Este artículo es la sexta parte de una serie sobre expresiones de tabla. El mes pasado, en la Parte 5, cubrí el tratamiento lógico de CTE no recursivos. Este mes cubro el tratamiento lógico de CTE recursivos. Describo el soporte de T-SQL para CTE recursivos, así como elementos estándar que aún no son compatibles con T-SQL. Proporciono soluciones T-SQL lógicamente equivalentes para los elementos no admitidos.
Datos de muestra
Para los datos de muestra, usaré una tabla llamada Empleados, que contiene una jerarquía de empleados. La columna empid representa el ID de empleado del subordinado (el nodo secundario) y la columna mgrid representa el ID de empleado del gerente (el nodo principal). Utilice el siguiente código para crear y completar la tabla Empleados en la base de datos tempdb:
CONFIGURAR NOCUENTO EN; USAR tempdb;BOTAR TABLA SI EXISTE dbo.Empleados;IR CREAR TABLA dbo.Empleados( empid INT NOT NULL RESTRICCIÓN PK_Employees PRIMARY KEY, mgrid INT NULL RESTRICCIÓN FK_Employees_Employees REFERENCIAS dbo.Employees, empname VARCHAR(25) NO NULO, salario DINERO NO NULO, COMPROBAR (empid <> mgrid)); INSERTAR EN dbo.Empleados(empid, mgrid, empname, salario) VALORES(1, NULL, 'David', $10000.00), (2, 1, 'Eitan', $7000.00), (3, 1, 'Ina', $7500.00) , (4, 2, 'Seraph', $5000.00), (5, 2, 'Jiru', $5500.00), (6, 2, 'Steve', $4500.00), (7, 3, 'Aaron', $5000.00), ( 8, 5, 'Lilach', $3500.00), (9, 7, 'Rita', $3000.00), (10, 5, 'Sean', $3000.00), (11, 7, 'Gabriel', $3000.00), (12, 9, 'Emilia', $2000.00), (13, 9, 'Michael', $2000.00), (14, 9, 'Didi', $1500.00); CREAR ÍNDICE ÚNICO idx_unc_mgrid_empid EN dbo.Empleados(mgrid, empid) INCLUDE(empname, salario);
Observe que la raíz de la jerarquía de empleados, el CEO, tiene un valor NULL en la columna mgrid. El resto de los empleados tienen un administrador, por lo que su columna mgrid se establece en el ID de empleado de su administrador.
La figura 1 tiene una representación gráfica de la jerarquía de los empleados, que muestra el nombre del empleado, la identificación y su ubicación en la jerarquía.
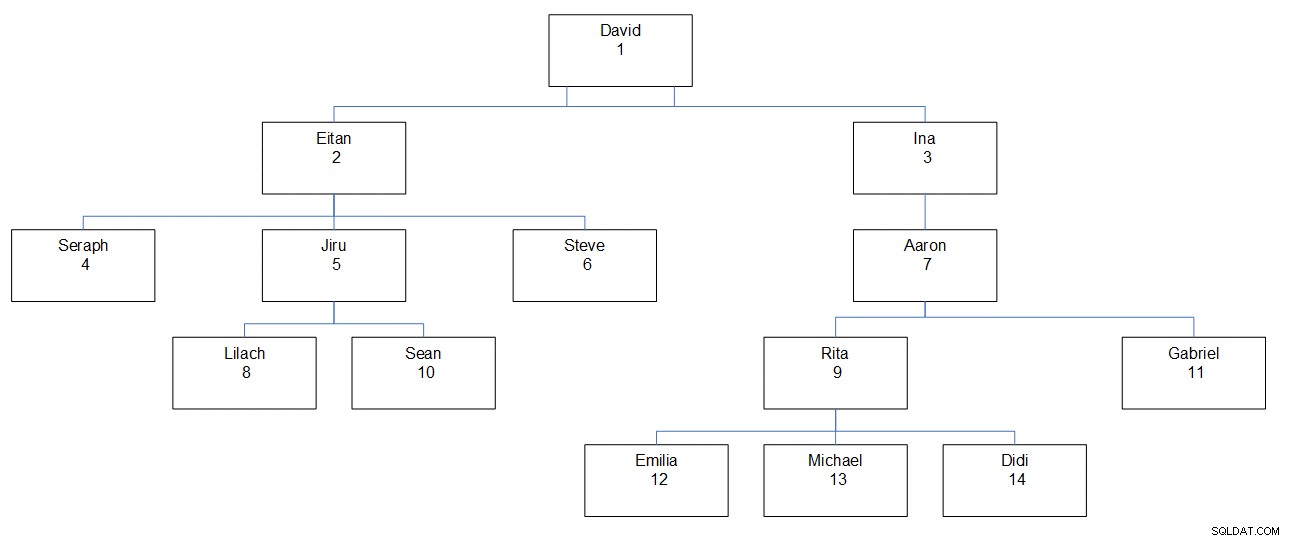 Figura 1:Jerarquía de empleados
Figura 1:Jerarquía de empleados
CTE recursivos
Los CTE recursivos tienen muchos casos de uso. Una categoría clásica de usos tiene que ver con el manejo de estructuras gráficas, como nuestra jerarquía de empleados. Las tareas que involucran gráficos a menudo requieren atravesar caminos de longitud arbitraria. Por ejemplo, dado el ID de empleado de algún gerente, devolver el empleado de entrada, así como todos los subordinados del empleado de entrada en todos los niveles; es decir, subordinados directos e indirectos. Si tuviera un pequeño límite conocido en la cantidad de niveles que podría necesitar seguir (el grado del gráfico), podría usar una consulta con una combinación por nivel de subordinados. Sin embargo, si el grado del gráfico es potencialmente alto, en algún momento se vuelve poco práctico escribir una consulta con muchas uniones. Otra opción es usar código iterativo imperativo, pero tales soluciones tienden a ser largas. Aquí es donde realmente brillan los CTE recursivos:le permiten usar soluciones declarativas, concisas e intuitivas.
