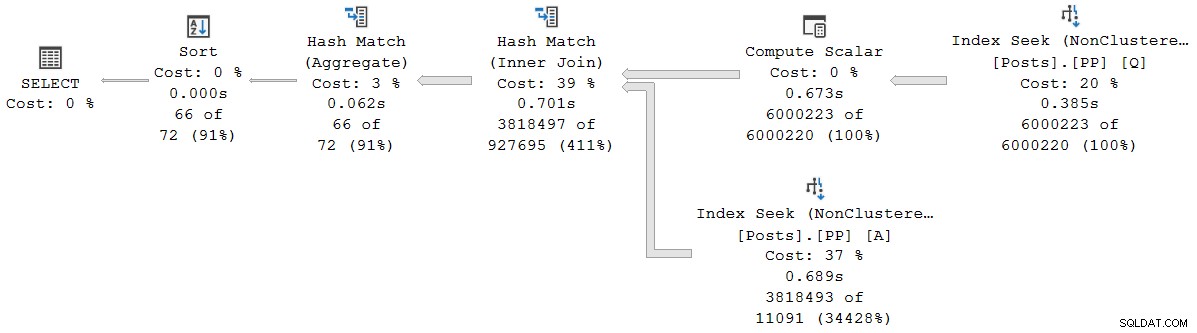
Los tiempos del plan de presentación (incluida la representación XML) están truncados a milisegundos. Si necesita mayor precisión, use el query_thread_profile evento extendido, que informa en microsegundos . El resultado de este evento para el plan de ejecución que se muestra arriba es:
Esto muestra que el tiempo transcurrido para la unión (nodo 2) es de 701 465 µs (reducido a 701 ms en el plan de presentación). El agregado tiene un tiempo transcurrido de 62,162µs (62ms). La búsqueda del índice de 'preguntas' se muestra como una ejecución de 385 ms, mientras que el evento extendido muestra que la cifra real para el nodo 4 fue de 385 938 µs (casi 386 ms).
SQL Server utiliza la alta precisión Contador de rendimiento de consultas API para capturar datos de tiempo. Esto utiliza hardware, generalmente un oscilador de cristal, que produce pulsos a una tasa constante muy alta, independientemente de la velocidad del procesador, la configuración de energía o cualquier cosa de esa naturaleza. El reloj sigue funcionando a la misma velocidad incluso durante el sueño. Consulte el artículo muy detallado vinculado si está interesado en todos los detalles más finos. El breve resumen es que puede confiar en que los números de microsegundos son precisos.
En este plan de modo por lotes puro, el tiempo total de ejecución es muy cercano a la suma de los tiempos transcurridos de los operadores individuales. La diferencia se debe en gran medida al trabajo posterior al estado de cuenta no asociado con los operadores del plan (que ya cerraron para entonces), aunque el truncamiento de milisegundos también juega un papel.
En los planes de modo por lotes puro, debe sumar manualmente los tiempos del operador actual y secundario para obtener el acumulativo tiempo transcurrido en cualquier nodo dado.
Ejecución paralela en modo por lotes
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
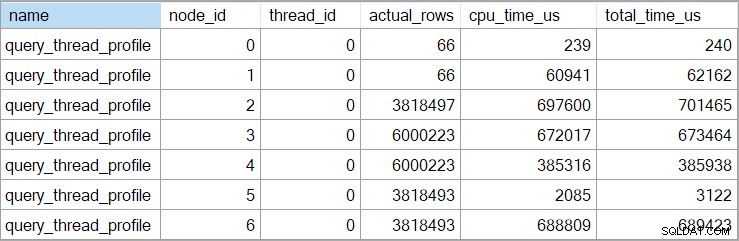
); El plan de ejecución es:
Todos los operadores, excepto el intercambio de flujo de recopilación final, se ejecutan en modo por lotes. El tiempo total transcurrido es 933 ms con 6.673ms de tiempo de CPU con caché tibia.
Seleccionar la unión hash y buscar en las Propiedades de SSMS ventana, vemos el tiempo transcurrido y el tiempo de CPU por subproceso para ese operador:
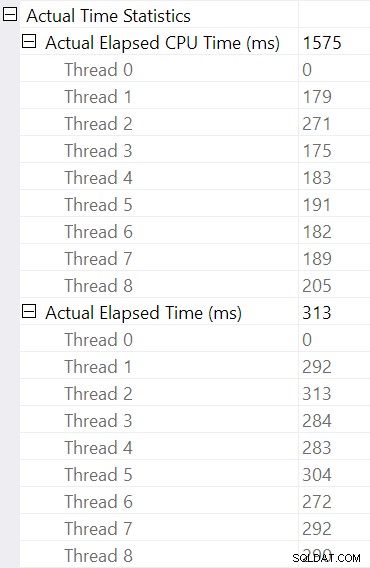
El tiempo de CPU reportado para el operador es la suma de los tiempos de CPU de subprocesos individuales. El operador informado tiempo transcurrido es el máximo de los tiempos transcurridos por subproceso. Ambos cálculos se realizan sobre los valores de milisegundos truncados por subproceso. Como antes, el tiempo total de ejecución es muy similar a la suma de los tiempos transcurridos de cada operador.
