Este artículo es el cuarto de una serie sobre umbrales de optimización. La serie cubre la agrupación y agregación de datos, explica los diferentes algoritmos que SQL Server puede usar y el modelo de costos que lo ayuda a elegir entre los algoritmos. En este artículo me centro en las consideraciones de paralelismo. Cubro las diferentes estrategias de paralelismo que SQL Server puede usar, los umbrales para elegir entre un plan en serie y paralelo, y la lógica de costos que aplica SQL Server usando un concepto llamado grado de paralelismo para costos (DOP para costeo).
Continuaré usando la tabla dbo.Orders en la base de datos de muestra PerformanceV3 en mis ejemplos. Antes de ejecutar los ejemplos de este artículo, ejecute el siguiente código para eliminar un par de índices innecesarios:
DROP INDEX IF EXISTS idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX IF EXISTS idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Los únicos dos índices que deben quedar en esta tabla son idx_cl_od (agrupados con orderdate como clave) y PK_Orders (no agrupados con orderid como clave).
Estrategias de paralelismo
Además de tener que elegir entre varias estrategias de agrupación y agregación (Stream Aggregate pedido previamente, Sort + Stream Aggregate, Hash Aggregate), SQL Server también debe elegir si optar por un plan en serie o paralelo. De hecho, puede elegir entre múltiples estrategias de paralelismo diferentes. SQL Server utiliza una lógica de costos que da como resultado umbrales de optimización que, en diferentes condiciones, hacen que una estrategia prefiera a las demás. Ya hemos discutido en profundidad la lógica de costos que utiliza SQL Server en los planes en serie en las partes anteriores de la serie. En esta sección, presentaré una serie de estrategias de paralelismo que SQL Server puede usar para manejar la agrupación y la agregación. Inicialmente, no entraré en los detalles de la lógica de costos, sino que simplemente describiré las opciones disponibles. Más adelante en el artículo explicaré cómo funcionan las fórmulas de costeo y un factor importante en esas fórmulas llamado DOP para costeo.
Como aprenderá más adelante, SQL Server tiene en cuenta la cantidad de CPU lógicas en la máquina en sus fórmulas de costos para planes paralelos. En mis ejemplos, a menos que diga lo contrario, asumo que el sistema de destino tiene 8 CPU lógicas. Si desea probar los ejemplos que proporcionaré, para obtener los mismos planes y valores de costos que yo, también debe ejecutar el código en una máquina con 8 CPU lógicas. Si sucede que su máquina tiene una cantidad diferente de CPU, puede emular una máquina con 8 CPU, para fines de costos, así:
DBCC OPTIMIZER_WHATIF(CPUs, 8);
Aunque esta herramienta no está oficialmente documentada ni respaldada, es bastante conveniente para fines de investigación y aprendizaje.
La tabla Pedidos de nuestra base de datos de muestra tiene 1 000 000 de filas con ID de pedido en el rango de 1 a 1 000 000. Para demostrar tres estrategias de paralelismo diferentes para agrupar y agregar, filtraré los pedidos en los que el ID de pedido sea mayor o igual a 300001 (700 000 coincidencias) y agruparé los datos de tres formas diferentes (por custid [20 000 grupos antes del filtrado], por empid [500 grupos] y por shipperid [5 grupos]) y calcule el recuento de pedidos por grupo.
Utilice el siguiente código para crear índices que admitan las consultas agrupadas:
CREATE INDEX idx_oid_i_eid ON dbo.Orders(orderid) INCLUDE(empid); CREATE INDEX idx_oid_i_sid ON dbo.Orders(orderid) INCLUDE(shipperid); CREATE INDEX idx_oid_i_cid ON dbo.Orders(orderid) INCLUDE(custid);
Las siguientes consultas implementan el filtrado y la agrupación antes mencionados:
-- Query 1: Serial SELECT custid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY custid OPTION(MAXDOP 1); -- Query 2: Parallel, not local/global SELECT custid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY custid; -- Query 3: Local parallel global parallel SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY empid; -- Query 4: Local parallel global serial SELECT shipperid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY shipperid;
Observe que la Consulta 1 y la Consulta 2 son iguales (ambas agrupadas por custid), solo que la primera fuerza un plan en serie y la segunda obtiene un plan paralelo en una máquina con 8 CPU. Utilizo estos dos ejemplos para comparar las estrategias en serie y en paralelo para la misma consulta.