Comenzaré con los conceptos básicos de CTE recursivos antes de llegar a las cosas más interesantes donde cubro las capacidades de búsqueda y ciclismo.
Recuerda que la sintaxis de una consulta contra un CTE es la siguiente:
WITHAS
(
)
Aquí muestro un CTE definido usando la cláusula WITH, pero como sabes, puedes definir múltiples CTE separados por comas.
En los CTE normales, no recursivos, la expresión de la tabla interna se basa en una consulta que se evalúa solo una vez. En las CTE recursivas, la expresión de la tabla interna se basa normalmente en dos consultas conocidas como miembros , aunque puede tener más de dos para manejar algunas necesidades especializadas. Los miembros suelen estar separados por un operador UNION ALL para indicar que sus resultados están unificados.
Un miembro puede ser un miembro ancla —lo que significa que se evalúa solo una vez; o puede ser un miembro recursivo —lo que significa que se evalúa repetidamente, hasta que devuelve un conjunto de resultados vacío. Esta es la sintaxis de una consulta contra un CTE recursivo que se basa en un miembro ancla y un miembro recursivo:
WITHAS
(
UNION ALL
)
Lo que hace que un miembro sea recursivo es tener una referencia al nombre de CTE. Esta referencia representa el conjunto de resultados de la última ejecución. En la primera ejecución del miembro recursivo, la referencia al nombre de CTE representa el conjunto de resultados del miembro ancla. En la ejecución N, donde N> 1, la referencia al nombre de CTE representa el conjunto de resultados de la ejecución (N – 1) del miembro recursivo. Como se mencionó, una vez que el miembro recursivo devuelve un conjunto vacío, no se vuelve a ejecutar. Una referencia al nombre de CTE en la consulta externa representa los conjuntos de resultados unificados de la ejecución única del miembro ancla y todas las ejecuciones del miembro recursivo.
El siguiente código implementa la tarea antes mencionada de devolver el subárbol de empleados para un administrador de entrada dado, pasando el ID de empleado 3 como el empleado raíz en este ejemplo:
DECLARACIÓN @root COMO INT =3; CON C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid) SELECCIONE empid, mgrid, empnameFROM C;
La consulta ancla se ejecuta solo una vez y devuelve la fila para el empleado raíz de entrada (empleado 3 en nuestro caso).
La consulta recursiva une el conjunto de empleados del nivel anterior, representado por la referencia al nombre de CTE, alias M para gerentes, con sus subordinados directos de la tabla Empleados, alias S para subordinados. El predicado de combinación es S.mgrid =M.empid, lo que significa que el valor mgrid del subordinado es igual al valor empid del gerente. La consulta recursiva se ejecuta cuatro veces de la siguiente manera:
- Devolver a los subordinados del empleado 3; salida:empleado 7
- Devolver a los subordinados del empleado 7; salida:empleados 9 y 11
- Devolver a los subordinados de los empleados 9 y 11; salida:12, 13 y 14
- Devolver a los subordinados de los empleados 12, 13 y 14; salida:conjunto vacío; paradas de recursividad
La referencia al nombre de CTE en la consulta externa representa los resultados unificados de la ejecución única de la consulta ancla (empleado 3) con los resultados de todas las ejecuciones de la consulta recursiva (empleados 7, 9, 11, 12, 13 y 14). Este código genera el siguiente resultado:
empid mgrid empname------ ------ --------3 1 Ina7 3 Aaron9 7 Rita11 7 Gabriel12 9 Emilia13 9 Michael14 9 Didi
Un problema común en las soluciones de programación es el código descontrolado, como los bucles infinitos, generalmente causados por un error. Con CTE recursivos, un error podría conducir a una ejecución en la pista del miembro recursivo. Por ejemplo, suponga que en nuestra solución para devolver los subordinados de un empleado de entrada, tiene un error en el predicado de unión del miembro recursivo. En lugar de usar ON S.mgrid =M.empid, usó ON S.mgrid =S.mgrid, así:
DECLARACIÓN @root COMO INT =3; CON C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =S .mgrid) SELECCIONE empid, mgrid, empnameFROM C;
Dado al menos un empleado con una ID de gerente no nula presente en la tabla, la ejecución del miembro recursivo seguirá devolviendo un resultado no vacío. Recuerde que la condición de terminación implícita para el miembro recursivo es cuando su ejecución devuelve un conjunto de resultados vacío. Si devuelve un conjunto de resultados no vacío, SQL Server lo ejecuta de nuevo. Se da cuenta de que si SQL Server no tuviera un mecanismo para limitar las ejecuciones recursivas, seguiría ejecutando el miembro recursivo repetidamente para siempre. Como medida de seguridad, T-SQL admite una opción de consulta MAXRECURSION que limita la cantidad máxima permitida de ejecuciones del miembro recursivo. De forma predeterminada, este límite se establece en 100, pero puede cambiarlo a cualquier valor SMALLINT no negativo, donde 0 representa la ausencia de límite. Establecer el límite máximo de recursión en un valor positivo N significa que los N + 1 intentos de ejecución del miembro recursivo se cancelan con un error. Por ejemplo, ejecutar el código con errores anterior tal como está significa que confía en el límite de recurrencia máximo predeterminado de 100, por lo que falla la ejecución 101 del miembro recursivo:
empid mgrid empname------ ------ --------3 1 Ina2 1 Eitan3 1 Ina...Mensaje 530, Nivel 16, Estado 1, Línea 121
La declaración finalizó. La recursividad máxima 100 se agotó antes de completar la instrucción.