Los planes paralelos en modo por lotes no utilizan intercambios para distribuir el trabajo entre subprocesos. Los operadores por lotes se implementan para que múltiples subprocesos puedan funcionar de manera eficiente en una sola estructura compartida (por ejemplo, tabla hash). Todavía se requiere cierta sincronización entre subprocesos en planes paralelos en modo por lotes, pero los puntos de sincronización y otros detalles no son visibles en la salida del plan de presentación.
Ejecución serial en modo fila
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISALLOW_BATCH_MODE')
); El plan de ejecución es visualmente el mismo que el plan en serie del modo por lotes, pero ahora todos los operadores se ejecutan en modo de fila:
La consulta se ejecuta durante 9850 ms con 9845ms de tiempo de CPU. Esto es mucho más lento que la consulta del modo por lotes en serie (2523ms/2522ms), como se esperaba. Más importante para la presente discusión, el modo fila el tiempo transcurrido del operador y los tiempos de CPU representan el tiempo utilizado por el operador actual y todos sus hijos .
El evento extendido también muestra la CPU acumulada y los tiempos transcurridos en cada nodo (en microsegundos):
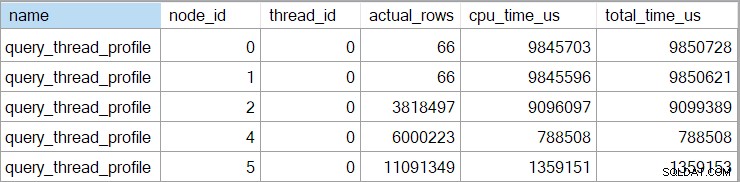
No hay datos para el operador escalar de cálculo (nodo 3) porque la ejecución del modo de fila puede diferir la mayoría de los cálculos de expresión al operador que consume el resultado. Actualmente, esto no está implementado para la ejecución en modo por lotes.
El acumulativo informado el tiempo transcurrido para los operadores de modo de fila significa que el tiempo que se muestra para el operador de clasificación final coincide con el tiempo total de ejecución de la consulta (de todos modos, con una resolución de milisegundos). El tiempo transcurrido para la combinación hash también incluye contribuciones de las dos búsquedas de índice debajo de él, así como su propio tiempo. Para calcular el tiempo transcurrido solo para la unión hash en modo fila, tendríamos que restarle ambos tiempos de búsqueda.
Hay ventajas y desventajas en ambas presentaciones (acumulativas para el modo fila, operador individual solo para el modo por lotes). Cualquiera que prefiera, es importante ser consciente de las diferencias.
Planes de modo de ejecución mixto
En general, los planes de ejecución modernos pueden contener cualquier combinación de operadores de modo por filas y por lotes. Los operadores del modo por lotes informarán los tiempos solo para ellos. Los operadores de modo fila incluirán un total acumulado hasta ese punto en el plan, incluidos todos. operadores secundarios. Para que quede claro:los tiempos acumulados de un operador en modo fila incluyen cualquier operador secundario en modo por lotes.
Vimos esto anteriormente en el plan de modo por lotes paralelo:el operador de flujos de recopilación final (modo de fila) mostró un tiempo transcurrido (acumulativo) de 0,933 s, incluidos todos sus operadores de modo por lotes secundarios. Los otros operadores estaban todos en modo por lotes, por lo que informaron los tiempos solo para el operador individual.
Esta situación, donde algunos operadores de planes en el mismo plan tienen tiempos acumulativos y otros no, sin duda se considerarán confusos por muchas personas.
Ejecución paralela en modo fila
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISALLOW_BATCH_MODE')
); El plan de ejecución es:

Cada operador está en modo fila. La consulta se ejecuta durante 4677 ms con 23 311 ms de tiempo de CPU (suma de todos los subprocesos).
Como un plan de modo exclusivamente de fila, esperaríamos que todos los tiempos fueran acumulativos . Pasando de niño a padre (de derecha a izquierda), los tiempos deberían aumentar en esa dirección.