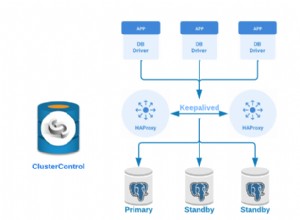
La Figura 1 muestra los planes estimados para las cuatro consultas:
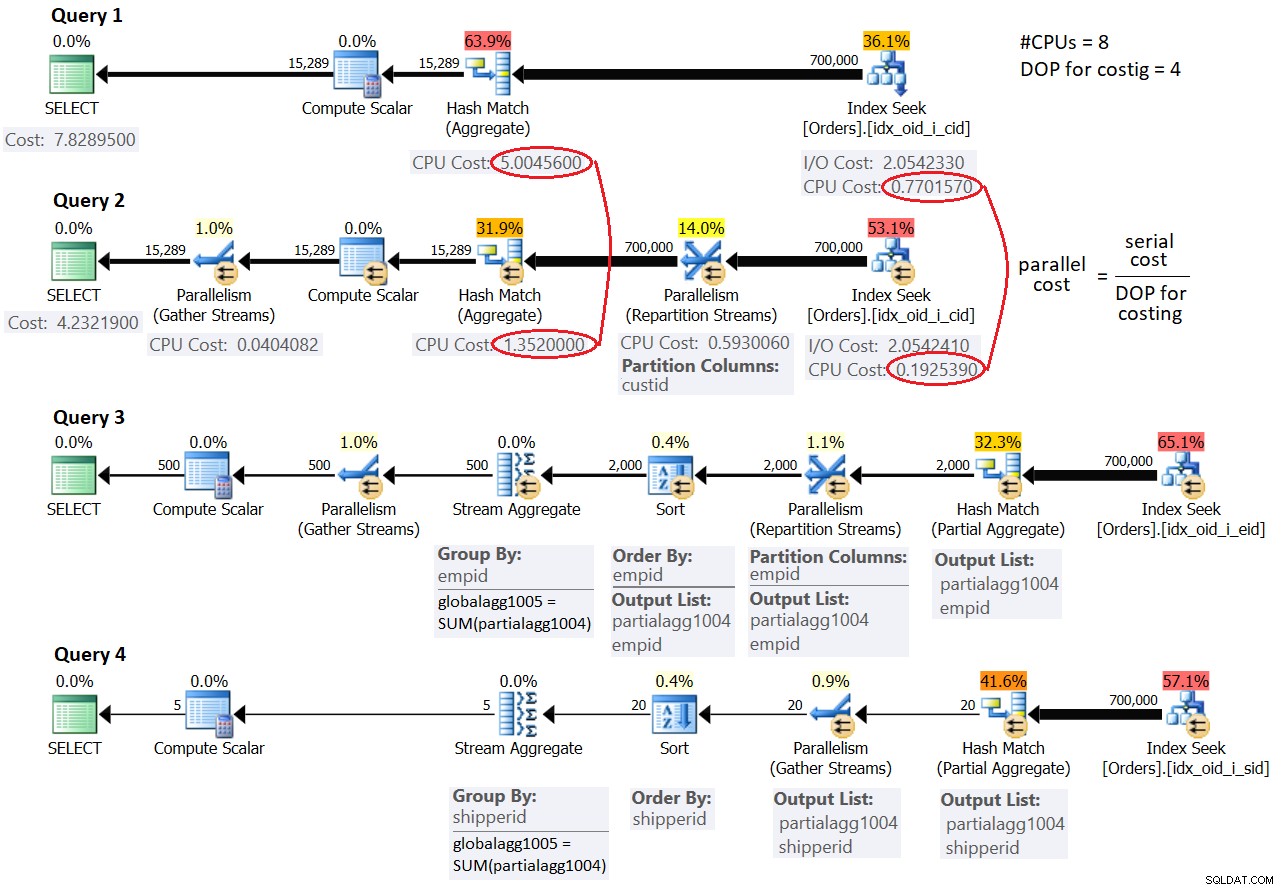 Figura 1:Estrategias de paralelismo
Figura 1:Estrategias de paralelismo
Por ahora, no se preocupe por los valores de costo que se muestran en la figura y la mención del término DOP para el cálculo de costos. Llegaré a eso más tarde. Primero, concéntrese en comprender las estrategias y las diferencias entre ellas.