Digamos que en su organización es seguro asumir que la jerarquía de los empleados no superará los 6 niveles de gestión. Puede reducir el límite máximo de recurrencia de 100 a un número mucho más pequeño, como 10 para estar seguro, así:
DECLARACIÓN @root COMO INT =3; CON C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =S .mgrid)SELECT empid, mgrid, empnameFROM COPTION (MAXRECURSION 10);
Ahora, si hay un error que resulta en una ejecución descontrolada del miembro recursivo, se descubrirá en el intento de ejecución 11 del miembro recursivo en lugar de en la ejecución 101:
empid mgrid empname------ ------ --------3 1 Ina2 1 Eitan3 1 Ina...Mensaje 530, Nivel 16, Estado 1, Línea 149
La declaración finalizó. La recursividad máxima 10 se agotó antes de completar la instrucción.
Es importante tener en cuenta que el límite máximo de recurrencia debe usarse principalmente como una medida de seguridad para abortar la ejecución de un código desbocado con errores. Recuerde que cuando se excede el límite, la ejecución del código se aborta con un error. No debe usar esta opción para limitar la cantidad de niveles para visitar con fines de filtrado. No desea que se genere un error cuando no hay ningún problema con el código.
Para fines de filtrado, puede limitar la cantidad de niveles para visitar mediante programación. Defina una columna llamada lvl que rastrea el número de nivel del empleado actual en comparación con el empleado raíz de entrada. En la consulta ancla, establece la columna lvl en la constante 0. En la consulta recursiva, la establece en el valor lvl del administrador más 1. Para filtrar tantos niveles por debajo de la raíz de entrada como @maxlevel, agregue el predicado M.lvl <@ maxlevel a la cláusula ON de la consulta recursiva. Por ejemplo, el código siguiente devuelve el empleado 3 y dos niveles de subordinados del empleado 3:
DECLARAR @root COMO INT =3, @maxlevel COMO INT =2; CON C AS( SELECT empid, mgrid, empname, 0 AS lvl FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl FROM C AS M INNER ÚNASE a dbo.Employees COMO S EN S.mgrid =M.empid Y M.lvl <@maxlevel) SELECCIONE empid, mgrid, empname, lvlFROM C;
Esta consulta genera el siguiente resultado:
empid mgrid empname lvl------ ------ -------- ----3 1 Ina 07 3 Aaron 19 7 Rita 211 7 Gabriel 2
Cláusulas estándar de BÚSQUEDA y CICLO
El estándar ISO/IEC SQL define dos opciones muy poderosas para CTE recursivos. Una es una cláusula llamada BÚSQUEDA que controla el orden de búsqueda recursivo, y otra es una cláusula llamada CICLO que identifica ciclos en los caminos recorridos. Esta es la sintaxis estándar para las dos cláusulas:
7.18Función
Especifique la generación de información de detección de pedidos y ciclos en el resultado de expresiones de consulta recursivas.
Formato
AS
SEARCH
PROFUNDIDAD PRIMERO POR
CYCLE
DEFAULT
En el momento de escribir este artículo, T-SQL no admite estas opciones, pero en los siguientes enlaces puede encontrar solicitudes de mejora de funciones que solicitan su inclusión en T-SQL en el futuro y votar por ellas:
- Agregue soporte para la cláusula ISO/IEC SQL SEARCH a CTE recursivos en T-SQL
- Agregue soporte para la cláusula ISO/IEC SQL CYCLE a CTE recursivos en T-SQL
En las siguientes secciones, describiré las dos opciones estándar y también proporcionaré soluciones alternativas lógicamente equivalentes que están actualmente disponibles en T-SQL.
cláusula BUSCAR
La cláusula BÚSQUEDA estándar define el orden de búsqueda recursiva como PRIMERO EN ANCHO o PRIMERO EN PROFUNDIDAD por alguna columna de ordenación especificada, y crea una nueva columna de secuencia con las posiciones ordinales de los nodos visitados. Especifique BREADTH FIRST para buscar primero en cada nivel (ancho) y luego hacia abajo en los niveles (profundidad). Usted especifica PROFUNDIDAD PRIMERO para buscar primero hacia abajo (profundidad) y luego a través (ancho).
