El mes pasado cubrí un desafío de Islas Especiales. La tarea consistía en identificar períodos de actividad para cada ID de servicio, tolerando una brecha de hasta una cantidad de segundos de entrada (@allowedgap ). La advertencia era que la solución tenía que ser compatible con versiones anteriores a 2012, por lo que no podía usar funciones como LAG y LEAD, o agregar funciones de ventana con un marco. Obtuve varias soluciones muy interesantes publicadas en los comentarios de Toby Ovod-Everett, Peter Larsson y Kamil Kosno. Asegúrate de repasar sus soluciones ya que todas son bastante creativas.
Curiosamente, varias de las soluciones se ejecutaron más lentamente con el índice recomendado que sin él. En este artículo propongo una explicación para esto.
Aunque todas las soluciones eran interesantes, aquí quería centrarme en la solución de Kamil Kosno, que es un desarrollador de ETL con Zopa. En su solución, Kamil usó una técnica muy creativa para emular LAG y LEAD sin LAG y LEAD. Probablemente encontrará la técnica útil si necesita realizar cálculos similares a LAG/LEAD utilizando un código compatible con versiones anteriores a 2012.
¿Por qué algunas soluciones son más rápidas sin el índice recomendado?
Como recordatorio, sugerí usar el siguiente índice para respaldar las soluciones al desafío:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Mi solución compatible anterior a 2012 fue la siguiente:
DECLARE @allowedgap AS INT = 66; -- in seconds
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; La Figura 1 tiene el plan para mi solución con el índice recomendado en su lugar.
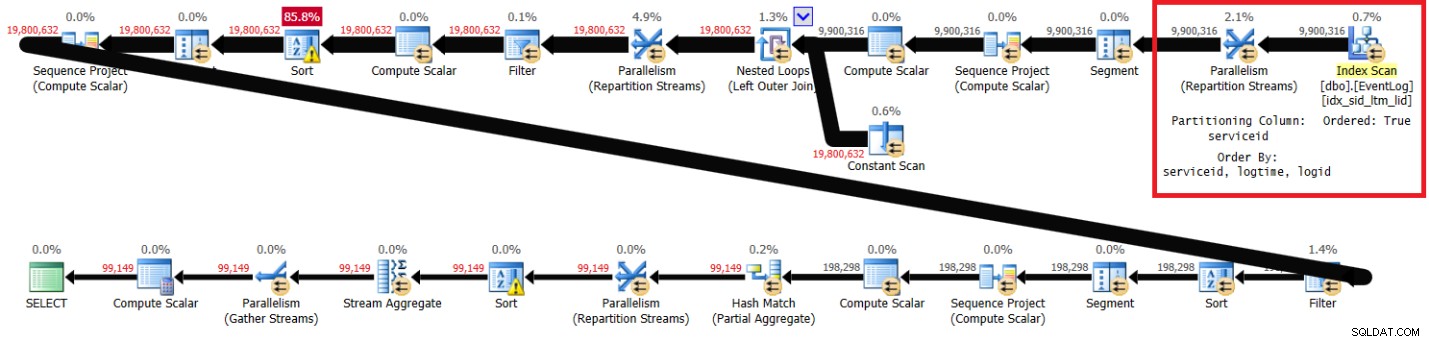 Figura 1:Plan para la solución de Itzik con índice recomendado
Figura 1:Plan para la solución de Itzik con índice recomendado
Tenga en cuenta que el plan analiza el índice recomendado en orden clave (la propiedad Ordered es True), divide los flujos por serviceid mediante un intercambio que conserva el orden y, a continuación, aplica el cálculo inicial de los números de fila basándose en el orden del índice sin necesidad de ordenar. Las siguientes son las estadísticas de rendimiento que obtuve para la ejecución de esta consulta en mi computadora portátil (tiempo transcurrido, tiempo de CPU y espera superior expresado en segundos):
elapsed: 43, CPU: 60, logical reads: 144,120 , top wait: CXPACKET: 166
Luego eliminé el índice recomendado y volví a ejecutar la solución:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
Obtuve el plan que se muestra en la Figura 2.
