Este artículo es la quinta parte de una serie sobre expresiones de tablas. En la Parte 1 proporcioné los antecedentes de las expresiones de tabla. En las Partes 2, 3 y 4, cubrí los aspectos lógicos y de optimización de las tablas derivadas. Este mes empiezo la cobertura de expresiones de tabla comunes (CTE). Al igual que con las tablas derivadas, primero abordaré el tratamiento lógico de CTE y, en el futuro, abordaré las consideraciones de optimización.
En mis ejemplos, usaré una base de datos de muestra llamada TSQLV5. Puede encontrar el script que lo crea y lo completa aquí, y su diagrama ER aquí.
CTEs
Comencemos con el término expresión de tabla común . Ni este término ni su acrónimo CTE aparecen en las especificaciones del estándar ISO/IEC SQL. Entonces, podría ser que el término se originó en uno de los productos de base de datos y luego fue adoptado por algunos de los otros proveedores de bases de datos. Puede encontrarlo en la documentación de Microsoft SQL Server y Azure SQL Database. T-SQL lo admite a partir de SQL Server 2005. El estándar usa el término expresión de consulta para representar una expresión que define una o más CTE, incluida la consulta externa. Utiliza el término con elemento de lista para representar lo que T-SQL llama un CTE. Proporcionaré la sintaxis para una expresión de consulta en breve.
Aparte del origen del término, expresión de tabla común , o CET , es el término comúnmente utilizado por los profesionales de T-SQL para la estructura en la que se centra este artículo. Entonces, primero, abordemos si es un término apropiado. Ya concluimos que el término expresión de tabla es apropiado para una expresión que conceptualmente devuelve una tabla. Las tablas derivadas, CTE, vistas y funciones con valores de tabla en línea son todos tipos de expresiones de tabla con nombre que admite T-SQL. Entonces, la expresión de tabla parte de expresión de tabla común ciertamente parece apropiado. En cuanto a lo común parte del término, probablemente tenga que ver con una de las ventajas de diseño de los CTE sobre las tablas derivadas. Recuerde que no puede reutilizar el nombre de la tabla derivada (o más exactamente, el nombre de la variable de rango) más de una vez en la consulta externa. Por el contrario, el nombre de CTE se puede usar varias veces en la consulta externa. En otras palabras, el nombre de CTE es común a la consulta externa. Por supuesto, demostraré este aspecto del diseño en este artículo.
Los CTE le brindan beneficios similares a las tablas derivadas, incluida la habilitación del desarrollo de soluciones modulares, la reutilización de alias de columna, la interacción indirecta con funciones de ventana en cláusulas que normalmente no las permiten, la compatibilidad con modificaciones que dependen indirectamente de TOP o OFFSET FETCH con especificación de orden, y otros. Pero hay ciertas ventajas de diseño en comparación con las tablas derivadas, que cubriré en detalle después de proporcionar la sintaxis de la estructura.
Sintaxis
Esta es la sintaxis estándar para una expresión de consulta:
7.17
Función
Especifique una tabla.
Formato
[
[
AS
|
[
|
[
|
[
|
[
CORRESPONDING [ BY
FETCH { PRIMERO | SIGUIENTE } [
|
7.18
Función
Especificar la generación de información de detección de pedidos y ciclos en el resultado de expresiones de consulta recursivas.
Formato
SEARCH
PROFUNDIDAD PRIMERO POR
CYCLE
DEFAULT
7.3
Función
Especifique un conjunto de
El término estándar expresión de consulta representa una expresión que implica una cláusula WITH, una lista with , que está compuesto por uno o más elementos with list y una consulta externa. T-SQL se refiere al estándar con elemento de lista como CTE.
T-SQL no admite todos los elementos de sintaxis estándar. Por ejemplo, no admite algunos de los elementos de consulta recursiva más avanzados que le permiten controlar la dirección de búsqueda y manejar los ciclos en una estructura gráfica. Las consultas recursivas son el foco del artículo del próximo mes.
