Las tareas de brechas e islas son desafíos de consulta clásicos en los que necesita identificar rangos de valores faltantes y rangos de valores existentes en una secuencia. La secuencia a menudo se basa en alguna fecha, o valores de fecha y hora, que normalmente deberían aparecer en intervalos regulares, pero faltan algunas entradas. La tarea de intervalos busca los períodos que faltan y la tarea de islas busca los períodos existentes. Cubrí muchas soluciones a lagunas y tareas de islas en mis libros y artículos en el pasado. Recientemente, mi amigo, Adam Machanic, me presentó un nuevo desafío de islas especiales, y resolverlo requirió un poco de creatividad. En este artículo presento el desafío y la solución que se me ocurrió.
El desafío
En su base de datos, realiza un seguimiento de los servicios que admite su empresa en una tabla llamada CompanyServices, y cada servicio normalmente informa aproximadamente una vez por minuto que está en línea en una tabla llamada EventLog. El siguiente código crea estas tablas y las completa con pequeños conjuntos de datos de muestra:
SET NOCOUNT ON; USE tempdb; IF OBJECT_ID(N'dbo.EventLog') IS NOT NULL DROP TABLE dbo.EventLog; IF OBJECT_ID(N'dbo.CompanyServices') IS NOT NULL DROP TABLE dbo.CompanyServices; CREATE TABLE dbo.CompanyServices ( serviceid INT NOT NULL, CONSTRAINT PK_CompanyServices PRIMARY KEY(serviceid) ); GO INSERT INTO dbo.CompanyServices(serviceid) VALUES(1), (2), (3); CREATE TABLE dbo.EventLog ( logid INT NOT NULL IDENTITY, serviceid INT NOT NULL, logtime DATETIME2(0) NOT NULL, CONSTRAINT PK_EventLog PRIMARY KEY(logid) ); GO INSERT INTO dbo.EventLog(serviceid, logtime) VALUES (1, '20180912 08:00:00'), (1, '20180912 08:01:01'), (1, '20180912 08:01:59'), (1, '20180912 08:03:00'), (1, '20180912 08:05:00'), (1, '20180912 08:06:02'), (2, '20180912 08:00:02'), (2, '20180912 08:01:03'), (2, '20180912 08:02:01'), (2, '20180912 08:03:00'), (2, '20180912 08:03:59'), (2, '20180912 08:05:01'), (2, '20180912 08:06:01'), (3, '20180912 08:00:01'), (3, '20180912 08:03:01'), (3, '20180912 08:04:02'), (3, '20180912 08:06:00'); SELECT * FROM dbo.EventLog;
La tabla EventLog se rellena actualmente con los siguientes datos:
logid serviceid logtime ----------- ----------- --------------------------- 1 1 2018-09-12 08:00:00 2 1 2018-09-12 08:01:01 3 1 2018-09-12 08:01:59 4 1 2018-09-12 08:03:00 5 1 2018-09-12 08:05:00 6 1 2018-09-12 08:06:02 7 2 2018-09-12 08:00:02 8 2 2018-09-12 08:01:03 9 2 2018-09-12 08:02:01 10 2 2018-09-12 08:03:00 11 2 2018-09-12 08:03:59 12 2 2018-09-12 08:05:01 13 2 2018-09-12 08:06:01 14 3 2018-09-12 08:00:01 15 3 2018-09-12 08:03:01 16 3 2018-09-12 08:04:02 17 3 2018-09-12 08:06:00
La tarea de las islas especiales es identificar los períodos de disponibilidad (servicio, hora de inicio, hora de finalización). Un problema es que no hay garantía de que un servicio informe que está en línea exactamente cada minuto; se supone que debe tolerar un intervalo de hasta, digamos, 66 segundos desde la entrada de registro anterior y aun así considerarlo parte del mismo período de disponibilidad (isla). Más allá de los 66 segundos, la nueva entrada de registro inicia un nuevo período de disponibilidad. Entonces, para los datos de muestra de entrada anteriores, se supone que su solución debe devolver el siguiente conjunto de resultados (no necesariamente en este orden):
