Esta es la segunda parte de una serie de cinco partes que profundiza en la forma en que se inician los planes paralelos del modo de fila de SQL Server. Al final de la primera parte, habíamos creado contexto de ejecución cero para la tarea principal. Este contexto contiene el árbol completo de operadores ejecutables, pero aún no están listos para el modelo de ejecución iterativa del motor de procesamiento de consultas.
Ejecución iterativa
SQL Server ejecuta una consulta a través de un proceso conocido como análisis de consulta . La inicialización del plan comienza en la raíz mediante el procesador de consultas llamando a Open en el nodo raíz. Open las llamadas atraviesan el árbol de iteradores llamando recursivamente a Open en cada niño hasta que se abra todo el árbol.
El proceso de devolver filas de resultados también es recursivo, activado por el procesador de consultas que llama a GetRow en la raiz. Cada llamada raíz devuelve una fila a la vez. El procesador de consultas continúa llamando a GetRow en el nodo raíz hasta que no haya más filas disponibles. La ejecución se cierra con un Close recursivo final llamar. Esta disposición permite que el procesador de consultas inicialice, ejecute y cierre cualquier plan arbitrario llamando a los mismos métodos de interfaz solo en la raíz.
Para transformar el árbol de operadores ejecutables en uno adecuado para el procesamiento fila por fila, SQL Server agrega un análisis de consulta envoltura a cada operador. El análisis de consultas objeto proporciona el Open , GetRow y Close métodos necesarios para la ejecución iterativa.
El objeto de exploración de consulta también mantiene información de estado y expone otros métodos específicos del operador necesarios durante la ejecución. Por ejemplo, el objeto de exploración de consulta para un operador de filtro de inicio (CQScanStartupFilterNew ) expone los siguientes métodos:
OpenGetRowClosePrepRecomputeGetScrollLockSetMarkerGotoMarkerGotoLocationReverseDirectionDormant
Los métodos adicionales para este iterador se emplean principalmente en planes de cursor.
Inicializar el escaneo de consultas
El proceso de empaquetado se denomina inicialización del análisis de consulta . Se realiza mediante una llamada del procesador de consultas a CQueryScan::InitQScanRoot . La tarea principal realiza este proceso para el plan completo (contenido dentro del contexto de ejecución cero). El proceso de traducción es en sí mismo de naturaleza recursiva, comenzando en la raíz y avanzando hacia abajo en el árbol.
Durante este proceso, cada operador es responsable de inicializar sus propios datos y crear cualquier recurso de tiempo de ejecución necesita. Esto puede incluir la creación de objetos adicionales fuera del procesador de consultas, por ejemplo, las estructuras necesarias para comunicarse con el motor de almacenamiento para obtener datos del almacenamiento persistente.
Un recordatorio del plan de ejecución, con números de nodos agregados (haga clic para ampliar):
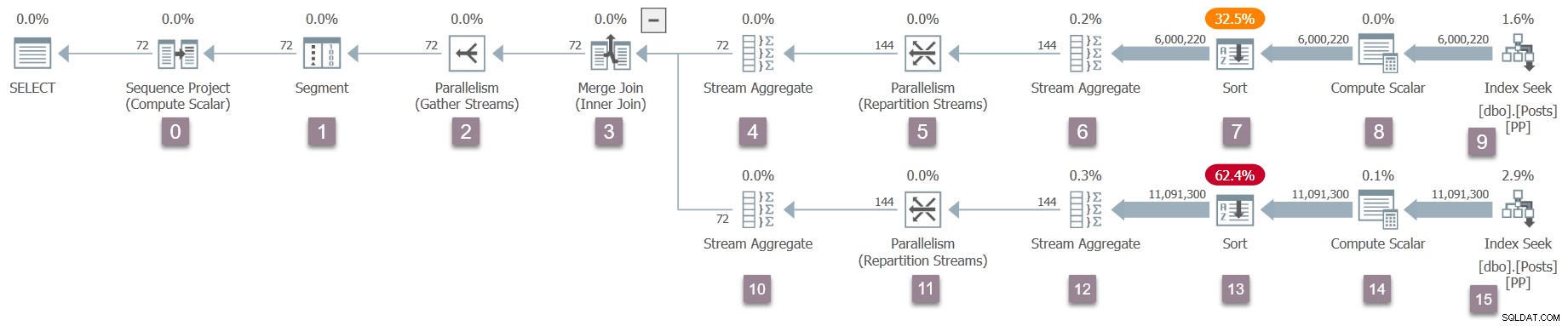
El operador en la raíz (nodo 0) del árbol del plan ejecutable es un proyecto de secuencia . Está representado por una clase llamada CXteSeqProject . Como de costumbre, aquí es donde comienza la transformación recursiva.