Veamos solo la sección más a la derecha del plan:
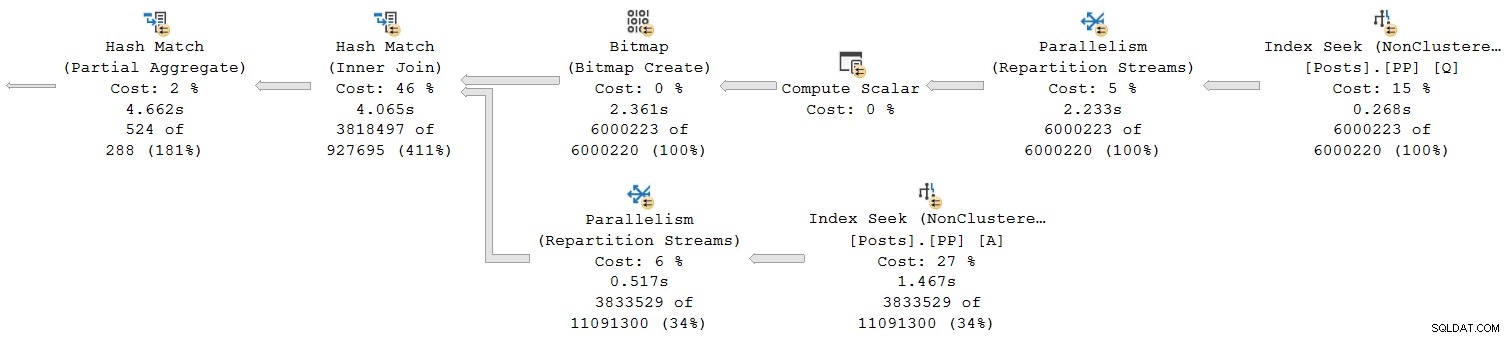
Trabajando de derecha a izquierda en la fila superior, los tiempos acumulativos ciertamente parecen ser el caso. Pero hay una excepción en la entrada inferior a la unión hash:la búsqueda de índice tiene un tiempo transcurrido de 1,467 s , mientras que su padre las secuencias de partición tienen un tiempo transcurrido de solo 0,517 s .
¿Cómo puede un padre el operador se ejecuta durante menos tiempo que su hijo si los tiempos transcurridos son acumulativos en los planes de modo fila?
Tiempos inconsistentes
Hay varias partes en la respuesta a este rompecabezas. Veámoslo pieza por pieza, porque es bastante complejo:
Primero, recuerda que un intercambio (operador de paralelismo) tiene dos partes. La mano izquierda (consumidor El lado ) está conectado a un conjunto de subprocesos que ejecutan operadores en la rama paralela a la izquierda. La mano derecha (productor ) del intercambio está conectado a un conjunto diferente de subprocesos que ejecutan operadores en la rama paralela a la derecha.
Las filas del lado del productor se ensamblan en paquetes y luego transferido al lado del consumidor. Esto proporciona un grado de amortiguación y control de flujo entre los dos conjuntos de hilos conectados. (Si necesita un repaso sobre intercambios y sucursales de planes paralelos, consulte mi artículo Planes de ejecución paralelos:sucursales y subprocesos).
El alcance de los tiempos acumulativos
Mirando la rama paralela en el productor lado del intercambio:
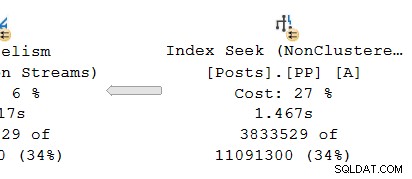
Como de costumbre, los subprocesos de trabajo adicionales DOP (grado de paralelismo) ejecutan un serial independiente copia del plan de operadores en esta sucursal. Por lo tanto, en DOP 8, hay 8 búsquedas de índice serial independientes que cooperan para realizar la parte de exploración de rango de la operación de búsqueda de índice general (paralelo). Cada búsqueda de subproceso único está conectada a una entrada diferente (puerto) en el lado del productor del único compartido operador de intercambio.
