En la Parte 5 de mi serie sobre expresiones de tabla, proporcioné la siguiente solución para generar una serie de números utilizando CTE, un constructor de valores de tabla y uniones cruzadas:
DECLARAR @low COMO BIGINT =1001, @high COMO BIGINT =1010; CON L0 COMO ( SELECCIONE 1 COMO c DE (VALORES(1),(1)) COMO D(c) ), L1 COMO ( SELECCIONE 1 COMO c DE L0 COMO UNA CRUZ ÚNASE L0 COMO B ), L2 COMO ( SELECCIONE 1 COMO c DE L1 COMO CRUZ ÚNETE L1 COMO B ), L3 COMO ( SELECCIONA 1 COMO c DE L2 COMO CRUZ ÚNETE L2 COMO B ), L4 COMO ( SELECCIONA 1 COMO c DE L3 COMO CRUZ ÚNETE L3 COMO B ), L5 COMO ( SELECCIONE 1 COMO c DESDE L4 COMO UNA CRUZ ÚNASE A L4 COMO B ), Números COMO ( SELECCIONE ROW_NUMBER() SOBRE(ORDENAR POR (SELECCIONE NULL)) COMO número de fila DESDE L5 ) SELECCIONE SUPERIOR(@alto - @bajo + 1) @bajo + número de fila - 1 COMO nDE NumsORDER POR número de fila;
Hay muchos casos prácticos de uso para una herramienta de este tipo, incluida la generación de una serie de valores de fecha y hora, la creación de datos de muestra y más. Reconociendo la necesidad común, algunas plataformas proporcionan una herramienta integrada, como la función generate_series de PostgreSQL. Al momento de escribir este artículo, T-SQL no proporciona una herramienta integrada de este tipo, pero uno siempre puede esperar y votar para que se agregue una herramienta de este tipo en el futuro.
En un comentario a mi artículo, Marcos Kirchner mencionó que probó mi solución con diferentes cardinalidades del constructor de valores de tabla y obtuvo diferentes tiempos de ejecución para las diferentes cardinalidades.
 Siempre usé mi solución con una cardinalidad de constructor de valor de tabla base de 2, pero el comentario de Marcos me hizo pensar. Esta herramienta es tan útil que nosotros, como comunidad, deberíamos unir fuerzas para intentar crear la versión más rápida que podamos. Probar diferentes cardinalidades de la tabla base es solo una dimensión para probar. Podría haber muchos otros. Presentaré las pruebas de rendimiento que he realizado con mi solución. Principalmente experimenté con diferentes cardinalidades de constructores de valores de tabla, con procesamiento en serie frente a paralelo, y con modo de fila frente a procesamiento por lotes. Sin embargo, podría ser que una solución completamente diferente sea incluso más rápida que mi mejor versión. Entonces, ¡el desafío está en marcha! Estoy llamando a todos los jedi, padawan, magos y aprendices por igual. ¿Cuál es la solución de mejor rendimiento que puede conjurar? ¿Lo tienes dentro de ti para vencer a la solución más rápida publicada hasta ahora? Si es así, comparta el suyo como un comentario a este artículo y siéntase libre de mejorar cualquier solución publicada por otros.
Siempre usé mi solución con una cardinalidad de constructor de valor de tabla base de 2, pero el comentario de Marcos me hizo pensar. Esta herramienta es tan útil que nosotros, como comunidad, deberíamos unir fuerzas para intentar crear la versión más rápida que podamos. Probar diferentes cardinalidades de la tabla base es solo una dimensión para probar. Podría haber muchos otros. Presentaré las pruebas de rendimiento que he realizado con mi solución. Principalmente experimenté con diferentes cardinalidades de constructores de valores de tabla, con procesamiento en serie frente a paralelo, y con modo de fila frente a procesamiento por lotes. Sin embargo, podría ser que una solución completamente diferente sea incluso más rápida que mi mejor versión. Entonces, ¡el desafío está en marcha! Estoy llamando a todos los jedi, padawan, magos y aprendices por igual. ¿Cuál es la solución de mejor rendimiento que puede conjurar? ¿Lo tienes dentro de ti para vencer a la solución más rápida publicada hasta ahora? Si es así, comparta el suyo como un comentario a este artículo y siéntase libre de mejorar cualquier solución publicada por otros.