Envoltorios de escaneo de consultas
Como se mencionó, el CXteSeqProject el objeto no está equipado para participar en el análisis de consulta iterativo proceso — no tiene el Open requerido , GetRow y Close métodos. El procesador de consultas necesita un contenedor alrededor del operador ejecutable para proporcionar esa interfaz.
Para obtener ese contenedor de exploración de consulta, la tarea principal llama a CXteSeqProject::QScanGet para devolver un objeto de tipo CQScanSeqProjectNew . El mapa vinculado de operadores creados anteriormente se actualiza para hacer referencia al nuevo objeto de exploración de consulta, y sus métodos iteradores se conectan a la raíz del plan.
El elemento secundario del proyecto de secuencia es un segmento operador (nodo 1). Llamando a CXteSegment::QScanGet devuelve un objeto contenedor de exploración de consultas de tipo CQScanSegmentNew . El mapa vinculado se actualiza de nuevo y los punteros de función del iterador se conectan al escaneo de consulta del proyecto de secuencia principal.
Medio intercambio
El siguiente operador es un intercambio de flujos de recopilación (nodo 2). Llamando a CXteExchange::QScanGet devuelve un CQScanExchangeNew como podrías estar esperando ahora.
Este es el primer operador en el árbol que necesita realizar una inicialización adicional significativa. Crea el lado del consumidor del intercambio a través de CXTransport::CreateConsumerPart . Esto crea el puerto (CXPort ) — una estructura de datos en la memoria compartida utilizada para la sincronización y el intercambio de datos — y una tubería (CXPipe ) para el transporte de paquetes. Tenga en cuenta que el productor el lado del intercambio no se crea en este momento. ¡Solo tenemos medio intercambio!
Más envoltura
El proceso de configuración del análisis del procesador de consultas continúa con la combinación de combinación. (nodo 3). No siempre repetiré el QScanGet y CQScan* llamadas a partir de este momento, pero siguen el patrón establecido.
La unión por fusión tiene dos hijos. La configuración del análisis de consultas continúa como antes con la entrada externa (superior):un agregado de flujo (nodo 4), luego una partición transmite intercambio (nodo 5). Los flujos de partición nuevamente crean solo el lado del consumidor del intercambio, pero esta vez se crean dos conductos porque DOP es dos. El lado del consumidor de este tipo de intercambio tiene conexiones DOP con su operador principal (una por subproceso).
A continuación, tenemos otro agregado de transmisión (nodo 6) y un ordenar (nodo 7). La ordenación tiene un elemento secundario que no está visible en los planes de ejecución:un conjunto de filas del motor de almacenamiento que se usa para implementar la distribución a tempdb . El esperado CQScanSortNew por lo tanto, está acompañado por un niño CQScanRowsetNew en el árbol interno. No es visible en la salida del plan de presentación.
Perfiles de E/S y operaciones diferidas
El ordenar operador también es el primero que hemos inicializado hasta ahora que podría ser responsable de I/O . Suponiendo que la ejecución ha solicitado datos de perfiles de E/S (p. ej., solicitando un plan "real"), la ordenación crea un objeto para registrar estos datos de perfil en tiempo de ejecución. a través de CProfileInfo::AllocProfileIO .
El siguiente operador es un computación escalar (nodo 8), llamado proyecto internamente. La llamada de configuración de exploración de consultas a CXteProject::QScanGet no devolver un objeto de exploración de consulta, porque los cálculos realizados por este escalar de cómputo son diferidos al primer operador principal que necesita el resultado. En este plan, ese operador es el tipo. La ordenación hará todo el trabajo asignado al escalar de cómputo, por lo que el proyecto en el nodo 8 no forma parte del árbol de exploración de consultas. El escalar de cómputo realmente no se ejecuta en tiempo de ejecución. Para obtener más detalles sobre los escalares de cómputo diferidos, consulte Escalares de cómputo, expresiones y rendimiento del plan de ejecución.
Escaneo paralelo
El operador final después del escalar de cómputo en esta rama del plan es una búsqueda de índice (CXteRange ) en el nodo 9. Esto produce el operador de exploración de consulta esperado (CQScanRangeNew ), pero también requiere una secuencia compleja de inicializaciones para conectarse al motor de almacenamiento y facilitar un escaneo paralelo del índice.