Especifique la cláusula SEARCH justo antes de la consulta externa.
Comenzaré con un ejemplo de orden de búsqueda recursivo primero en amplitud. Solo recuerde que esta función no está disponible en T-SQL, por lo que no podrá ejecutar los ejemplos que usan las cláusulas estándar en SQL Server o Azure SQL Database. El siguiente código devuelve el subárbol del empleado 1, solicitando un orden de búsqueda en anchura por empid, creando una columna de secuencia llamada seqbreadth con las posiciones ordinales de los nodos visitados:
DECLARACIÓN @root COMO INT =1; CON C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid) BUSCAR ANCHO PRIMERO POR empid SET seqbreadth---------------------------------------- ---- SELECCIONE empid, mgrid, empname, seqbreadthFROM CORDER BY seqbreadth;
Aquí está el resultado deseado de este código:
empid mgrid empname seqbreadth------ ------ -------- -----------1 NULL David 12 1 Eitan 23 1 Ina 34 2 Serafín 45 2 Jiru 56 2 Steve 67 3 Aaron 78 5 Lilach 89 7 Rita 910 5 Sean 1011 7 Gabriel 1112 9 Emilia 1213 9 Michael 1314 9 Didi 14
No se confunda por el hecho de que los valores de seqbreadth parecen ser idénticos a los valores empid. Eso es solo por casualidad como resultado de la forma en que asigné manualmente los valores empid en los datos de muestra que creé.
La Figura 2 tiene una representación gráfica de la jerarquía de los empleados, con una línea de puntos que muestra el primer orden de amplitud en el que se buscaron los nodos. Los valores de empid aparecen justo debajo de los nombres de los empleados, y los valores de amplitud de segmento asignados aparecen en la esquina inferior izquierda de cada cuadro.
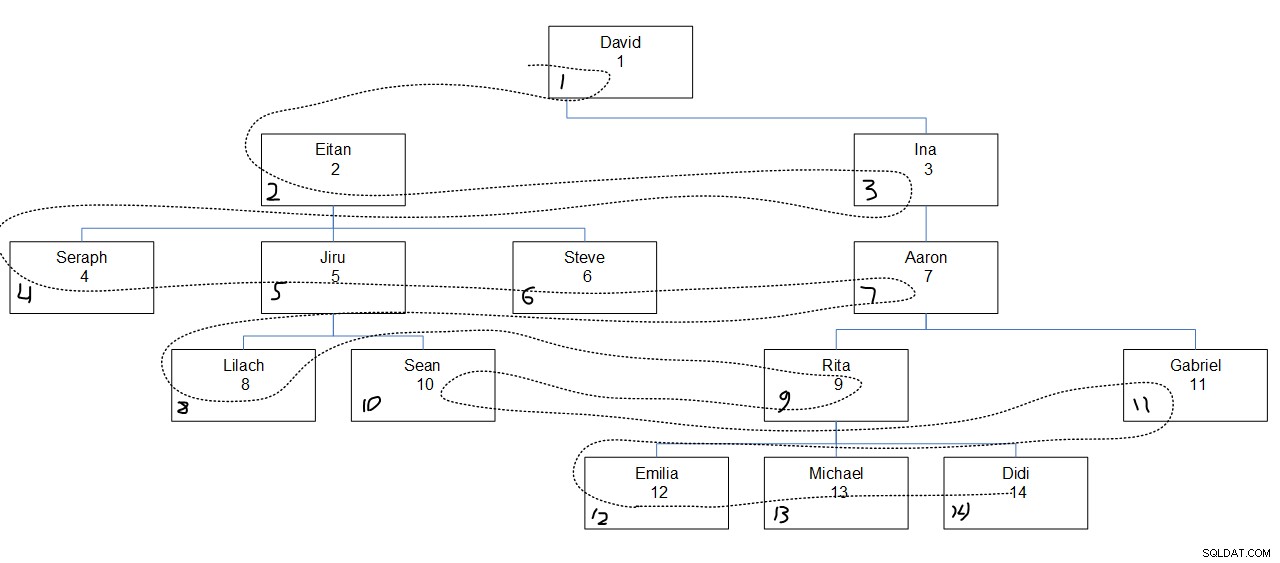 Figura 2:Busca primero la amplitud
Figura 2:Busca primero la amplitud
Lo que es interesante notar aquí es que dentro de cada nivel, los nodos se buscan según el orden de columna especificado (empid en nuestro caso) independientemente de la asociación principal del nodo. Por ejemplo, observe que en el cuarto nivel se accede primero a Lilach, segundo a Rita, tercero a Sean y último a Gabriel. Eso es porque entre todos los empleados en el cuarto nivel, ese es su orden basado en sus valores empid. No es que se suponga que Lilach y Sean deben ser buscados consecutivamente porque son subordinados directos del mismo gerente, Jiru.
