Los parámetros con valores de tabla existen desde SQL Server 2008 y proporcionan un mecanismo útil para enviar varias filas de datos a SQL Server, reunidas como una única llamada parametrizada. Cualquier fila está disponible en una variable de tabla que luego se puede usar en la codificación T-SQL estándar, lo que elimina la necesidad de escribir una lógica de procesamiento especializada para desglosar los datos nuevamente. Por su propia definición, los parámetros con valores de tabla están fuertemente tipados en un tipo de tabla definido por el usuario que debe existir dentro de la base de datos donde se realiza la llamada. Sin embargo, fuertemente tipado no es estrictamente "fuertemente tipado" como cabría esperar, como se demostrará en este artículo, y el rendimiento podría verse afectado como resultado.
Para demostrar los impactos potenciales en el rendimiento de los parámetros con valores de tabla escritos incorrectamente con SQL Server, vamos a crear un tipo de tabla definido por el usuario de ejemplo con la siguiente estructura:
CREATE TYPE dbo.PharmacyData AS TABLE ( Dosage int, Drug varchar(20), FirstName varchar(50), LastName varchar(50), AddressLine1 varchar(250), PhoneNumber varchar(50), CellNumber varchar(50), EmailAddress varchar(100), FillDate datetime );
Luego, necesitaremos una aplicación .NET que usará este tipo de tabla definida por el usuario como parámetro de entrada para pasar datos a SQL Server. Para usar un parámetro con valores de tabla de nuestra aplicación, normalmente se completa un objeto DataTable y luego se pasa como el valor del parámetro con un tipo de SqlDbType.Structured. DataTable se puede crear de varias maneras en el código .NET, pero una forma común de crear la tabla es algo como lo siguiente:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData");
DefaultTable.Columns.Add("Dosage", typeof(int));
DefaultTable.Columns.Add("Drug", typeof(string));
DefaultTable.Columns.Add("FirstName", typeof(string));
DefaultTable.Columns.Add("LastName", typeof(string));
DefaultTable.Columns.Add("AddressLine1", typeof(string));
DefaultTable.Columns.Add("PhoneNumber", typeof(string));
DefaultTable.Columns.Add("CellNumber", typeof(string));
DefaultTable.Columns.Add("EmailAddress", typeof(string));
DefaultTable.Columns.Add("Date", typeof(DateTime)); También puede crear DataTable usando la definición en línea de la siguiente manera:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{"Dosage", typeof(int)},
{"Drug", typeof(string)},
{"FirstName", typeof(string)},
{"LastName", typeof(string)},
{"AddressLine1", typeof(string)},
{"PhoneNumber", typeof(string)},
{"CellNumber", typeof(string)},
{"EmailAddress", typeof(string)},
{"Date", typeof(DateTime)},
},
Locale = CultureInfo.InvariantCulture
}; Cualquiera de estas definiciones del objeto DataTable en .NET se puede usar como un parámetro con valores de tabla para el tipo de datos definido por el usuario que se creó, pero tenga en cuenta la definición de typeof(cadena) para las diversas columnas de cadena; todos estos pueden estar tipeados "correctamente", pero en realidad no están fuertemente tipados para los tipos de datos implementados en el tipo de datos definido por el usuario. Podemos llenar la tabla con datos aleatorios y pasarlos a SQL Server como un parámetro a una declaración SELECT muy simple que devolverá exactamente las mismas filas que la tabla que pasamos, de la siguiente manera:
using (SqlCommand cmd = new SqlCommand("SELECT * FROM @tvp;", connection))
{
var pList = new SqlParameter("@tvp", SqlDbType.Structured);
pList.TypeName = "dbo.PharmacyData";
pList.Value = DefaultTable;
cmd.Parameters.Add(pList);
cmd.ExecuteReader().Dispose();
