En 2014, comencé una serie de publicaciones de blog aquí para hablar sobre tipos de espera específicos y lo que significan y no significan. Eso me dio la idea de crear las bibliotecas de espera y pestillos que mantengo (más sobre esto más adelante).
Si estás leyendo esto y pensando "¿de qué está hablando?" entonces esta publicación es para ti. Voy a presentarle las estadísticas de espera y explicar lo importantes que son para solucionar problemas de rendimiento de la carga de trabajo en SQL Server.
Programación
La ejecución del código interno de SQL Server se realiza mediante un mecanismo llamado threads . Cada subproceso puede ejecutar código de SQL Server y varios subprocesos se coordinan juntos cuando una consulta se ejecuta en paralelo. Estos subprocesos se crean cuando se inicia SQL Server, según la cantidad de núcleos de procesador disponibles para que los use SQL Server.
Los hilos se colocan en un programador cuando se inicia una consulta, con un programador por núcleo de procesador, y no salga de ese programador hasta que la consulta haya finalizado. Un programador tiene tres "partes" básicas:
- El procesador , que tiene exactamente un subproceso actualmente ejecutando código.
- La lista de camareros , que tiene todos los subprocesos que básicamente están atascados, esperando que un recurso en particular esté disponible.
- La cola ejecutable , que tiene todos los subprocesos que pueden ejecutarse pero que están esperando para entrar en el procesador.
Los subprocesos pasan del estado 1 al 2 al 3 al 1, una y otra vez hasta que finaliza la consulta.
Espera
Desde nuestra perspectiva, la parte más interesante de la programación es cuando un subproceso tiene que esperar un recurso antes de poder continuar. Algunos ejemplos de esto son:
- Un subproceso necesita leer una página y la página no está en la memoria, por lo que el subproceso emite una E/S física asíncrona y luego tiene que esperar, fuera del procesador, hasta que se complete la E/S.
- Un subproceso necesita adquirir un bloqueo compartido en una fila para leerlo, pero otro subproceso ya tiene un bloqueo exclusivo conflictivo mientras actualiza la fila.
Cuando un subproceso encuentra la necesidad de un recurso que no puede obtener, no tiene más remedio que detenerse y esperar a que el recurso esté disponible (el mecanismo por el cual se notifica al subproceso sobre la disponibilidad de recursos está más allá del alcance de este artículo). Cuando eso sucede, SQL Server toma nota de por qué el subproceso tuvo que esperar y esto se denomina tipo de espera . Algunos ejemplos de esto son:
- Cuando un subproceso está esperando que una página se lea en la memoria para poder leerla, el tipo de espera es PAGEIOLATCH_SH (si el hilo está esperando una página que cambiará, el tipo de espera es PAGEIOLATCH_EX ).
- Cuando un subproceso espera un bloqueo compartido en una fila, el tipo de espera es LCK_M_S (modo de bloqueo-compartir)
SQL Server también realiza un seguimiento de cuánto tiempo tiene que esperar el subproceso. Esto se denomina tiempo de espera del recurso , y generalmente se conoce simplemente como el tiempo de espera .
Estadísticas de espera
El conjunto general de métricas de cuántos subprocesos han esperado qué recursos y durante cuánto tiempo en promedio se denomina estadísticas de espera . Esta información es extremadamente útil para solucionar problemas de rendimiento de la carga de trabajo, ya que puede ver fácilmente dónde pueden estar los cuellos de botella en el rendimiento.
La idea básica es que SQL Server tiene la información sobre por qué los subprocesos deben detenerse y esperar, y qué están esperando. Por lo tanto, en lugar de tener que adivinar dónde comenzar a solucionar problemas, un análisis cuidadoso de las estadísticas de espera generalmente puede indicarle la dirección a seguir.
Por ejemplo, si la mayoría de las esperas en el servidor son PAGEIOLATCH_SH , esto puede indicar que hay presión de memoria en el servidor, o que hay consultas que realizan escaneos de tablas grandes en lugar de usar índices no agrupados, o que hay un problema con el subsistema de E/S subyacente, o una serie de otras razones.
Hay una gran cantidad de tipos de espera, pero la mayoría de ellos no aparecen con mucha frecuencia, por lo que hay un conjunto básico que verá una y otra vez en sus servidores. Comprender lo que significan y cómo investigarlos es fundamental para que no sucumba a lo que yo llamo "ajuste de rendimiento instintivo" y pierda tiempo y esfuerzo tratando de solucionar un problema que en realidad no es un problema. Escribí una serie de publicaciones de blog aquí que entran en detalles allí, y Aaron Bertrand también escribió una publicación de resumen de las 10 principales estadísticas de espera el año pasado.
Seguimiento de esperas
Hay varias formas de realizar un seguimiento de las esperas. La más simple es mirar qué esperas están ocurriendo en el servidor en este momento, usando una secuencia de comandos que examina sys.dm_os_waiting_tasks DMV. Puede encontrar un script para hacer eso aquí, y tiene URL generadas automáticamente en la biblioteca de espera.