Es bastante simple encontrar una solución T-SQL que proporcione el equivalente lógico de la opción estándar SAERCH DEPTH FIRST. Crea una columna llamada lvl como mostré anteriormente para rastrear el nivel del nodo con respecto a la raíz (0 para el primer nivel, 1 para el segundo, y así sucesivamente). Luego, calcula la columna de secuencia de resultados deseada en la consulta externa mediante una función ROW_NUMBER. Como orden de la ventana, especifique primero lvl y luego la columna de orden deseada (empid en nuestro caso). Aquí está el código de la solución completa:
DECLARACIÓN @root COMO INT =1; CON C AS( SELECT empid, mgrid, empname, 0 AS lvl FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, M.lvl + 1 AS lvl FROM C AS M INNER ÚNASE a dbo.Employees COMO S EN S.mgrid =M.empid) SELECCIONE empid, mgrid, empname, ROW_NUMBER() OVER(ORDER BY lvl, empid) AS seqbreadthFROM POR seqbreadth;
A continuación, examinemos el orden de búsqueda PRIMERO EN PROFUNDIDAD. De acuerdo con el estándar, el siguiente código debe devolver el subárbol del empleado 1, solicitando una orden de búsqueda de profundidad primero por empid, creando una columna de secuencia llamada profundidad de secuencia con las posiciones ordinales de los nodos buscados:
DECLARACIÓN @root COMO INT =1; CON C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid) PROFUNDIDAD DE BÚSQUEDA PRIMERO POR empid SET seq depth---------------------------------------- SELECCIONE empid, mgrid, empname, seq depth DESDE CORDER POR seq depth;
El siguiente es el resultado deseado de este código:
empid mgrid empname seq depth------ ------ -------- ---------1 NULL David 12 1 Eitan 24 2 Seraph 35 2 Jiru 48 5 Lilach 510 5 Sean 66 2 Steve 73 1 Ina 87 3 Aaron 99 7 Rita 1012 9 Emilia 1113 9 Michael 1214 9 Didi 1311 7 Gabriel 14
Mirando el resultado de la consulta deseada, probablemente sea difícil averiguar por qué los valores de secuencia se asignaron de la forma en que se asignaron. La figura 3 debería ayudar. Tiene una representación gráfica de la jerarquía de los empleados, con una línea de puntos que refleja el orden de búsqueda en profundidad primero, con los valores de secuencia asignados en la esquina inferior izquierda de cada cuadro.
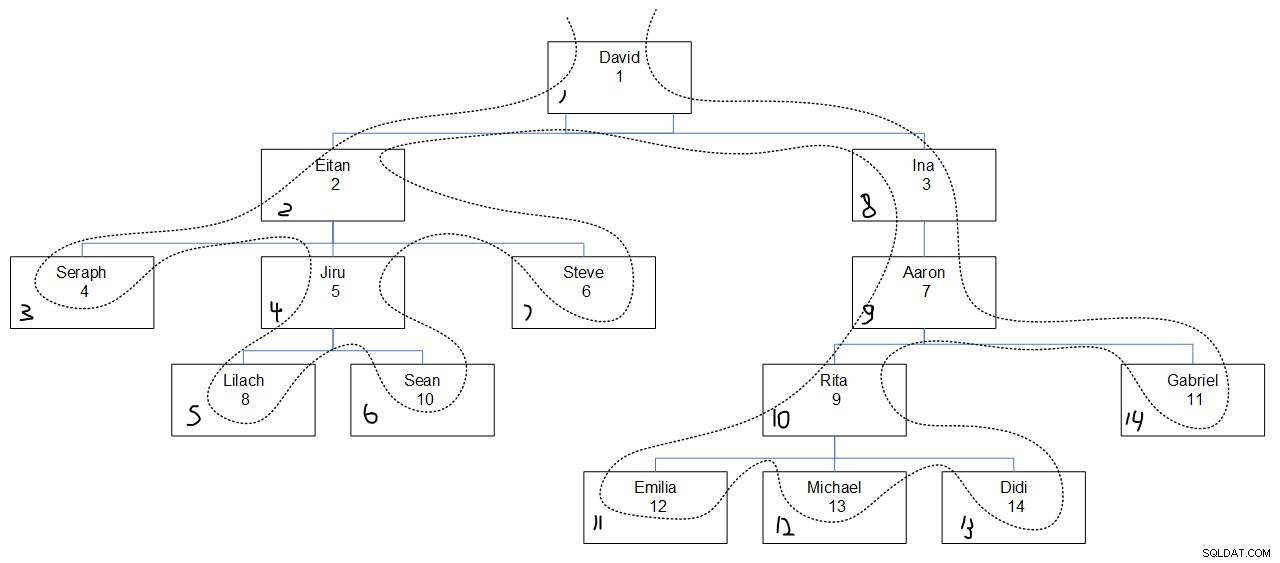 Figura 3:Profundidad de búsqueda primero
Figura 3:Profundidad de búsqueda primero
Proponer una solución T-SQL que proporcione el equivalente lógico a la opción estándar PRIMERO EN PROFUNDIDAD DE BUSQUEDA es un poco complicado, pero factible. Describiré la solución en dos pasos.
