Este artículo es el segundo de una serie sobre los umbrales de optimización relacionados con la agrupación y agregación de datos. En la Parte 1, proporcioné la fórmula de ingeniería inversa para el costo del operador de Stream Aggregate. Expliqué que este operador necesita consumir las filas ordenadas por el conjunto de agrupación (cualquier orden de sus miembros), y que cuando los datos se obtienen preordenados de un índice, se obtiene un escalado lineal con respecto al número de filas y el número de grupos Además, no se necesita una concesión de memoria en tal caso.
En este artículo, me enfoco en el cálculo de costos y la escala de una operación basada en agregados de transmisión cuando los datos no se obtienen ordenados previamente de un índice, sino que se deben clasificar primero.
En mis ejemplos, usaré la base de datos de muestra PerformanceV3, como en la Parte 1. Puede descargar el script que crea y completa esta base de datos desde aquí. Antes de ejecutar los ejemplos de este artículo, asegúrese de ejecutar primero el siguiente código para eliminar un par de índices innecesarios:
SOLTA EL ÍNDICE idx_nc_sid_od_cid EN dbo.Orders;SUELTA EL ÍNDICE idx_unc_od_oid_i_cid_eid EN dbo.Orders;
Los únicos dos índices que deben quedar en esta tabla son idx_cl_od (agrupado con orderdate como clave) y PK_Orders (no agrupado con orderid como clave).
Ordenar + Stream Agregado
El enfoque de este artículo es tratar de descubrir cómo se escala una operación de agregación de flujo cuando el conjunto de agrupación no ordena previamente los datos. Dado que el operador Stream Aggregate debe procesar las filas ordenadas, si no están ordenadas previamente en un índice, el plan debe incluir un operador Sort explícito. Entonces, el costo de la operación agregada que debe tener en cuenta es la suma de los costos de los operadores Sort + Stream Aggregate.
Usaré la siguiente consulta (la llamaremos Consulta 1) para demostrar un plan que involucre tal optimización:
SELECT shipperid, MAX(orderdate) AS maxod FROM (SELECT TOP (100) * FROM dbo.Orders) AS D GROUP BY shipperid;
El plan para esta consulta se muestra en la Figura 1.

Figura 1:Plan para Consulta 1
La razón por la que uso una expresión de tabla con un filtro TOP es para controlar el número exacto de filas (estimadas) involucradas en la agrupación y agregación. La aplicación de cambios controlados hace que sea más fácil probar y aplicar ingeniería inversa a las fórmulas de costos.
Si se pregunta por qué filtrar una cantidad tan pequeña de filas en este ejemplo, tiene que ver con los umbrales de optimización que hacen que esta estrategia sea preferida al algoritmo Hash Aggregate. En la Parte 3, describiré el costo y la escala de la alternativa hash. En los casos en los que el optimizador no elige una operación de agregación de flujo por sí mismo, por ejemplo, cuando se trata de un gran número de filas, siempre puede forzarlo con la sugerencia OPCIÓN (GRUPO DE ORDEN) durante el proceso de búsqueda. Cuando se enfoca en el costo de los planes en serie, obviamente puede agregar una sugerencia MAXDOP 1 para eliminar el paralelismo.
Como se mencionó, para evaluar el costo y la escala de un algoritmo de agregación de flujo no preordenado, debe tener en cuenta la suma de los operadores Sort + Stream Aggregate. Ya conoce la fórmula de costos para el operador Stream Aggregate de la Parte 1:
@numrows * 0.0000006 + @numgroups * 0.0000005En nuestra consulta, tenemos 100 filas de entrada estimadas y 5 grupos de salida estimados (5 ID de remitente distintos estimados en función de la información de densidad). Entonces, el costo del operador Stream Aggregate en nuestro plan es:
100 * 0,0000006 + 5 * 0,0000005 =0,0000625Intentemos averiguar la fórmula de costeo para el operador Ordenar. Recuerde, nuestro enfoque es el costo estimado y la escala porque nuestro objetivo final es determinar los umbrales de optimización en los que el optimizador cambia sus opciones de una estrategia a otra.
La estimación del costo de E/S parece ser fija:0.0112613. Obtengo el mismo costo de E/S independientemente de factores como el número de filas, el número de columnas de clasificación, el tipo de datos, etc. Esto probablemente se deba a algún trabajo de E/S anticipado.