serviceid starttime endtime ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 2 2018-09-12 08:00:02 2018-09-12 08:06:01 3 2018-09-12 08:00:01 2018-09-12 08:00:01 3 2018-09-12 08:03:01 2018-09-12 08:04:02 3 2018-09-12 08:06:00 2018-09-12 08:06:00
Observe, por ejemplo, cómo la entrada de registro 5 inicia una nueva isla ya que el intervalo desde la entrada de registro anterior es de 120 segundos (> 66), mientras que la entrada de registro 6 no inicia una nueva isla ya que el intervalo desde la entrada anterior es de 62 segundos ( <=66). Otro problema es que Adam quería que la solución fuera compatible con los entornos anteriores a SQL Server 2012, lo que hace que sea un desafío mucho más difícil, ya que no puede usar funciones de agregación de ventana con un marco para calcular totales acumulados y funciones de ventana de compensación. como LAG y LEAD. Como de costumbre, sugiero que intentes resolver el desafío tú mismo antes de ver mis soluciones. Utilice los pequeños conjuntos de datos de muestra para comprobar la validez de sus soluciones. Use el siguiente código para completar sus tablas con grandes conjuntos de datos de muestra (500 servicios, ~10 millones de entradas de registro para probar el rendimiento de sus soluciones):
-- Helper function dbo.GetNums
IF OBJECT_ID(N'dbo.GetNums') IS NOT NULL DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
-- ~10,000,000 intervals
DECLARE
@numservices AS INT = 500,
@logsperservice AS INT = 20000,
@enddate AS DATETIME2(0) = '20180912',
@validinterval AS INT = 60, -- seconds
@normdifferential AS INT = 3, -- seconds
@percentmissing AS FLOAT = 0.01;
TRUNCATE TABLE dbo.EventLog;
TRUNCATE TABLE dbo.CompanyServices;
INSERT INTO dbo.CompanyServices(serviceid)
SELECT A.n AS serviceid
FROM dbo.GetNums(1, @numservices) AS A;
WITH C AS
(
SELECT S.n AS serviceid,
DATEADD(second, -L.n * @validinterval + CHECKSUM(NEWID()) % (@normdifferential + 1), @enddate) AS logtime,
RAND(CHECKSUM(NEWID())) AS rnd
FROM dbo.GetNums(1, @numservices) AS S
CROSS JOIN dbo.GetNums(1, @logsperservice) AS L
)
INSERT INTO dbo.EventLog WITH (TABLOCK) (serviceid, logtime)
SELECT serviceid, logtime
FROM C
WHERE rnd > @percentmissing; Los resultados que proporcionaré para los pasos de mis soluciones asumirán los conjuntos pequeños de datos de muestra, y los números de rendimiento que proporcionaré asumirán los conjuntos grandes.
Todas las soluciones que presentaré se benefician del siguiente índice:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
¡Buena suerte!
Solución 1 para SQL Server 2012+
Antes de cubrir una solución que es compatible con entornos anteriores a SQL Server 2012, cubriré una que requiere un mínimo de SQL Server 2012. La llamaré Solución 1.