La estrategia utilizada en el plan en serie para la Consulta 1 debería resultarle familiar por las partes anteriores de la serie. El plan filtra los pedidos relevantes mediante una búsqueda en el índice de cobertura que creó anteriormente. Luego, con el número estimado de filas que se agruparán y agregarán, el optimizador prefiere la estrategia Hash Aggregate a la estrategia Sort + Stream Aggregate.
El plan para la consulta 2 usa una estrategia de paralelismo simple que emplea solo un operador agregado. Un operador Index Seek paralelo distribuye paquetes de filas a los diferentes subprocesos en forma de turno rotativo. Cada paquete de filas puede contener varios ID de clientes distintos. Para que un solo operador agregado pueda calcular los recuentos de grupo finales correctos, todas las filas que pertenecen al mismo grupo deben ser manejadas por el mismo subproceso. Por este motivo, se utiliza un operador de intercambio de paralelismo (repartición de flujos) para volver a particionar los flujos por el conjunto de agrupación (custid). Por último, se utiliza un operador de intercambio de Parallelism (Gather Streams) para recopilar los flujos de varios subprocesos en un solo flujo de filas de resultados.
Los planes para Consulta 3 y Consulta 4 emplean una estrategia de paralelismo más compleja. Los planes comienzan de manera similar al plan para la Consulta 2, donde un operador Index Seek paralelo distribuye paquetes de filas a diferentes subprocesos. Luego, el trabajo de agregación se realiza en dos pasos:un operador de agregado agrupa localmente y agrega las filas del subproceso actual (observe el miembro de resultado sharedagg1004), y un segundo operador de agregado agrupa y agrega globalmente los resultados de los agregados locales (observe el globalagg1005 miembro de resultado). Cada uno de los dos pasos agregados (local y global) puede usar cualquiera de los algoritmos agregados que describí anteriormente en la serie. Ambos planes para la Consulta 3 y la Consulta 4 comienzan con un Hash Aggregate local y continúan con un Sort + Stream Aggregate global. La diferencia entre los dos es que el primero usa el paralelismo en ambos pasos (por lo tanto, se usa un intercambio de Repartition Streams entre los dos y un intercambio de Gather Streams después del agregado global), y el segundo maneja el agregado local en una zona paralela y el global. agregado en una zona serial (por lo tanto, se usa un intercambio Gather Streams entre los dos).
Al investigar sobre la optimización de consultas en general y el paralelismo en particular, es bueno estar familiarizado con las herramientas que le permiten controlar varios aspectos de la optimización para ver sus efectos. Ya sabe cómo forzar un plan serial (con una sugerencia de MAXDOP 1) y cómo emular un entorno que, para fines de costos, tiene una cierta cantidad de CPU lógicas (DBCC OPTIMIZER_WHATIF, con la opción de CPU). Otra herramienta útil es la sugerencia de consulta ENABLE_PARALLEL_PLAN_PREFERENCE (introducida en SQL Server 2016 SP1 CU2), que maximiza el paralelismo. Lo que quiero decir con esto es que si se admite un plan paralelo para la consulta, se preferirá el paralelismo en todas las partes del plan que se puedan manejar en paralelo, como si fuera gratuito. Por ejemplo, observe en la Figura 1 que, de manera predeterminada, el plan para la Consulta 4 maneja el agregado local en una zona en serie y el agregado global en una zona paralela. Esta es la misma consulta, solo que esta vez con la sugerencia de consulta ENABLE_PARALLEL_PLAN_PREFERENCE aplicada (la llamaremos Consulta 5):
SELECT shipperid, COUNT(*) AS numorders
FROM dbo.Orders
WHERE orderid >= 300001
GROUP BY shipperid
OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')); El plan para la Consulta 5 se muestra en la Figura 2:
 Figura 2:Maximización del paralelismo
Figura 2:Maximización del paralelismo
Observe que esta vez tanto los agregados locales como los globales se manejan en zonas paralelas.
