Esta es la segunda parte de una serie sobre soluciones al desafío del generador de series numéricas. El mes pasado cubrí soluciones que generan las filas sobre la marcha usando un constructor de valores de tabla con filas basadas en constantes. No hubo operaciones de E/S involucradas en esas soluciones. Este mes me centro en las soluciones que consultan una tabla base física que se rellena previamente con filas. Por esta razón, más allá de informar el perfil de tiempo de las soluciones como hice el mes pasado, también informaré el perfil de E/S de las nuevas soluciones. Gracias nuevamente a Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2 y Ed Wagner por compartir sus ideas y comentarios.
La solución más rápida hasta ahora
Primero, como recordatorio rápido, revisemos la solución más rápida del artículo del mes pasado, implementada como un TVF en línea llamado dbo.GetNumsAlanCharlieItzikBatch.
Haré mis pruebas en tempdb, habilitando las estadísticas IO y TIME:
SET NOCOUNT ON; USE tempdb; SET STATISTICS IO, TIME ON;
La solución más rápida del mes pasado aplica una combinación con una tabla ficticia que tiene un índice de almacén de columnas para obtener el procesamiento por lotes. Aquí está el código para crear la tabla ficticia:
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Y aquí está el código con la definición de la función dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO El mes pasado usé el siguiente código para probar el rendimiento de la función con 100 millones de filas, después de habilitar Descartar resultados después de la ejecución en SSMS para suprimir la devolución de las filas de salida:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Aquí están las estadísticas de tiempo que obtuve para esta ejecución:
Tiempo de CPU =16031 ms, tiempo transcurrido =17172 ms.Joe Obbish señaló correctamente que esta prueba podría no reflejar algunos escenarios de la vida real en el sentido de que una gran parte del tiempo de ejecución se debe a esperas de E/S de red asíncronas (tipo de espera ASYNC_NETWORK_IO). Puede observar las esperas más altas mirando la página de propiedades del nodo raíz del plan de consulta real, o ejecutar una sesión de eventos extendidos con información de espera. El hecho de que habilite Descartar resultados después de la ejecución en SSMS no impide que SQL Server envíe las filas de resultados a SSMS; simplemente evita que SSMS los imprima. La pregunta es, ¿cuál es la probabilidad de que devuelva grandes conjuntos de resultados al cliente en escenarios de la vida real, incluso cuando utilice la función para producir una gran serie de números? Tal vez con más frecuencia escriba los resultados de la consulta en una tabla o use el resultado de la función como parte de una consulta que eventualmente produce un pequeño conjunto de resultados. Necesitas resolver esto. Puede escribir el conjunto de resultados en una tabla temporal usando la instrucción SELECT INTO, o puede usar el truco de Alan Burstein con una instrucción SELECT de asignación, que asigna el valor de la columna de resultados a una variable.
Así es como cambiaría la última prueba para usar la opción de asignación de variables:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Aquí están las estadísticas de tiempo que obtuve para esta prueba:
Tiempo de CPU =8641 ms, tiempo transcurrido =8645 ms.Esta vez, la información de espera no tiene esperas de E/S de red asíncronas, y puede ver la caída significativa en el tiempo de ejecución.
Pruebe la función nuevamente, esta vez agregando pedidos:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Obtuve las siguientes estadísticas de rendimiento para esta ejecución:
Tiempo de CPU =9360 ms, tiempo transcurrido =9551 ms.Recuerde que no es necesario un operador Ordenar en el plan para esta consulta, ya que la columna n se basa en una expresión que conserva el orden con respecto a la columna número de fila. Eso es gracias al constante truco de plegado de Charli, que cubrí el mes pasado. Los planes para ambas consultas, la que no ordena y la que ordena, son los mismos, por lo que el rendimiento tiende a ser similar.
La Figura 1 resume los números de rendimiento que obtuve para las soluciones del mes pasado, solo que esta vez usando la asignación de variables en las pruebas en lugar de descartar los resultados después de la ejecución.