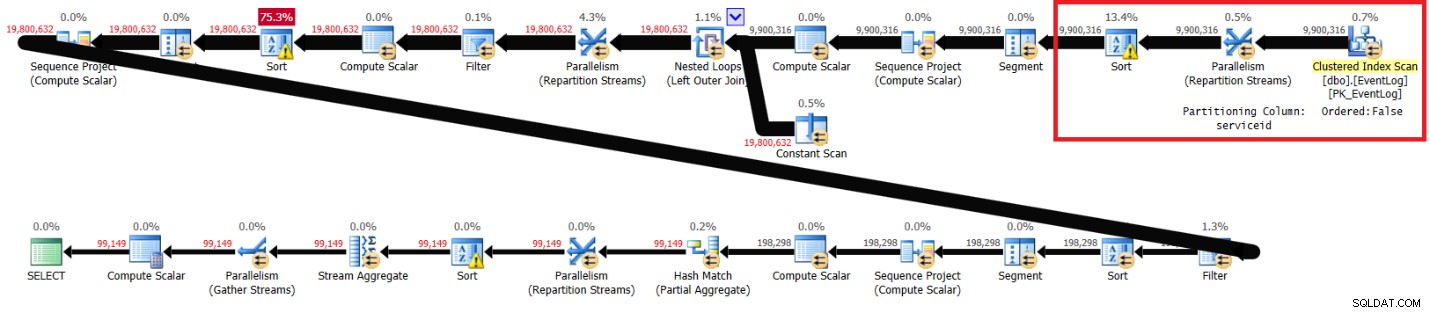 Figura 2:Plan para la solución de Itzik sin índice recomendado
Figura 2:Plan para la solución de Itzik sin índice recomendado
Las secciones resaltadas en los dos planes muestran la diferencia. El plan sin el índice recomendado realiza un análisis desordenado del índice agrupado, divide los flujos por ID de servicio utilizando un intercambio que no conserva el orden y luego ordena las filas según las necesidades de la función de ventana (por ID de servicio, tiempo de registro, ID de registro). El resto del trabajo parece ser el mismo en ambos planos. Pensarías que el plan sin el índice recomendado debería ser más lento ya que tiene un tipo extra que el otro plan no tiene. Pero aquí están las estadísticas de rendimiento que obtuve para este plan en mi computadora portátil:
elapsed: 31, CPU: 89, logical reads: 172,598 , CXPACKET waits: 84
Hay más tiempo de CPU involucrado, lo que en parte se debe a la clasificación adicional; hay más E/S involucradas, probablemente debido a derrames de clasificación adicionales; sin embargo, el tiempo transcurrido es aproximadamente un 30 por ciento más rápido. ¿Qué podría explicar esto? Una forma de intentar resolver esto es ejecutar la consulta en SSMS con la opción Estadísticas de consulta en vivo habilitada. Cuando hice esto, el operador Parallelism (Repartition Streams) más a la derecha terminó en 6 segundos sin el índice recomendado y en 35 segundos con el índice recomendado. La diferencia clave es que el primero obtiene los datos ordenados previamente de un índice y es un intercambio que preserva el pedido. Este último obtiene los datos desordenados y no es un intercambio que preserve el orden. Los intercambios que preservan el orden tienden a ser más caros que los que no lo hacen. Además, al menos en la parte más a la derecha del plan hasta la primera ordenación, la primera entrega las filas en el mismo orden que la columna de partición de intercambio, por lo que no obtiene todos los subprocesos para procesar las filas en paralelo. El último entrega las filas desordenadas, por lo que obtiene todos los subprocesos para procesar las filas realmente en paralelo. Puede ver que la espera principal en ambos planes es CXPACKET, pero en el primer caso el tiempo de espera es el doble que en el último, lo que le indica que el manejo del paralelismo en el último caso es más óptimo. Podría haber otros factores en juego en los que no estoy pensando. Si tiene ideas adicionales que podrían explicar la sorprendente diferencia de rendimiento, compártalas.