Elección de plan en serie/paralelo
Recuerde que durante la optimización de consultas, SQL Server crea múltiples planes candidatos y elige el que tiene el costo más bajo entre los que produjo. El término coste es un nombre un poco inapropiado ya que se supone que el plan candidato con el costo más bajo es, según las estimaciones, el que tiene el tiempo de ejecución más bajo, no el que tiene la cantidad más baja de recursos utilizados en general. Por ejemplo, entre un plan candidato en serie y uno paralelo producido para la misma consulta, es probable que el plan paralelo use más recursos, ya que necesita usar operadores de intercambio que sincronicen los subprocesos (distribuir, repartir y recopilar flujos). Sin embargo, para que el plan paralelo necesite menos tiempo para completar la ejecución que el plan en serie, los ahorros logrados al hacer el trabajo con múltiples subprocesos deben superar el trabajo adicional realizado por los operadores de intercambio. Y esto debe reflejarse en las fórmulas de costos que utiliza SQL Server cuando se trata de paralelismo. ¡No es una tarea fácil de hacer con precisión!
Además de que el costo del plan paralelo debe ser menor que el costo del plan en serie para ser preferido, el costo de la alternativa del plan en serie debe ser mayor o igual que el umbral de costo para el paralelismo . Esta es una opción de configuración del servidor establecida en 5 por defecto que evita que las consultas con un costo bastante bajo se manejen con paralelismo. El pensamiento aquí es que un sistema con una gran cantidad de consultas pequeñas en general se beneficiaría más del uso de planes en serie, en lugar de desperdiciar una gran cantidad de recursos en la sincronización de subprocesos. Todavía puede tener múltiples consultas con planes en serie ejecutándose al mismo tiempo, utilizando de manera eficiente los recursos de múltiples CPU de la máquina. De hecho, a muchos profesionales de SQL Server les gusta aumentar el umbral de costo para el paralelismo de su valor predeterminado de 5 a un valor más alto. Un sistema que ejecuta una cantidad bastante pequeña de consultas grandes simultáneamente se beneficiaría mucho más del uso de planes paralelos.
En resumen, para que SQL Server prefiera un plan paralelo a la alternativa en serie, el costo del plan en serie debe ser al menos el umbral de costo para el paralelismo, y el costo del plan paralelo debe ser menor que el costo del plan en serie (lo que implica potencialmente menor tiempo de ejecución).
Antes de llegar a los detalles de las fórmulas de costos reales, ilustraré con ejemplos diferentes escenarios en los que se elige entre planes en serie y paralelos. Asegúrese de que su sistema asuma 8 CPU lógicas para obtener costos de consulta similares a los míos si desea probar los ejemplos.
Considere las siguientes consultas (las llamaremos Consulta 6 y Consulta 7):
-- Query 6: Serial
SELECT empid, COUNT(*) AS numorders
FROM dbo.Orders
WHERE orderid >= 400001
GROUP BY empid;
-- Query 7: Forced parallel
SELECT empid, COUNT(*) AS numorders
FROM dbo.Orders
WHERE orderid >= 400001
GROUP BY empid
OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')); Los planes para estas consultas se muestran en la Figura 3.