Requisitos:
- Implemente su solución como una función con valores de tabla en línea (iTVF) denominada dbo.GetNumsYourName con los parámetros @low AS BIGINT y @high AS BIGINT. Como ejemplo, vea los que envío al final de este artículo.
- Puede crear tablas de apoyo en la base de datos del usuario si es necesario.
- Puede agregar sugerencias según sea necesario.
- Como se mencionó, la solución debe admitir delimitadores del tipo BIGINT, pero puede suponer una cardinalidad de serie máxima de 4 294 967 296.
- Para evaluar el rendimiento de su solución y compararla con otras, la probaré con el rango de 1 a 100 000 000, con Descartar resultados después de la ejecución habilitado en SSMS.
¡Buena suerte a todos nosotros! Que gane la mejor comunidad.;)
Diferentes cardinalidades para el constructor de valores de la tabla base
Experimenté con cardinalidades variables del CTE base, comenzando con 2 y avanzando en una escala logarítmica, elevando al cuadrado la cardinalidad anterior en cada paso:2, 4, 16 y 256.
Antes de comenzar a experimentar con diferentes cardinalidades base, podría ser útil tener una fórmula que, dada la cardinalidad base y la cardinalidad de rango máximo, le indicara cuántos niveles de CTE necesita. Como paso preliminar, es más fácil idear primero una fórmula que, dada la cardinalidad base y la cantidad de niveles de CTE, calcule cuál es la cardinalidad máxima del rango resultante. Aquí hay una fórmula de este tipo expresada en T-SQL:
DECLARAR @basecardinality COMO INT =2, @levels COMO INT =5; SELECCIONE POTENCIA(1.*@cardinalidad base, POTENCIA(2., @niveles));
Con los valores de entrada de muestra anteriores, esta expresión produce una cardinalidad de rango máximo de 4,294,967,296.
Luego, la fórmula inversa para calcular el número de niveles de CTE necesarios implica anidar dos funciones de registro, así:
DECLARAR @basecardinality COMO INT =2, @seriescardinality COMO BIGINT =4294967296; SELECCIONE TECHO(LOG(LOG(@seriescardinality, @basecardinality), 2));
Con los valores de entrada de muestra anteriores, esta expresión produce 5. Tenga en cuenta que este número se suma al CTE base que tiene el constructor de valores de tabla, que denominé L0 (para el nivel 0) en mi solución.
No me preguntes cómo llegué a estas fórmulas. La historia a la que me atengo es que Gandalf me las pronunció en élfico en mis sueños.
Procedamos a las pruebas de rendimiento. Asegúrese de habilitar Descartar resultados después de la ejecución en el cuadro de diálogo Opciones de consulta de SSMS en Cuadrícula, Resultados. Utilice el siguiente código para ejecutar una prueba con cardinalidad CTE base de 2 (requiere 5 niveles adicionales de CTE):
DECLARAR @low COMO BIGINT =1, @high COMO BIGINT =100000000; CON L0 COMO ( SELECCIONE 1 COMO c DE (VALORES(1),(1)) COMO D(c) ), L1 COMO ( SELECCIONE 1 COMO c DE L0 COMO UNA CRUZ ÚNASE L0 COMO B ), L2 COMO ( SELECCIONE 1 COMO c DE L1 COMO CRUZ ÚNETE L1 COMO B ), L3 COMO ( SELECCIONA 1 COMO c DE L2 COMO CRUZ ÚNETE L2 COMO B ), L4 COMO ( SELECCIONA 1 COMO c DE L3 COMO CRUZ ÚNETE L3 COMO B ), L5 COMO ( SELECCIONE 1 COMO c DESDE L4 COMO UNA CRUZ ÚNASE A L4 COMO B ), Números COMO ( SELECCIONE ROW_NUMBER() SOBRE(ORDENAR POR (SELECCIONE NULL)) COMO número de fila DESDE L5 ) SELECCIONE SUPERIOR(@alto - @bajo + 1) @bajo + número de fila - 1 COMO nDE NumsORDER POR número de fila;
Obtuve el plan que se muestra en la Figura 1 para esta ejecución.