En mi computadora portátil, esto dio como resultado que la ejecución sin el índice recomendado fuera más rápida que la que tenía el índice recomendado. Aún así, en otra máquina de prueba, fue al revés. Después de todo, tienes un tipo extra, con potencial de derrame.
Por curiosidad, probé una ejecución en serie (con la opción MAXDOP 1) con el índice recomendado y obtuve las siguientes estadísticas de rendimiento en mi computadora portátil:
elapsed: 42, CPU: 40, logical reads: 143,519
Como puede ver, el tiempo de ejecución es similar al tiempo de ejecución de la ejecución en paralelo con el índice recomendado en su lugar. Solo tengo 4 CPU lógicas en mi computadora portátil. Por supuesto, su kilometraje puede variar con diferentes hardware. El punto es que vale la pena probar diferentes alternativas, incluso con y sin la indexación que crees que debería ayudar. Los resultados son a veces sorprendentes y contradictorios.
La solución de Kamil
La solución de Kamil me intrigó mucho y me gustó especialmente la forma en que emuló LAG y LEAD con una técnica compatible anterior a 2012.
Aquí está el código que implementa el primer paso en la solución:
SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog;
Este código genera el siguiente resultado (que muestra solo datos para serviceid 1):
serviceid logtime end_time start_time ---------- -------------------- --------- ----------- 1 2018-09-12 08:00:00 1 0 1 2018-09-12 08:01:01 2 1 1 2018-09-12 08:01:59 3 2 1 2018-09-12 08:03:00 4 3 1 2018-09-12 08:05:00 5 4 1 2018-09-12 08:06:02 6 5 ...
Este paso calcula dos números de fila que son uno aparte para cada fila, divididos por serviceid y ordenados por logtime. El número de fila actual representa la hora de finalización (llámese end_time), y el número de fila actual menos uno representa la hora de inicio (llámese start_time).
El siguiente código implementa el segundo paso de la solución:
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT *
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U; Este paso genera el siguiente resultado:
serviceid logtime rownum time_type ---------- -------------------- ------- ----------- 1 2018-09-12 08:00:00 0 start_time 1 2018-09-12 08:00:00 1 end_time 1 2018-09-12 08:01:01 1 start_time 1 2018-09-12 08:01:01 2 end_time 1 2018-09-12 08:01:59 2 start_time 1 2018-09-12 08:01:59 3 end_time 1 2018-09-12 08:03:00 3 start_time 1 2018-09-12 08:03:00 4 end_time 1 2018-09-12 08:05:00 4 start_time 1 2018-09-12 08:05:00 5 end_time 1 2018-09-12 08:06:02 5 start_time 1 2018-09-12 08:06:02 6 end_time ...
Este paso separa cada fila en dos filas, duplicando cada entrada de registro, una vez para el tipo de tiempo start_time y otra para end_time. Como puede ver, además de los números de fila mínimo y máximo, cada número de fila aparece dos veces:una con la hora de registro del evento actual (start_time) y otra con la hora de registro del evento anterior (end_time).
El siguiente código implementa el tercer paso de la solución:
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT *
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P; Este código genera el siguiente resultado:
serviceid rownum start_time end_time ----------- -------------------- --------------------------- --------------------------- 1 0 2018-09-12 08:00:00 NULL 1 1 2018-09-12 08:01:01 2018-09-12 08:00:00 1 2 2018-09-12 08:01:59 2018-09-12 08:01:01 1 3 2018-09-12 08:03:00 2018-09-12 08:01:59 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 5 2018-09-12 08:06:02 2018-09-12 08:05:00 1 6 NULL 2018-09-12 08:06:02 ...
Este paso gira los datos, agrupando pares de filas con el mismo número de fila y devolviendo una columna para la hora del registro de eventos actual (start_time) y otra para la hora del registro de eventos anterior (end_time). Esta parte emula efectivamente una función LAG.
