En 2014, escribí un artículo llamado Performance Tuning the Whole Query Plan. Examinó formas de encontrar una cantidad relativamente pequeña de valores distintos de un conjunto de datos moderadamente grande y concluyó que una solución recursiva podría ser óptima. Esta publicación de seguimiento revisa la pregunta para SQL Server 2019, usando una mayor cantidad de filas.
Entorno de prueba
Usaré la base de datos Stack Overflow 2013 de 50 GB, pero serviría cualquier tabla grande con una cantidad baja de valores distintos.
Buscaré valores distintos en BountyAmount columna de dbo.Votes tabla, presentada en orden ascendente de cantidad de recompensa. La tabla Votos tiene algo menos de 53 millones de filas (52 928 720 para ser exactos). Solo hay 19 montos de recompensa diferentes, incluido NULL .
La base de datos Stack Overflow 2013 viene sin índices no agrupados para minimizar el tiempo de descarga. Hay un índice de clave principal agrupado en el Id columna de dbo.Votes mesa. Viene configurado para compatibilidad con SQL Server 2008 (nivel 100), pero comenzaremos con una configuración más moderna de SQL Server 2017 (nivel 140):
ALTER DATABASE StackOverflow2013
SET COMPATIBILITY_LEVEL = 140;
Las pruebas se realizaron en mi computadora portátil con SQL Server 2019 CU 2. Esta máquina tiene cuatro CPU i7 (con hiperprocesamiento a 8) con una velocidad base de 2,4 GHz. Tiene 32 GB de RAM, con 24 GB disponibles para la instancia de SQL Server 2019. El umbral de costo para el paralelismo se establece en 50.
Cada resultado de la prueba representa el mejor de diez ejecuciones, con todos los datos requeridos y las páginas de índice en la memoria.
1. Índice agrupado de almacén de filas
Para establecer una línea de base, la primera ejecución es una consulta en serie sin indexación nueva (y recuerde que esto es con la base de datos establecida en el nivel de compatibilidad 140):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (MAXDOP 1);
Esto escanea el índice agrupado y usa un agregado de hash en modo fila para encontrar los distintos valores de BountyAmount :
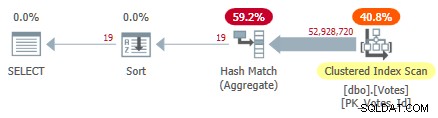 Plan de índice agrupado en serie
Plan de índice agrupado en serie
Esto toma 10,500ms para completar, utilizando la misma cantidad de tiempo de CPU. Recuerde que este es el mejor tiempo de diez ejecuciones con todos los datos en la memoria. Estadísticas de muestra creadas automáticamente en el BountyAmount se crearon en la primera ejecución.
Aproximadamente la mitad del tiempo transcurrido se dedica a la exploración del índice agrupado y aproximadamente la otra mitad al agregado de coincidencia de hash. Sort solo tiene 19 filas para procesar, por lo que consume solo 1 ms aproximadamente. Todos los operadores de este plan utilizan la ejecución en modo fila.
Eliminando el MAXDOP 1 sugerencia da un plan paralelo:
 Plan de índice agrupado en paralelo
Plan de índice agrupado en paralelo
Este es el plan que elige el optimizador sin ninguna pista en mi configuración. Devuelve resultados en 4200ms utilizando un total de 32 800 ms de CPU (en DOP 8).
2. Índice no agrupado
Explorando toda la tabla para encontrar solo el BountyAmount parece ineficiente, por lo que es natural intentar agregar un índice no agrupado solo en la columna que necesita esta consulta:
CREATE NONCLUSTERED INDEX b ON dbo.Votes (BountyAmount);
Este índice tarda un tiempo en crearse (1m 40s). El MAXDOP 1 la consulta ahora usa Stream Aggregate porque el optimizador puede usar el índice no agrupado para presentar filas en BountyAmount orden:
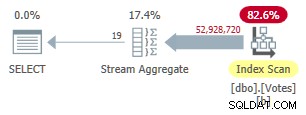 Plan de modo de fila no agrupado en serie
Plan de modo de fila no agrupado en serie
Tiene una duración de 9300 ms (consumiendo la misma cantidad de tiempo de CPU). Una mejora útil en los 10 500 ms originales, pero difícilmente impactante.