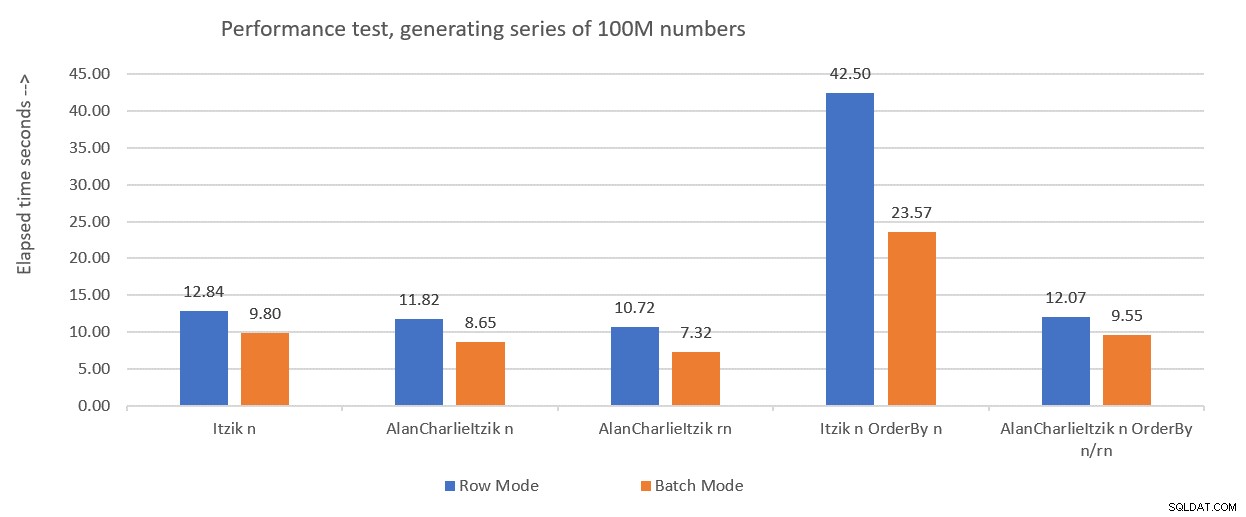 Figura 1:Resumen de rendimiento hasta ahora con asignación de variables
Figura 1:Resumen de rendimiento hasta ahora con asignación de variables
Usaré la técnica de asignación de variables para probar el resto de las soluciones que presentaré en este artículo. Asegúrese de ajustar sus pruebas para reflejar mejor su situación de la vida real, utilizando asignación de variables, SELECCIONAR EN, Descartar resultados después de la ejecución o cualquier otra técnica.
Sugerencia para forzar planes en serie sin MAXDOP 1
Antes de presentar nuevas soluciones, solo quería cubrir un pequeño consejo. Recuerde que algunas de las soluciones funcionan mejor cuando se utiliza un plan en serie. La forma obvia de forzar esto es con una sugerencia de consulta MAXDOP 1. Y ese es el camino correcto a seguir si a veces desea habilitar el paralelismo y otras veces no. Sin embargo, ¿qué sucede si siempre desea forzar un plan en serie cuando usa la función, aunque sea un escenario menos probable?
Hay un truco para lograr esto. El uso de una UDF escalar no lineal en la consulta es un inhibidor de paralelismo. Uno de los inhibidores de inserción de UDF escalares invoca una función intrínseca que depende del tiempo, como SYSDATETIME. Aquí hay un ejemplo de una UDF escalar no lineal:
CREATE OR ALTER FUNCTION dbo.MySYSDATETIME() RETURNS DATETIME2 AS BEGIN RETURN SYSDATETIME(); END; GO
Otra opción es definir una UDF con solo alguna constante como valor devuelto y usar la opción INLINE =OFF en su encabezado. Pero esta opción solo está disponible a partir de SQL Server 2019, que introdujo la inserción de UDF escalar. Con la función sugerida anteriormente, puede crearla tal cual con versiones anteriores de SQL Server.
A continuación, modifique la definición de la función dbo.GetNumsAlanCharlieItzikBatch para tener una llamada ficticia a dbo.MySYSDATETIME (defina una columna basada en ella pero no haga referencia a la columna en la consulta devuelta), así:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT
ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum,
dbo.MySYSDATETIME() AS dontinline
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Ahora puede volver a ejecutar la prueba de rendimiento sin especificar MAXDOP 1 y seguir obteniendo un plan en serie:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n;
Sin embargo, es importante enfatizar que cualquier consulta que use esta función ahora obtendrá un plan en serie. Si existe alguna posibilidad de que la función se use en consultas que se beneficiarán de planes paralelos, mejor no use este truco, y cuando necesite un plan en serie, simplemente use MAXDOP 1.
Solución de Joe Obbish
La solución de Joe es bastante creativa. Aquí está su propia descripción de la solución:
“Opté por crear un índice de almacén de columnas agrupado (CCI) con 134 217 728 filas de números enteros secuenciales. La función hace referencia a la tabla hasta 32 veces para obtener todas las filas necesarias para el conjunto de resultados. Elegí un CCI porque los datos se comprimirán bien (menos de 3 bytes por fila), obtienes el modo por lotes "gratis" y la experiencia previa sugiere que leer números secuenciales de un CCI será más rápido que generarlos a través de algún otro método. ”Como se mencionó anteriormente, Joe también notó que mi prueba de rendimiento original estaba significativamente sesgada debido a las esperas de E/S de la red asíncrona generadas al transmitir las filas a SSMS. Entonces, todas las pruebas que realizaré aquí usarán la idea de Alan con la asignación de variables. Asegúrese de ajustar sus pruebas según lo que mejor refleje su situación de la vida real.