El siguiente código implementa el cuarto paso de la solución:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
)
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap; Este código genera el siguiente resultado:
serviceid rownum start_time end_time start_time_grp end_time_grp ---------- ------- -------------------- -------------------- --------------- ------------- 1 0 2018-09-12 08:00:00 NULL 1 0 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 1 1 6 NULL 2018-09-12 08:06:02 3 2 ...
Este paso filtra pares donde la diferencia entre la hora de finalización anterior y la hora de inicio actual es mayor que el espacio permitido y filas con un solo evento. Ahora necesita conectar la hora de inicio de cada fila actual con la hora de finalización de la fila siguiente. Esto requiere un cálculo tipo LEAD. Para lograr esto, el código, nuevamente, crea números de fila separados por uno, solo que esta vez el número de fila actual representa la hora de inicio (start_time_grp) y el número de fila actual menos uno representa la hora de finalización (end_time_grp).
Como antes, el siguiente paso (número 5) es descentrar las filas. Aquí está el código que implementa este paso:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
),
Ranges as
(
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap
)
SELECT *
FROM Ranges
UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U; Salida:
serviceid rownum start_time end_time grp grp_type ---------- ------- -------------------- -------------------- ---- --------------- 1 0 2018-09-12 08:00:00 NULL 0 end_time_grp 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 end_time_grp 1 0 2018-09-12 08:00:00 NULL 1 start_time_grp 1 6 NULL 2018-09-12 08:06:02 2 end_time_grp 1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 start_time_grp 1 6 NULL 2018-09-12 08:06:02 3 start_time_grp ...
Como puede ver, la columna grp es única para cada isla dentro de una ID de servicio.
El paso 6 es el paso final en la solución. Este es el código que implementa este paso, que también es el código completo de la solución:
DECLARE @allowedgap AS INT = 66;
WITH RNS AS
(
SELECT
serviceid,
logtime,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time
FROM dbo.EventLog
),
Ranges as
(
SELECT serviceid, rownum, start_time, end_time,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp,
ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp
FROM RNS
UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U
PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P
WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1) > @allowedgap
)
SELECT
serviceid, MIN(start_time) AS start_time, MAX(end_time) AS end_time
FROM Ranges
UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U
GROUP BY serviceid, grp
HAVING (MIN(start_time) IS NOT NULL AND MAX(end_time) IS NOT NULL); Este paso genera el siguiente resultado:
serviceid start_time end_time ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 ...
Este paso agrupa las filas por serviceid y grp, filtra solo los grupos relevantes y devuelve el tiempo de inicio mínimo como el comienzo de la isla y el tiempo de finalización máximo como el final de la isla.
La figura 3 tiene el plan que obtuve para esta solución con el índice recomendado:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Plano con índice recomendado en la Figura 3.