Eliminando el MAXDOP 1 sugerencia da un plan paralelo con agregación local (por subproceso):
 Plan de modo de fila paralelo no agrupado
Plan de modo de fila paralelo no agrupado
Esto se ejecuta en 3400 ms usando 25,800ms de tiempo de CPU. Es posible que podamos mejorar la compresión de filas o páginas en el nuevo índice, pero quiero pasar a opciones más interesantes.
3. Modo por lotes en almacenamiento en fila (BMOR)
Ahora configure la base de datos en el modo de compatibilidad de SQL Server 2019 usando:
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 150;
Esto le da al optimizador la libertad de elegir el modo por lotes en el almacenamiento de filas si lo considera conveniente. Esto puede proporcionar algunos de los beneficios de la ejecución en modo por lotes sin necesidad de un índice de almacenamiento de columnas. Para obtener detalles técnicos profundos y opciones no documentadas, consulte el excelente artículo de Dmitry Pilugin sobre el tema.
Desafortunadamente, el optimizador aún elige la ejecución en modo de fila completa utilizando agregados de flujo para las consultas de prueba en serie y en paralelo. Para obtener un modo por lotes en el plan de ejecución de la tienda de filas, podemos agregar una sugerencia para fomentar la agregación mediante la coincidencia de hash (que puede ejecutarse en modo por lotes):
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (HASH GROUP, MAXDOP 1); Esto nos da un plan con todos los operadores ejecutándose en modo por lotes:
 Modo por lotes en serie en el plan de almacenamiento en fila
Modo por lotes en serie en el plan de almacenamiento en fila
Los resultados se devuelven en 2600 ms (toda la CPU como de costumbre). Esto ya es más rápido que el paralelo plan de modo de fila (3400 ms transcurridos) mientras se usa mucho menos CPU (2600 ms frente a 25 800 ms).
Eliminando el MAXDOP 1 pista (pero manteniendo HASH GROUP ) proporciona un modo de lote paralelo en el plan de almacenamiento de filas:
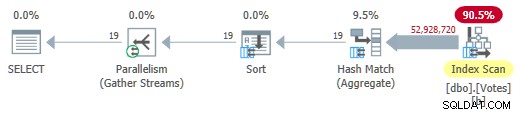 Modo de lote paralelo en plan de almacenamiento en fila
Modo de lote paralelo en plan de almacenamiento en fila
Esto se ejecuta en solo 725 ms utilizando 5700 ms de CPU.
4. Modo por lotes en el almacén de columnas
El modo de lote paralelo en el resultado del almacenamiento en fila es una mejora impresionante. Podemos hacerlo aún mejor al proporcionar una representación de almacén de columnas de los datos. Para mantener todo lo demás igual, agregaré un no agrupado índice de almacenamiento de columnas solo en la columna que necesitamos:
CREATE NONCLUSTERED COLUMNSTORE INDEX nb ON dbo.Votes (BountyAmount);
Esto se completa a partir del índice no agrupado del árbol b existente y se crea en solo 15 segundos.
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY V.BountyAmount
OPTION (MAXDOP 1); El optimizador elige un plan de modo por lotes completo que incluye un análisis de índice de almacén de columnas:
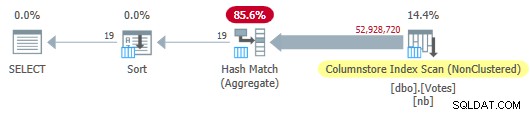 Plan de almacenamiento de columnas en serie
Plan de almacenamiento de columnas en serie
Esto se ejecuta en 115 ms utilizando la misma cantidad de tiempo de CPU. El optimizador elige este plan sin ninguna sugerencia sobre la configuración de mi sistema porque el costo estimado del plan está por debajo del umbral de costo para el paralelismo .
