En PASS Summit hace unas semanas, Microsoft lanzó CTP2.1 de SQL Server 2019, y una de las grandes mejoras de funciones que se incluye en CTP es Scalar UDF Inlining. Antes de esta versión, quería jugar con la diferencia de rendimiento entre la inserción de UDF escalares y la ejecución RBAR (fila por fila agonizante) de UDF escalares en versiones anteriores de SQL Server y encontré una opción de sintaxis para el CREAR FUNCIÓN declaración en SQL Server Books Online que nunca había visto antes.
El DDL para CREATE FUNCTION admite una cláusula WITH para las opciones de función y, mientras leía los Libros en línea, noté que la sintaxis incluía lo siguiente:
-- Transact-SQL Function Clauses
<function_option>::=
{
[ ENCRYPTION ]
| [ SCHEMABINDING ]
| [ RETURNS NULL ON NULL INPUT | CALLED ON NULL INPUT ]
| [ EXECUTE_AS_Clause ]
} Tenía mucha curiosidad acerca de RETURNS NULL ON NULL INPUT opción de función, así que decidí hacer algunas pruebas. Me sorprendió mucho descubrir que en realidad es una forma de optimización UDF escalar que ha estado en el producto desde al menos SQL Server 2008 R2.
Resulta que si sabe que una UDF escalar siempre devolverá un resultado NULL cuando se proporciona una entrada NULL, la UDF SIEMPRE debe crearse con RETURNS NULL ON NULL INPUT opción, porque entonces SQL Server ni siquiera ejecuta la definición de la función en absoluto para las filas donde la entrada es NULL, lo que provoca un cortocircuito y evita la ejecución desperdiciada del cuerpo de la función.
Para mostrarle este comportamiento, voy a usar una instancia de SQL Server 2017 con la última actualización acumulativa aplicada y AdventureWorks2017 base de datos de GitHub (puede descargarla desde aquí) que se envía con un dbo.ufnLeadingZeros función que simplemente agrega ceros iniciales al valor de entrada y devuelve una cadena de ocho caracteres que incluye esos ceros iniciales. Voy a crear una nueva versión de esa función que incluye RETURNS NULL ON NULL INPUT opción para poder compararla con la función original para el rendimiento de ejecución.
USE [AdventureWorks2017];
GO
CREATE FUNCTION [dbo].[ufnLeadingZeros_new](
@Value int
)
RETURNS varchar(8)
WITH SCHEMABINDING, RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE @ReturnValue varchar(8);
SET @ReturnValue = CONVERT(varchar(8), @Value);
SET @ReturnValue = REPLICATE('0', 8 - DATALENGTH(@ReturnValue)) + @ReturnValue;
RETURN (@ReturnValue);
END;
GO Con el fin de probar las diferencias de rendimiento de ejecución dentro del motor de base de datos de las dos funciones, decidí crear una sesión de eventos extendidos en el servidor para rastrear el sqlserver.module_end evento, que se activa al final de cada ejecución de la UDF escalar para cada fila. Esto me permitió demostrar la semántica de procesamiento fila por fila y también me permitió rastrear cuántas veces se invocó realmente la función durante la prueba. Decidí recopilar también el sql_batch_completed y sql_statement_completed eventos y filtrar todo por session_id para asegurarme de que solo estaba capturando información relacionada con la sesión en la que realmente estaba ejecutando las pruebas (si desea replicar estos resultados, deberá cambiar el 74 en todos los lugares en el código a continuación a cualquier ID de sesión su prueba se ejecutará el código). La sesión del evento está usando TRACK_CAUSALITY para que sea fácil contar cuántas ejecuciones de la función ocurrieron a través de activity_id.seq_no valor para los eventos (que aumenta en uno por cada evento que satisfaga el session_id filtro).