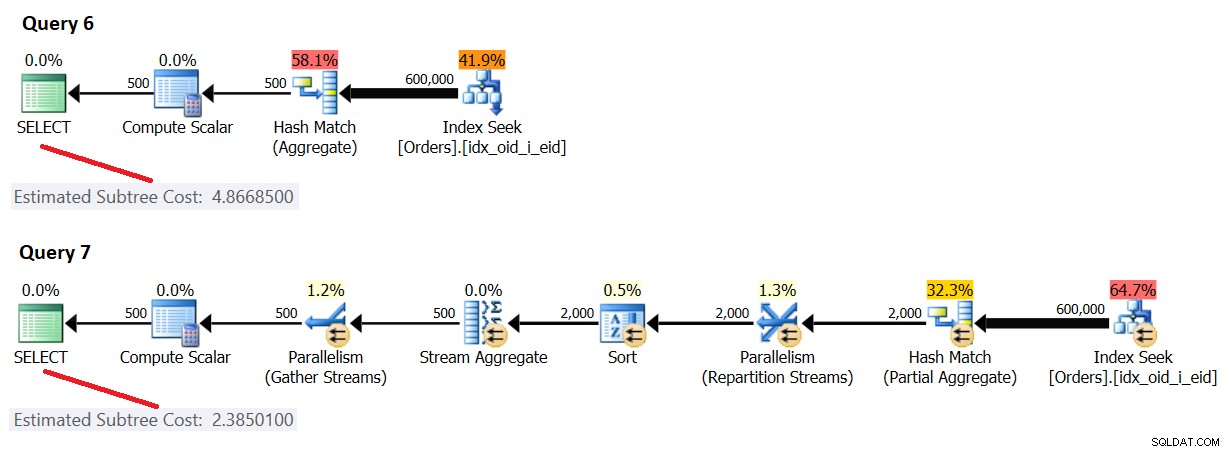 Figura 3:Costo serial
Figura 3:Costo serial
Aquí, el costo del plan paralelo [forzado] es más bajo que el costo del plan en serie; sin embargo, el costo del plan en serie es menor que el umbral de costo predeterminado para el paralelismo de 5, por lo que SQL Server eligió el plan en serie de forma predeterminada.
Considere las siguientes consultas (las llamaremos Consulta 8 y Consulta 9):
-- Query 8: Parallel SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY empid; -- Query 9: Forced serial SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY empid OPTION(MAXDOP 1);
Los planes para estas consultas se muestran en la Figura 4.
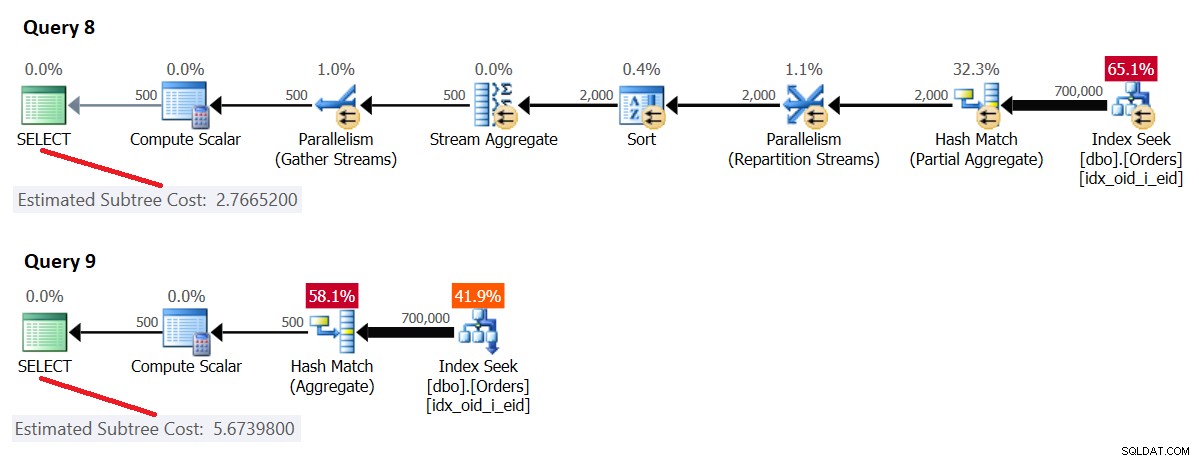 Figura 4:Costo serial>=umbral de costo para paralelismo, costo paralelo
Figura 4:Costo serial>=umbral de costo para paralelismo, costo paralelo
Aquí, el costo del plan en serie [forzado] es mayor o igual que el umbral de costo para el paralelismo, y el costo del plan en paralelo es menor que el costo del plan en serie, por lo que SQL Server eligió el plan en paralelo de forma predeterminada.
Considere las siguientes consultas (las llamaremos Consulta 10 y Consulta 11):
-- Query 10: Serial
SELECT *
FROM dbo.Orders
WHERE orderid >= 100000;
-- Query 11: Forced parallel
SELECT *
FROM dbo.Orders
WHERE orderid >= 100000
OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')); Los planes para estas consultas se muestran en la Figura 5.