Para obtener un plan paralelo, podemos reducir el umbral de costo o usar una sugerencia no documentada:
SELECT DISTINCT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount
OPTION (USE HINT ('ENABLE_PARALLEL_PLAN_PREFERENCE')); En cualquier caso, el plan paralelo es:
 Plan de almacenamiento de columnas paralelas
Plan de almacenamiento de columnas paralelas
El tiempo transcurrido de la consulta ahora se ha reducido a 30 ms , mientras consume 210ms de CPU.
5. Modo por lotes en almacenamiento en columna con empuje hacia abajo
El mejor tiempo de ejecución actual de 30 ms es impresionante, especialmente si se compara con los 10 500 ms originales. Sin embargo, es un poco vergonzoso que tengamos que pasar casi 53 millones de filas (en 58 868 lotes) del escaneo al agregado de coincidencia de hash.
Sería bueno si SQL Server pudiera empujar la agregación hacia abajo en el escaneo y simplemente devolver valores distintos del almacén de columnas directamente. Podrías pensar que necesitamos expresar el DISTINCT como GROUP BY para obtener el empuje agregado agrupado, pero eso es lógicamente redundante y no es la historia completa en cualquier caso.
Con la implementación actual de SQL Server, en realidad necesitamos calcular un agregado para activar el pushdown agregado. Más que eso, necesitamos usar el resultado agregado de alguna manera, o el optimizador simplemente lo eliminará como innecesario.
Una forma de escribir la consulta para lograr un pushdown agregado es agregar un requisito de pedido secundario lógicamente redundante:
SELECT
V.BountyAmount
FROM dbo.Votes AS V
GROUP BY
V.BountyAmount
ORDER BY
V.BountyAmount,
COUNT_BIG(*) -- New!
OPTION (MAXDOP 1); El plan de serie es ahora:
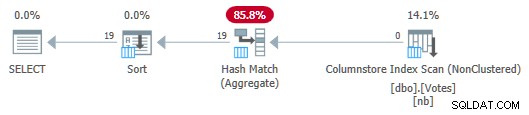 Plan de almacenamiento de columnas en serie con inserción agregada
Plan de almacenamiento de columnas en serie con inserción agregada
¡Observe que no se pasan filas del Escaneo al Agregado! Debajo de las sábanas, agregados parciales de BountyAmount Los valores y sus recuentos de filas asociados se pasan a Hash Match Aggregate, que suma los agregados parciales para formar el agregado final (global) requerido. Esto es muy eficiente, como lo confirma el tiempo transcurrido de 13ms (todo lo cual es tiempo de CPU). Como recordatorio, el plan de serie anterior tardó 115 ms.
Para completar el conjunto, podemos obtener una versión paralela de la misma forma que antes:
 Plan de almacenamiento de columnas paralelas con empuje agregado hacia abajo
Plan de almacenamiento de columnas paralelas con empuje agregado hacia abajo
Esto funciona durante 7 ms usando 40ms de CPU en total.
Es una pena que necesitemos calcular y usar un agregado que no necesitamos solo para empujar hacia abajo. Quizás esto se mejore en el futuro para que DISTINCT y GROUP BY sin agregados se pueden empujar hacia abajo para escanear.