Una situación similar existe en el consumidor lado del intercambio. En DOP 8, hay 8 copias separadas de un solo subproceso de esta rama, todas ejecutándose de forma independiente:
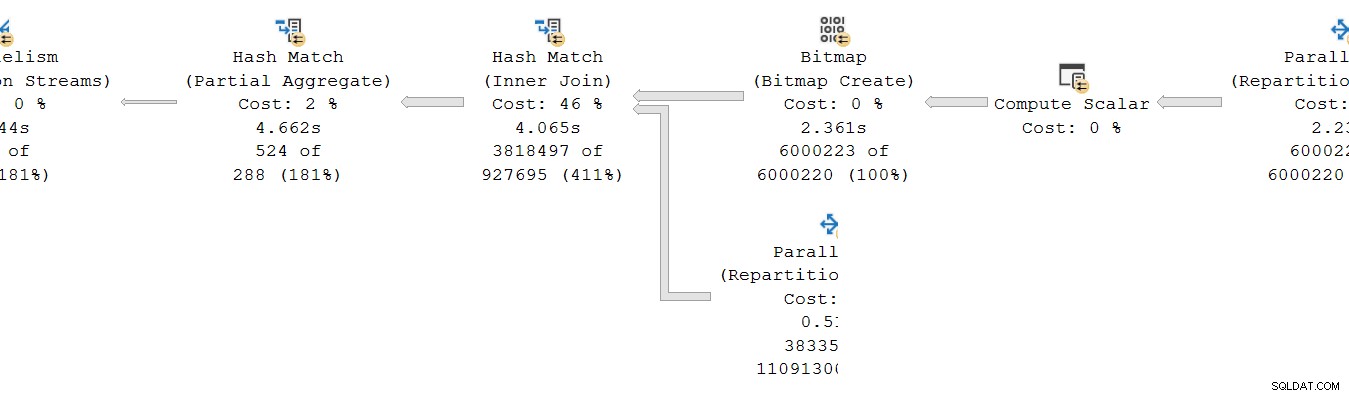
Cada uno de estos subplanes de subproceso único se ejecuta de la manera habitual, con cada operador acumulando totales de tiempo de CPU y transcurrido en cada nodo. Al ser operadores de modo fila, cada total representa el tiempo empleado en el total acumulado para el nodo actual y cada uno de sus hijos.
El punto crucial es que los totales acumulativos solo incluir operadores en el mismo hilo y solo dentro de la rama actual . Con suerte, esto tiene un sentido intuitivo, porque cada subproceso no tiene idea de lo que podría estar pasando en otro lugar.
Cómo se recopilan las métricas en modo fila
La segunda parte del rompecabezas se relaciona con la forma en que se recopilan las métricas de tiempo y el recuento de filas en los planes de modo de fila. Cuando se requiere información del plan en tiempo de ejecución ("real"), el motor de ejecución agrega un invisible operador de perfilado a la inmediata izquierda (principal) de cada operador en el plan que se ejecutará en tiempo de ejecución.
Este operador puede registrar (entre otras cosas) la diferencia entre el momento en que pasó el control a su operador secundario y el momento en que se devolvió el control. Esta diferencia de tiempo representa el tiempo transcurrido para el operador monitoreado y todos sus hijos , ya que el hijo llama a su propio hijo por fila y así sucesivamente. Se puede llamar a un operador muchas veces (para inicializar, luego una vez por fila, finalmente para cerrar), por lo que el tiempo recopilado por el operador de generación de perfiles es una acumulación. sobre potencialmente muchas iteraciones por fila.
Para más detalles sobre los datos de perfil recopilados utilizando diferentes métodos de captura, consulte la documentación del producto que cubre la Infraestructura de creación de perfiles de consultas. Para aquellos interesados en estas cosas, el nombre del operador de creación de perfiles invisible utilizado por la infraestructura estándar es sqlmin!CQScanProfileNew . Como todos los iteradores de modo fila, tiene Open , GetRow y Close métodos, entre otros. Cada método contiene llamadas al QueryPerformanceCounter de Windows. API para recopilar el valor actual del temporizador de alta resolución.
Dado que el operador de creación de perfiles está a la izquierda del operador objetivo, mide solo el consumidor lado del intercambio. No hay ningún operador de creación de perfiles para el productor lado del intercambio (lamentablemente). Si lo hubiera, coincidiría o superaría el tiempo transcurrido que se muestra en la búsqueda de índice, porque la búsqueda de índice y el lado del productor ejecutan el mismo conjunto de subprocesos y el lado del productor del intercambio es el operador principal de la búsqueda de índice.
Tiempos revisados

Con todo lo dicho, es posible que aún tenga problemas con los tiempos que se muestran arriba. ¿Cómo puede una búsqueda de índice tomar 1.467s? para pasar filas al lado del productor de un intercambio, pero el lado del consumidor solo toma 0.517 s para recibirlos? Independientemente de subprocesos separados, almacenamiento en búfer y demás, seguramente el intercambio debe durar (de extremo a extremo) más tiempo que la búsqueda?
Bueno, sí, pero esa es una medida diferente del tiempo transcurrido o de la CPU. Seamos precisos sobre lo que estamos midiendo aquí.
Para el modo fila tiempo transcurrido , imagina un cronómetro por hilo en cada operador. El cronómetro empieza cuando SQL Server ingresa el código de un operador desde su principal y detiene (pero no se reinicia) cuando ese código deja que el operador devuelva el control al padre (no al hijo). El tiempo transcurrido incluye cualquier espera o retraso en la programación, ninguno de ellos detiene el reloj.