En el Paso 1, para cada nodo, calcula una ruta de clasificación binaria que se compone de un segmento por ancestro del nodo, y cada segmento refleja la posición de clasificación del ancestro entre sus hermanos. Construya esta ruta de manera similar a la forma en que calcula la columna lvl. Es decir, comience con una cadena binaria vacía para el nodo raíz en la consulta de anclaje. Luego, en la consulta recursiva, concatena la ruta del padre con la posición de clasificación del nodo entre los hermanos después de convertirlo en un segmento binario. Utiliza la función ROW_NUMBER para calcular la posición, dividida por el padre (mgrid en nuestro caso) y ordenada por la columna de ordenación relevante (empid en nuestro caso). Convierte el número de fila en un valor binario de un tamaño suficiente según el número máximo de hijos directos que un padre puede tener en su gráfico. BINARIO(1) admite hasta 255 niños por padre, BINARIO(2) admite 65 535, BINARIO(3):16 777 215, BINARIO(4):4 294 967 295. En una CTE recursiva, las columnas correspondientes en el ancla y las consultas recursivas deben ser del mismo tipo y tamaño , así que asegúrese de convertir la ruta de clasificación a un valor binario del mismo tamaño en ambos.
Aquí está el código que implementa el Paso 1 en nuestra solución (suponiendo que BINARY(1) sea suficiente por segmento, lo que significa que no tiene más de 255 subordinados directos por gerente):
DECLARACIÓN @root COMO INT =1; CON C AS( SELECT empid, mgrid, empname, CAST(0x AS VARBINARY(900)) AS sortpath FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M. sortpath + CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid) AS BINARY(1)) AS VARBINARY(900)) AS sortpath FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, sortpathFROM C;
Este código genera el siguiente resultado:
empid mgrid empname sortpath------ ------ -------- -----------1 NULL David 0x2 1 Eitan 0x013 1 Ina 0x027 3 Aaron 0x02019 7 rita 0x02010111 7 Gabriel 0x02010212 9 Emilia 0x0201010113 9 Michael 0x02010214 9 didi 0x020101034 2 Seraph 0x01015 2 jiru 0x01026 2 steve 0x01038 5 lilach 0x01010 5 sean 0x01020202Tenga en cuenta que utilicé una cadena binaria vacía como la ruta de clasificación para el nodo raíz del único subárbol que estamos consultando aquí. En caso de que el miembro de anclaje pueda potencialmente devolver varias raíces de subárbol, simplemente comience con un segmento que se base en un cálculo de ROW_NUMBER en la consulta de anclaje, similar a la forma en que lo calcula en la consulta recursiva. En tal caso, su ruta de clasificación será un segmento más larga.
Lo que queda por hacer en el paso 2 es crear la columna de profundidad de secuencia del resultado deseado calculando los números de fila que están ordenados por ruta de clasificación en la consulta externa, así
DECLARACIÓN @root COMO INT =1; CON C AS( SELECT empid, mgrid, empname, CAST(0x AS VARBINARY(900)) AS sortpath FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M. sortpath + CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid) AS BINARY(1)) AS VARBINARY(900)) AS sortpath FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ROW_NUMBER() OVER(ORDER BY sortpath) COMO seq depthFROM CORDER BY seq depth;Esta solución es el equivalente lógico de usar la opción estándar BÚSQUEDA EN PROFUNDIDAD PRIMERO que se mostró anteriormente junto con el resultado deseado.
Una vez que tenga una columna de secuencia que refleje el primer orden de búsqueda de profundidad (seq depth en nuestro caso), con un poco más de esfuerzo puede generar una representación visual muy agradable de la jerarquía. También necesitará la columna lvl antes mencionada. Ordena la consulta externa por la columna de secuencia. Devuelve algún atributo que desea usar para representar el nodo (digamos, empname en nuestro caso), con el prefijo de alguna cadena (digamos ' | ') replicado lvl veces. Aquí está el código completo para lograr tal representación visual:
DECLARACIÓN @root COMO INT =1; CON C AS( SELECT empid, empname, 0 AS lvl, CAST(0x AS VARBINARY(900)) AS sortpath FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.empname, M.lvl + 1 AS lvl, CAST(M.sortpath + CAST(ROW_NUMBER() OVER(PARTITION BY S.mgrid ORDER BY S.empid) AS BINARY(1)) AS VARBINARY(900)) AS sortpath FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, ROW_NUMBER() OVER(ORDER BY sortpath) AS seq depth, REPLICATE(' | ', lvl) + empname AS empFROM CORDER BY seq depth;Este código genera el siguiente resultado:
empid seq depth emp------ --------- --------------------1 1 David2 2 | Eitan4 3 | | serafín5 4 | | Jiru8 5 | | | lila10 6 | | | Sean6 7 | | Steve3 8 | Ina7 9 | | Aarón9 10 | | | Rita12 11 | | | | Emilia13 12 | | | | Miguel14 13 | | | | Didi11 14 | | | Gabriel¡Eso es genial!
