Creo que todo el mundo ya conoce mis opiniones sobre MERGE y por qué me mantengo alejado de eso. Pero aquí hay otro (anti-) patrón que veo por todas partes cuando la gente quiere realizar un upsert (actualice una fila si existe e insértela si no):
IF EXISTS (SELECT 1 FROM dbo.t WHERE [key] = @key) BEGIN UPDATE dbo.t SET val = @val WHERE [key] = @key; END ELSE BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END
Esto parece un flujo bastante lógico que refleja cómo pensamos sobre esto en la vida real:
- ¿Ya existe una fila para esta clave?
- SÍ :OK, actualice esa fila.
- NO :OK, luego agréguelo.
Pero esto es un desperdicio.
Ubicar la fila para confirmar que existe, solo para tener que ubicarla nuevamente para actualizarla, es hacer el doble de trabajo para nada. Incluso si la clave está indexada (que espero que sea siempre el caso). Si pongo esta lógica en un diagrama de flujo y asocio, en cada paso, el tipo de operación que tendría que ocurrir dentro de la base de datos, tendría esto:
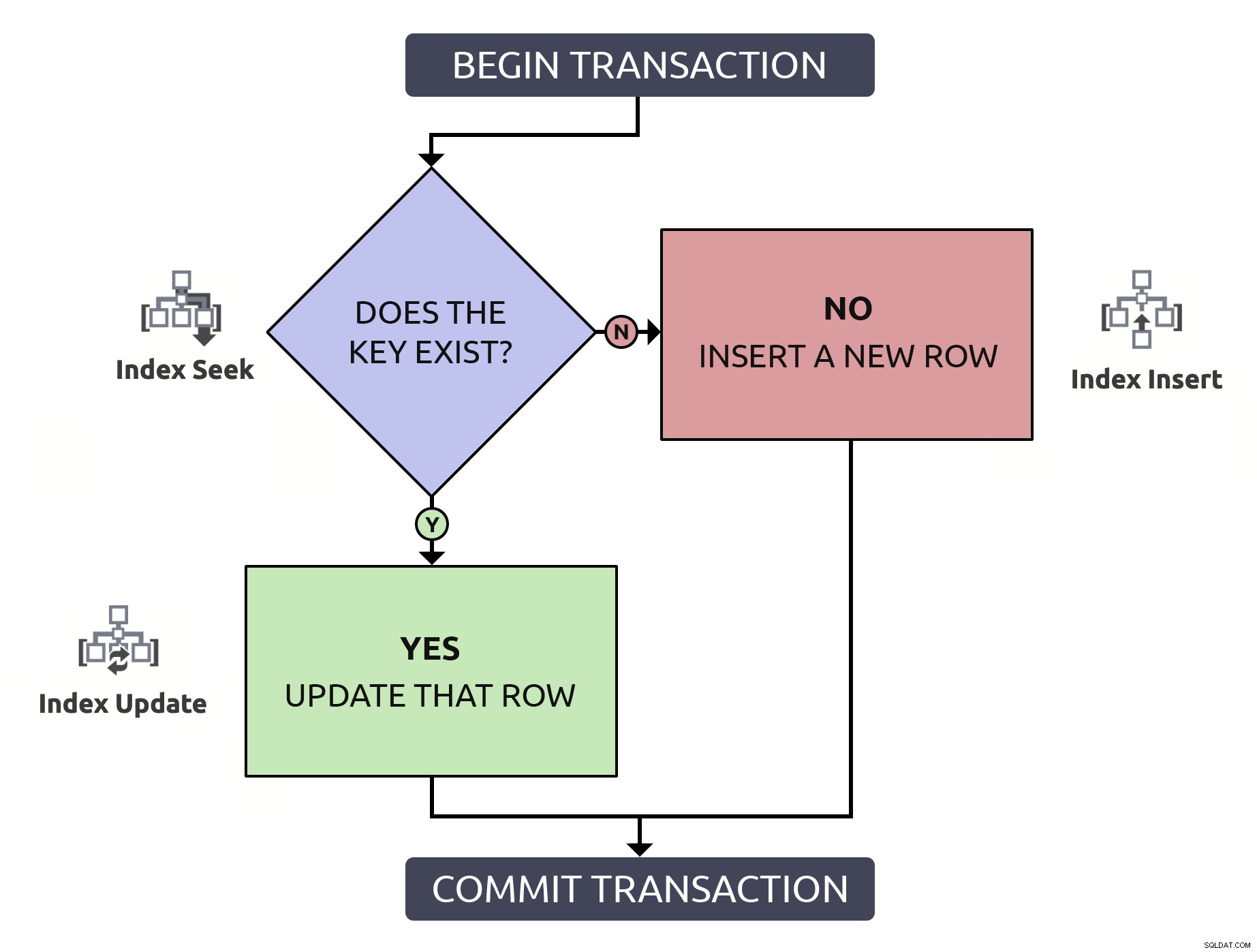 Observe que todas las rutas incurrirán en dos operaciones de índice.