Para el modo de fila tiempo de CPU , imagine el mismo cronómetro con las mismas características, excepto que se detiene durante las esperas y los retrasos en la programación. Solo acumula tiempo cuando el operador o uno de sus hijos está ejecutando activamente en un programador (CPU). El tiempo total en un cronómetro por subproceso por operador se construye a partir de un ciclo de inicio y parada para cada fila.
Apliquemos eso a la situación actual con el lado del consumidor del intercambio y la búsqueda del índice:
Recuerde, el lado del consumidor del intercambio y la búsqueda de índices están en ramas separadas, por lo que se ejecutan en hilos separados . El lado del consumidor no tiene hijos en el mismo hilo. La búsqueda de índice tiene el lado del productor del intercambio como su padre del mismo hilo, pero no tenemos un cronómetro allí.
Cada subproceso de consumidor inicia su reloj cuando su operador principal (el lado de la sonda de la combinación hash) pasa el control (por ejemplo, para obtener una fila). El reloj sigue funcionando mientras el consumidor recupera una fila del paquete de intercambio actual. El reloj se detiene cuando el control deja al consumidor y regresa al lado de la sonda hash join. Otros padres (el agregado parcial y su intercambio principal) también trabajarán en esa fila (y podrían esperar) antes de que el control regrese al lado del consumidor de nuestro intercambio para obtener la siguiente fila. En ese momento, el lado del consumidor de nuestro intercambio comienza a acumular el tiempo transcurrido y el tiempo de CPU nuevamente.
Mientras tanto, independientemente de lo que puedan estar haciendo los subprocesos de rama del lado del consumidor, la búsqueda de índice los subprocesos continúan ubicando filas en el índice y las alimentan en el intercambio. Un subproceso de búsqueda de índice inicia su cronómetro cuando el lado del productor del intercambio le solicita una fila. El cronómetro se detiene cuando se pasa la fila al intercambio. Cuando el intercambio solicita la siguiente fila, se reanuda el cronómetro de búsqueda de índice.
Tenga en cuenta que el lado del productor del intercambio puede experimentar CXPACKET espera a que se llenen los búferes de intercambio, pero eso no se sumará a los tiempos transcurridos registrados en la búsqueda de índice porque su cronómetro no se está ejecutando cuando eso sucede. Si tuviéramos un cronómetro para el lado del productor del intercambio, el tiempo transcurrido faltante aparecería allí.
Para aproximar un resumen de la situación visualmente, el siguiente diagrama muestra cuando cada operador acumula el tiempo transcurrido en las dos ramas paralelas:
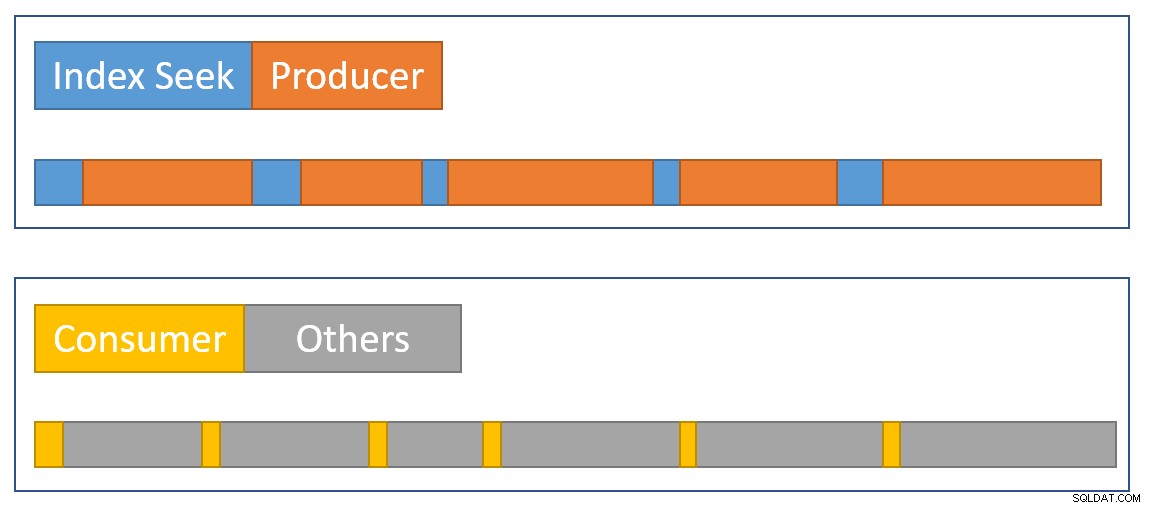
El azul las barras de tiempo de búsqueda de índice son cortas porque obtener una fila de un índice es rápido. La naranja los tiempos de producción pueden ser largos debido a CXPACKET murga. El amarillo los tiempos del consumidor son cortos porque es rápido recuperar una fila del intercambio cuando los datos están disponibles. El gris Los segmentos de tiempo representan el tiempo utilizado por los demás operadores (lado de la sonda hash join, agregado parcial y su lado del productor del intercambio principal) por encima del lado del consumidor del intercambio.