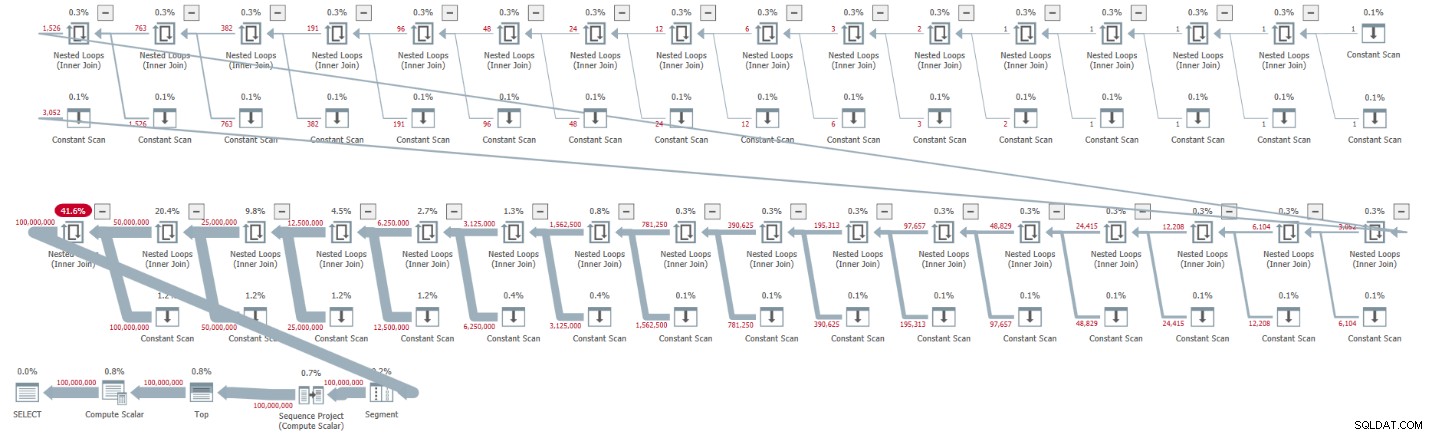 Figura 1:Plan para cardinalidad base CTE de 2
Figura 1:Plan para cardinalidad base CTE de 2
El plan es en serie y todos los operadores del plan utilizan el procesamiento de modo de fila de forma predeterminada. Si obtiene un plan paralelo de forma predeterminada, por ejemplo, al encapsular la solución en un iTVF y usar un rango amplio, por ahora fuerce un plan en serie con una sugerencia MAXDOP 1.
Observe cómo el desempaquetado de los CTE resultó en 32 instancias del operador Constant Scan, cada una representando una tabla con dos filas.
Obtuve las siguientes estadísticas de rendimiento para esta ejecución:
Tiempo de CPU =30188 ms, tiempo transcurrido =32844 ms.
Utilice el siguiente código para probar la solución con una cardinalidad CTE base de 4, que según nuestra fórmula requiere cuatro niveles de CTE:
DECLARAR @low COMO BIGINT =1, @high COMO BIGINT =100000000; CON L0 COMO ( SELECCIONE 1 COMO c DE (VALORES(1),(1),(1),(1)) COMO D(c) ), L1 COMO ( SELECCIONE 1 COMO c DE L0 COMO CRUZ ÚNASE L0 COMO B ), L2 COMO ( SELECCIONE 1 COMO c DE L1 COMO CRUZ ÚNASE A L1 COMO B ), L3 COMO ( SELECCIONE 1 COMO c DE L2 COMO CRUZ ÚNASE A L2 COMO B ), L4 COMO ( SELECCIONE 1 COMO c DE L3 COMO CRUZ ÚNASE A L3 COMO B), Números COMO (SELECCIONE ROW_NUMBER() SOBRE(ORDENAR POR (SELECCIONE NULL)) COMO número de fila DESDE L4) SELECCIONE SUPERIOR(@alto - @bajo + 1) @bajo + número de fila - 1 COMO nDE NumsORDEN POR número de fila;
Obtuve el plan que se muestra en la Figura 2 para esta ejecución.