Aquí está el código que Joe usó para crear la tabla dbo.GetNumsObbishTable y llenarla con 134,217,728 filas:
DROP TABLE IF EXISTS dbo.GetNumsObbishTable; CREATE TABLE dbo.GetNumsObbishTable (ID BIGINT NOT NULL, INDEX CCI CLUSTERED COLUMNSTORE); GO SET NOCOUNT ON; DECLARE @c INT = 0; WHILE @c < 128 BEGIN INSERT INTO dbo.GetNumsObbishTable SELECT TOP (1048576) @c * 1048576 - 1 + ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2 OPTION (MAXDOP 1); SET @c = @c + 1; END; GO
Este código tardó 1:04 minutos en completarse en mi máquina.
Puede verificar el uso de espacio de esta tabla ejecutando el siguiente código:
EXEC sys.sp_spaceused @objname = N'dbo.GetNumsObbishTable';
Tengo alrededor de 350 MB de espacio utilizado. En comparación con las otras soluciones que presentaré en este artículo, esta utiliza mucho más espacio.
En la arquitectura de almacén de columnas de SQL Server, un grupo de filas está limitado a 2^20 =1 048 576 filas. Puede verificar cuántos grupos de filas se crearon para esta tabla usando el siguiente código:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.GetNumsObbishTable'); Tengo 128 grupos de filas.
Aquí está el código con la definición de la función dbo.GetNumsObbish:
CREATE OR ALTER FUNCTION dbo.GetNumsObbish(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE AS RETURN SELECT @low + ID AS n FROM dbo.GetNumsObbishTable WHERE ID <= @high - @low UNION ALL SELECT @low + ID + CAST(134217728 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(134217728 AS BIGINT) AND ID <= @high - @low - CAST(134217728 AS BIGINT) UNION ALL SELECT @low + ID + CAST(268435456 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(268435456 AS BIGINT) AND ID <= @high - @low - CAST(268435456 AS BIGINT) UNION ALL SELECT @low + ID + CAST(402653184 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(402653184 AS BIGINT) AND ID <= @high - @low - CAST(402653184 AS BIGINT) UNION ALL SELECT @low + ID + CAST(536870912 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(536870912 AS BIGINT) AND ID <= @high - @low - CAST(536870912 AS BIGINT) UNION ALL SELECT @low + ID + CAST(671088640 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(671088640 AS BIGINT) AND ID <= @high - @low - CAST(671088640 AS BIGINT) UNION ALL SELECT @low + ID + CAST(805306368 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(805306368 AS BIGINT) AND ID <= @high - @low - CAST(805306368 AS BIGINT) UNION ALL SELECT @low + ID + CAST(939524096 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(939524096 AS BIGINT) AND ID <= @high - @low - CAST(939524096 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1073741824 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1073741824 AS BIGINT) AND ID <= @high - @low - CAST(1073741824 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1207959552 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1207959552 AS BIGINT) AND ID <= @high - @low - CAST(1207959552 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1342177280 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1342177280 AS BIGINT) AND ID <= @high - @low - CAST(1342177280 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1476395008 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1476395008 AS BIGINT) AND ID <= @high - @low - CAST(1476395008 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1610612736 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1610612736 AS BIGINT) AND ID <= @high - @low - CAST(1610612736 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1744830464 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1744830464 AS BIGINT) AND ID <= @high - @low - CAST(1744830464 AS BIGINT) UNION ALL SELECT @low + ID + CAST(1879048192 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(1879048192 AS BIGINT) AND ID <= @high - @low - CAST(1879048192 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2013265920 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2013265920 AS BIGINT) AND ID <= @high - @low - CAST(2013265920 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2147483648 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2147483648 AS BIGINT) AND ID <= @high - @low - CAST(2147483648 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2281701376 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2281701376 AS BIGINT) AND ID <= @high - @low - CAST(2281701376 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2415919104 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2415919104 AS BIGINT) AND ID <= @high - @low - CAST(2415919104 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2550136832 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2550136832 AS BIGINT) AND ID <= @high - @low - CAST(2550136832 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2684354560 