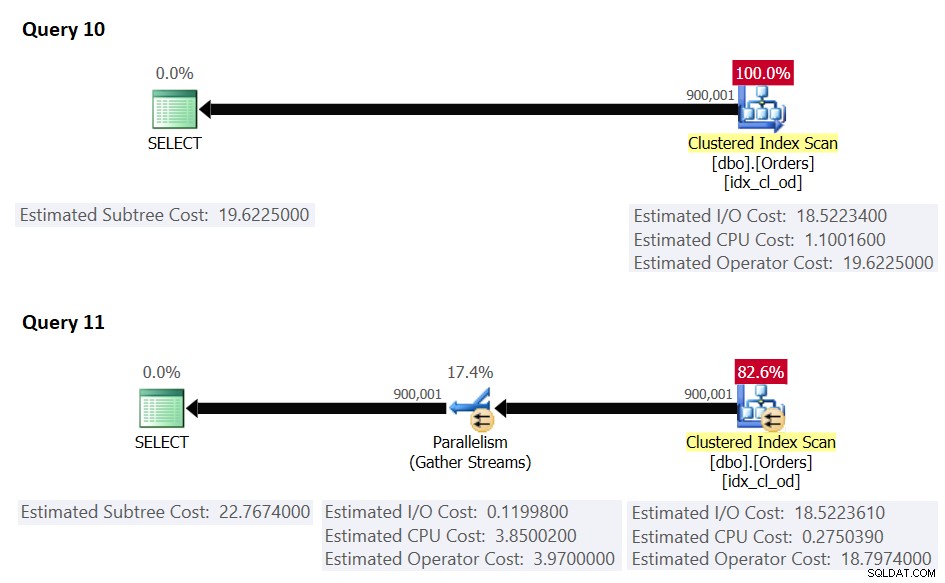 Figura 5:Costo serial>=umbral de costo para paralelismo, costo paralelo>=costo serial
Figura 5:Costo serial>=umbral de costo para paralelismo, costo paralelo>=costo serial
Aquí, el costo del plan en serie es mayor o igual que el umbral de costo para el paralelismo; sin embargo, el costo del plan en serie es más bajo que el costo del plan paralelo [forzado], por lo tanto, SQL Server eligió el plan en serie de forma predeterminada.
Hay otra cosa que debe saber acerca de intentar maximizar el paralelismo con la sugerencia ENABLE_PARALLEL_PLAN_PREFERENCE. Para que SQL Server incluso pueda usar un plan paralelo, tiene que haber algún activador de paralelismo como un predicado residual, una ordenación, un agregado, etc. Un plan que aplica solo un escaneo de índice o una búsqueda de índice sin un predicado residual y sin ningún otro habilitador de paralelismo, se procesará con un plan en serie. Considere las siguientes consultas como ejemplo (las llamaremos Consulta 12 y Consulta 13):
-- Query 12
SELECT *
FROM dbo.Orders
OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));
-- Query 13
SELECT *
FROM dbo.Orders
WHERE orderid >= 100000
OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')); Los planes para estas consultas se muestran en la Figura 6.
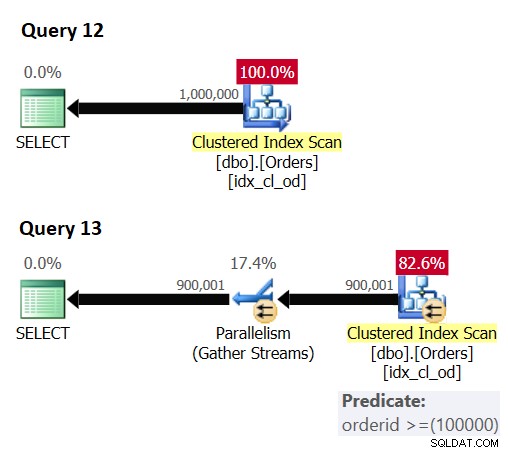 Figura 6:Habilitador de paralelismo
Figura 6:Habilitador de paralelismo
La consulta 12 obtiene un plan en serie a pesar de la sugerencia, ya que no hay habilitador de paralelismo. La consulta 13 obtiene un plan paralelo ya que hay un predicado residual involucrado.