 Figura 2:Plan para cardinalidad base CTE de 4
Figura 2:Plan para cardinalidad base CTE de 4
El desempaquetado de los CTE resultó en 16 operadores Constant Scan, cada uno representando una tabla de 4 filas.
Obtuve las siguientes estadísticas de rendimiento para esta ejecución:
Tiempo de CPU =23781 ms, tiempo transcurrido =25435 ms.
Esta es una mejora decente del 22,5 por ciento con respecto a la solución anterior.
Al examinar las estadísticas de espera informadas para la consulta, el tipo de espera dominante es SOS_SCHEDULER_YIELD. De hecho, el recuento de esperas curiosamente se redujo en un 22,8 % en comparación con la primera solución (recuento de esperas 15 280 frente a 19 800).
Utilice el siguiente código para probar la solución con una cardinalidad CTE base de 16, que según nuestra fórmula requiere tres niveles de CTE:
DECLARAR @low COMO BIGINT =1, @high COMO BIGINT =100000000; CON L0 COMO ( SELECCIONE 1 COMO c DE (VALORES(1),(1),(1),(1),(1),(1),(1),(1), (1),(1) ,(1),(1),(1),(1),(1),(1)) COMO D(c) ), L1 COMO ( SELECCIONE 1 COMO c DESDE L0 COMO UNA CRUZ ÚNASE A L0 COMO B ), L2 COMO ( SELECCIONE 1 COMO c DE L1 COMO CRUZ ÚNASE L1 COMO B ), L3 COMO ( SELECCIONE 1 COMO c DE L2 COMO CRUZ ÚNASE L2 COMO B ), Nums COMO ( SELECCIONE ROW_NUMBER() SOBRE(ORDENAR POR (SELECCIONE NULL )) COMO número de fila DESDE L3 ) SELECCIONE SUPERIOR(@alto - @bajo + 1) @bajo + número de fila - 1 COMO nDE Núm. ORDEN POR número de fila;
Obtuve el plan que se muestra en la Figura 3 para esta ejecución.
 Figura 3:Plan para cardinalidad base CTE de 16
Figura 3:Plan para cardinalidad base CTE de 16
Esta vez, el desempaquetado de los CTE resultó en 8 operadores Constant Scan, cada uno representando una tabla con 16 filas.
Obtuve las siguientes estadísticas de rendimiento para esta ejecución:
Tiempo de CPU =22968 ms, tiempo transcurrido =24409 ms.
Esta solución reduce aún más el tiempo transcurrido, aunque solo en un pequeño porcentaje adicional, lo que representa una reducción del 25,7 por ciento en comparación con la primera solución. Nuevamente, el conteo de espera del tipo de espera SOS_SCHEDULER_YIELD sigue disminuyendo (12,938).