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2684354560 AS BIGINT) AND ID <= @high - @low - CAST(2684354560 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2818572288 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2818572288 AS BIGINT) AND ID <= @high - @low - CAST(2818572288 AS BIGINT) UNION ALL SELECT @low + ID + CAST(2952790016 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(2952790016 AS BIGINT) AND ID <= @high - @low - CAST(2952790016 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3087007744 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3087007744 AS BIGINT) AND ID <= @high - @low - CAST(3087007744 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3221225472 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3221225472 AS BIGINT) AND ID <= @high - @low - CAST(3221225472 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3355443200 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3355443200 AS BIGINT) AND ID <= @high - @low - CAST(3355443200 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3489660928 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3489660928 AS BIGINT) AND ID <= @high - @low - CAST(3489660928 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3623878656 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3623878656 AS BIGINT) AND ID <= @high - @low - CAST(3623878656 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3758096384 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3758096384 AS BIGINT) AND ID <= @high - @low - CAST(3758096384 AS BIGINT) UNION ALL SELECT @low + ID + CAST(3892314112 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(3892314112 AS BIGINT) AND ID <= @high - @low - CAST(3892314112 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4026531840 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4026531840 AS BIGINT) AND ID <= @high - @low - CAST(4026531840 AS BIGINT) UNION ALL SELECT @low + ID + CAST(4160749568 AS BIGINT) AS n FROM dbo.GetNumsObbishTable WHERE @high - @low + 1 > CAST(4160749568 AS BIGINT) AND ID <= @high - @low - CAST(4160749568 AS BIGINT); GO
Las 32 consultas individuales generan los subintervalos de 134 217 728 enteros disjuntos que, cuando se unifican, producen el intervalo ininterrumpido completo del 1 al 4 294 967 296. Lo realmente inteligente de esta solución son los predicados de filtro WHERE que utilizan las consultas individuales. Recuerde que cuando SQL Server procesa un TVF en línea, primero aplica la incrustación de parámetros, sustituyendo los parámetros con las constantes de entrada. Luego, SQL Server puede optimizar las consultas que producen subrangos que no se cruzan con el rango de entrada. Por ejemplo, cuando solicita el rango de entrada de 1 a 100 000 000, solo la primera consulta es relevante y el resto se optimiza. Entonces, el plan en este caso implicará una referencia a solo una instancia de la tabla. ¡Eso es bastante brillante!
Probemos el rendimiento de la función con el rango de 1 a 100,000,000:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000);
El plan para esta consulta se muestra en la Figura 2.
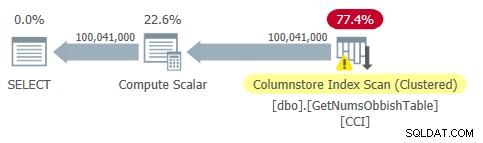 Figura 2:Plan para dbo.GetNumsObbish, 100 millones de filas, desordenado
Figura 2:Plan para dbo.GetNumsObbish, 100 millones de filas, desordenado
Observe que, de hecho, solo se necesita una referencia al CCI de la tabla en este plan.
Obtuve las siguientes estadísticas de tiempo para esta ejecución:
Eso es bastante impresionante y mucho más rápido que cualquier otra cosa que haya probado.
Aquí están las estadísticas de E/S que obtuve para esta ejecución:
Tabla 'GetNumsObbishTable'. Recuento de escaneos 1, lecturas lógicas 0, lecturas físicas 0, lecturas del servidor de páginas 0, lecturas anticipadas 0, lecturas anticipadas del servidor de páginas 0, lecturas lógicas de lob 32928 , el lob físico lee 0, el servidor de la página lob lee 0, la lectura anticipada del lob lee 0, la lectura anticipada del servidor de la página lob lee 0.Tabla 'GetNumsObbishTable'. El segmento lee 96 , segmento omitido 32.
El perfil de E/S de esta solución es una de sus desventajas en comparación con las demás, ya que genera más de 30 000 lecturas lógicas de lob para esta ejecución.
Para ver que cuando cruza múltiples subrangos de 134,217,728 enteros, el plan implicará múltiples referencias a la tabla, consulte la función con el rango de 1 a 400,000,000, por ejemplo:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 400000000);
El plan para esta ejecución se muestra en la Figura 3.
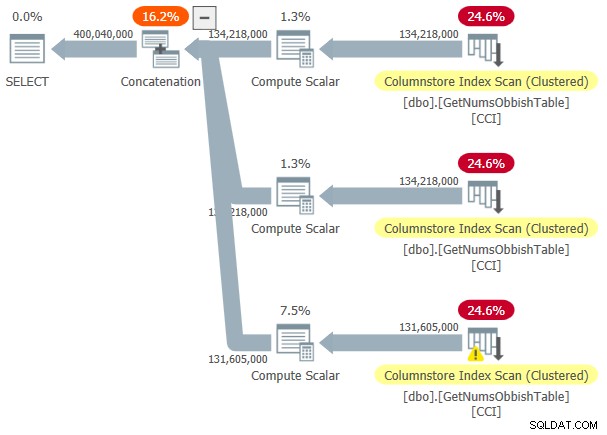 Figura 3:Plan para dbo.GetNumsObbish, 400 millones de filas, sin ordenar
Figura 3:Plan para dbo.GetNumsObbish, 400 millones de filas, sin ordenar
El rango solicitado cruzó tres subrangos de 134 217 728 enteros, por lo que el plan muestra tres referencias al CCI de la tabla.