Esta es la sintaxis de T-SQL para una consulta simplificada contra un CTE:
Aquí hay un ejemplo de una consulta simple contra un CTE que representa a clientes de EE. UU.:
Encontrará las mismas tres partes en una declaración contra un CTE como lo haría con una declaración contra una tabla derivada:
Lo que es diferente sobre el diseño de CTE en comparación con las tablas derivadas es dónde se ubican estos tres elementos en el código. Con las tablas derivadas, la consulta interna se anida dentro de la cláusula FROM de la consulta externa y el nombre de la expresión de la tabla se asigna después de la propia expresión de la tabla. Los elementos están como entrelazados. Por el contrario, con CTE, el código separa los tres elementos:primero asigna el nombre de la expresión de la tabla; segundo, especifica la expresión de la tabla, de principio a fin sin interrupciones; en tercer lugar, especifica la consulta externa, de principio a fin sin interrupciones. Más adelante, en "Consideraciones de diseño", explicaré las implicaciones de estas diferencias de diseño.
Una palabra sobre CTE y el uso de un punto y coma como terminador de declaración. Desafortunadamente, a diferencia del SQL estándar, T-SQL no lo obliga a terminar todas las declaraciones con un punto y coma. Sin embargo, hay muy pocos casos en T-SQL en los que, sin un terminador, el código sea ambiguo. En esos casos, la terminación es obligatoria. Uno de esos casos se refiere al hecho de que la cláusula WITH se usa para múltiples propósitos. Una es definir un CTE, otra es definir una sugerencia de tabla para una consulta y hay algunos casos de uso adicionales. Como ejemplo, en la siguiente declaración, la cláusula WITH se usa para forzar el nivel de aislamiento serializable con una sugerencia de tabla:
La posibilidad de ambigüedad es cuando tiene una declaración no terminada que precede a una definición de CTE, en cuyo caso es posible que el analizador no pueda determinar si la cláusula WITH pertenece a la primera o a la segunda declaración. Aquí hay un ejemplo que demuestra esto:
Aquí, el analizador no puede decir si se supone que la cláusula WITH debe usarse para definir una sugerencia de tabla para la tabla Customers en la primera instrucción o iniciar una definición de CTE. Obtiene el siguiente error:
La solución es, por supuesto, finalizar la declaración que precede a la definición de CTE, pero como mejor práctica, realmente debería finalizar todas sus declaraciones:
Es posible que haya notado que algunas personas comienzan sus definiciones de CTE con un punto y coma como práctica, así:
El objetivo de esta práctica es reducir la posibilidad de errores futuros. ¿Qué sucede si en un momento posterior alguien agrega una declaración sin terminar justo antes de su definición de CTE en el script y no se molesta en verificar el script completo, sino solo su declaración? Su punto y coma justo antes de la cláusula WITH se convierte efectivamente en el terminador de su declaración. Ciertamente puedes ver la practicidad de esta práctica, pero es un poco antinatural. Lo que se recomienda, aunque más difícil de lograr, es inculcar buenas prácticas de programación en la organización, incluida la terminación de todas las declaraciones.
En cuanto a las reglas de sintaxis que se aplican a la expresión de tabla utilizada como consulta interna en la definición de CTE, son las mismas que se aplican a la expresión de tabla utilizada como consulta interna en una definición de tabla derivada. Esos son:
Para obtener más información, consulte la sección "Una expresión de tabla es una tabla" en la Parte 2 de la serie.
Si encuesta a desarrolladores de T-SQL experimentados sobre si prefieren usar tablas derivadas o CTE, no todos estarán de acuerdo en cuál es mejor. Naturalmente, diferentes personas tienen diferentes preferencias de estilo. A veces uso tablas derivadas y, a veces, CTE. Es bueno poder identificar conscientemente las diferencias de diseño de lenguaje específico entre las dos herramientas y elegir en función de sus prioridades en cualquier solución dada. Con el tiempo y la experiencia, toma sus decisiones de forma más intuitiva.
Además, es importante no confundir el uso de expresiones de tabla y tablas temporales, pero esa es una discusión relacionada con el rendimiento que abordaré en un artículo futuro.
Los CTE tienen capacidades de consulta recursiva y las tablas derivadas no. Entonces, si necesita confiar en ellos, naturalmente elegiría CTE. Las consultas recursivas son el foco del artículo del próximo mes.
