Introducción
Lograr registro mínimo usando INSERT...SELECT en un vacío el objetivo del índice agrupado no es tan simple como se describe en la Guía de carga de rendimiento de datos .
Esta publicación proporciona nuevos detalles sobre los requisitos para registro mínimo cuando el objetivo de inserción es un índice agrupado tradicional vacío. (La palabra "tradicional" excluye columnstore y optimizado para memoria ('Hekaton') tablas agrupadas). Para conocer las condiciones que se aplican cuando la tabla de destino es un montón, consulte el artículo anterior de esta serie.
Resumen de tablas agrupadas
La Guía de rendimiento de carga de datos contiene un resumen de alto nivel de las condiciones requeridas para registro mínimo en tablas agrupadas:
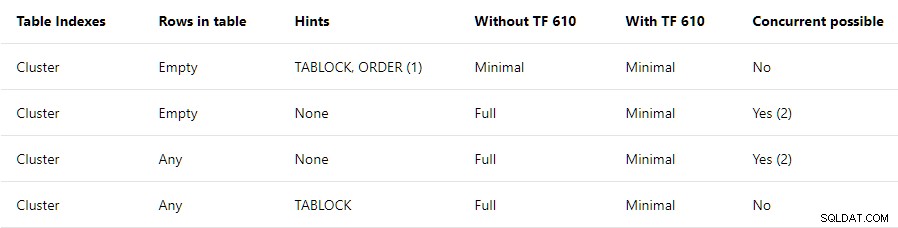
Esta publicación se refiere a la fila superior únicamente . Establece que TABLOCK y ORDER se requieren sugerencias, con una nota que diga:
Si usa BULK INSERT, se debe usar la sugerencia de pedido.
Objetivo vacío con bloqueo de tabla
La fila superior de resumen sugiere que todas las inserciones en un índice agrupado vacío serán registradas mínimamente siempre que TABLOCK y ORDER se especifican sugerencias. El TABLOCK se requiere una sugerencia para habilitar el RowSetBulk instalación como se utiliza para cargas a granel de mesa de montón. Un ORDER se requiere una sugerencia para garantizar que las filas lleguen a la inserción de índice agrupado operador del plan en el índice de destino orden clave . Sin esta garantía, SQL Server podría agregar filas de índice que no están ordenadas correctamente, lo que no sería bueno.
A diferencia de otros métodos de carga masiva, no es posible para especificar el ORDER requerido pista sobre un INSERT...SELECT declaración. Esta pista no es lo mismo como usando un ORDER BY cláusula en INSERT...SELECT declaración. Un ORDER BY cláusula en un INSERT sólo garantiza la forma en que cualquier identidad se asignan valores, no orden de inserción de fila.
Para INSERT...SELECT , SQL Server toma su propia determinación si se debe garantizar que las filas se presenten en el inserto de índice agrupado operador en orden clave o no. El resultado de esta evaluación es visible en los planes de ejecución a través de DMLRequestSort propiedad del Insertar operador. El DMLRequestSort propiedad debe establecerse en verdadero para INSERT...SELECT en un índice para ser registrado mínimamente . Cuando se establece en falso , registro mínimo no puede ocurrir.
Tener DMLRequestSort establecido en verdadero es la única garantía aceptable del orden de entrada de inserción para SQL Server. Se podría inspeccionar el plan de ejecución y predecir que las filas deberían/llegarán/deben llegar en orden de índice agrupado, pero sin las garantías internas específicas proporcionado por DMLRequestSort , esa evaluación no cuenta para nada.
Cuando DMLRequestSort es verdadero , SQL Server puede introducir un Ordenar explícito operador en el plan de ejecución. Si puede garantizar internamente el pedido de otras formas, el Sort puede omitirse. Si hay disponibles alternativas de ordenación y no ordenación, el optimizador realizará una basada en el costo elección. El análisis de costes no tiene en cuenta el registro mínimo directamente; está impulsado por los beneficios esperados de la E/S secuencial y la evitación de la división de páginas.
Condiciones DMLRequestSort
Las dos pruebas siguientes deben pasar para que SQL Server elija establecer DMLRequestSort a verdadero al insertar en un índice agrupado vacío con bloqueo de tabla especificado:
- Una estimación de más de 250 filas en el lado de entrada de la inserción de índice agrupado operador; y
- Un estimado tamaño de datos de más de 2 páginas . El tamaño de datos estimado no es un número entero, por lo que un resultado de 2.001 páginas cumpliría esta condición.
(Esto puede recordarle las condiciones para el registro mínimo del montón , pero el estimado requerido el tamaño de los datos aquí es de dos páginas en lugar de ocho).
Cálculo del tamaño de los datos
El tamaño de datos estimado el cálculo aquí está sujeto a las mismas peculiaridades descritas en el artículo anterior para montones, excepto que el RID de 8 bytes no está presente.