Aquí están las estadísticas de tiempo que obtuve para esta ejecución:
Tiempo de CPU =20610 ms, tiempo transcurrido =20628 ms.Y aquí están sus estadísticas de E/S:
Tabla 'GetNumsObbishTable'. Recuento de escaneos 3, lecturas lógicas 0, lecturas físicas 0, servidor de páginas lee 0, lecturas anticipadas 0, lecturas anticipadas del servidor de páginas lee 0, lecturas lógicas de lob 131026 , el lob físico lee 0, el servidor de la página lob lee 0, la lectura anticipada del lob lee 0, la lectura anticipada del servidor de la página lob lee 0.Tabla 'GetNumsObbishTable'. El segmento lee 382 , segmento omitido 2.
Esta vez, la ejecución de la consulta resultó en más de 130 000 lecturas lógicas de lob.
Si puede soportar los costos de E/S y no necesita procesar las series numéricas de manera ordenada, esta es una excelente solución. Sin embargo, si necesita procesar la serie en orden, esta solución dará como resultado un operador Ordenar en el plan. Aquí hay una prueba que solicita el resultado ordenado:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsObbish(1, 100000000) ORDER BY n;
El plan para esta ejecución se muestra en la Figura 4.
 Figura 4:Plan para dbo.GetNumsObbish, 100 millones de filas, ordenado
Figura 4:Plan para dbo.GetNumsObbish, 100 millones de filas, ordenado
Aquí están las estadísticas de tiempo que obtuve para esta ejecución:
Tiempo de CPU =44516 ms, tiempo transcurrido =34836 ms.Como puede ver, el rendimiento se degradó significativamente con el aumento del tiempo de ejecución en un orden de magnitud debido a la clasificación explícita.
Aquí están las estadísticas de E/S que obtuve para esta ejecución:
Tabla 'GetNumsObbishTable'. Número de escaneos 4, lecturas lógicas 0, lecturas físicas 0, lecturas del servidor de páginas 0, lecturas anticipadas 0, lecturas anticipadas del servidor de páginas 0, lecturas lógicas de lob 32928 , el lob físico lee 0, el servidor de la página lob lee 0, la lectura anticipada del lob lee 0, la lectura anticipada del servidor de la página lob lee 0.Tabla 'GetNumsObbishTable'. El segmento lee 96 , segmento omitido 32.
Mesa 'Mesa de trabajo'. Recuento de escaneos 0, lecturas lógicas 0, lecturas físicas 0, lecturas del servidor de páginas 0, lecturas anticipadas 0, lecturas anticipadas del servidor de páginas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas del servidor de páginas lob 0, lecturas lob- adelante lee 0, la lectura anticipada del servidor de páginas de lob lee 0.
Observe que apareció una tabla de trabajo en la salida de STATISTICS IO. Esto se debe a que una clasificación puede potencialmente pasar a tempdb, en cuyo caso usaría una mesa de trabajo. Esta ejecución no se derramó, por lo que los números son todos ceros en esta entrada.
Solución de John Nelson #2, Dave, Joe, Alan, Charlie, Itzik
John Nelson #2 publicó una solución que es hermosa en su simplicidad. Además, incluye ideas y sugerencias de otras soluciones de Dave, Joe, Alan, Charlie y yo mismo.
Al igual que con la solución de Joe, John decidió usar un CCI para obtener un alto nivel de compresión y procesamiento por lotes "gratuito". Solo John decidió llenar la tabla con 4B filas con algún marcador NULL ficticio en una columna de bits y hacer que la función ROW_NUMBER genere los números. Dado que los valores almacenados son todos iguales, con la compresión de valores repetidos se necesita mucho menos espacio, lo que genera menos E/S en comparación con la solución de Joe. La compresión de almacén de columnas maneja muy bien los valores repetidos, ya que puede representar cada una de esas secciones consecutivas dentro del segmento de columna de un grupo de filas solo una vez junto con el recuento de ocurrencias repetidas consecutivamente. Dado que todas las filas tienen el mismo valor (el marcador NULL), teóricamente solo necesita una aparición por grupo de filas. Con filas 4B, debe terminar con 4096 grupos de filas. Cada uno debe tener un segmento de una sola columna, con muy poco requisito de uso de espacio.