En la Parte 2 expliqué que veo el anidamiento de tablas derivadas como algo que agrega complejidad al código, ya que dificulta seguir la lógica. Proporcioné el siguiente ejemplo, identificando los años de pedido en los que más de 70 clientes realizaron pedidos:
Los CTE no admiten la anidación. Entonces, cuando revisa o soluciona problemas de una solución basada en CTE, no se pierde en la lógica anidada. En lugar de anidar, crea más soluciones modulares definiendo múltiples CTE bajo la misma instrucción WITH, separados por comas. Cada uno de los CTE se basa en una consulta que se escribe de principio a fin sin interrupciones. Lo veo como algo bueno desde la perspectiva de la claridad del código y la facilidad de mantenimiento.
Aquí hay una solución a la tarea antes mencionada usando CTE:
Me gusta más la solución basada en CTE. Pero nuevamente, pregunte a los desarrolladores experimentados cuál de las dos soluciones anteriores prefieren, y no todos estarán de acuerdo. Algunos prefieren la lógica anidada y poder ver todo en un solo lugar.
Una ventaja muy clara de los CTE sobre las tablas derivadas es cuando necesita interactuar con varias instancias de la misma expresión de tabla en su solución. Recuerde el siguiente ejemplo basado en tablas derivadas de la Parte 2 de la serie:
Esta solución devuelve años de pedidos, recuentos de pedidos por año y la diferencia entre los recuentos del año actual y del año anterior. Sí, podría hacerlo más fácilmente con la función LAG, pero mi enfoque aquí no es encontrar la mejor manera de lograr esta tarea tan específica. Utilizo este ejemplo para ilustrar ciertos aspectos del diseño del lenguaje de las expresiones de tabla con nombre.
El problema con esta solución es que no puede asignar un nombre a una expresión de tabla y reutilizarla en el mismo paso de procesamiento de consultas lógicas. Una tabla derivada se nombra después de la propia expresión de la tabla en la cláusula FROM. Si define y asigna un nombre a una tabla derivada como la primera entrada de una combinación, no puede reutilizar ese nombre de tabla derivada como la segunda entrada de la misma combinación. Si necesita unir dos instancias de la misma expresión de tabla, con las tablas derivadas no tiene más remedio que duplicar el código. Eso es lo que hiciste en el ejemplo anterior. Por el contrario, el nombre de CTE se asigna como el primer elemento del código entre los tres anteriores (nombre de CTE, consulta interna, consulta externa). En términos de procesamiento de consultas lógicas, cuando llega a la consulta externa, el nombre de CTE ya está definido y disponible. Esto significa que puede interactuar con varias instancias del nombre CTE en la consulta externa, así:
Esta solución tiene una clara ventaja de programabilidad con respecto a la que se basa en tablas derivadas, ya que no es necesario mantener dos copias de la misma expresión de tabla. Hay más que decir al respecto desde la perspectiva del procesamiento físico y compararlo con el uso de tablas temporales, pero lo haré en un artículo futuro que se centre en el rendimiento.
Una ventaja que tiene el código basado en tablas derivadas en comparación con el código basado en CTE tiene que ver con la propiedad de cierre que se supone que posee una expresión de tabla. Recuerde que la propiedad de cierre de una expresión relacional dice que tanto las entradas como la salida son relaciones y que, por lo tanto, se puede usar una expresión relacional donde se espera una relación, como entrada para otra expresión relacional. De manera similar, una expresión de tabla devuelve una tabla y se supone que está disponible como tabla de entrada para otra expresión de tabla. Esto es cierto para una consulta que se basa en tablas derivadas; puede usarla donde se espera una tabla. Por ejemplo, puede utilizar una consulta basada en tablas derivadas como la consulta interna de una definición de CTE, como en el siguiente ejemplo:
Sin embargo, no ocurre lo mismo con una consulta basada en CTE. Aunque conceptualmente se supone que se considera una expresión de tabla, no puede usarla como consulta interna en definiciones de tablas derivadas, subconsultas y CTE en sí. Por ejemplo, el siguiente código no es válido en T-SQL:
La buena noticia es que puede usar una consulta basada en CTE como consulta interna en vistas y funciones con valores de tabla en línea, que trataré en artículos futuros.