Esperamos que los paquetes de intercambio se llenen rápidamente por la búsqueda de índice, pero vaciado lentamente (en términos relativos) por parte de los operadores del lado del consumidor porque tienen más trabajo que hacer. Esto significa que los paquetes en el intercambio generalmente estarán llenos o casi llenos. El consumidor podrá recuperar rápidamente una fila de espera, pero es posible que el productor deba esperar a que aparezca el espacio del paquete.
Es una pena que no podamos ver los tiempos transcurridos en el lado del productor del intercambio. Durante mucho tiempo he sido de la opinión de que un intercambio debe estar representado por dos diferentes operadores en los planes de ejecución. Haría difícil CXPACKET /CXCONSUMER análisis de espera mucho menos necesario, y planes de ejecución mucho más fáciles de entender. El operador productor de intercambio obtendría naturalmente su propio operador de perfiles.
Diseños alternativos
Hay muchas formas en que SQL Server podría lograr acumulativos consistentes. transcurrido y tiempo de CPU en ramas paralelas en principio . En lugar de perfilar a los operadores, cada fila podría contener información sobre cuánto tiempo de CPU había transcurrido y acumulado hasta el momento en su viaje a través del plan. Con el historial asociado a cada fila, no importaría cómo los intercambios redistribuyen las filas entre hilos, etc.
No es así como se diseñó el producto, por lo que no es lo que tenemos (y podría ser ineficiente de todos modos). Para ser justos, el diseño del modo de fila original solo se ocupaba de cosas como la recopilación de recuentos de filas reales y la cantidad de iteraciones en cada operador. Agregar el tiempo transcurrido por operador a los planes fue una función muy solicitada , pero no fue fácil incorporarlo al marco existente.
Cuando se agregó el procesamiento en modo por lotes al producto, se pudo implementar un enfoque diferente (tiempo solo para el operador actual) como parte del desarrollo original sin romper nada. De nuevo, en principio , los operadores de modo fila se podrían haber modificado para funcionar de la misma manera que los operadores de modo por lotes, pero eso habría requerido una gran cantidad de trabajo de reingeniería de cada operador de modo fila existente. Agregar un nuevo punto de datos a los operadores de perfiles de modo de fila existentes fue mucho más fácil. Dados los recursos de ingeniería limitados y una larga lista de mejoras de productos deseadas, a menudo se deben hacer concesiones como esta.
El segundo problema
Otra inconsistencia de tiempo acumulativa ocurre en el plan actual en el lado izquierdo:

A primera vista, parece el mismo problema:el agregado parcial tiene un tiempo transcurrido de 4,662 s , pero el intercambio anterior solo se ejecuta durante 2,844 s . Por supuesto, están en juego las mismas mecánicas básicas que antes, pero hay otro factor importante. Una pista se encuentra en los tiempos sospechosamente iguales informados para el agregado de secuencias, la clasificación y el intercambio de particiones.
¿Recuerdas los "ajustes de tiempo" que mencioné en la introducción? Aquí es donde entran en juego. Veamos los tiempos individuales transcurridos de los subprocesos en el lado del consumidor del intercambio de flujos de partición:
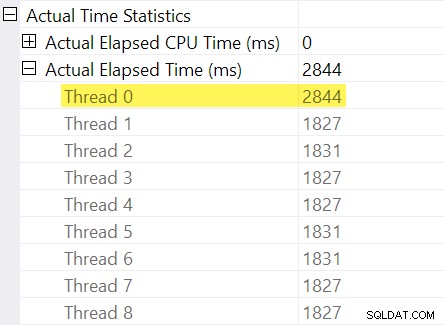
Recuerde que los planes muestran el tiempo transcurrido para un operador paralelo como el máximo de los tiempos por hilo. Los 8 subprocesos tuvieron un tiempo transcurrido de alrededor de 1830 ms, pero hay una entrada adicional para "Subproceso 0" con 2844 ms. De hecho, todos los operadores en esta rama paralela (el consumidor de intercambio, la ordenación y el agregado de flujo) tienen el mismo Contribución de 2844 ms del "Subproceso 0".
El subproceso cero (también conocido como coordinador o tarea principal) solo ejecuta operadores directamente a la izquierda del operador final de flujos de recopilación. ¿Por qué se le asigna trabajo aquí, en una rama paralela?