Avanzando en nuestra escala logarítmica, la siguiente prueba involucra una cardinalidad CTE base de 256. Es larga y fea, pero pruébala:
DECLARAR @low COMO BIGINT =1, @high COMO BIGINT =100000000; CON L0 COMO ( SELECCIONE 1 COMO c DE (VALORES(1),(1),(1),(1),(1),(1),(1),(1), (1),(1) ,(1),(1),(1),(1),(1),(1), (1),(1),(1),(1),(1),(1),( 1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1) ,(1),(1),(1),(1),(1), (1),(1),(1),(1),(1),(1),(1),( 1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1) ,(1),(1),(1),(1), (1),(1),(1),(1),(1),(1),(1),(1), ( 1),(1),(1),(1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ,(1),(1),(1), (1),(1),(1),(1),(1),(1),(1),(1), (1),( 1),(1),(1),(1),(1),(1),(1), (1),(1),(1),(1),(1),(1) ,(1),(1), (1),(1),(1),(1),(1),(1),(1),(1), (1),(1),( 1),(1),(1),(1),(1),(1), (1),(1),(1),(1),(1),(1),(1) ,(1), (1),(1),(1),(1),(1),(1),(1),(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1) ),(1),(1),(1), (1),(1),(1),(1),(1),(1),(1),(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1) ),(1),(1), (1),(1),(1),(1),(1),(1),(1),(1), (1),(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1) ),(1), (1),(1),(1),(1),(1),(1),(1),(1), (1),(1),(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1) ), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1)) COMO D (c) ), L1 COMO ( SELECCIONE 1 COMO c DE L0 COMO CRUZ ÚNASE L0 COMO B ), L2 COMO ( SELECCIONE 1 COMO c DE L1 COMO CRUZ ÚNASE L1 COMO B ), Nums COMO ( SELECCIONE ROW_NUMBER() SOBRE( ORDENAR POR (SELECCIONAR NULO)) COMO número de fila DESDE L2 )SELECCIONAR SUPERIOR(@alto - @bajo + 1) @low + rownum - 1 COMO nFROM NumsORDER BY rownum;
Obtuve el plan que se muestra en la Figura 4 para esta ejecución.
 Figura 4:Plan para cardinalidad CTE base de 256
Figura 4:Plan para cardinalidad CTE base de 256
Esta vez, el desempaquetado de los CTE resultó en solo cuatro operadores Constant Scan, cada uno con 256 filas.
Obtuve los siguientes números de rendimiento para esta ejecución:
Tiempo de CPU =23516 ms, tiempo transcurrido =25529 ms.
Esta vez parece que el rendimiento se degradó un poco en comparación con la solución anterior con una cardinalidad CTE base de 16. De hecho, el recuento de espera del tipo de espera SOS_SCHEDULER_YIELD aumentó un poco a 13 176. Entonces, parece que encontramos nuestro número dorado:¡16!
Planes paralelos versus planes en serie
Experimenté forzando un plan paralelo usando la sugerencia ENABLE_PARALLEL_PLAN_PREFERENCE, pero terminó perjudicando el rendimiento. De hecho, cuando implementé la solución como iTVF, obtuve un plan paralelo en mi máquina de forma predeterminada para rangos grandes y tuve que forzar un plan en serie con una sugerencia de MAXDOP 1 para obtener un rendimiento óptimo.
Procesamiento por lotes
El principal recurso utilizado en los planes de mis soluciones es la CPU. Dado que el procesamiento por lotes se trata de mejorar la eficiencia de la CPU, especialmente cuando se trata de un gran número de filas, vale la pena probar esta opción. La actividad principal aquí que puede beneficiarse del procesamiento por lotes es el cálculo del número de fila. Probé mis soluciones en SQL Server 2019 Enterprise edition. SQL Server eligió el procesamiento en modo de fila para todas las soluciones mostradas anteriormente de forma predeterminada. Aparentemente, esta solución no superó las heurísticas requeridas para habilitar el modo por lotes en el almacén de filas. Hay un par de formas de hacer que SQL Server use el procesamiento por lotes aquí.