CREATE EVENT SESSION [Session72] ON SERVER ADD EVENT sqlserver.module_end( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_batch_completed( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_batch_starting( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_statement_completed( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_statement_starting( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))) WITH (TRACK_CAUSALITY=ON) GO
Una vez que comencé la sesión del evento y abrí Live Data Viewer en Management Studio, ejecuté dos consultas; uno que usa la versión original de la función para rellenar con ceros el CurrencyRateID columna en Sales.SalesOrderHeader y la nueva función para producir la misma salida pero usando RETURNS NULL ON NULL INPUT y capturé la información del Plan de Ejecución Real para comparar.
SELECT SalesOrderID, dbo.ufnLeadingZeros(CurrencyRateID) FROM Sales.SalesOrderHeader; GO SELECT SalesOrderID, dbo.ufnLeadingZeros_new(CurrencyRateID) FROM Sales.SalesOrderHeader; GO
La revisión de los datos de Extended Events mostró un par de cosas interesantes. Primero, la función original se ejecutó 31 465 veces (desde el recuento de module_end eventos) y el tiempo total de CPU para sql_statement_completed el evento fue de 204ms con 482ms de duración.
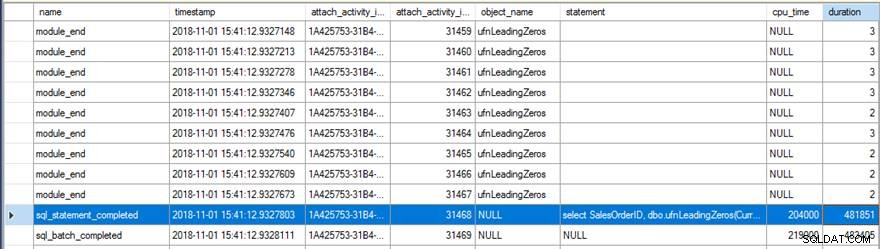
La nueva versión con RETURNS NULL ON NULL INPUT opción especificada solo se ejecutó 13 976 veces (nuevamente, desde el recuento de module_end eventos) y el tiempo de CPU para sql_statement_completed el evento fue de 78ms con 359ms de duración.

Encontré esto interesante, así que para verificar los recuentos de ejecución ejecuté la siguiente consulta para contar NOT NULL filas de valor, filas de valor NULL y filas de total en Sales.SalesOrderHeader mesa.
SELECT SUM(CASE WHEN CurrencyRateID IS NOT NULL THEN 1 ELSE 0 END) AS NOTNULL, SUM(CASE WHEN CurrencyRateID IS NULL THEN 1 ELSE 0 END) AS NULLVALUE, COUNT(*) FROM Sales.SalesOrderHeader;
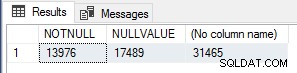
Estos números corresponden exactamente al número de module_end eventos para cada una de las pruebas, por lo que esta es definitivamente una optimización de rendimiento muy simple para UDF escalares que debe usarse si sabe que el resultado de la función será NULL si los valores de entrada son NULL, para cortocircuitar / omitir la ejecución de la función completamente para esas filas.
La información de QueryTimeStats en los planes de ejecución reales también reflejó las ganancias de rendimiento:
<QueryTimeStats CpuTime="204" ElapsedTime="482" UdfCpuTime="160" UdfElapsedTime="218" /> <QueryTimeStats CpuTime="78" ElapsedTime="359" UdfCpuTime="52" UdfElapsedTime="64" />
Esta es una reducción bastante significativa solo en el tiempo de la CPU, lo que puede ser un problema importante para algunos sistemas.
El uso de UDF escalares es un antipatrón de diseño bien conocido para el rendimiento y existe una variedad de métodos para reescribir el código para evitar su uso y el impacto en el rendimiento. Pero si ya están en su lugar y no se pueden cambiar o eliminar fácilmente, simplemente vuelva a crear el UDF con RETURNS NULL ON NULL INPUT La opción podría ser una forma muy sencilla de mejorar el rendimiento si hay muchas entradas NULL en el conjunto de datos donde se usa el UDF.