Para SQL Server 2012 y versiones anteriores, esto significa 5 bytes adicionales por fila se incluyen en el cálculo del tamaño de los datos:un byte para un bit interno flag y cuatro bytes para el uniquifier (utilizado en el cálculo incluso para índices únicos, que no almacenan un uniquificador ).
Para SQL Server 2014 y versiones posteriores, el uniquificador se omite correctamente para único índices, pero el un byte adicional para el bit interno se conserva la bandera.
Demostración
El siguiente script debe ejecutarse en una instancia de desarrollo de SQL Server en una nueva base de datos de prueba configurado para usar el SIMPLE o BULK_LOGGED modelo de recuperación.
La demostración carga 268 filas en una nueva tabla agrupada usando INSERT...SELECT con TABLOCK e informes sobre los registros de transacciones generados.
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- Clear the log
CHECKPOINT;
GO
-- Insert rows
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (268)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
(Si ejecuta el script en SQL Server 2012 o anterior, cambie el TOP cláusula en el guión de 268 a 252, por razones que se explicarán en un momento).
El resultado muestra que todas las filas insertadas fueron completamente registradas a pesar del vacío tabla agrupada de destino y TABLOCK pista:
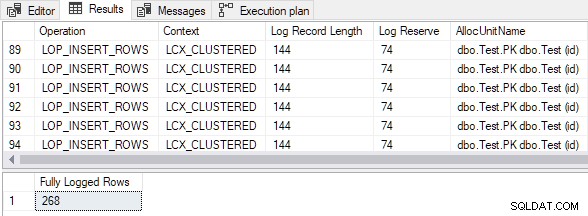
Tamaño de datos de inserción calculado
Las propiedades del plan de ejecución de la inserción de índice agrupado el operador muestra que DMLRequestSort se establece en falso . Esto se debe a que aunque el número estimado de filas a insertar es superior a 250 (cumpliendo el primer requisito), el calculado el tamaño de los datos no superar dos páginas de 8 KB.
Los detalles del cálculo (para SQL Server 2014 en adelante) son los siguientes:
- Total de longitud fija tamaño de columna =54 bytes :<último>
- Tipo id 104
bit=1 byte (interno). - Escriba id 56
integer=4 bytes (idcolumna). - Escriba id 56
integer=4 bytes (c1columna). - Escriba id 175
char(45)=45 bytes (paddingcolumna).
El tamaño de fila calculado (61 bytes) difiere del tamaño de almacenamiento de fila real (60 bytes) por el byte adicional de metadatos internos presentes en el flujo de inserción. El cálculo tampoco tiene en cuenta los 96 bytes utilizados en cada página por el encabezado de página, u otras cosas como la sobrecarga de versiones de fila. El mismo cálculo en SQL Server 2012 agrega 4 bytes adicionales por fila para el uniquificador (que no está presente en los índices únicos como se mencionó anteriormente). Los bytes adicionales significan que caben menos filas en cada página:
- Tamaño de fila calculado =61 + 4 =65 bytes .
- Tamaño de datos calculado =65 bytes * 252 filas =16 380 bytes
- Páginas de datos calculados =16 380/8192 =1,99951171875 .
Cambiando el TOP cláusula de 268 filas a 269 (o de 252 a 253 para 2012) hace que el cálculo del tamaño de datos esperado simplemente propina sobre el umbral mínimo de 2 páginas:
- Servidor SQL 2014
- 61 bytes * 269 filas =16 409 bytes.
- 16.409 / 8192 =2,0030517578125 páginas.
- Servidor SQL 2012
- 65 bytes * 253 filas =16 445 bytes.
- 16.445 / 8192 =2,0074462890625 páginas.
Con la segunda condición ahora también satisfecha, DMLRequestSort se establece en verdadero y registro mínimo se logra, como se muestra en el siguiente resultado:
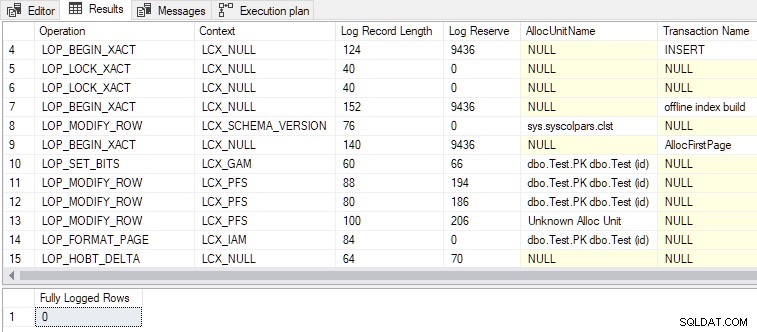
Algunos otros puntos de interés:
- Se genera un total de 79 entradas de registro, en comparación con 328 para la versión de registro completo. Menos entradas de registro son el resultado esperado de un registro mínimo.