Además, recuerde que siempre puede definir otro CTE basado en la última consulta y luego hacer que la consulta más externa interactúe con ese CTE:
Desde el punto de vista de la solución de problemas, como se mencionó, generalmente me resulta más fácil seguir la lógica del código que se basa en CTE, en comparación con el código basado en tablas derivadas. Sin embargo, las soluciones basadas en tablas derivadas tienen la ventaja de que puede resaltar cualquier nivel de anidamiento y ejecutarlo de forma independiente, como se muestra en la Figura 1.
Con CTE las cosas son más complicadas. Para que el código que involucra CTE sea ejecutable, debe comenzar con una cláusula WITH, seguida de una o más expresiones de tabla entre paréntesis separadas por comas, seguidas de una consulta sin paréntesis sin coma precedente. Puede resaltar y ejecutar cualquiera de las consultas internas que son realmente independientes, así como el código de la solución completa; sin embargo, no puede resaltar y ejecutar correctamente ninguna otra parte intermedia de la solución. Por ejemplo, la Figura 2 muestra un intento fallido de ejecutar el código que representa a C2.
Entonces, con CTE, debe recurrir a medios algo incómodos para poder solucionar un paso intermedio de la solución. Por ejemplo, una solución común es inyectar temporalmente una consulta SELECT * FROM your_cte justo debajo de la CTE relevante. Luego, resalta y ejecuta el código que incluye la consulta inyectada y, cuando haya terminado, elimina la consulta inyectada. La Figura 3 demuestra esta técnica.
El problema es que cada vez que realiza cambios en el código, incluso cambios menores temporales como los anteriores, existe la posibilidad de que cuando intente volver al código original, termine introduciendo un nuevo error.
Otra opción es diseñar su código de manera un poco diferente, de modo que cada definición de CTE que no sea la primera comience con una línea de código separada que se vea así:
Luego, cada vez que desee ejecutar una parte intermedia del código hasta un CTE determinado, puede hacerlo con cambios mínimos en su código. Al usar un comentario de línea, comenta solo esa línea de código que corresponde a ese CTE. Luego, resalta y ejecuta el código hasta incluir la consulta interna de CTE, que ahora se considera la consulta más externa, como se ilustra en la Figura 4.
Si no estás satisfecho con este estilo, tienes otra opción. Puede usar un comentario de bloque que comience justo antes de la coma que precede a la CTE de interés y finalice después del paréntesis de apertura, como se ilustra en la Figura 5.
Se reduce a preferencias personales. Por lo general, uso la técnica de consulta SELECT * inyectada temporalmente.
Hay una cierta limitación en la compatibilidad de T-SQL con los constructores de valores de tabla en comparación con el estándar. Si no está familiarizado con la construcción, asegúrese de consultar primero la Parte 2 de la serie, donde la describo en detalle. Mientras que T-SQL le permite definir una tabla derivada basada en un constructor de valores de tabla, no le permite definir un CTE basado en un constructor de valores de tabla.
Aquí hay un ejemplo compatible que usa una tabla derivada:
Desafortunadamente, no se admite un código similar que use un CTE:
Este código genera el siguiente error:
Sin embargo, hay un par de soluciones. Una es usar una consulta contra una tabla derivada, que a su vez se basa en un constructor de valores de tabla, como la consulta interna de CTE, así:
Otra es recurrir a la técnica que la gente usaba antes de que se introdujeran los constructores con valores de tabla en T-SQL, usando una serie de consultas FROMless separadas por operadores UNION ALL, así:
Observe que los alias de columna se asignan justo después del nombre de CTE.
Los dos métodos se algebrizan y optimizan de la misma manera, así que use el que le resulte más cómodo.
Una herramienta que utilizo con bastante frecuencia en mis soluciones es una tabla auxiliar de números. Una opción es crear una tabla de números reales en su base de datos y llenarla con una secuencia de tamaño razonable. Otra es desarrollar una solución que produzca una secuencia de números sobre la marcha. Para la última opción, desea que las entradas sean los delimitadores del rango deseado (los llamaremos
Este código genera el siguiente resultado:
El primer CTE llamado L0 se basa en un constructor de valores de tabla con dos filas. Los valores reales allí son insignificantes; lo importante es que tiene dos filas. Luego, hay una secuencia de cinco CTE adicionales denominados L1 a L5, cada uno de los cuales aplica una unión cruzada entre dos instancias del CTE anterior. El siguiente código calcula el número de filas potencialmente generadas por cada uno de los CTE, donde @L es el número de nivel de CTE:
Estos son los números que obtienes para cada CTE:
Subir al nivel 5 te da más de cuatro mil millones de filas. Esto debería ser suficiente para cualquier caso de uso práctico que se me ocurra. El siguiente paso tiene lugar en el CTE denominado Nums. Utiliza una función ROW_NUMBER para generar una secuencia de números enteros que comienzan con 1 en función de un orden no definido (ORDER BY (SELECT NULL)), y nombra la columna de resultados número de fila. Finalmente, la consulta externa usa un filtro TOP basado en el ordenamiento de filas para filtrar tantos números como la cardinalidad de secuencia deseada (@alto – @bajo + 1) y calcula el número de resultado n como @bajo + filas – 1.