El primer paso en la solución es calcular un indicador llamado isstart que es 0 si el evento no inicia una nueva isla y 1 en caso contrario. Esto se puede lograr utilizando la función LAG para obtener el tiempo de registro del evento anterior y verificando si la diferencia de tiempo en segundos entre el evento anterior y el actual es menor o igual que el intervalo permitido. Aquí está el código que implementa este paso:
DECLARE @allowedgap AS INT = 66; -- in seconds
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog; Este código genera el siguiente resultado:
logid serviceid logtime isstart ----------- ----------- --------------------------- ----------- 1 1 2018-09-12 08:00:00 1 2 1 2018-09-12 08:01:01 0 3 1 2018-09-12 08:01:59 0 4 1 2018-09-12 08:03:00 0 5 1 2018-09-12 08:05:00 1 6 1 2018-09-12 08:06:02 0 7 2 2018-09-12 08:00:02 1 8 2 2018-09-12 08:01:03 0 9 2 2018-09-12 08:02:01 0 10 2 2018-09-12 08:03:00 0 11 2 2018-09-12 08:03:59 0 12 2 2018-09-12 08:05:01 0 13 2 2018-09-12 08:06:01 0 14 3 2018-09-12 08:00:01 1 15 3 2018-09-12 08:03:01 1 16 3 2018-09-12 08:04:02 0 17 3 2018-09-12 08:06:00 1
A continuación, un simple total acumulado de la bandera isstart produce un identificador de isla (lo llamaré grp). Aquí está el código que implementa este paso:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
)
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1; Este código genera el siguiente resultado:
logid serviceid logtime isstart grp ----------- ----------- --------------------------- ----------- ----------- 1 1 2018-09-12 08:00:00 1 1 2 1 2018-09-12 08:01:01 0 1 3 1 2018-09-12 08:01:59 0 1 4 1 2018-09-12 08:03:00 0 1 5 1 2018-09-12 08:05:00 1 2 6 1 2018-09-12 08:06:02 0 2 7 2 2018-09-12 08:00:02 1 1 8 2 2018-09-12 08:01:03 0 1 9 2 2018-09-12 08:02:01 0 1 10 2 2018-09-12 08:03:00 0 1 11 2 2018-09-12 08:03:59 0 1 12 2 2018-09-12 08:05:01 0 1 13 2 2018-09-12 08:06:01 0 1 14 3 2018-09-12 08:00:01 1 1 15 3 2018-09-12 08:03:01 1 2 16 3 2018-09-12 08:04:02 0 2 17 3 2018-09-12 08:06:00 1 3
Por último, agrupe las filas por ID de servicio e identificador de isla y devuelva los tiempos de registro mínimo y máximo como la hora de inicio y la hora de finalización de cada isla. Aquí está la solución completa:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1
)
SELECT serviceid, MIN(logtime) AS starttime, MAX(logtime) AS endtime
FROM C2
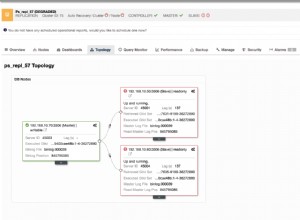
GROUP BY serviceid, grp; Esta solución tardó 41 segundos en completarse en mi sistema y produjo el plan que se muestra en la Figura 1.
 Figura 1:Plan para la Solución 1
Figura 1:Plan para la Solución 1
Como puede ver, ambas funciones de ventana se calculan según el orden del índice, sin necesidad de una clasificación explícita.
Si está utilizando SQL Server 2016 o posterior, puede usar el truco que cubro aquí para habilitar el operador de ventana agregada en modo por lotes mediante la creación de un índice de almacén de columnas filtrado vacío, así:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
La misma solución ahora tarda solo 5 segundos en completarse en mi sistema, produciendo el plan que se muestra en la Figura 2.
 Figura 2:Plan para la solución 1 usando el operador de ventana agregada en modo por lotes
Figura 2:Plan para la solución 1 usando el operador de ventana agregada en modo por lotes
Todo esto es genial, pero como se mencionó, Adam estaba buscando una solución que pudiera ejecutarse en entornos anteriores a 2012.
Antes de continuar, asegúrese de eliminar el índice del almacén de columnas para la limpieza:
DROP INDEX idx_cs ON dbo.EventLog;
Solución 2 para entornos anteriores a SQL Server 2012
Desafortunadamente, antes de SQL Server 2012, no teníamos soporte para funciones de ventana compensada como LAG, ni soporte para calcular totales acumulados con funciones de agregado de ventana con un marco. Esto significa que tendrás que trabajar mucho más duro para encontrar una solución razonable.
El truco que usé es convertir cada entrada de registro en un intervalo artificial cuya hora de inicio es la hora de registro de la entrada y cuya hora de finalización es la hora de registro de la entrada más el intervalo permitido. A continuación, puede tratar la tarea como una tarea de embalaje de intervalo clásico.