6. Expresión de tabla común recursiva en modo fila
Al principio, prometí revisar la solución CTE recursiva utilizada para encontrar una pequeña cantidad de duplicados en un gran conjunto de datos. Implementar el requisito actual usando esa técnica es bastante sencillo, aunque el código es necesariamente más largo que cualquier cosa que hayamos visto hasta este punto:
WITH R AS
(
-- Anchor
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH FIRST 1 ROW ONLY
UNION ALL
-- Recursive
SELECT
Q1.BountyAmount
FROM
(
SELECT
V.BountyAmount,
rn = ROW_NUMBER() OVER (
ORDER BY V.BountyAmount ASC)
FROM R
JOIN dbo.Votes AS V
ON V.BountyAmount > ISNULL(R.BountyAmount, -1)
) AS Q1
WHERE
Q1.rn = 1
)
SELECT
R.BountyAmount
FROM R
ORDER BY
R.BountyAmount ASC
OPTION (MAXRECURSION 0); La idea tiene sus raíces en el llamado escaneo de salto de índice:encontramos el valor más bajo de interés al comienzo del índice de árbol b ordenado ascendente, luego buscamos encontrar el siguiente valor en el orden del índice, y así sucesivamente. La estructura de un índice de árbol b hace que encontrar el siguiente valor más alto sea muy eficiente:no hay necesidad de escanear los duplicados.
El único truco real aquí es convencer al optimizador para que nos permita usar TOP en la parte 'recursiva' del CTE para devolver una copia de cada valor distinto. Consulte mi artículo anterior si necesita un repaso de los detalles.
El plan de ejecución (explicado en general por Craig Freedman aquí) es:
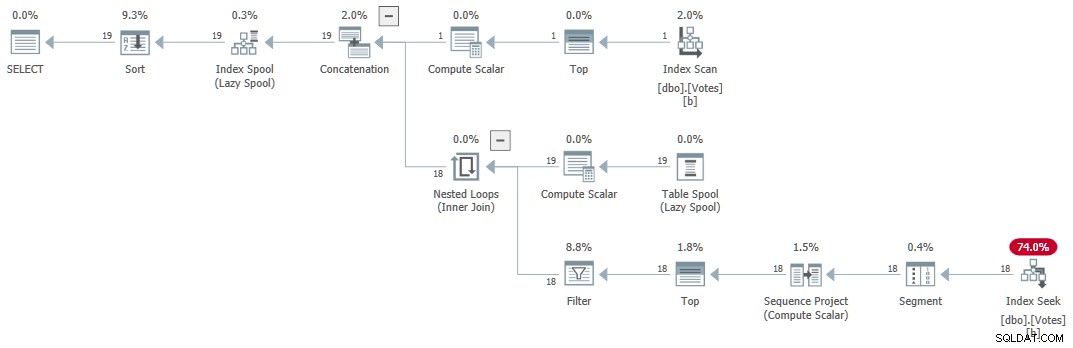 CTE recursivo serial
CTE recursivo serial
La consulta devuelve resultados correctos en 1 ms utilizando 1 ms de CPU, según Sentry One Plan Explorer.
7. T-SQL iterativo
Se puede expresar una lógica similar usando un WHILE círculo. El código puede ser más fácil de leer y comprender que el CTE recursivo. También evita tener que usar trucos para sortear las muchas restricciones en la parte recursiva de un CTE. El rendimiento es competitivo en torno a los 15 ms. Este código se proporciona por interés y no está incluido en la tabla de resumen de rendimiento.