Observe que todas las rutas incurrirán en dos operaciones de índice.
Más importante aún, aparte del rendimiento, a menos que use una transacción explícita y eleve el nivel de aislamiento, varias cosas podrían salir mal cuando la fila aún no existe:
- Si la clave existe y dos sesiones intentan actualizarse simultáneamente, ambas se actualizarán correctamente (uno "ganará"; el "perdedor" seguirá con el cambio que se mantiene, lo que lleva a una "actualización perdida"). Esto no es un problema en sí mismo, y es como deberíamos esperar que funcione un sistema con concurrencia. Paul White habla sobre la mecánica interna con mayor detalle aquí, y Martin Smith habla sobre algunos otros matices aquí.
- Si la clave no existe, pero ambas sesiones pasan la verificación de existencia de la misma manera, podría pasar cualquier cosa cuando ambas intenten insertar:
- punto muerto debido a bloqueos incompatibles;
- generar errores clave de infracción eso no debería haber sucedido; o,
- insertar valores clave duplicados si esa columna no está restringida correctamente.
Ese último es el peor, en mi humilde opinión, porque es el que potencialmente corrompe los datos . Los interbloqueos y las excepciones se pueden manejar fácilmente con cosas como el manejo de errores, XACT_ABORT y la lógica de reintento, según la frecuencia con la que espere colisiones. Pero si se deja llevar por la sensación de seguridad de que IF EXISTS check lo protege de duplicados (o violaciones de claves), que es una sorpresa esperando a suceder. Si espera que una columna actúe como una clave, hágalo oficial y agregue una restricción.
"Mucha gente dice..."
Dan Guzman habló sobre las condiciones de carrera hace más de una década en Condición de carrera INSERTAR/ACTUALIZAR condicional y más tarde en Condición de carrera "UPSERT" con MERGE.
Michael Swart también ha tratado este tema varias veces:
- Destrucción de mitos:actualización simultánea/soluciones de inserción:donde reconoció que dejar la lógica inicial en su lugar y solo elevar el nivel de aislamiento solo cambió las infracciones clave a interbloqueos;
- Tenga cuidado con la Declaración de fusión:donde comprobó su entusiasmo por
MERGE; y, - Qué evitar si desea usar MERGE, donde confirmó una vez más que todavía hay muchas razones válidas para continuar evitando
MERGE.
Asegúrate de leer también todos los comentarios en las tres publicaciones.
La solución
He solucionado muchos puntos muertos en mi carrera simplemente ajustándome al siguiente patrón (eliminar el cheque redundante, envolver la secuencia en una transacción y proteger el primer acceso a la tabla con el bloqueo adecuado):
BEGIN TRANSACTION; UPDATE dbo.t WITH (UPDLOCK, SERIALIZABLE) SET val = @val WHERE [key] = @key; IF @@ROWCOUNT = 0 BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END COMMIT TRANSACTION;
¿Por qué necesitamos dos pistas? No es UPDLOCK suficiente?
UPDLOCKse utiliza para proteger contra bloqueos de conversión en la declaración nivel (deje que otra sesión espere en lugar de animar a la víctima a que vuelva a intentarlo).SERIALIZABLEse utiliza para proteger contra cambios en los datos subyacentes a lo largo de la transacción (asegúrese de que una fila que no existe siga sin existir).