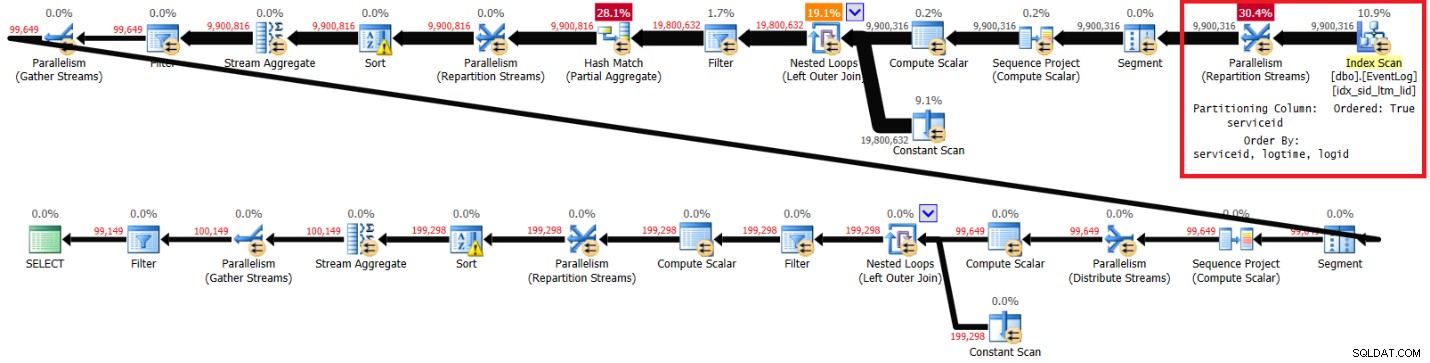 Figura 3:Plan para la solución de Kamil con índice recomendado
Figura 3:Plan para la solución de Kamil con índice recomendado
Estas son las estadísticas de rendimiento que obtuve para esta ejecución en mi computadora portátil:
elapsed: 44, CPU: 66, logical reads: 72979, top wait: CXPACKET: 148
Luego eliminé el índice recomendado y volví a ejecutar la solución:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
Obtuve el plan que se muestra en la Figura 4 para la ejecución sin el índice recomendado.
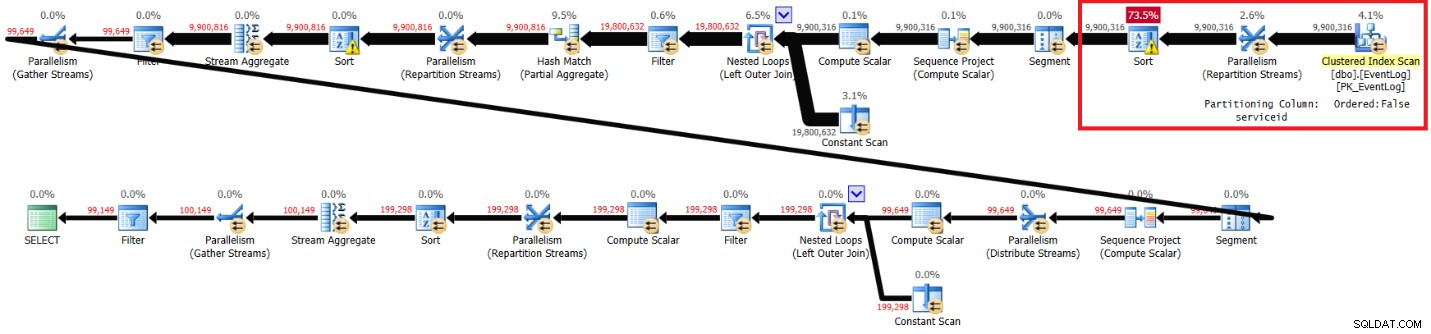 Figura 4:Plan para la solución de Kamil sin índice recomendado
Figura 4:Plan para la solución de Kamil sin índice recomendado
Estas son las estadísticas de rendimiento que obtuve para esta ejecución:
elapsed: 30, CPU: 85, logical reads: 94813, top wait: CXPACKET: 70
Los tiempos de ejecución, los tiempos de CPU y los tiempos de espera de CXPACKET son muy similares a mi solución, aunque las lecturas lógicas son más bajas. La solución de Kamil también se ejecuta más rápido en mi computadora portátil sin el índice recomendado, y parece que se debe a razones similares.
Conclusión
Las anomalías son algo bueno. Te hacen sentir curiosidad y te hacen ir e investigar la causa raíz del problema y, como resultado, aprender cosas nuevas. Es interesante ver que algunas consultas, en ciertas máquinas, se ejecutan más rápido sin la indexación recomendada.
Gracias nuevamente a Toby, Peter y Kamil por sus soluciones. En este artículo cubrí la solución de Kamil, con su técnica creativa para emular LAG y LEAD con números de fila, sin pivotar y pivotando. Esta técnica le resultará útil cuando necesite cálculos similares a LAG y LEAD que deban admitirse en entornos anteriores a 2012.