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE @Result table
(
BountyAmount integer NULL UNIQUE CLUSTERED
);
DECLARE @BountyAmount integer;
-- First value in index order
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
-- Next higher value
WHILE @@ROWCOUNT > 0
BEGIN
WITH U AS
(
SELECT
V.BountyAmount
FROM dbo.Votes AS V
WHERE
V.BountyAmount > ISNULL(@BountyAmount, -1)
ORDER BY
V.BountyAmount ASC
OFFSET 0 ROWS
FETCH NEXT 1 ROW ONLY
)
UPDATE U
SET @BountyAmount = U.BountyAmount
OUTPUT Inserted.BountyAmount
INTO @Result (BountyAmount);
END;
-- Accumulated results
SELECT
R.BountyAmount
FROM @Result AS R
ORDER BY
R.BountyAmount; Tabla de resumen de rendimiento
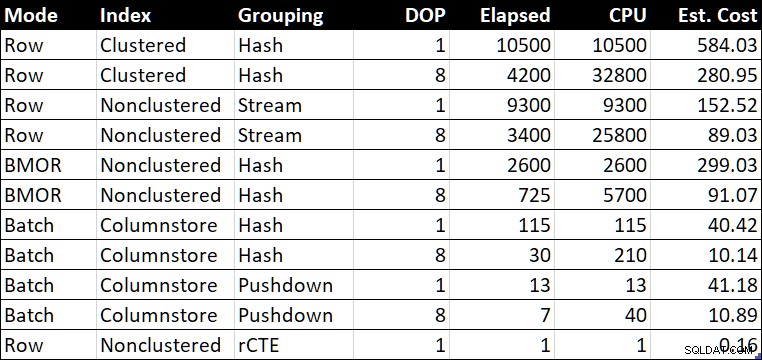 Tabla de resumen de rendimiento (duración/CPU en milisegundos)
Tabla de resumen de rendimiento (duración/CPU en milisegundos)
La “Est. Costo” muestra la estimación de costos del optimizador para cada consulta según lo informado en el sistema de prueba.
Pensamientos finales
Encontrar una pequeña cantidad de valores distintos puede parecer un requisito bastante específico, pero lo he encontrado con bastante frecuencia a lo largo de los años, generalmente como parte del ajuste de una consulta más grande.
Los últimos ejemplos estuvieron bastante cerca en rendimiento. Muchas personas estarían contentas con cualquiera de los resultados en fracciones de segundo, dependiendo de las prioridades. Incluso el modo por lotes en serie en el resultado de almacenamiento en fila de 2600 ms se compara bien con el mejor paralelo planes de modo de fila, lo que es un buen augurio para aceleraciones significativas simplemente actualizando a SQL Server 2019 y habilitando el nivel de compatibilidad de la base de datos 150. No todos podrán pasar rápidamente al almacenamiento de almacenamiento en columna, y no siempre será la solución correcta de todos modos . El modo por lotes en el almacenamiento de filas proporciona una forma ordenada de lograr algunas de las ganancias posibles con los almacenamientos de columnas, suponiendo que pueda convencer al optimizador para que opte por usarlo.
El resultado de empuje hacia abajo agregado de la tienda de columnas paralelas de 57 millones de filas procesado en 7ms (usando 40ms de CPU) es notable, especialmente considerando el hardware. El resultado de la reducción agregada en serie de 13 ms es igualmente impresionante. Sería genial si no hubiera tenido que agregar un resultado agregado sin sentido para obtener estos planes.
Para aquellos que aún no pueden migrar a SQL Server 2019 o al almacenamiento de almacenamiento en columnas, el CTE recursivo sigue siendo una solución viable y eficiente cuando existe un índice de árbol b adecuado y se garantiza que la cantidad de valores distintos necesarios es bastante pequeña. Sería bueno si SQL Server pudiera acceder a un árbol b como este sin necesidad de escribir un CTE recursivo (o un código T-SQL de bucle iterativo equivalente usando WHILE ).
Otra posible solución para el problema es crear una vista indexada. Esto proporcionará valores distintos con gran eficiencia. La desventaja, como de costumbre, es que cada cambio en la tabla subyacente deberá actualizar el recuento de filas almacenado en la vista materializada.
Cada una de las soluciones presentadas aquí tiene su lugar, dependiendo de los requisitos. Tener una amplia gama de herramientas disponibles es, en términos generales, algo bueno cuando se ajustan las consultas. La mayoría de las veces, elegiría una de las soluciones de modo por lotes porque su rendimiento será bastante predecible sin importar cuántos duplicados estén presentes.