La opción 1 es involucrar una tabla con un índice de almacén de columnas en la solución. Puede lograr esto creando una tabla ficticia con un índice de almacén de columnas e introduciendo una combinación izquierda ficticia en la consulta más externa entre nuestro Nums CTE y esa tabla. Aquí está la definición de la tabla ficticia:
CREAR TABLA dbo.BatchMe(col1 INT NO NULO, ÍNDICE idx_cs ALMACÉN DE COLUMNAS EN CLÚSTER);
Luego revise la consulta externa contra Nums para usar FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 =0. Aquí hay un ejemplo con una cardinalidad CTE base de 16:
DECLARAR @low COMO BIGINT =1, @high COMO BIGINT =100000000; CON L0 COMO ( SELECCIONE 1 COMO c DE (VALORES(1),(1),(1),(1),(1),(1),(1),(1), (1),(1) ,(1),(1),(1),(1),(1),(1)) COMO D(c) ), L1 COMO ( SELECCIONE 1 COMO c DESDE L0 COMO UNA CRUZ ÚNASE A L0 COMO B ), L2 COMO ( SELECCIONE 1 COMO c DE L1 COMO CRUZ ÚNASE L1 COMO B ), L3 COMO ( SELECCIONE 1 COMO c DE L2 COMO CRUZ ÚNASE L2 COMO B ), Nums COMO ( SELECCIONE ROW_NUMBER() SOBRE(ORDENAR POR (SELECCIONE NULL )) COMO número de fila DESDE L3 )SELECCIONE SUPERIOR (@alto - @bajo + 1) @bajo + número de fila - 1 COMO nDE Núm.Obtuve el plan que se muestra en la Figura 5 para esta ejecución.
Figura 5:Plan con procesamiento por lotes
Observe el uso del operador Agregado de ventana del modo por lotes para calcular los números de fila. También observe que el plan no incluye la mesa ficticia. El optimizador lo optimizó.
La ventaja de la opción 1 es que funciona en todas las ediciones de SQL Server y es relevante en SQL Server 2016 o posterior, ya que el operador Agregado de ventanas en modo por lotes se introdujo en SQL Server 2016. La desventaja es la necesidad de crear la tabla ficticia e incluir en la solución.
La opción 2 para obtener procesamiento por lotes para nuestra solución, siempre que esté utilizando la edición Enterprise de SQL Server 2019, es usar la sugerencia autoexplicativa no documentada OVERRIDE_BATCH_MODE_HEURISTICS (detalles en el artículo de Dmitry Pilugin), así:
DECLARAR @low COMO BIGINT =1, @high COMO BIGINT =100000000; CON L0 COMO ( SELECCIONE 1 COMO c DE (VALORES(1),(1),(1),(1),(1),(1),(1),(1), (1),(1) ,(1),(1),(1),(1),(1),(1)) COMO D(c) ), L1 COMO ( SELECCIONE 1 COMO c DESDE L0 COMO UNA CRUZ ÚNASE A L0 COMO B ), L2 COMO ( SELECCIONE 1 COMO c DE L1 COMO CRUZ ÚNASE L1 COMO B ), L3 COMO ( SELECCIONE 1 COMO c DE L2 COMO CRUZ ÚNASE L2 COMO B ), Nums COMO ( SELECCIONE ROW_NUMBER() SOBRE(ORDENAR POR (SELECCIONE NULL )) COMO número de fila DESDE L3 ) SELECCIONE SUPERIOR (@alto - @bajo + 1) @bajo + número de fila - 1 COMO nDE NumsORDER POR número de fila OPCIÓN (USE SUGERENCIA ('OVERRIDE_BATCH_MODE_HEURISTICS'));La ventaja de la opción 2 es que no necesita crear una tabla ficticia e involucrarla en su solución. Las desventajas son que necesita usar la edición Enterprise, usar como mínimo SQL Server 2019 donde se introdujo el modo por lotes en el almacén de filas, y la solución implica usar una sugerencia no documentada. Por estas razones, prefiero la opción 1.
Estas son las cifras de rendimiento que obtuve para las distintas cardinalidades base de CTE:
Cardinalidad 2:tiempo de CPU =21594 ms, tiempo transcurrido =22743 ms (antes 32844). Cardinalidad 4:tiempo de CPU =18375 ms, tiempo transcurrido =19394 ms (antes 25435). Cardinalidad 16:tiempo de CPU =17640 ms, tiempo transcurrido =18568 ms (antes 24409). Cardinalidad 256:tiempo de CPU =17109 ms, tiempo transcurrido =18507 ms (antes 25529).La figura 6 tiene una comparación de rendimiento entre las diferentes soluciones:
Figura 6:Comparación de rendimiento
Puede observar una mejora de rendimiento decente de 20-30 por ciento sobre las contrapartes del modo fila.