Aquí puede apreciar realmente la belleza del diseño de CTE y los ahorros que permite cuando construye soluciones de forma modular. En última instancia, el proceso de anidamiento desempaqueta 32 tablas, cada una de las cuales consta de dos filas basadas en constantes. Esto se puede ver claramente en el plan de ejecución de este código, como se muestra en la Figura 6 usando SentryOne Plan Explorer.
Cada operador Constant Scan representa una tabla de constantes con dos filas. La cuestión es que el operador Top es el que solicita esas filas y hace un cortocircuito después de obtener el número deseado. Observe las 10 filas indicadas arriba de la flecha que fluye hacia el operador Superior.
Sé que el enfoque de este artículo es el tratamiento conceptual de los CTE y no las consideraciones físicas o de rendimiento, pero al observar el plan, realmente puede apreciar la brevedad del código en comparación con la extensión de lo que se traduce entre bastidores.
Usando tablas derivadas, puede escribir una solución que sustituya cada referencia CTE con la consulta subyacente que representa. Lo que obtienes es bastante aterrador:
Obviously, you don’t want to write a solution like this, but it’s a good way to illustrate what SQL Server does behind the scenes with your CTE code.
If you were really planning to write a solution based on derived tables, instead of using the above nested approach, you’d be better off simplifying the logic to a single query with 31 cross joins between 32 table value constructors, each based on two rows, like so:
Still, the solution based on CTEs is obviously significantly simpler. The plans are identical.
CTEs can be used as the source and target tables in INSERT, UPDATE, DELETE and MERGE statements. They cannot be used in the TRUNCATE statement.
The syntax is pretty straightforward. You start the statement as usual with a WITH clause, followed by one or more CTEs separated by commas. Then you specify the outer modification statement, which interacts with the CTEs that were defined under the WITH clause as the source tables, target table, or both. Just like I explained in Part 2 about derived tables, also with CTEs what really gets modified is the underlying base table that the table expression uses. I’ll show a couple of examples using DELETE and UPDATE statements, but remember that you can use CTEs in MERGE and INSERT statements as well.
Here’s the general syntax of a DELETE statement against a CTE:
As an example (don’t actually run it), the following code deletes the 10 oldest orders:
Here’s the general syntax of an UPDATE statement against a CTE:
As an example, the following code updates the 10 oldest unshipped orders that have an overdue required date, increasing the required date to 10 days from today:
The code applies the update in a transaction that it then rolls back so that the change won’t stick.
This code generates the following output, showing both the old and the new required dates:
Of course you will get a different new required date based on when you run this code.
I like CTEs. They have a few advantages compared to derived tables. Instead of nesting the code, you define multiple CTEs separated by commas, typically leading to a more modular solution that is easier to review and maintain. Also, you can have multiple references to the same CTE name in the outer statement, so you don’t need to repeat the inner table expression’s code. However, unlike derived tables, CTEs cannot be defined directly based on a table value constructor, and you cannot highlight and execute some of the intermediate parts of the code. The following table summarizes the differences between derived tables and CTEs:
As the last item says, derived tables do not support recursive capabilities, whereas CTEs do. Recursive queries are the focus of next month’s article.