En cuanto al costo de la CPU, por desgracia, Microsoft no expone públicamente los algoritmos exactos que utilizan para clasificar. Sin embargo, entre los algoritmos comunes que se utilizan para clasificar por motores de bases de datos en general, se encuentran diferentes implementaciones de clasificación por combinación y clasificación rápida. Gracias a los esfuerzos realizados por Paul White, a quien le gusta mirar los rastros de la pila del depurador de Windows (no todos tenemos estómago para esto), tenemos un poco más de información sobre el tema, publicado en su serie "Internals of the Seven SQL Server". Ordena." De acuerdo con los hallazgos de Paul, la clase de ordenación general (usada en el plan anterior) usa la ordenación por fusión (primero interna, luego en transición a externa). En promedio, este algoritmo requiere n log n comparaciones para clasificar n elementos. Con esto en mente, probablemente sea una apuesta segura como punto de partida asumir que la parte de la CPU del costo del operador se basa en una fórmula como:
Costo de CPU del operador =Por supuesto, esto podría ser una simplificación excesiva de la fórmula de cálculo de costos real que usa Microsoft, pero a falta de documentación al respecto, esta es una mejor suposición inicial.
A continuación, puede obtener los costos de CPU de clasificación a partir de dos planes de consulta producidos para clasificar diferentes números de filas, por ejemplo, 1000 y 2000, y en función de estos y de la fórmula anterior, realizar ingeniería inversa del costo de comparación y el costo inicial. Para este propósito, no tiene que usar una consulta agrupada; es suficiente con hacer un ORDEN básico. Usaré las siguientes dos consultas (las llamaremos Consulta 2 y Consulta 3):
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid;
El objetivo de ordenar por el resultado de un cálculo es forzar el uso de un operador Ordenar en el plan.
La Figura 2 muestra las partes relevantes de los dos planes:
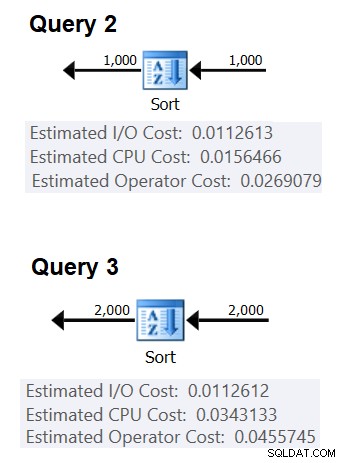
Figura 2:Planes para Consulta 2 y Consulta 3
Para tratar de inferir el costo de una comparación, usaría la siguiente fórmula:
costo de comparación =
((
/ (
(0.0343133 – 0.0156466) / (2000*LOG(2000) – 1000*LOG(1000)) =2.25061348918698E-06
En cuanto al costo inicial, puede deducirlo según cualquiera de los planes, por ejemplo, según el plan que ordena 2000 filas:
costo de inicio =0.0343133 – 2000*LOG(2000) * 2.25061348918698E-06 =9.99127891201865E-05
Y por lo tanto, nuestra fórmula de costo de CPU de clasificación se convierte en:
Ordenar costo de CPU del operador =9.99127891201865E-05 + @numrows * LOG(@numrows) * 2.25061348918698E-06Usando técnicas similares, encontrará que factores como el tamaño de fila promedio, la cantidad de columnas de orden y sus tipos de datos no afectan el costo de CPU de clasificación estimado. El único factor que parece ser relevante es el número estimado de filas. Tenga en cuenta que la ordenación necesitará una concesión de memoria, y la concesión es proporcional al número de filas (no grupos) y al tamaño medio de las filas. Pero nuestro enfoque actualmente es el costo estimado del operador, y parece que esta estimación solo se ve afectada por la cantidad estimada de filas.