Explicación
Este problema puede ocurrir cuando hay un operador de bloqueo en la rama paralela a continuación (a la derecha de) el actual. Sin este ajuste, los operadores de la sucursal actual informarían menos tiempo transcurrido por la cantidad de tiempo necesario para abrir la rama secundaria (hay complicados razones arquitectónicas para esto).
SQL Server busca dar cuenta de esto registrando el retraso de la rama secundaria en el intercambio en el operador de perfilado invisible. El valor del tiempo se registra en la tarea principal ("Subproceso 0") en la diferencia entre su primer activo y último activo veces. (Puede parecer extraño registrar el número de esta manera, pero en el momento en que se debe registrar el número, los subprocesos de trabajo paralelos adicionales aún no se han creado).
En el caso actual, el ajuste de 2844 ms surge predominantemente debido al tiempo que tarda la unión hash en construir su tabla hash. (Tenga en cuenta que este tiempo es diferente del total tiempo de ejecución de la combinación hash, que incluye el tiempo necesario para procesar el lado de sondeo de la combinación).
La necesidad de un ajuste surge porque una unión hash está bloqueando su entrada de compilación. (Curiosamente, el hash agregado parcial en el plan no se considera bloqueo en este contexto porque solo se le asigna una cantidad mínima de memoria, nunca se derrama a tempdb , y simplemente deja de agregar si se queda sin memoria (volviendo así al modo de transmisión). Craig Freedman explica esto en su publicación, Agregación parcial).
Dado que el ajuste del tiempo transcurrido representa un retraso de inicialización en la rama secundaria, SQL Server debería para tratar el valor "Subproceso 0" como un desplazamiento para los números de tiempo transcurrido medidos por subproceso dentro de la rama actual. Tomando el máximo de todos los subprocesos, ya que el tiempo transcurrido es razonable en general, porque los subprocesos tienden a comenzar al mismo tiempo. no ¡tiene sentido hacer esto cuando uno de los valores del subproceso es una compensación para todos los demás valores!
Podemos hacer el cálculo de compensación correcto manualmente utilizando los datos disponibles en el plan. En el lado del consumidor del intercambio tenemos:
El tiempo máximo transcurrido entre los subprocesos de trabajo adicionales es 1831 ms (excluyendo el valor de compensación almacenado en “Thread 0”). Agregar el desplazamiento de 2844 ms da un total de 4675 ms .
En cualquier plan donde los tiempos por subproceso son menos que el desplazamiento, el operador incorrectamente mostrar el desplazamiento como el tiempo total transcurrido. Es probable que esto ocurra cuando el operador de bloqueo anterior es lento (quizás una ordenación o un agregado global sobre un gran conjunto de datos) y los operadores de rama posteriores consumen menos tiempo.
Revisando esta parte del plan:
Reemplazo del desplazamiento de 2844 ms asignado erróneamente a los operadores agregados de secuencias, clasificación y secuencias de partición con nuestros 4675 ms calculados El valor coloca sus tiempos acumulados transcurridos claramente entre los 4662 ms en el agregado parcial y los 4676 ms en los arroyos finales se reúnen. (La ordenación y el agregado operan en un pequeño número de filas, por lo que sus cálculos de tiempo transcurrido son los mismos que los de la ordenación, pero en general suelen ser diferentes):

Todos los operadores en el fragmento del plan anterior tienen 0 ms de tiempo de CPU transcurrido en todos los subprocesos (aparte del agregado parcial, que tiene 14 891 ms). Por lo tanto, el plan con nuestros números calculados tiene mucho más sentido que el que se muestra:
- 4675ms – 4662ms =13ms transcurrido es un número mucho más razonable para el tiempo consumido por las secuencias de partición solo . Este operador no consume tiempo de CPU y solo procesa 524 filas.
- 0ms transcurrido (a una resolución de milisegundos) es razonable para el pequeño agregado de ordenación y transmisión (nuevamente, excluyendo a sus hijos).
- 4676ms – 4675ms =1ms parece bueno que los flujos de recopilación finales recopilen 66 filas en el subproceso de la tarea principal para devolverlas al cliente.
Aparte de la inconsistencia obvia en el plan dado entre el agregado parcial (4662 ms) y los flujos de partición (2844 ms), no es razonable pensar que los flujos de recopilación final de 66 filas podrían ser responsables de 4676 ms – 2844 ms = 1832 ms del tiempo transcurrido. El número corregido (1 ms) es mucho más preciso y no confundirá a los sintonizadores de consultas.
Ahora, incluso si este cálculo de compensación se realizara correctamente, es posible que los planes de modo de hileras paralelas no mostrar tiempos acumulativos consistentes en todos los casos, por las razones discutidas previamente. Lograr una consistencia completa puede ser difícil, o incluso imposible, sin cambios importantes en la arquitectura.