Aquí está el código para crear y completar la tabla, implementado como un CCI con compresión de archivo:
DROP TABLE IF EXISTS dbo.NullBits4B;
CREATE TABLE dbo.NullBits4B
(
b BIT NULL,
INDEX cc_NullBits4B CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B),
nulls(b) AS (SELECT A.b FROM L2 AS A CROSS JOIN L2 AS B)
INSERT INTO dbo.NullBits4B WITH (TABLOCK) (b)
SELECT b FROM nulls;
GO El principal inconveniente de esta solución es el tiempo que lleva completar esta tabla. Este código tardó 12:32 minutos en completarse en mi máquina al permitir el paralelismo y 15:17 minutos al forzar un plan en serie.
Tenga en cuenta que podría trabajar en la optimización de la carga de datos. Por ejemplo, John probó una solución que cargaba las filas mediante 32 conexiones simultáneas con OSTRESS.EXE, cada una de las cuales ejecutaba 128 rondas de inserciones de 2^20 filas (tamaño máximo del grupo de filas). Esta solución redujo el tiempo de carga de John a un tercio. Este es el código que usó John:
ostress -S(local)\YourSQLInstance -E -dtempdb -n32 -r128 -Q"CON L0 COMO (SELECCIONE CAST(NULL COMO BIT) COMO b DE (VALORES(1),(1),(1),(1) ,(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) COMO D(b)), L1 COMO (SELECCIONE A.b DE L0 COMO CRUZ ÚNASE A L0 COMO B), L2 COMO (SELECCIONE A.b DE L1 COMO CRUZ ÚNASE A L1 COMO B), nulls(b) COMO (SELECCIONE A.b DE L2 COMO A CROSS JOIN L2 AS B) INSERT INTO dbo.NullBits4B(b) SELECCIONA TOP(1048576) b FROM nulls OPTION(MAXDOP 1);"Aún así, el tiempo de carga es en minutos. La buena noticia es que solo necesita realizar esta carga de datos una vez.
La gran noticia es la pequeña cantidad de espacio que necesita la mesa. Utilice el siguiente código para comprobar el uso del espacio:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits4B';
Tengo 1,64 MB. ¡Es increíble considerando el hecho de que la tabla tiene filas 4B!
Use el siguiente código para verificar cuántos grupos de filas se crearon:
SELECT COUNT(*) AS numrowgroups
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits4B'); Como era de esperar, el número de grupos de filas es 4096.
La definición de la función dbo.GetNumsJohn2DaveObbishAlanCharlieItzik se vuelve bastante simple:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits4B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO
Como puede ver, una consulta simple contra la tabla usa la función ROW_NUMBER para calcular los números de fila base (columna de número de fila), y luego la consulta externa usa las mismas expresiones que en dbo.GetNumsAlanCharlieItzikBatch para calcular rn, op y n. También aquí, tanto rn como n conservan el orden con respecto a rownum.
Probemos el rendimiento de la función:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000);
Obtuve el plan que se muestra en la Figura 5 para esta ejecución.
 Figura 5:Plan para dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Figura 5:Plan para dbo.GetNumsJohn2DaveObbishAlanCharlieItzik
Aquí están las estadísticas de tiempo que obtuve para esta prueba:
Tiempo de CPU =7593 ms, tiempo transcurrido =7590 ms.
Como puede ver, el tiempo de ejecución no es tan rápido como con la solución de Joe, pero sigue siendo más rápido que todas las demás soluciones que he probado.
Estas son las estadísticas de E/S que obtuve para esta prueba:
Tabla 'NullBits4B'. El segmento lee 96 , segmento saltado 0
Observe que los requisitos de E/S son significativamente más bajos que con la solución de Joe.
La otra ventaja de esta solución es que cuando necesita procesar la serie de números solicitada, no paga nada adicional. Eso es porque no dará como resultado una operación de clasificación explícita en el plan, independientemente de si ordena el resultado por rn o n.
Aquí hay una prueba para demostrar esto:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik(1, 100000000) ORDER BY n;
Obtiene el mismo plan que se muestra anteriormente en la Figura 5.
Aquí están las estadísticas de tiempo que obtuve para esta prueba;
Tiempo de CPU =7578 ms, tiempo transcurrido =7582 ms.Y aquí están las estadísticas de E/S:
Tabla 'NullBits4B'. Recuento de escaneos 1, lecturas lógicas 0, lecturas físicas 0, lecturas del servidor de páginas 0, lecturas anticipadas 0, lecturas anticipadas del servidor de páginas lee 0, lecturas lógicas de lob 194 , el lob físico lee 0, el servidor de la página lob lee 0, la lectura anticipada del lob lee 0, la lectura anticipada del servidor de la página lob lee 0.Tabla 'NullBits4B'. El segmento lee 96 , segmento omitido 0.
Son básicamente los mismos que en la prueba sin el orden.