Esta fórmula parece predecir bien el costo de la CPU hasta un umbral de aproximadamente 5000 filas. Pruébalo con los siguientes números:100, 200, 300, 400, 500, 1000, 2000, 3000, 4000, 5000:
SELECT numrows, 9.99127891201865E-05 + numrows * LOG(numrows) * 2.25061348918698E-06 AS costo predicado DE (VALORES(100), (200), (300), (400), (500), (1000) , (2000), (3000), (4000), (5000)) AS D(númfilas);
Compare lo que predice la fórmula y los costos de CPU estimados que muestran los planes para las siguientes consultas:
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (100) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECCIONE orderid % 1000000000 as myorderid FROM (SELECT TOP (200) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECCIONE orderid % 1000000000 as myorderid FROM (SELECT TOP (300) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECCIONE orderid % 1000000000 as myorderid FROM (SELECT TOP (400) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECCIONE orderid % 1000000000 as myorderid FROM (SELECT TOP (500) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECCIONE orderid % 1000000000 as myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECCIONE orderid % 1000000000 as myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECCIONE orderid % 1000000000 as myorderid FROM (SELECT TOP (3000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (4000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECCIONE orderid % 1000000000 as myorderid FROM (SELECT TOP (5000) * FROM dbo.Orders) AS D ORDER BY myorderid;
Obtuve los siguientes resultados:
numrows costo predicado costo estimado ratio ----------- --------------- -------------- --- ---- 100 0.0011363 0.0011365 1.00018 200 0.0024848 0.0024849 1.00004 300 0.0039510 0.0039511 1.00003 400 0.0054937 0.0054938 1.00002 500 0.0070933 0.0070933 1.00000 1000 0.0156466 0.0156466 1.00000 2000 0.0343133 0.0343133 1.00000 3000 0.0541576 0.0541576 1.00000 4000 0.0747667 0.0747665 1.00000 5000 0.0959445 0.0959442 1.00000
La columna costopredicho muestra la predicción basada en nuestra fórmula de ingeniería inversa, la columna costoestimado muestra el costo estimado que aparece en el plan y la columna relación muestra la relación entre el último y el primero.
La predicción parece bastante precisa hasta 5000 filas. Sin embargo, con números superiores a 5000, nuestra fórmula de ingeniería inversa deja de funcionar bien. La siguiente consulta le brinda las predicaciones para filas de 6K, 7K, 10K, 20K, 100K y 200K:
SELECT numrows, 9.99127891201865E-05 + numrows * LOG(numrows) * 2.25061348918698E-06 AS costo predicado DE (VALORES(6000), (7000), (10000), (20000), (100000), (200000) ) AS D(númfilas);
Utilice las siguientes consultas para obtener los costos de CPU estimados de los planes (tenga en cuenta la sugerencia de forzar un plan en serie ya que con un mayor número de filas es más probable que obtenga un plan paralelo donde las fórmulas de costos se ajustan para el paralelismo):
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (6000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECCIONE orderid % 1000000000 as myorderid FROM (SELECT TOP (7000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION (MAXDOP 1); SELECCIONE orderid % 1000000000 as myorderid FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION (MAXDOP 1); SELECCIONE orderid % 1000000000 as myorderid FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION (MAXDOP 1); SELECCIONE orderid % 1000000000 as myorderid FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION (MAXDOP 1); SELECCIONE orderid % 1000000000 as myorderid FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION (MAXDOP 1);
Obtuve los siguientes resultados:
numrows costo predicado costo estimado ratio ----------- --------------- -------------- --- --- 6000 0.117575 0.160970 1.3691 7000 0.139583 0.244848 1.7541 10000 0.207389 0.603420 2.9096 20000 0.445878 1.311710 2.9419 100000 2.591210 7.623920 2.9422 200000 5. 5.94330 16.165700 16.165700 2.9423.Como puede ver, más allá de las 5000 filas, nuestra fórmula se vuelve cada vez menos precisa, pero, curiosamente, el índice de precisión se estabiliza en alrededor de 2,94 en torno a las 20 000 filas. Esto implica que con números grandes nuestra fórmula aún se aplica, solo que con un costo de comparación más alto, y que aproximadamente entre 5000 y 20 000 filas, pasa gradualmente del costo de comparación más bajo al más alto. Pero, ¿qué podría explicar la diferencia entre la pequeña escala y la gran escala? La buena noticia es que la respuesta no es tan compleja como reconciliar la mecánica cuántica y la relatividad general con la teoría de cuerdas. Es solo que, en la escala más pequeña, Microsoft quería tener en cuenta el hecho de que es probable que se use el caché de la CPU y, por motivos de costos, asumen un tamaño de caché fijo.