cláusula CYCLE
Las estructuras gráficas pueden tener ciclos. Esos ciclos pueden ser válidos o no válidos. Un ejemplo de ciclos válidos es un gráfico que representa carreteras y caminos que conectan ciudades y pueblos. Eso es lo que se conoce como un gráfico cíclico . Por el contrario, se supone que un gráfico que representa una jerarquía de empleados, como en nuestro caso, no tiene ciclos. Eso es lo que se conoce como un acíclico grafico. Sin embargo, supongamos que debido a alguna actualización errónea, terminas con un ciclo sin querer. Por ejemplo, suponga que, por error, actualiza la ID de gerente del CEO (empleado 1) al empleado 14 ejecutando el siguiente código:
ACTUALIZAR Empleados SET mgrid =14WHERE empid =1;Ahora tiene un ciclo no válido en la jerarquía de empleados.
Ya sea que los ciclos sean válidos o inválidos, cuando atraviesa la estructura del gráfico, ciertamente no desea seguir siguiendo una ruta cíclica repetidamente. En ambos casos, desea dejar de seguir una ruta una vez que se encuentra una aparición no primera del mismo nodo y marcar dicha ruta como cíclica.
Entonces, ¿qué sucede cuando consulta un gráfico que tiene ciclos utilizando una consulta recursiva, sin ningún mecanismo para detectarlos? Esto depende de la implementación. En SQL Server, en algún momento alcanzará el límite máximo de recurrencia y su consulta se cancelará. Por ejemplo, suponiendo que ejecutó la actualización anterior que introdujo el ciclo, intente ejecutar la siguiente consulta recursiva para identificar el subárbol del empleado 1:
DECLARACIÓN @root COMO INT =1; CON C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid) SELECCIONE empid, mgrid, empnameFROM C;Dado que este código no establece un límite máximo de recurrencia explícito, se asume el límite predeterminado de 100. SQL Server aborta la ejecución de este código antes de completarse y genera un error:
empid mgrid empname------ ------ --------1 14 David2 1 Eitan3 1 Ina7 3 Aaron9 7 Rita11 7 Gabriel12 9 Emilia13 9 Michael14 9 Didi1 14 David2 1 Eitan3 1 Ina7 3 Aarón...Mensaje 530, Nivel 16, Estado 1, Línea 432
La declaración finalizó. La recursividad máxima 100 se agotó antes de completar la instrucción.El estándar SQL define una cláusula llamada CYCLE para CTE recursivos, lo que le permite manejar ciclos en su gráfico. Especifique esta cláusula justo antes de la consulta externa. Si también está presente una cláusula SEARCH, la especifica primero y luego la cláusula CYCLE. Esta es la sintaxis de la cláusula CYCLE:
CYCLE
SETTO DEFAULT
USINGLa detección de un ciclo se basa en la lista de columnas de ciclos especificada . Por ejemplo, en nuestra jerarquía de empleados, probablemente querrá usar la columna empid para este propósito. Cuando aparece el mismo valor de empid por segunda vez, se detecta un ciclo y la consulta no sigue ese camino más. Usted especifica una nueva columna de marca de ciclo que indicará si se encontró un ciclo o no, y sus propios valores como la marca de ciclo y marca de no ciclo valores. Por ejemplo, podrían ser 1 y 0 o 'Sí' y 'No', o cualquier otro valor de su elección. En la cláusula USING, especifica un nuevo nombre de columna de matriz que contendrá la ruta de los nodos encontrados hasta el momento.
Así es como manejaría una solicitud de subordinados de algún empleado raíz de entrada, con la capacidad de detectar ciclos en función de la columna empid, indicando 1 en la columna de marca de ciclo cuando se detecta un ciclo y 0 en caso contrario:
DECLARACIÓN @root COMO INT =1; CON C AS( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid) CYCLE empid SET ciclo A 1 DEFAULT 0---------------------------------------------------- SELECT empid, mgrid, empnameDE C;Aquí está el resultado deseado de este código:
empid mgrid empname ciclo------ ------ -------- ------1 14 David 02 1 Eitan 03 1 Ina 07 3 Aaron 09 7 Rita 011 7 Gabriel 012 9 Emilia 013 9 Michael 014 9 Didi 01 14 David 14 2 Seraph 05 2 Jiru 06 2 Steve 08 5 Lilach 010 5 Sean 0Actualmente, T-SQL no admite la cláusula CYCLE, pero existe una solución alternativa que proporciona un equivalente lógico. Implica tres pasos. Recuerde que anteriormente creó una ruta de clasificación binaria para manejar el orden de búsqueda recursivo. De manera similar, como primer paso en la solución, crea una ruta de antepasados basada en cadenas de caracteres hecha de los ID de nodo (ID de empleado en nuestro caso) de los antepasados que conducen al nodo actual, incluido el nodo actual. Desea separadores entre los ID de nodo, incluido uno al principio y otro al final.