El primer paso de la solución calcula los delimitadores de intervalos artificiales y los números de fila que marcan las posiciones de cada uno de los tipos de eventos (counteach). Aquí está el código que implementa este paso:
DECLARE @allowedgap AS INT = 66; SELECT logid, serviceid, logtime AS s, -- important, 's' > 'e', for later ordering DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog;
Este código genera el siguiente resultado:
logid serviceid s e counteach ------ ---------- -------------------- -------------------- ---------- 1 1 2018-09-12 08:00:00 2018-09-12 08:01:06 1 2 1 2018-09-12 08:01:01 2018-09-12 08:02:07 2 3 1 2018-09-12 08:01:59 2018-09-12 08:03:05 3 4 1 2018-09-12 08:03:00 2018-09-12 08:04:06 4 5 1 2018-09-12 08:05:00 2018-09-12 08:06:06 5 6 1 2018-09-12 08:06:02 2018-09-12 08:07:08 6 7 2 2018-09-12 08:00:02 2018-09-12 08:01:08 1 8 2 2018-09-12 08:01:03 2018-09-12 08:02:09 2 9 2 2018-09-12 08:02:01 2018-09-12 08:03:07 3 10 2 2018-09-12 08:03:00 2018-09-12 08:04:06 4 11 2 2018-09-12 08:03:59 2018-09-12 08:05:05 5 12 2 2018-09-12 08:05:01 2018-09-12 08:06:07 6 13 2 2018-09-12 08:06:01 2018-09-12 08:07:07 7 14 3 2018-09-12 08:00:01 2018-09-12 08:01:07 1 15 3 2018-09-12 08:03:01 2018-09-12 08:04:07 2 16 3 2018-09-12 08:04:02 2018-09-12 08:05:08 3 17 3 2018-09-12 08:06:00 2018-09-12 08:07:06 4
El siguiente paso es descentrar los intervalos en una secuencia cronológica de eventos de inicio y finalización, identificados como tipos de eventos 's' y 'e', respectivamente. Tenga en cuenta que la elección de las letras s y e es importante ('s' > 'e' ). Este paso calcula los números de fila que marcan el orden cronológico correcto de ambos tipos de eventos, que ahora están intercalados (cuentan ambos). En caso de que un intervalo termine exactamente donde comienza otro, al colocar el evento de inicio antes del evento de finalización, los empaquetará juntos. Aquí está el código que implementa este paso:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
)
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U; Este código genera el siguiente resultado:
logid serviceid logtime eventtype counteach countboth ------ ---------- -------------------- ---------- ---------- ---------- 1 1 2018-09-12 08:00:00 s 1 1 2 1 2018-09-12 08:01:01 s 2 2 1 1 2018-09-12 08:01:06 e 1 3 3 1 2018-09-12 08:01:59 s 3 4 2 1 2018-09-12 08:02:07 e 2 5 4 1 2018-09-12 08:03:00 s 4 6 3 1 2018-09-12 08:03:05 e 3 7 4 1 2018-09-12 08:04:06 e 4 8 5 1 2018-09-12 08:05:00 s 5 9 6 1 2018-09-12 08:06:02 s 6 10 5 1 2018-09-12 08:06:06 e 5 11 6 1 2018-09-12 08:07:08 e 6 12 7 2 2018-09-12 08:00:02 s 1 1 8 2 2018-09-12 08:01:03 s 2 2 7 2 2018-09-12 08:01:08 e 1 3 9 2 2018-09-12 08:02:01 s 3 4 8 2 2018-09-12 08:02:09 e 2 5 10 2 2018-09-12 08:03:00 s 4 6 9 2 2018-09-12 08:03:07 e 3 7 11 2 2018-09-12 08:03:59 s 5 8 10 2 2018-09-12 08:04:06 e 4 9 12 2 2018-09-12 08:05:01 s 6 10 11 2 2018-09-12 08:05:05 e 5 11 13 2 2018-09-12 08:06:01 s 7 12 12 2 2018-09-12 08:06:07 e 6 13 13 2 2018-09-12 08:07:07 e 7 14 14 3 2018-09-12 08:00:01 s 1 1 14 3 2018-09-12 08:01:07 e 1 2 15 3 2018-09-12 08:03:01 s 2 3 16 3 2018-09-12 08:04:02 s 3 4 15 3 2018-09-12 08:04:07 e 2 5 16 3 2018-09-12 08:05:08 e 3 6 17 3 2018-09-12 08:06:00 s 4 7 17 3 2018-09-12 08:07:06 e 4 8
Como se mencionó, counteach marca la posición del evento solo entre los eventos del mismo tipo, y countboth marca la posición del evento entre los eventos combinados e intercalados de ambos tipos.