Para anticipar una pregunta que podría surgir en este punto:No, el análisis anterior de búsqueda de intercambio e índice no involucró un error de cálculo de compensación de "Subproceso 0". No hay ningún operador de bloqueo por debajo de ese intercambio, por lo que no surge ningún retraso de inicialización.
Un último ejemplo
La siguiente consulta de ejemplo usa la misma base de datos e índice que antes. No lo exploraré con demasiado detalle porque solo sirve para ampliar los puntos que ya he mencionado, para el lector interesado.
Las características de esta demostración son:
- Sin un
ORDER GROUPSugerencia, muestra cómo un agregado parcial no se considera un operador de bloqueo, por lo que no surge ningún ajuste de "Subproceso 0" en el intercambio de flujos de partición. Los tiempos transcurridos son consistentes. - Con la sugerencia, se introducen ordenaciones de bloqueo en lugar de un agregado parcial hash. Dos diferentes Los ajustes de "Subproceso 0" aparecen en los dos intercambios de repartición. Los tiempos transcurridos son inconsistentes en ambas ramas, de diferentes maneras.
Consulta:
SELECT * FROM
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 1
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C1
JOIN
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 2
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C2
ON C2.yr = C1.yr
AND C2.mth = C1.mth
ORDER BY
C1.yr ASC,
C1.mth ASC
OPTION
(
--ORDER GROUP,
USE HINT ('DISALLOW_BATCH_MODE')
);
Plan de ejecución sin ORDER GROUP (sin ajuste, tiempos consistentes):

Plan de ejecución con ORDER GROUP (dos ajustes diferentes, tiempos inconsistentes):

Resumen y conclusiones
Informe de operadores de plan de modo de fila acumulativo times inclusive of all child operators in the same thread. Batch mode operators record the time used inside that operator alone .
A single plan can include both row and batch mode operators; the row mode operators will record cumulative elapsed time, including any batch operators. Correctly interpreting elapsed times in mixed-mode plans can be challenging.
For parallel plans, total CPU time for an operator is the sum of individual thread contributions. Total elapsed time is the maximum of the per-thread numbers.
Row mode actual plans include an invisible profiling operator to the immediate left (parent) of executing visible operators to collect runtime statistics like total row count, number of iterations, and timings. Because the row mode profiling operator is a parent of the target operator, it captures activity for that operator and all children (but only in the same thread).
Exchanges are row mode operators. There is no separate hidden profiling operator for the producer side, so exchanges only show details and timings for the consumer side . The consumer side has no children in the same thread so it reports timings for itself only.
Long elapsed times on an exchange with low CPU usage generally mean the consumer side has to wait for rows (CXCONSUMER ). This is often caused by a slow producer side (with various root causes). For an example of that with a super investigation, see CXCONSUMER As a Sign of Slow Parallel Joins by Josh Darneli.
Batch mode operators do not use separate profiling operators. The batch mode operator itself contains code to record timing on every entry and exit (e.g. per batch). Passing control to a child operator counts as an exit . This is why batch mode operators record only their own activity (exclusive of their child operators).
Internal architectural details mean the way parallel row mode plans start up would cause elapsed times to be under-reported for operators in a parallel branch when a child parallel branch contains a blocking operator. An attempt is made to adjust for the timing offset caused by this, but the implementation appears to be incomplete, resulting in inconsistent and potentially misleading elapsed times. Multiple separate adjustments may be present in a single execution plan. Adjustments may accumulate when multiple branches contain blocking operators, and a single operator may combine more than one adjustment (e.g. merge join with an adjustment on each input).
Without the attempted adjustments, parallel row-mode plans would only show consistent elapsed times within a branch (i.e. between parallelism operators). This would not be ideal, but it would arguably be better than the current situation. As it is, we simply cannot trust elapsed times in parallel row-mode plans to be a true reflection of reality.
Look out for “Thread 0” elapsed times on exchanges, and the associated branch plan operators. These will sometimes show up as implausibly identical times for operators within that branch. You may need to manually add the offset to the maximum per-thread times for each affected operator to get sensible results.
The same adjustment mechanism exists for CPU times , but it appears non-functional at the moment. Unfortunately, this means you should not expect CPU times to be cumulative across branches in row mode parallel plans. This is somewhat ironic because it does make sense to sum CPU times (including the “Thread 0” value). I doubt many people rely on cumulative CPU times in execution plans though.
With any luck, these calculations will be improved in a future product update, if the required corrective work is not too onerous.
In the meantime, this all represents another reason to prefer batch mode plans when dealing with even moderately large numbers of rows. Performance will usually be improved, and the timing numbers will make more sense. Remember, SQL Server 2019 makes batch mode processing easier to achieve in practice because it does not require a columnstore index.