Entonces, para calcular el costo de comparación a gran escala, desea utilizar los costos de CPU de clasificación de dos planes para números superiores a 20,000. Usaré filas 100,000 y 200,000 (las dos últimas filas en la tabla anterior). Esta es la fórmula para inferir el costo de comparación:
costo de comparación =
(16.1657 – 7.62392) / (200000*LOG(200000) – 100000*LOG(100000)) =6.62193536908588E-06A continuación, esta es la fórmula para inferir el costo inicial según el plan para 200 000 filas:
costo inicial =
16.1657 – 200000*LOG(200000) * 6.62193536908588E-06 =1.35166186417734E-04Es muy posible que el costo de inicio para las escalas pequeña y grande sea el mismo, y que la diferencia que obtuvimos se deba a errores de redondeo. En cualquier caso, con un gran número de filas, el costo inicial se vuelve insignificante en comparación con el costo de las comparaciones.
En resumen, esta es la fórmula para el costo de CPU del operador Ordenar para números grandes (>=20000):
Costo de CPU del operador =1,35166186417734E-04 + @numrows * LOG(@numrows) * 6,62193536908588E-06Probemos la precisión de la fórmula con filas de 500K, 1M y 10M. El siguiente código le proporciona las predicaciones de nuestra fórmula:
SELECT numrows, 1.35166186417734E-04 + numrows * LOG(numrows) * 6.62193536908588E-06 AS costo predicado FROM (VALUES(500000), (1000000), (10000000)) AS D(numrows);Utilice las siguientes consultas para obtener los costos de CPU estimados:
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECCIONE orderid % 1000000000 as myorderid FROM (SELECT TOP (1000000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION (MAXDOP 1); SELECT CHECKSUM(NEWID()) as myorderid FROM (SELECT TOP (10000000) O1.orderid FROM dbo.Orders AS O1 CROSS JOIN dbo.Orders AS O2) AS D ORDER BY myorderid OPTION(MAXDOP 1);Obtuve los siguientes resultados:
numrows costo predicado costo estimado ratio ----------- --------------- -------------- --- --- 500000 43,4479 43,448 1,0000 1000000 91,4856 91,486 1,0000 10000000 1067,3300 1067,340 1,0000Parece que nuestra fórmula para números grandes funciona bastante bien.
Poniéndolo todo junto
El costo total de aplicar un flujo agregado con clasificación explícita para un pequeño número de filas (<=5000 filas) es:
+ + =
0.0112613
+ 9.99127891201865E-05 + @numrows * LOG(@ numrows) * 2.25061348918698E-06
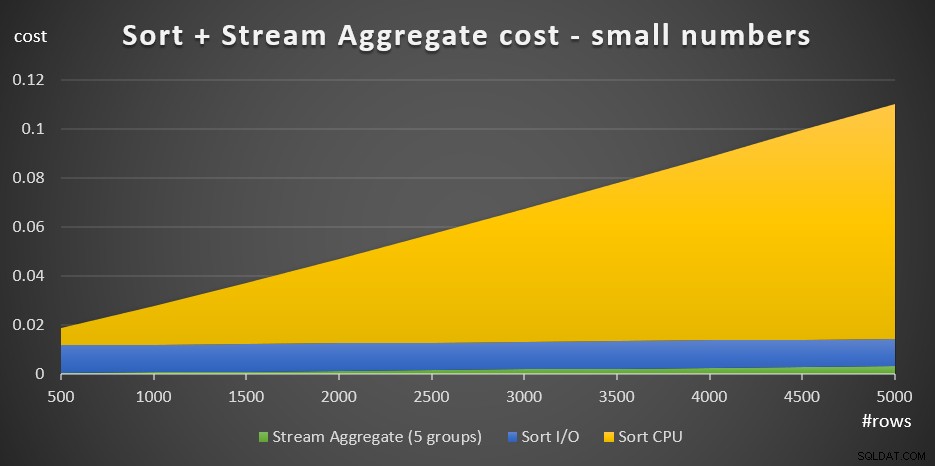
+ @numrows * 0.0000006 + @numgroups * 0.0000005La figura 3 tiene un gráfico de áreas que muestra cómo se escala este costo.
Figura 3:Costo de ordenación + flujo agregado para pequeñas cantidades de filasEl costo de la CPU de clasificación es la parte más importante del costo agregado total de Clasificación + Transmisión. Aún así, con un pequeño número de filas, el costo de Stream Aggregate y la parte de Sort I/O del costo no son del todo insignificantes. En términos visuales, puede ver claramente las tres partes en el gráfico.