- El
LOP_BEGIN_XACTregistros en el registrado mínimamente los registros reservan una cantidad comparativamente grande de espacio de registro (9436 bytes cada uno). - Uno de los nombres de transacciones enumerados en los registros es “construcción de índice sin conexión” . Si bien no pedimos que se creara un índice como tal, la carga masiva de filas en un índice vacío es esencialmente la misma operación.
- El completamente registrado insert toma un bloqueo exclusivo a nivel de tabla (
Tab-X), mientras que el registrado mínimamente insertar toma la modificación del esquema (Sch-M) como lo hace una compilación de índice fuera de línea 'real'. - Carga masiva de una tabla agrupada vacía mediante
INSERT...SELECTconTABLOCKyDMRequestSortestablecido en verdadero utiliza elRowsetBulkmecanismo, al igual que el mínimamente registrado montones de cargas en el artículo anterior.
Estimaciones de cardinalidad
Cuidado con las estimaciones de baja cardinalidad en el inserto de índice agrupado operador. Si se requiere alguno de los umbrales para establecer DMLRequestSort a verdadero no se alcanza debido a una estimación de cardinalidad inexacta, la inserción será registrada por completo , independientemente del número real de filas y el tamaño total de los datos encontrados en el momento de la ejecución.
Por ejemplo, cambiando el TOP cláusula en el script de demostración para usar una variable da como resultado una cardinalidad fija suposición de 100 filas, que está por debajo del mínimo de 251 filas:
-- Insert rows
DECLARE @NumRows bigint = 269;
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (@NumRows)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV; Planificación de almacenamiento en caché
El DMLRequestSort la propiedad se guarda como parte del plan en caché. Cuando un plan en caché se reutiliza , el valor de DMLRequestSort no se vuelve a calcular en el momento de la ejecución, a menos que se produzca una recompilación. Tenga en cuenta que las recompilaciones no ocurren para TRIVIAL planes basados en cambios en estadísticas o cardinalidad de tablas.
Una forma de evitar cualquier comportamiento inesperado debido al almacenamiento en caché es usar una OPTION (RECOMPILE) insinuación. Esto garantizará la configuración adecuada para DMLRequestSort se vuelve a calcular, a costa de una compilación en cada ejecución.
Bandera de seguimiento
Es posible forzar DMLRequestSort para establecerse en verdadero configurando undocumented and unsupported trace flag 2332, como escribí en Optimización de consultas T-SQL que cambian datos. Desafortunadamente, esto no afectar registro mínimo elegibilidad para tablas agrupadas vacías:el inserto aún debe estimarse en más de 250 filas y 2 páginas. Esta marca de seguimiento afecta a otros registro mínimo escenarios, que se tratan en la parte final de esta serie.
Resumen
Carga masiva de un vacío índice agrupado usando INSERT...SELECT reutiliza el RowsetBulk mecanismo utilizado para cargar tablas de montones de forma masiva. Esto requiere el bloqueo de la tabla (normalmente se logra con un TABLOCK sugerencia) y un ORDER insinuación. No hay forma de agregar un ORDER sugerencia a un INSERT...SELECT declaración. Como consecuencia, lograr registro mínimo en una tabla agrupada vacía requiere que DMLRequestSort propiedad del inserto de índice agrupado el operador se establece en verdadero . Esto garantiza a SQL Server esas filas presentadas a Insert el operador llegará en el orden de clave de índice de destino. El efecto es el mismo que cuando se usa el ORDER sugerencia disponible para otros métodos de inserción masiva como BULK INSERT y bcp .
Para DMLRequestSort para establecerse en verdadero , debe haber:
- Más de 250 filas estimado para ser insertado; y
- Un estimado insertar tamaño de datos de más de dos páginas .
El estimado insertar cálculo de tamaño de datos no hacer coincidir el resultado de multiplicar el plan de ejecución número estimado de filas y tamaño de fila estimado propiedades en la entrada de Insert operador. El cálculo interno (incorrectamente) incluye una o más columnas internas en el flujo de inserción, que no se conservan en el índice final. El cálculo interno tampoco tiene en cuenta los encabezados de página u otros gastos generales como el control de versiones de filas.
Al probar o depurar registro mínimo tenga cuidado con las estimaciones de baja cardinalidad y recuerde que la configuración de DMLRequestSort se almacena en caché como parte del plan de ejecución.
La parte final de esta serie detalla las condiciones requeridas para lograr tala mínima sin usar RowsetBulk mecanismo. Estos corresponden directamente a las nuevas instalaciones agregadas bajo el indicador de rastreo 610 a SQL Server 2008, luego se cambiaron para que estén activadas de forma predeterminada desde SQL Server 2016 en adelante.