Aquí está el código para construir una ruta de ancestros de este tipo:
DECLARACIÓN @root COMO INT =1; CON C AS( SELECT empid, mgrid, empname, CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ancpathFROM C;Este código genera el siguiente resultado, aún sigue rutas cíclicas y, por lo tanto, aborta antes de completarse una vez que se excede el límite máximo de recurrencia:
empid mgrid empname ancpath------ ------ -------- -------------------1 14 David . 1.2 1 Eitan .1.2.3 1 Ina .1.3.7 3 Aaron .1.3.7.9 7 Rita .1.3.7.9.11 7 Gabriel .1.3.7.11.12 9 Emilia .1.3.7.9.12.13 9 Michael .1.3.7.9. 13.14 9 Didi .1.3.7.9.14.1 14 David .1.3.7.9.14.1.2 1 Eitan .1.3.7.9.14.1.2.3 1 Ina .1.3.7.9.14.1.3.7 3 Aaron .1.3.7.9.14.1.3.7. ...Mensaje 530, Nivel 16, Estado 1, Línea 492
La declaración finalizó. La recursividad máxima 100 se agotó antes de completar la instrucción.Eyeballing the output, you can identify a cyclic path when the current node appears in the path for the nonfirst time, such as in the path
'.1.3.7.9.14.1.'.In the second step of the solution you produce the cycle mark column. In the anchor query you simply set it to 0 since clearly a cycle cannot be found in the first node. In the recursive member you use a CASE expression that checks with a LIKE-based predicate whether the current node ID already appears in the parent’s path, in which case it returns the value 1, or not, in which case it returns the value 0.
Here’s the code implementing Step 2:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, 0 AS cycle FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1 ELSE 0 END AS cycle FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid)SELECT empid, mgrid, empname, ancpath, cycleFROM C;This code generates the following output, again, still pursuing cyclic paths and failing once the max recursion limit is reached:
empid mgrid empname ancpath cycle------ ------ -------- ------------------- ------1 14 David .1. 02 1 Eitan .1.2. 03 1 Ina .1.3. 07 3 Aaron .1.3.7. 09 7 Rita .1.3.7.9. 011 7 Gabriel .1.3.7.11. 012 9 Emilia .1.3.7.9.12. 013 9 Michael .1.3.7.9.13. 014 9 Didi .1.3.7.9.14. 01 14 David .1.3.7.9.14.1. 12 1 Eitan .1.3.7.9.14.1.2. 03 1 Ina .1.3.7.9.14.1.3. 17 3 Aaron .1.3.7.9.14.1.3.7. 1...Msg 530, Level 16, State 1, Line 532
The statement terminated. The maximum recursion 100 has been exhausted before statement completion.The third and last step is to add a predicate to the ON clause of the recursive member that pursues a path only if a cycle was not detected in the parent’s path.
Here’s the code implementing Step 3, which is also the complete solution:
DECLARE @root AS INT =1; WITH C AS( SELECT empid, mgrid, empname, CAST('.' + CAST(empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, 0 AS cycle FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname, CAST(M.ancpath + CAST(S.empid AS VARCHAR(4)) + '.' AS VARCHAR(900)) AS ancpath, CASE WHEN M.ancpath LIKE '%.' + CAST(S.empid AS VARCHAR(4)) + '.%' THEN 1 ELSE 0 END AS cycle FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M.empid AND M.cycle =0)SELECT empid, mgrid, empname, cycleFROM C;This code runs to completion, and generates the following output:
empid mgrid empname cycle------ ------ -------- -----------1 14 David 02 1 Eitan 03 1 Ina 07 3 Aaron 09 7 Rita 011 7 Gabriel 012 9 Emilia 013 9 Michael 014 9 Didi 01 14 David 14 2 Seraph 05 2 Jiru 06 2 Steve 08 5 Lilach 010 5 Sean 0You identify the erroneous data easily here, and fix the problem by setting the manager ID of the CEO to NULL, like so:
UPDATE Employees SET mgrid =NULLWHERE empid =1;Run the recursive query and you will find that there are no cycles present.
Conclusión
Recursive CTEs enable you to write concise declarative solutions for purposes such as traversing graph structures. A recursive CTE has at least one anchor member, which gets executed once, and at least one recursive member, which gets executed repeatedly until it returns an empty result set. Using a query option called MAXRECURSION you can control the maximum number of allowed executions of the recursive member as a safety measure. To limit the executions of the recursive member programmatically for filtering purposes you can maintain a column that tracks the level of the current node with respect to the root node.
The SQL standard supports two very powerful options for recursive CTEs that are currently not available in T-SQL. One is a clause called SEARCH that controls the recursive search order, and another is a clause called CYCLE that detects cycles in the traversed paths. I provided logically equivalent solutions that are currently available in T-SQL. If you find that the unavailable standard features could be important future additions to T-SQL, make sure to vote for them here:
- Add support for ISO/IEC SQL SEARCH clause to recursive CTEs in T-SQL
- Add support for ISO/IEC SQL CYCLE clause to recursive CTEs in T-SQL
This article concludes the coverage of the logical aspects of CTEs. Next month I’ll turn my attention to physical/performance considerations of CTEs.