Solución 2 de John Nelson #2, Dave Mason, Joe Obbish, Alan, Charlie, Itzik
La solución de John es rápida y sencilla. Eso es fantástico. El único inconveniente es el tiempo de carga. A veces, esto no será un problema ya que la carga ocurre solo una vez. Pero si es un problema, podría llenar la tabla con 102 400 filas en lugar de 4B filas y usar una unión cruzada entre dos instancias de la tabla y un filtro TOP para generar el máximo deseado de 4B filas. Tenga en cuenta que para obtener 4B filas bastaría con completar la tabla con 65 536 filas y luego aplicar una unión cruzada; sin embargo, para que los datos se compriman inmediatamente, en lugar de cargarlos en un almacén delta basado en un almacén de filas, debe cargar la tabla con un mínimo de 102 400 filas.
Aquí está el código para crear y completar la tabla:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO El tiempo de carga es insignificante:43 ms en mi máquina.
Compruebe el tamaño de la tabla en el disco:
EXEC sys.sp_spaceused @objname = N'dbo.NullBits102400';
Tengo 56 KB de espacio necesario para los datos.
Compruebe el número de grupos de filas, su estado (comprimido o abierto) y su tamaño:
SELECT state_description, total_rows, size_in_bytes
FROM sys.column_store_row_groups
WHERE object_id = OBJECT_ID('dbo.NullBits102400'); Obtuve el siguiente resultado:
state_description total_rows size_in_bytes ------------------ ----------- -------------- COMPRESSED 102400 293
Aquí solo se necesita un grupo de filas; está comprimido y el tamaño es insignificante de 293 bytes.
Si rellena la tabla con una fila menos (102 399), obtiene un almacén delta abierto sin comprimir basado en el almacén de filas. En tal caso, sp_spaceused informa el tamaño de los datos en el disco de más de 1 MB, y sys.column_store_row_groups informa la siguiente información:
state_description total_rows size_in_bytes ------------------ ----------- -------------- OPEN 102399 1499136
¡Así que asegúrese de completar la tabla con 102 400 filas!
Aquí está la definición de la función dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Let’s test the function's performance:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
I got the plan shown in Figure 6 for this execution.
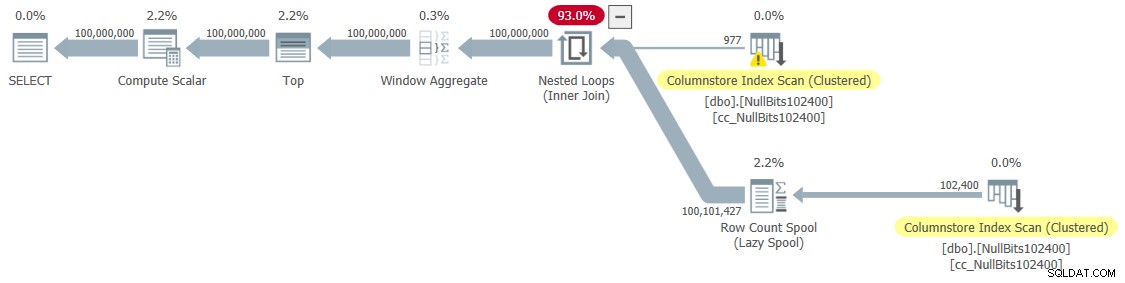 Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Figure 6:Plan for dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
I got the following time statistics for this test:
CPU time =9188 ms, elapsed time =9188 ms.As you can see, the execution time increased by ~ 26%. It’s still pretty fast, but not as fast as the single-table solution. So that’s a tradeoff that you’ll need to evaluate.
I got the following I/O stats for this test:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
The I/O profile of this solution is excellent.
Let’s add order to the test:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
You get the same plan as shown earlier in Figure 6 since there’s no explicit sorting needed.
I got the following time statistics for this test:
CPU time =9140 ms, elapsed time =9237 ms.And the following I/O stats:
Table 'NullBits102400'. Scan count 2, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 8 , lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.Table 'NullBits102400'. Segment reads 2, segment skipped 0.
Again, the numbers are very similar to the test without the ordering.
Performance summary
Figure 7 has a summary of the time statistics for the different solutions.