Luego, la magia se maneja en el siguiente paso:calcular el conteo de intervalos activos después de cada evento en función de contar cada uno y contar ambos. El número de intervalos activos es el número de eventos de inicio que ocurrieron hasta el momento menos el número de eventos de finalización que ocurrieron hasta el momento. Para los eventos de inicio, contar cada uno le indica cuántos eventos de inicio ocurrieron hasta el momento, y puede calcular cuántos terminaron hasta el momento restando contar cada uno de contar ambos. Entonces, la expresión completa que le indica cuántos intervalos están activos es:
counteach - (countboth - counteach)
Para los eventos finales, counteach te dice cuántos eventos finales ocurrieron hasta el momento, y puedes calcular cuántos comenzaron restando counteach de countboth. Entonces, la expresión completa que le indica cuántos intervalos están activos es:
(countboth - counteach) - counteach
Con la siguiente expresión CASE, calcula la columna contable según el tipo de evento:
CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END En el mismo paso, filtra solo los eventos que representan el inicio y el final de los intervalos empaquetados. Los inicios de los intervalos empaquetados tienen un tipo 's' y un 1 contable. Los finales de los intervalos empaquetados tienen un tipo 'e' y un 0 contable.
Después de filtrar, le quedan pares de eventos de inicio y finalización de intervalos empaquetados, pero cada par se divide en dos filas:una para el evento de inicio y otra para el evento de finalización. Por lo tanto, el mismo paso calcula el identificador de pares usando números de fila, con la fórmula (rownum – 1) / 2 + 1.
Aquí está el código que implementa este paso:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
)
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0); Este código genera el siguiente resultado:
serviceid eventtype logtime grp ----------- ---------- -------------------- ---- 1 s 2018-09-12 08:00:00 1 1 e 2018-09-12 08:04:06 1 1 s 2018-09-12 08:05:00 2 1 e 2018-09-12 08:07:08 2 2 s 2018-09-12 08:00:02 1 2 e 2018-09-12 08:07:07 1 3 s 2018-09-12 08:00:01 1 3 e 2018-09-12 08:01:07 1 3 s 2018-09-12 08:03:01 2 3 e 2018-09-12 08:05:08 2 3 s 2018-09-12 08:06:00 3 3 e 2018-09-12 08:07:06 3
El último paso gira los pares de eventos en una fila por intervalo y resta el espacio permitido de la hora de finalización para generar la hora correcta del evento. Aquí está el código de la solución completa:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; Esta solución tardó 43 segundos en completarse en mi sistema y generó el plan que se muestra en la Figura 3.