Solo cubriendo los aspectos más destacados, inicializando la búsqueda de índice:
- Crea un objeto de creación de perfiles para E/S (
CProfileInfo::AllocProfileIO). - Crea un conjunto de filas paralelo exploración de consultas (
CQScanRowsetNew::ParallelGetRowset). - Configura una sincronización para coordinar el escaneo de rango paralelo en tiempo de ejecución (
CQScanRangeNew::GetSyncInfo). - Crea el motor de almacenamiento cursor de tabla y un descriptor de transacción de solo lectura .
- Abre el conjunto de filas principal para lectura (accediendo al HoBt y tomando los pestillos necesarios).
- Establece el tiempo de espera de bloqueo.
- Configura la búsqueda previa (incluidos los búferes de memoria asociados).
Agregar operadores de perfilado en modo fila
Ahora hemos alcanzado el nivel hoja de esta rama del plan (el índice de búsqueda no tiene hijos). Habiendo creado el objeto de exploración de consulta para la búsqueda de índice, el siguiente paso es envolver la exploración de consulta con una clase de creación de perfiles (suponiendo que solicitamos un plan real). Esto se hace mediante una llamada a sqlmin!PqsWrapQScan . Tenga en cuenta que los generadores de perfiles se agregan después de que se haya creado el análisis de consulta, a medida que comenzamos a ascender en el árbol de iteradores.
PqsWrapQScan crea un nuevo operador de generación de perfiles como principal de la búsqueda de índice, a través de una llamada a CProfileInfo::GetOrCreateProfileInfo . El operador de creación de perfiles (CQScanProfileNew ) tiene los métodos habituales de interfaz de exploración de consultas. Además de recopilar los datos necesarios para los planes reales, los datos de creación de perfiles también se exponen a través de sys.dm_exec_query_profiles del DMV. .
Consultar ese DMV en este momento preciso para la sesión actual muestra que solo existe un único operador de plan (nodo 9) (lo que significa que es el único envuelto por un generador de perfiles):

Esta captura de pantalla muestra el conjunto de resultados completo del DMV en el momento actual (no ha sido editado).
A continuación, CQScanProfileNew llama a la API del contador de rendimiento de consultas (KERNEL32!QueryPerformanceCounterStub ) proporcionada por el sistema operativo para registrar los primeros y últimos tiempos de actividad del operador perfilado:

El último tiempo activo se actualizará utilizando la API del contador de rendimiento de consultas cada vez que se ejecute el código para ese iterador.
El generador de perfiles luego establece el número estimado de filas en este punto del plan (CProfileInfo::SetCardExpectedRows ), contabilizando cualquier objetivo de fila (CXte::CardGetRowGoal ). Dado que este es un plan paralelo, divide el resultado por la cantidad de subprocesos (CXte::FGetRowGoalDefinedForOneThread ) y guarda el resultado en el contexto de ejecución.
El número estimado de filas es no visible a través del DMV en este punto, porque la tarea principal no ejecutará este operador. En su lugar, la estimación por subproceso se expondrá más adelante en contextos de ejecución paralelos (que aún no se han creado). Sin embargo, el número por subproceso se guarda en el generador de perfiles de la tarea principal, simplemente no es visible a través del DMV.
El nombre descriptivo del operador del plan ("Index Seek") se establece mediante una llamada a CXteRange::GetPhysicalOp :

Antes de eso, es posible que haya notado que al consultar el DMV mostró el nombre como "???". Este es el nombre permanente que se muestra para los operadores invisibles (por ejemplo, búsqueda previa de bucles anidados, ordenación por lotes) que no tienen un nombre descriptivo definido.
Por último, indexe los metadatos y las estadísticas de E/S actuales. para la búsqueda de índice envuelto se agregan a través de una llamada a CQScanRowsetNew::GetIoCounters :

Los contadores están en cero en este momento, pero se actualizarán a medida que la búsqueda de índice realice operaciones de E/S durante la ejecución del plan finalizado.
Más procesamiento de escaneo de consultas
Con el operador de creación de perfiles creado para la búsqueda de índice, el procesamiento de exploración de consultas retrocede en el árbol hasta el ordenador principal. (nodo 7).
La clasificación realiza las siguientes tareas de inicialización:
- Registra su uso de memoria con la consulta administrador de memoria (
CQryMemManager::RegisterMemUsage) - Calcula la memoria necesaria para la entrada de clasificación (
CQScanIndexSortNew::CbufInputMemory) y salida (CQScanSortNew::CbufOutputMemory). - La tabla de clasificación se crea, junto con su conjunto de filas de motor de almacenamiento asociado (
sqlmin!RowsetSorted). - Una transacción del sistema independiente (no limitado por la transacción del usuario) se crea para clasificar las asignaciones de disco de derrame, junto con una tabla de trabajo falsa (
sqlmin!CreateFakeWorkTable). - El servicio de expresiones se inicializa (
sqlTsEs!CEsRuntime::Startup) para que el operador de clasificación realice los cálculos diferidos del escalar de cómputo. - Recuperación previa para cualquier tipo se ejecuta en tempdb luego se crea a través de (
CPrefetchMgr::SetupPrefetch).