Es un poco más de código, pero es 1000% más seguro, e incluso en el peor caso (la fila aún no existe), realiza lo mismo que el antipatrón. En el mejor de los casos, si está actualizando una fila que ya existe, será más eficiente ubicar esa fila solo una vez. Combinando esta lógica con las operaciones de alto nivel que tendrían que ocurrir en la base de datos, es un poco más simple:
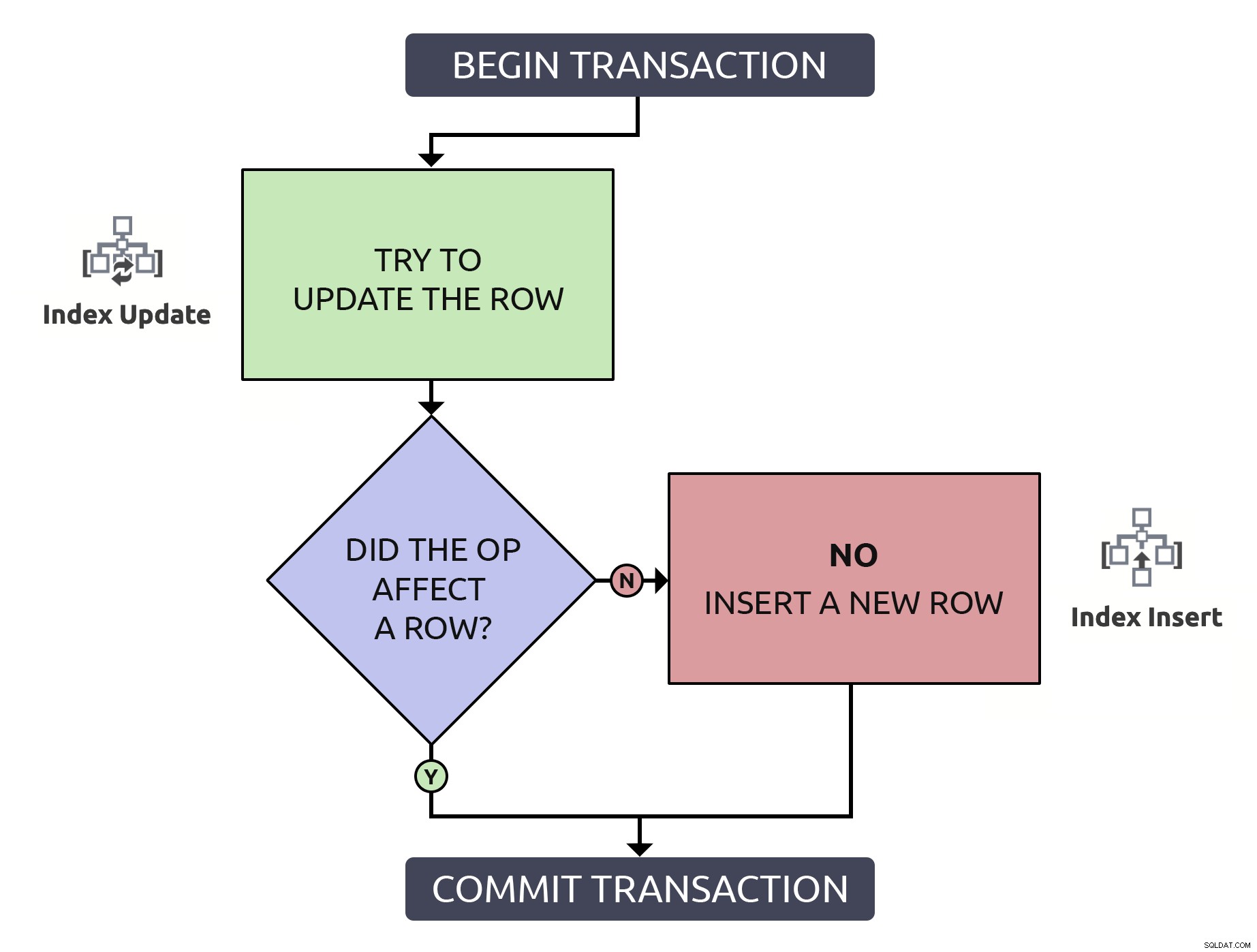 En este caso, una ruta solo incurre en una sola operación de índice.
En este caso, una ruta solo incurre en una sola operación de índice.