Computación y prueba de DOP para costos
Microsoft tuvo que calibrar las fórmulas de costos en un intento de tener un costo de plan paralelo más bajo que el costo del plan en serie reflejando un tiempo de ejecución más bajo y viceversa. Una idea potencial era tomar el costo de CPU del operador en serie y simplemente dividirlo por la cantidad de CPU lógicas en la máquina para producir el costo de CPU del operador en paralelo. El número lógico de CPU en la máquina es el factor principal que determina el grado de paralelismo de la consulta, o DOP en resumen (el número de subprocesos que se pueden usar en una zona paralela en el plan). El pensamiento simplista aquí es que si un operador tarda T unidades de tiempo en completarse cuando usa un subproceso, y el grado de paralelismo de la consulta es D, el operador tardaría T/D en completarse cuando usa D subprocesos. En la práctica, las cosas no son tan simples. Por ejemplo, normalmente tiene varias consultas ejecutándose simultáneamente y no solo una, en cuyo caso una sola consulta no obtendrá todos los recursos de la CPU de la máquina. Entonces, a Microsoft se le ocurrió la idea del grado de paralelismo para el cálculo de costos (DOP por costeo, en fin). Esta medida suele ser menor que la cantidad de CPU lógicas en la máquina y es el factor por el cual se divide el costo de CPU del operador en serie para calcular el costo de CPU del operador en paralelo.
Normalmente, el DOP para el cálculo de costos se calcula como el número de CPU lógicas dividido por 2, utilizando la división de enteros. Sin embargo, hay excepciones. Cuando la cantidad de CPU es 2 o 3, el DOP para el cálculo de costos se establece en 2. Con 4 o más CPU, el DOP para el cálculo de costos se establece en #CPU / 2, nuevamente, utilizando la división de enteros. Eso es hasta cierto máximo, que depende de la cantidad de memoria disponible para la máquina. En una máquina con hasta 4.096 MB de memoria el DOP máximo para costear es 8; con más de 4.096 MB, el DOP máximo para costear es 32.
Para probar esta lógica, ya sabe cómo emular una cantidad deseada de CPU lógicas utilizando DBCC OPTIMIZER_WHATIF, con la opción de CPU, así:
DBCC OPTIMIZER_WHATIF(CPUs, 8);
Usando el mismo comando con la opción MemoryMBs, puede emular una cantidad deseada de memoria en MB, así:
DBCC OPTIMIZER_WHATIF(MemoryMBs, 16384);
Use el siguiente código para verificar el estado existente de las opciones emuladas:
DBCC TRACEON(3604); DBCC OPTIMIZER_WHATIF(Status); DBCC TRACEOFF(3604);
Utilice el siguiente código para restablecer todas las opciones:
DBCC OPTIMIZER_WHATIF(ResetAll);
Aquí hay una consulta T-SQL que puede usar para calcular DOP para el cálculo de costos en función de una cantidad de CPU lógicas de entrada y una cantidad de memoria:
DECLARE @NumCPUs AS INT = 8, @MemoryMBs AS INT = 16384;
SELECT
CASE
WHEN @NumCPUs = 1 THEN 1
WHEN @NumCPUs <= 3 THEN 2
WHEN @NumCPUs >= 4 THEN
(SELECT MIN(n)
FROM ( VALUES(@NumCPUs / 2), (MaxDOP4C ) ) AS D2(n))
END AS DOP4C
FROM ( VALUES( CASE WHEN @MemoryMBs <= 4096 THEN 8 ELSE 32 END ) ) AS D1(MaxDOP4C); Con los valores de entrada especificados, esta consulta devuelve 4.
La Tabla 1 detalla el DOP para el costo que obtiene en función de la cantidad lógica de CPU y la cantidad de memoria en su máquina.