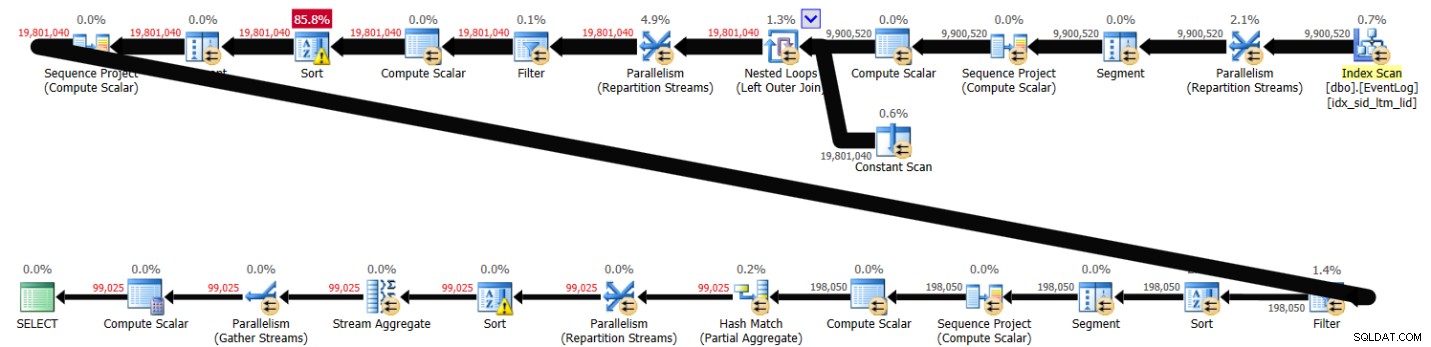 Figura 3:Plan para la solución 2
Figura 3:Plan para la solución 2
Como puede ver, el cálculo del número de la primera fila se calcula según el orden del índice, pero los dos siguientes implican una clasificación explícita. Aun así, el rendimiento no es tan malo considerando que hay alrededor de 10 000 000 de filas involucradas.
Aunque el objetivo de esta solución es usar un entorno anterior a SQL Server 2012, solo por diversión, probé su rendimiento después de crear un índice de almacén de columnas filtrado para ver cómo funciona con el procesamiento por lotes habilitado:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
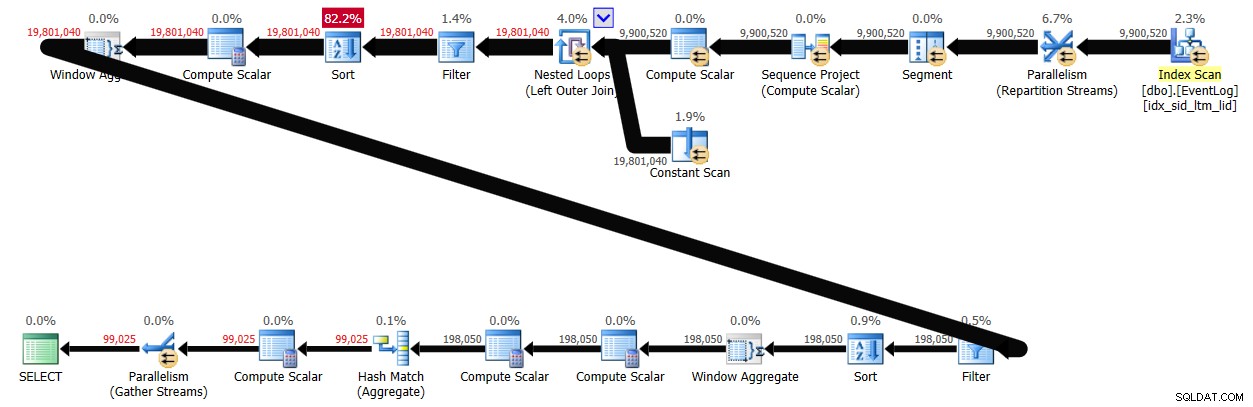
Con el procesamiento por lotes habilitado, esta solución tardó 29 segundos en finalizar en mi sistema, produciendo el plan que se muestra en la Figura 4.
Conclusión
Es natural que cuanto más limitado sea su entorno, más desafiante se vuelve resolver tareas de consulta. El desafío especial de islas de Adam es mucho más fácil de resolver en las versiones más nuevas de SQL Server que en las más antiguas. Pero luego te obligas a usar técnicas más creativas. Entonces, como ejercicio, para mejorar sus habilidades de consulta, podría abordar desafíos con los que ya está familiarizado, pero imponer ciertas restricciones intencionalmente. ¡Nunca sabes con qué tipo de ideas interesantes te puedes topar!