} Luego podemos usar una interrupción de depuración para poder inspeccionar la definición de DefaultTable durante la ejecución, como se muestra a continuación:
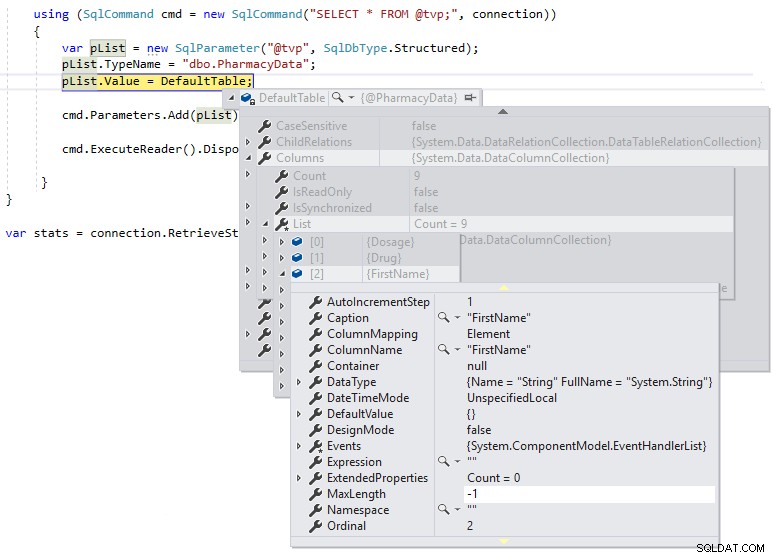
Podemos ver que MaxLength para las columnas de cadena se establece en -1, lo que significa que se pasan de TDS a SQL Server como LOB (objetos grandes) o esencialmente como columnas con tipo de datos MAX, y esto puede afectar el rendimiento de manera negativa. Si cambiamos la definición de .NET DataTable para que esté fuertemente tipada a la definición de esquema del tipo de tabla definida por el usuario de la siguiente manera y observamos la MaxLength de la misma columna usando una interrupción de depuración:
System.Data.DataTable SchemaTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{new DataColumn() { ColumnName = "Dosage", DataType = typeof(int)} },
{new DataColumn() { ColumnName = "Drug", DataType = typeof(string), MaxLength = 20} },
{new DataColumn() { ColumnName = "FirstName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "LastName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "AddressLine1", DataType = typeof(string), MaxLength = 250} },
{new DataColumn() { ColumnName = "PhoneNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "CellNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "EmailAddress", DataType = typeof(string), MaxLength = 100} },
{new DataColumn() { ColumnName = "Date", DataType = typeof(DateTime)} },
},
Locale = CultureInfo.InvariantCulture
};
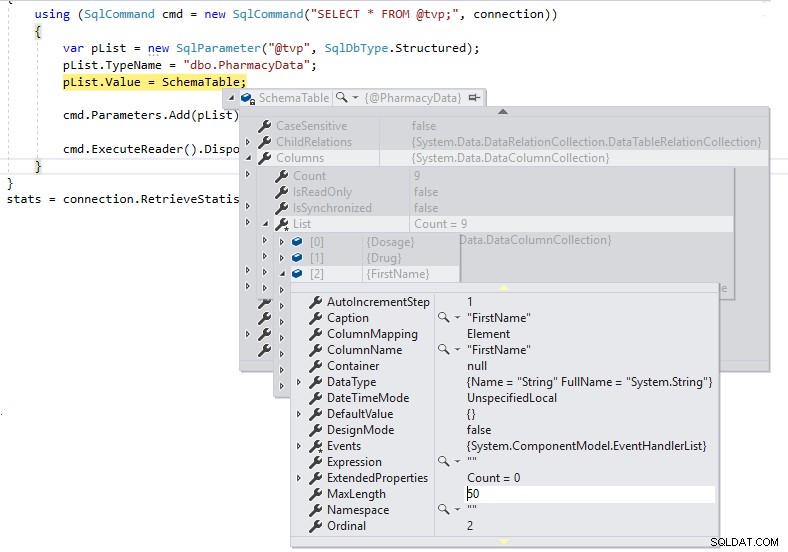
Ahora tenemos longitudes correctas para las definiciones de columna y no las pasaremos como LOB sobre TDS a SQL Server.
¿Cómo afecta esto al rendimiento?, se preguntará. Afecta la cantidad de búferes TDS que se envían a través de la red a SQL Server y también afecta el tiempo de procesamiento general de los comandos.
Usar exactamente el mismo conjunto de datos para las dos tablas de datos y aprovechar el método RetrieveStatistics en el objeto SqlConnection nos permite obtener las métricas de estadísticas ExecutionTime y BuffersSent para las llamadas al mismo comando SELECT, y simplemente usar las dos definiciones diferentes de DataTable como parámetros y llamar al método ResetStatistics del objeto SqlConnection permite borrar las estadísticas de ejecución entre pruebas.
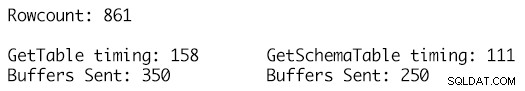
La definición de GetSchemaTable especifica el MaxLength para cada una de las columnas de cadena correctamente donde GetTable simplemente agrega columnas de tipo cadena que tienen un valor MaxLength establecido en -1, lo que da como resultado que se envíen 100 búferes TDS adicionales para 861 filas de datos en la tabla y un tiempo de ejecución de 158 milisegundos en comparación con solo 250 búferes enviados para la definición de DataTable fuertemente tipada y un tiempo de ejecución de 111 milisegundos. Si bien esto puede no parecer mucho en el gran esquema de las cosas, esta es una sola llamada, una sola ejecución y el impacto acumulado a lo largo del tiempo para muchos miles o millones de tales ejecuciones es donde los beneficios comienzan a acumularse y tienen un impacto notable. en el rendimiento de la carga de trabajo y el rendimiento.
Donde esto realmente puede marcar la diferencia es en las implementaciones en la nube en las que se paga por algo más que recursos informáticos y de almacenamiento. Además de tener los costos fijos de los recursos de hardware para Azure VM, SQL Database o AWS EC2 o RDS, existe un costo adicional por el tráfico de red hacia y desde la nube que se agrega a la facturación de cada mes. La reducción de los búferes que atraviesan el cable reducirá el TCO de la solución con el tiempo, y los cambios de código necesarios para implementar estos ahorros son relativamente simples.