Formato
VALUES
[ { WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
SELECT < select list >
FROM < table name >;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
SELECT custid, country FROM Sales.Customers WITH (SERIALIZABLE);
SELECT custid, country FROM Sales.Customers
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC
Sintaxis incorrecta cerca de 'UC'. Si se pretende que sea una expresión de tabla común, debe terminar explícitamente la declaración anterior con un punto y coma. SELECT custid, country FROM Sales.Customers;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
;WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
Consideraciones de diseño
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70;
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM ( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS CUR
LEFT OUTER JOIN
( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH OrdCount AS
(
SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate)
)
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM OrdCount AS CUR
LEFT OUTER JOIN OrdCount AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH C AS
(
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C; SELECT orderyear, custid
FROM (WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70) AS D; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
),
C3 AS
(
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C3;
 Figura 1:Puede resaltar y ejecutar parte del código con tablas derivadas
Figura 1:Puede resaltar y ejecutar parte del código con tablas derivadas  Figura 2:No se puede resaltar y ejecutar parte del código con CTE
Figura 2:No se puede resaltar y ejecutar parte del código con CTE  Figura 3:Inyecte SELECT * debajo de CTE relevante
Figura 3:Inyecte SELECT * debajo de CTE relevante , cte_name AS (
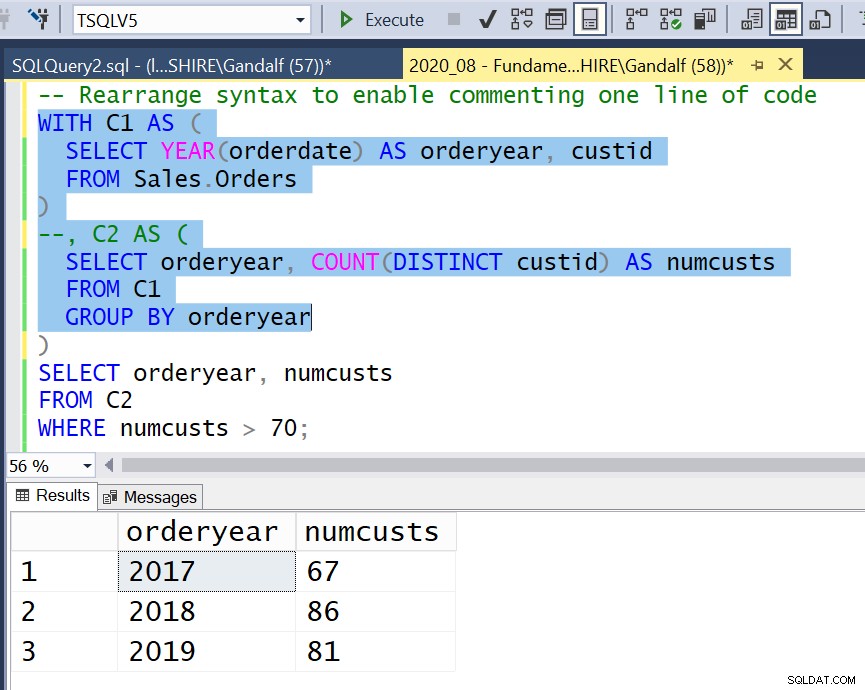 Figura 4:Reorganizar la sintaxis para permitir comentar una línea de código
Figura 4:Reorganizar la sintaxis para permitir comentar una línea de código  Figura 5:Usar comentario de bloque
Figura 5:Usar comentario de bloque Constructor de valores de tabla
SELECT custid, companyname, contractdate
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate); WITH MyCusts(custid, companyname, contractdate) AS
(
VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' )
)
SELECT custid, companyname, contractdate
FROM MyCusts;
Sintaxis incorrecta cerca de la palabra clave 'VALORES'. WITH MyCusts AS
(
SELECT *
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate)
)
SELECT custid, companyname, contractdate
FROM MyCusts; WITH MyCusts(custid, companyname, contractdate) AS
(
SELECT 2, 'Cust 2', '20200212'
UNION ALL SELECT 3, 'Cust 3', '20200118'
UNION ALL SELECT 5, 'Cust 5', '20200401'
)
SELECT custid, companyname, contractdate
FROM MyCusts; Producir una secuencia de números
@low y @high ). Desea que su solución admita rangos potencialmente grandes. Aquí está mi solución para este propósito, usando CTE, con una solicitud para el rango de 1001 a 1010 en este ejemplo específico:DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; n