Otra forma es mirar las estadísticas de espera agregadas para todo el servidor, con un script que examina los sys.dm_os_wait_stats DMV. Puede encontrar un script para hacer eso aquí, y tiene URL generadas automáticamente en la biblioteca de espera. Sin embargo, debe tener cuidado con ese método, ya que mostrará todas las esperas que se han producido desde que se inició el servidor. Una mejor manera es realizar un seguimiento de las esperas en intervalos pequeños, digamos media hora, y aquí hay un script para hacerlo.
También puede obtener estadísticas de espera con el complemento Server Reports de la nueva herramienta Azure Data Studio y con Query Store desde SQL Server 2017 en adelante.
Recuerde, aún debe comprender qué significan los tipos de espera una vez que haya recopilado las métricas.
Recursos de espera
Para ayudar con esto, y debido a que Microsoft no tiene documentación sobre cómo interpretar las estadísticas de espera, en 2016 lancé una biblioteca de tipos de espera, con detalles de cientos de tipos de espera comunes y cómo solucionarlos. Puede acceder a la biblioteca en https://www.SQLskills.com/help/waits. Y luego, en 2017, SentryOne creó un sistema automatizado para proporcionar una infografía para cada página de la biblioteca que puede usar rápidamente para ver si el tipo de espera que le interesa es realmente común o no (consulte esta publicación para obtener más detalles). . A continuación se muestra una infografía de ejemplo para PAGEIOLATCH_SH tipo de espera:
En el eje horizontal hay una escala (conmutable entre lineal y logarítmica) de qué porcentaje de instancias (monitoreadas de forma remota por SentryOne) experimentaron esta espera durante el mes calendario anterior, y en el eje vertical está el porcentaje de tiempo que aquellas instancias que experimentaron ese wait en realidad tenía un hilo esperando ese tipo de espera.
Otro recurso para ayudarlo a comprender las esperas es un curso de capacitación en línea que grabé para Pluralsight; consulte aquí.
Como mínimo, debe leer las diversas publicaciones de blog en las secciones Estadísticas de espera y Seguimiento de esperas anteriores.
Seguimiento de esperas con las herramientas de SentryOne
SQL Sentry realiza un seguimiento automático de las esperas a nivel de instancia a lo largo del tiempo, para que no tenga que detectar esperas elevadas "en el acto". ¿Alguien se quejó de un sistema lento ayer por la tarde o de un informe que se agotó el martes pasado? No hay problema. Puede profundizar en todas las esperas para cualquier punto en el tiempo o en un rango, y correlacionarlas con varias otras métricas de rendimiento recopiladas en ese momento, ya sean otras tendencias en el tablero, como respaldo o actividad de E/S de la base de datos, saltando a todos los principales comandos SQL que se estaban ejecutando en la misma ventana, investigando bloqueos de ejecución prolongada o usar líneas de base para comparar el perfil de espera con otros períodos.
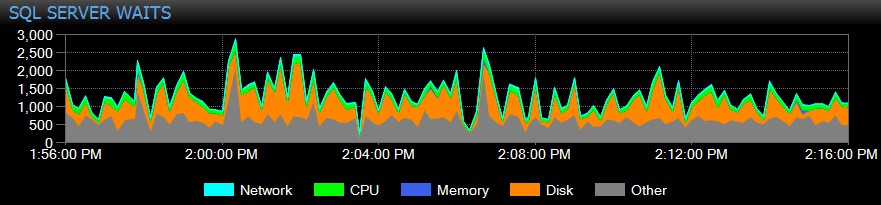
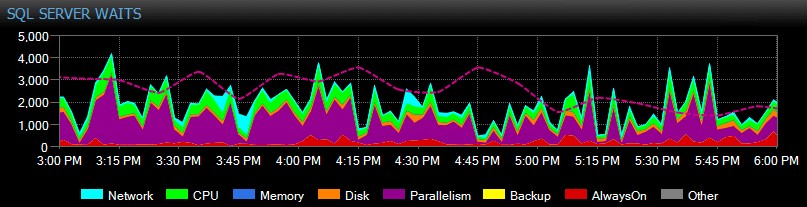
Incluso puede personalizar las esperas que se recopilan o no, cambiar las categorías que se presentan visualmente y crear alertas y/o respuestas inteligentes para escenarios de espera específicos. Muchos de nuestros clientes utilizan SQL Sentry para centrarse en problemas reales de rendimiento relacionados con las esperas, ya que les permite ignorar gran parte del ruido que es simplemente la actividad normal de subprocesos de SQL Server.
Resumen
Como puede ver en la información anterior, las esperas siempre ocurren en SQL Server, porque así es como funcionan la programación de subprocesos y los sistemas de subprocesos múltiples. Son una de las herramientas más poderosas en su caja de herramientas de solución de problemas, por lo que si aún no las está utilizando, ahora es el momento de comenzar. La curva de aprendizaje es corta y empinada:una vez que haya ejecutado las diversas consultas y herramientas varias veces, aprenderá rápidamente a hacerlo, y luego se trata de leer las guías para las esperas que está viendo y determinando si son un problema o no.
¡Feliz resolución de problemas!