Pero de nuevo, aparte del rendimiento:
- Si la clave existe y dos sesiones intentan actualizarla al mismo tiempo, ambas se alternarán y actualizarán la fila con éxito , como antes.
- Si la clave no existe, una sesión "ganará" e insertará la fila . El otro tendrá que esperar hasta que se liberen los bloqueos para incluso verificar su existencia y se vean obligados a actualizar.
En ambos casos, el escritor que ganó la carrera pierde sus datos por cualquier cosa que el "perdedor" actualice después de ellos.
Tenga en cuenta que el rendimiento general en un sistema altamente concurrente podría sufrir, pero ese es un compromiso que deberías estar dispuesto a hacer. El hecho de que tenga muchas víctimas de interbloqueo o errores de violación de clave, pero que sucedan rápidamente, no es una buena métrica de rendimiento. A algunas personas les encantaría que se eliminaran todos los bloqueos de todos los escenarios, pero algunos de ellos son los bloqueos que absolutamente desea para la integridad de los datos.
¿Pero qué sucede si es menos probable una actualización?
Está claro que la solución anterior se optimiza para las actualizaciones y asume que una clave en la que está tratando de escribir ya existirá en la tabla al menos con tanta frecuencia como no. Si prefiere optimizar para las inserciones, sabiendo o adivinando que las inserciones serán más probables que las actualizaciones, puede cambiar la lógica y aún tener una operación upsert segura:
BEGIN TRANSACTION;
INSERT dbo.t([key], val)
SELECT @key, @val
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.t WITH (UPDLOCK, SERIALIZABLE)
WHERE [key] = @key
);
IF @@ROWCOUNT = 0
BEGIN
UPDATE dbo.t SET val = @val WHERE [key] = @key;
END
COMMIT TRANSACTION; También existe el enfoque de "simplemente hazlo", en el que insertas ciegamente y dejas que las colisiones generen excepciones para la persona que llama:
BEGIN TRANSACTION; BEGIN TRY INSERT dbo.t([key], val) VALUES(@key, @val); END TRY BEGIN CATCH UPDATE dbo.t SET val = @val WHERE [key] = @key; END CATCH COMMIT TRANSACTION;
El costo de esas excepciones a menudo superará el costo de verificar primero; tendrá que intentarlo con una suposición aproximada de la tasa de aciertos/fallos. Escribí sobre esto aquí y aquí.
¿Qué hay de alterar varias filas?
Lo anterior trata sobre las decisiones de inserción/actualización de singleton, pero Justin Pealing preguntó qué hacer cuando se procesan varias filas sin saber cuáles de ellas ya existen.
Suponiendo que está enviando un conjunto de filas usando algo como un parámetro con valores de tabla, actualizaría usando una combinación y luego insertaría usando NO EXISTE, pero el patrón aún sería equivalente al primer enfoque anterior:
CREATE PROCEDURE dbo.UpsertTheThings
@tvp dbo.TableType READONLY
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE t WITH (UPDLOCK, SERIALIZABLE)
SET val = tvp.val
FROM dbo.t AS t
INNER JOIN @tvp AS tvp
ON t.[key] = tvp.[key];
INSERT dbo.t([key], val)
SELECT [key], val FROM @tvp AS tvp
WHERE NOT EXISTS (SELECT 1 FROM dbo.t WHERE [key] = tvp.[key]);
COMMIT TRANSACTION;
END Si está juntando varias filas de alguna otra manera que no sea un TVP (XML, lista separada por comas, vudú), colóquelas primero en forma de tabla y únalas a lo que sea. Tenga cuidado de no optimizar las inserciones primero en este escenario, de lo contrario, podría actualizar algunas filas dos veces.
Conclusión
Estos patrones de inserción son superiores a los que veo con demasiada frecuencia, y espero que empieces a usarlos. Señalaré esta publicación cada vez que detecte el IF EXISTS patrón en la naturaleza. Y, oye, otro agradecimiento a Paul White (sql.kiwi | @SQK_Kiwi), porque es excelente para hacer que los conceptos difíciles sean fáciles de entender y, a su vez, explicar.
Y si sientes que tienes que usa MERGE , por favor no me @; o tienes una buena razón (tal vez necesites algo oscuro MERGE -solo funcionalidad), o no tomó en serio los enlaces anteriores.