-----
1001
1002
1003
1004
1005
1006
1007
1008
1009
1010
DECLARE @L AS INT = 5;
SELECT POWER(2., POWER(2., @L));
CTE Cardinalidad L0 2 L1 4 L2 16 L3 256 L4 65.536 L5 4,294,967,296  Figura 6:Plan para la secuencia de números de generación de consultas
Figura 6:Plan para la secuencia de números de generación de consultas DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D9
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D10 ) AS Nums
ORDER BY rownum; DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN (VALUES(1),(1)) AS D02(c)
CROSS JOIN (VALUES(1),(1)) AS D03(c)
CROSS JOIN (VALUES(1),(1)) AS D04(c)
CROSS JOIN (VALUES(1),(1)) AS D05(c)
CROSS JOIN (VALUES(1),(1)) AS D06(c)
CROSS JOIN (VALUES(1),(1)) AS D07(c)
CROSS JOIN (VALUES(1),(1)) AS D08(c)
CROSS JOIN (VALUES(1),(1)) AS D09(c)
CROSS JOIN (VALUES(1),(1)) AS D10(c)
CROSS JOIN (VALUES(1),(1)) AS D11(c)
CROSS JOIN (VALUES(1),(1)) AS D12(c)
CROSS JOIN (VALUES(1),(1)) AS D13(c)
CROSS JOIN (VALUES(1),(1)) AS D14(c)
CROSS JOIN (VALUES(1),(1)) AS D15(c)
CROSS JOIN (VALUES(1),(1)) AS D16(c)
CROSS JOIN (VALUES(1),(1)) AS D17(c)
CROSS JOIN (VALUES(1),(1)) AS D18(c)
CROSS JOIN (VALUES(1),(1)) AS D19(c)
CROSS JOIN (VALUES(1),(1)) AS D20(c)
CROSS JOIN (VALUES(1),(1)) AS D21(c)
CROSS JOIN (VALUES(1),(1)) AS D22(c)
CROSS JOIN (VALUES(1),(1)) AS D23(c)
CROSS JOIN (VALUES(1),(1)) AS D24(c)
CROSS JOIN (VALUES(1),(1)) AS D25(c)
CROSS JOIN (VALUES(1),(1)) AS D26(c)
CROSS JOIN (VALUES(1),(1)) AS D27(c)
CROSS JOIN (VALUES(1),(1)) AS D28(c)
CROSS JOIN (VALUES(1),(1)) AS D29(c)
CROSS JOIN (VALUES(1),(1)) AS D30(c)
CROSS JOIN (VALUES(1),(1)) AS D31(c)
CROSS JOIN (VALUES(1),(1)) AS D32(c) ) AS Nums
ORDER BY rownum; Used in modification statements
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
DELETE [ FROM ] <table name>
[ WHERE <filter predicate> ];
WITH OldestOrders AS
(
SELECT TOP (10) *
FROM Sales.Orders
ORDER BY orderdate, orderid
)
DELETE FROM OldestOrders;
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
UPDATE <table name>
SET <assignments>
[ WHERE <filter predicate> ];
BEGIN TRAN;
WITH OldestUnshippedOrders AS
(
SELECT TOP (10) orderid, requireddate,
DATEADD(day, 10, CAST(SYSDATETIME() AS DATE)) AS newrequireddate
FROM Sales.Orders
WHERE shippeddate IS NULL
AND requireddate < CAST(SYSDATETIME() AS DATE)
ORDER BY orderdate, orderid
)
UPDATE OldestUnshippedOrders
SET requireddate = newrequireddate
OUTPUT
inserted.orderid,
deleted.requireddate AS oldrequireddate,
inserted.requireddate AS newrequireddate;
ROLLBACK TRAN; orderid oldrequireddate newrequireddate
----------- --------------- ---------------
11008 2019-05-06 2020-07-16
11019 2019-05-11 2020-07-16
11039 2019-05-19 2020-07-16
11040 2019-05-20 2020-07-16
11045 2019-05-21 2020-07-16
11051 2019-05-25 2020-07-16
11054 2019-05-26 2020-07-16
11058 2019-05-27 2020-07-16
11059 2019-06-10 2020-07-16
11061 2019-06-11 2020-07-16
(10 rows affected)
Resumen
Item Derived table CTE Supports nesting Sí No Supports multiple references No Sí Supports table value constructor Sí No Can highlight and run part of code Sí No Supports recursion No Sí