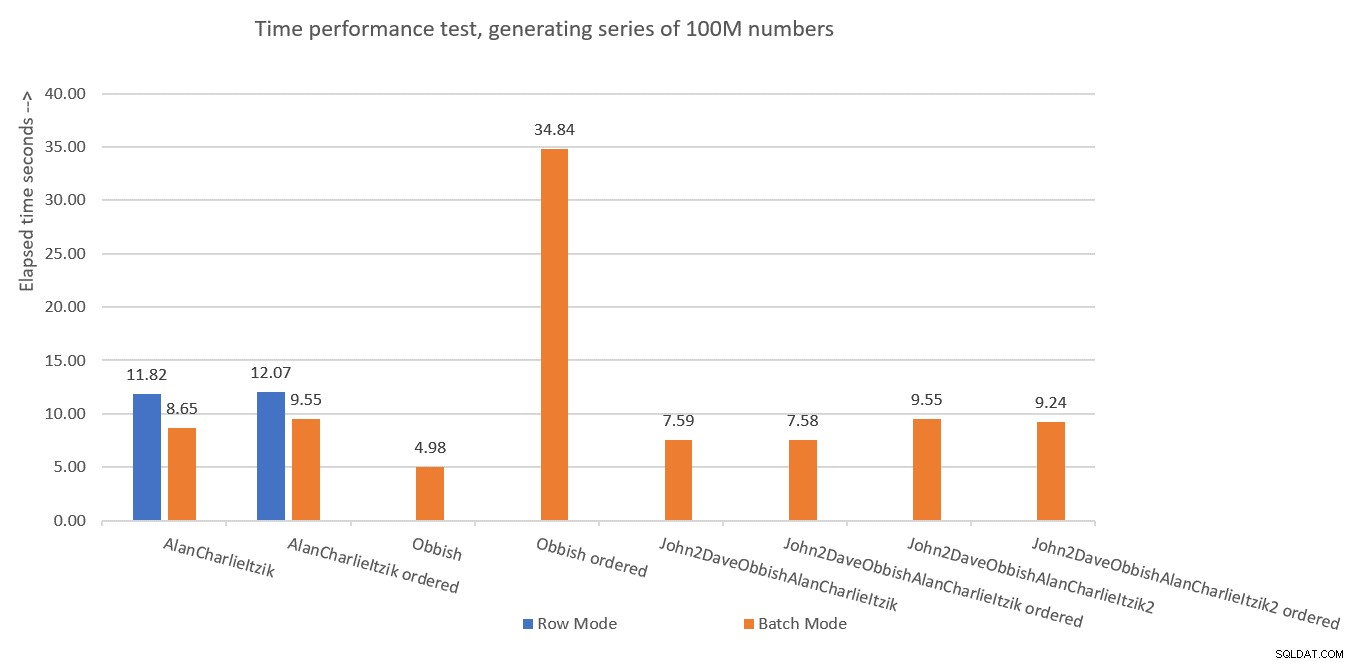 Figure 7:Time performance summary of solutions
Figure 7:Time performance summary of solutions
Figure 8 has a summary of the I/O statistics.
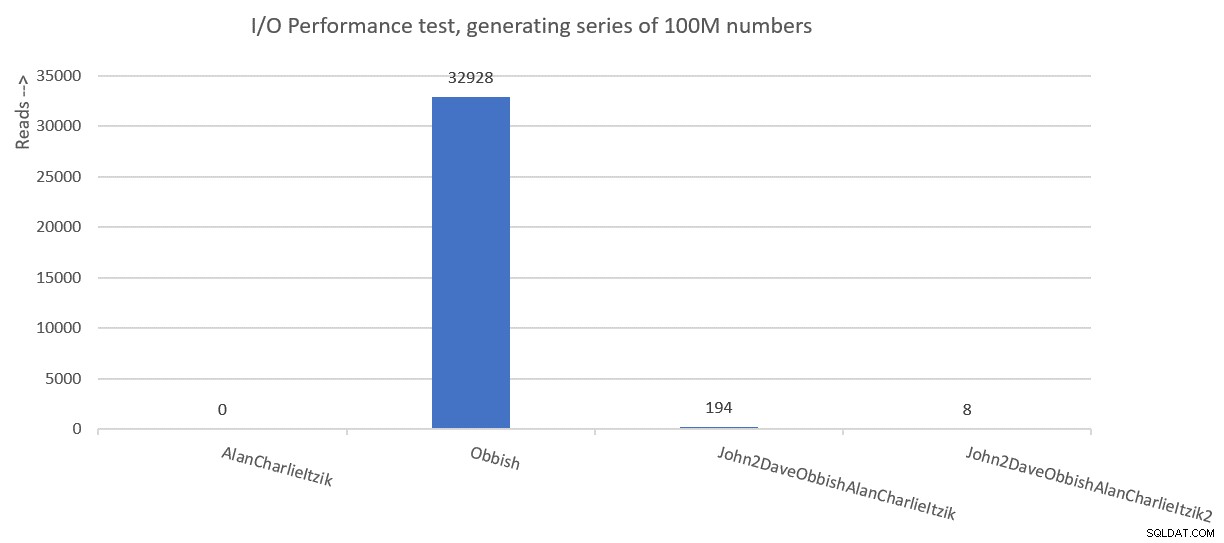 Figure 8:I/O performance summary of solutions
Figure 8:I/O performance summary of solutions
Thanks to all of you who posted ideas and suggestions in effort to create a fast number series generator. It’s a great learning experience!
We’re not done yet. Next month I’ll continue exploring additional solutions.