Finalmente, el análisis de la consulta de clasificación está envuelto por un operador de creación de perfiles (que incluye E/S) tal como vimos para la búsqueda de índice:

Observe que el escalar de cómputo (nodo 8) falta del DMV. Esto se debe a que su trabajo se difiere a la ordenación, no forma parte del árbol de análisis de consultas y, por lo tanto, no tiene un objeto generador de perfiles envolvente.
Pasando al elemento principal de la ordenación, el agregado de flujo el operador de exploración de consultas (nodo 6) inicializa sus expresiones y contadores de tiempo de ejecución (por ejemplo, el recuento de filas del grupo actual). El agregado de flujo se envuelve con un operador de perfilado, registrando sus tiempos iniciales:

La partición principal transmite intercambio (nodo 5) está envuelto por un generador de perfiles (recuerde que solo existe el lado del consumidor de este intercambio en este punto):

Se hace lo mismo para su agregado de flujo padre. (nodo 4), que también se inicializa como se describió anteriormente:

El procesamiento de exploración de consultas vuelve a la combinación de combinación principal (nodo 3) pero aún no lo inicializa. En su lugar, nos movemos hacia abajo por el lado interior (inferior) de la combinación de combinación, realizando las mismas tareas detalladas para esos operadores (nodos 10 a 15) como se hizo para la rama superior (externa):
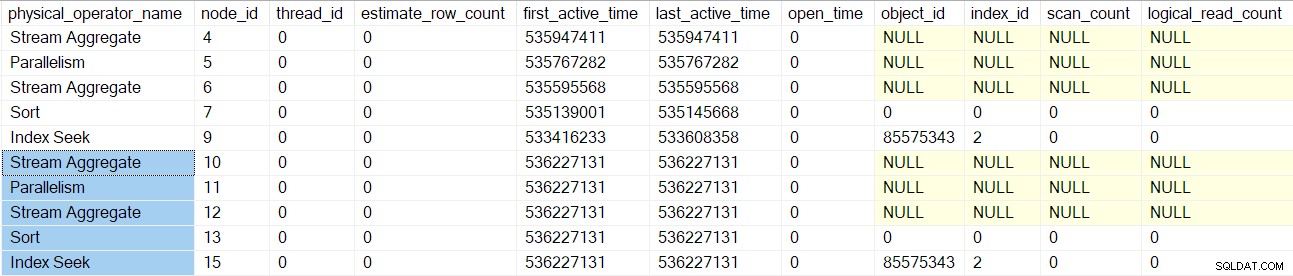
Una vez que se procesan esos operadores, la combinación de combinación el escaneo de consulta se crea, inicializa y envuelve con un objeto de generación de perfiles. Esto incluye contadores de E/S porque una combinación de combinación de muchos utiliza una tabla de trabajo (aunque la combinación de combinación actual es uno-muchos):
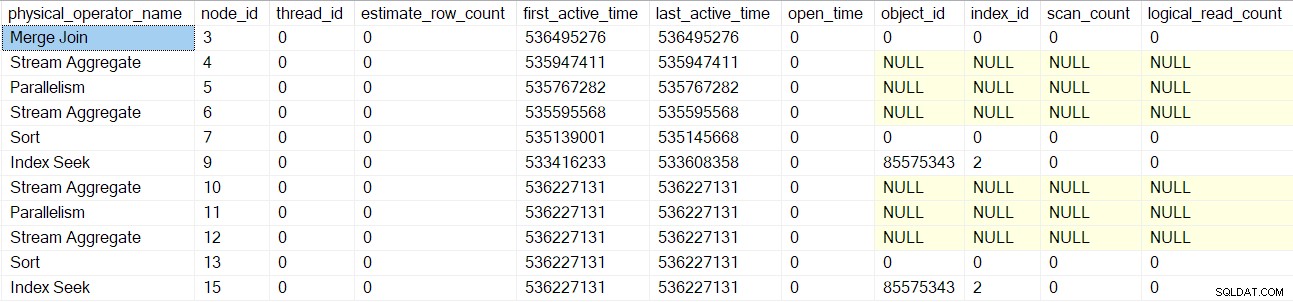
Se sigue el mismo proceso para los flujos de recopilación principales intercambio (nodo 2) solo del lado del consumidor, segmento (nodo 1) y proyecto de secuencia (nodo 0) operadores. No los describiré en detalle.