Curiosamente, con el procesamiento en modo por lotes, la solución con cardinalidad CTE base de 256 funcionó mejor. Sin embargo, es solo un poco más rápido que la solución con cardinalidad CTE base de 16. La diferencia es tan pequeña, y esta última tiene una clara ventaja en términos de brevedad de código, que me quedaría con 16.
Por lo tanto, mis esfuerzos de ajuste terminaron generando una mejora del 43,5 % con respecto a la solución original con la cardinalidad base de 2 mediante el procesamiento en modo fila.
¡El desafío está en marcha!
Presento dos soluciones como contribución de mi comunidad a este desafío. Si utiliza SQL Server 2016 o posterior y puede crear una tabla en la base de datos del usuario, cree la siguiente tabla ficticia:
CREAR TABLA dbo.BatchMe(col1 INT NO NULO, ÍNDICE idx_cs ALMACÉN DE COLUMNAS EN CLÚSTER);Y use la siguiente definición de iTVF:
CREAR O ALTERAR FUNCIÓN dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT) DEVUELVE TABLEASRETURN CON L0 COMO ( SELECCIONE 1 COMO c DE (VALORES(1),(1),(1),(1),(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1)) COMO D (c) ), L1 COMO ( SELECCIONE 1 COMO c DE L0 COMO CRUZ ÚNASE L0 COMO B ), L2 COMO ( SELECCIONE 1 COMO c DE L1 COMO CRUZ ÚNASE L1 COMO B ), L3 COMO ( SELECCIONE 1 COMO c DE L2 COMO UNA CRUZ ÚNASE A L2 COMO B ), Números COMO ( SELECCIONE ROW_NUMBER() SOBRE(ORDENAR POR (SELECCIONE NULL)) COMO número de fila DESDE L3 ) SELECCIONE SUPERIOR(@alto - @bajo + 1) @bajo + número de fila - 1 COMO n DESDE Números IZQUIERDA EXTERNA ÚNETE dbo.BatchMe ON 1 =0 ORDEN POR rownum;IRUse el siguiente código para probarlo (asegúrese de tener marcado Descartar resultados después de la ejecución):
SELECCIONE n DE dbo.GetNumsItzikBatch(1, 100000000) OPCIÓN(MAXDOP 1);Este código termina en 18 segundos en mi máquina.
Si por alguna razón no puede cumplir con los requisitos de la solución de procesamiento por lotes, envío la siguiente definición de función como mi segunda solución:
CREAR O ALTERAR FUNCIÓN dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT) DEVUELVE TABLEASRETURN CON L0 AS ( SELECCIONE 1 COMO c DE (VALORES(1),(1),(1),(1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1), (1)) COMO D (c) ), L1 COMO ( SELECCIONE 1 COMO c DE L0 COMO CRUZ ÚNASE L0 COMO B ), L2 COMO ( SELECCIONE 1 COMO c DE L1 COMO CRUZ ÚNASE L1 COMO B ), L3 COMO ( SELECCIONE 1 COMO c DE L2 COMO UNA CRUZ ÚNASE A L2 COMO B ), Números COMO ( SELECCIONE ROW_NUMBER() SOBRE(ORDENAR POR (SELECCIONE NULL)) COMO número de fila DESDE L3 ) SELECCIONE SUPERIOR(@alto - @bajo + 1) @bajo + número de fila - 1 COMO n DESDE Números ORDEN POR número de fila;IRUse el siguiente código para probarlo:
SELECCIONE n DESDE dbo.GetNumsItzik(1, 100000000) OPCIÓN(MAXDOP 1);Este código termina en 24 segundos en mi máquina.
¡Tu turno!