En cuanto a un gran número de filas (>=20 000), la fórmula de costos es:
0.0112613
+ 1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06
+ @numrows * 0.0000006 + @numgroups * 0.0000005No vi mucho valor en buscar la forma exacta en que el costo de comparación pasa de la pequeña a la gran escala.
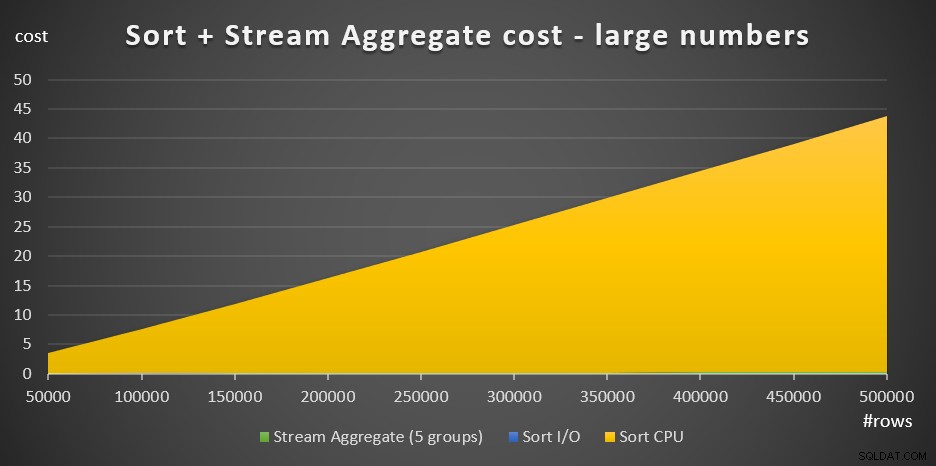
La figura 4 tiene un gráfico de áreas que muestra cómo se escala el costo para números grandes.
Figura 4:Costo de ordenación + flujo agregado para grandes cantidades de filasCon un gran número de filas, el costo de Stream Aggregate y el costo de Sort I/O son tan insignificantes en comparación con el costo de Sort CPU que ni siquiera son visibles a simple vista en el gráfico. Además, la parte del costo de la CPU de Sort atribuida al trabajo de inicio también es insignificante. Por lo tanto, la única parte del cálculo del costo que es realmente significativa es el costo total de comparación:
@numrows * LOG(@numrows) *Esto significa que cuando necesite evaluar la escala de la estrategia Sort + Stream Aggregate, puede simplificarla solo a esta parte dominante. Por ejemplo, si necesita evaluar cómo escalaría el costo de 100 000 filas a 100 000 000 filas, puede usar la fórmula (observe que el costo de comparación es irrelevante):
(100000000 * LOG(100000000)*) / (100000 * LOG(100000)*) =1600Esto le indica que cuando el número de filas aumenta de 100 000 por un factor de 1000 a 100 000 000, el costo estimado aumenta por un factor de 1600.
La escala de 1 000 000 a 1 000 000 000 de filas se calcula como:
(1000000000 * REGISTRO (1000000000)) / (1000000 * REGISTRO (1000000)) =1500Es decir, cuando el número de filas aumenta de 1 000 000 por un factor de 1000, el costo estimado aumenta por un factor de 1500.
Estas son observaciones interesantes sobre la forma en que escala la estrategia Sort + Stream Aggregate. Debido a su costo de inicio muy bajo y su escalado lineal adicional, esperaría que esta estrategia funcionara bien con un número muy pequeño de filas, pero no tan bien con números grandes. Además, el hecho de que el operador Stream Aggregate solo represente una fracción tan pequeña del costo en comparación con cuando también se necesita una ordenación, le dice que puede obtener un rendimiento significativamente mejor si la situación es tal que puede crear un índice de soporte .
En la siguiente parte de la serie, cubriré la escala del algoritmo Hash Aggregate. Si disfruta este ejercicio de tratar de descifrar fórmulas de costos, vea si puede descifrarlo para este algoritmo. Lo importante es descubrir los factores que lo afectan, la forma en que escala y las condiciones en las que funciona mejor que los otros algoritmos.