Los perfiles de consulta del DMV ahora informan un conjunto completo de nodos de análisis de consultas envueltos en el generador de perfiles:
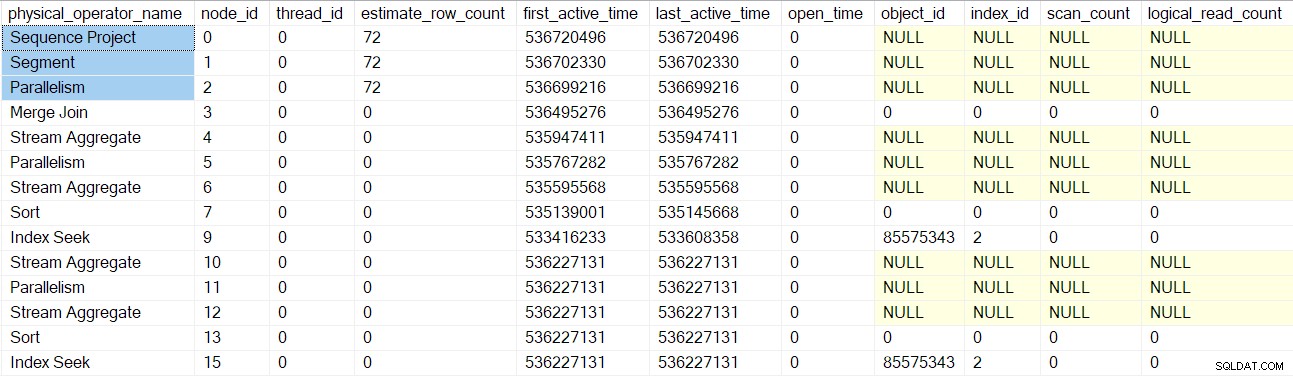
Observe que el proyecto de secuencia, el segmento y el consumidor de flujos de recopilación tienen un recuento de filas estimado porque estos operadores serán ejecutados por la tarea principal , no por tareas paralelas adicionales (ver CXte::FGetRowGoalDefinedForOneThread más temprano). La tarea principal no tiene trabajo que hacer en ramas paralelas, por lo que el concepto de recuento de filas estimado solo tiene sentido para tareas adicionales.
Los valores de tiempo activo que se muestran arriba están algo distorsionados porque necesitaba detener la ejecución y tomar capturas de pantalla del DMV en cada paso. Una ejecución separada (sin los retrasos artificiales introducidos por el uso de un depurador) produjo los siguientes tiempos:
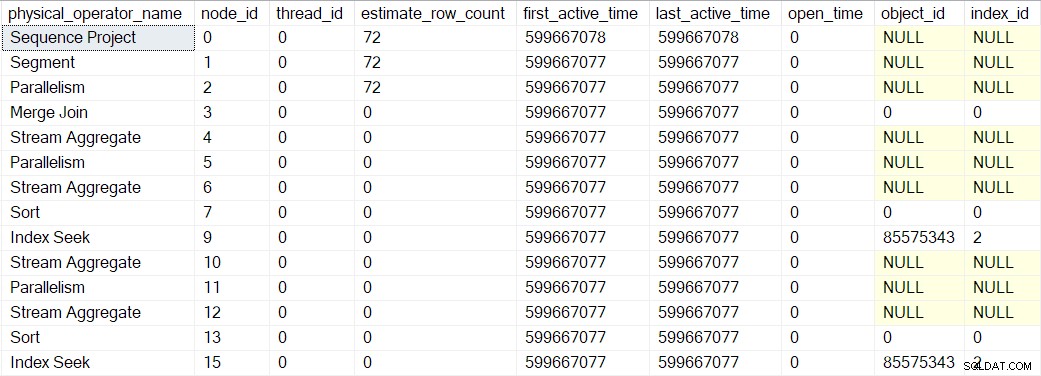
El árbol se construye en la misma secuencia descrita anteriormente, pero el proceso es tan rápido que solo hay 1 microsegundo diferencia entre el tiempo activo del primer operador envuelto (la búsqueda de índice en el nodo 9) y el último (proyecto de secuencia en el nodo 0).
Fin de la Parte 2
Puede parecer que hemos trabajado mucho, pero recuerde que solo hemos creado un árbol de exploración de consultas para la tarea principal , y los intercambios solo tienen un lado del consumidor (todavía no hay productor). Nuestro plan paralelo también solo tiene un hilo (como se muestra en la última captura de pantalla). La Parte 3 verá la creación de nuestras primeras tareas paralelas adicionales.