| #CPU | DOP para costear cuando MemoryMBs <=4096 | DOP para costear cuando MemoryMBs> 4096 |
|---|---|---|
| 1 | 1 | 1 |
| 2-5 | 2 | 2 |
| 6-7 | 3 | 3 |
| 8-9 | 4 | 4 |
| 10-11 | 5 | 5 |
| 12-13 | 6 | 6 |
| 14-15 | 7 | 7 |
| 16-17 | 8 | 8 |
| 18-19 | 8 | 9 |
| 20-21 | 8 | 10 |
| 22-23 | 8 | 11 |
| 24-25 | 8 | 12 |
| 26-27 | 8 | 13 |
| 28-29 | 8 | 14 |
| 30-31 | 8 | 15 |
| 32-33 | 8 | 16 |
| 34-35 | 8 | 17 |
| 36-37 | 8 | 18 |
| 38-39 | 8 | 19 |
| 40-41 | 8 | 20 |
| 42-43 | 8 | 21 |
| 44-45 | 8 | 22 |
| 46-47 | 8 | 23 |
| 48-49 | 8 | 24 |
| 50-51 | 8 | 25 |
| 52-53 | 8 | 26 |
| 54-55 | 8 | 27 |
| 56-57 | 8 | 28 |
| 58-59 | 8 | 29 |
| 60-61 | 8 | 30 |
| 62-63 | 8 | 31 |
| >=64 | 8 | 32 |
Tabla 1:DOP para costeo
Como ejemplo, revisemos la Consulta 1 y la Consulta 2 mostradas anteriormente:
-- Query 1: Forced serial SELECT custid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY custid OPTION(MAXDOP 1); -- Query 2: Naturally parallel SELECT custid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY custid;
Los planes para estas consultas se muestran en la Figura 7.
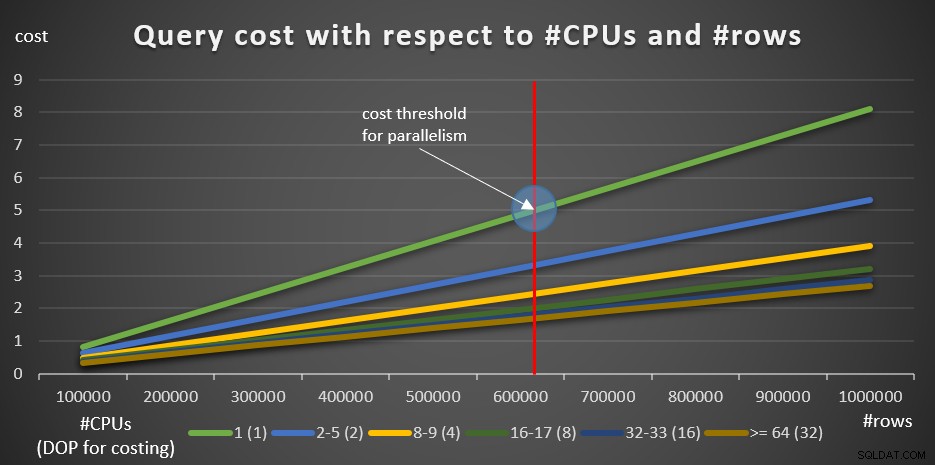 Figura 7:DOP para costos
Figura 7:DOP para costos
La Consulta 1 fuerza un plan en serie, mientras que la Consulta 2 obtiene un plan paralelo en mi entorno (emula 8 CPU lógicas y 16 384 MB de memoria). Esto significa que el costo de DOP en mi entorno es 4. Como se mencionó, el costo de la CPU de un operador paralelo se calcula como el costo de la CPU del operador en serie dividido por el costo de DOP. Puede ver que ese es el caso en nuestro plan paralelo con los operadores Index Seek y Hash Aggregate que se ejecutan en paralelo.
En cuanto a los costos de los operadores de intercambio, están compuestos por un costo de inicio y un costo constante por fila, que puede aplicar ingeniería inversa fácilmente.
Observe que en la estrategia de agrupación y agregación en paralelo simple, que es la que se usa aquí, las estimaciones de cardinalidad en los planes en serie y en paralelo son las mismas. Eso es porque solo se emplea un operador agregado. Más adelante verá que las cosas son diferentes cuando se utiliza la estrategia local/global.
Las siguientes consultas ayudan a ilustrar el efecto de la cantidad de CPU lógicas y la cantidad de filas involucradas en el costo de la consulta (10 consultas, con incrementos de 100 000 filas):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 900001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 800001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 700001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 600001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 500001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 400001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 200001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 100001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 000001 GROUP BY empid;
La Figura 8 muestra los resultados.
Figura 8:Costo de consulta con respecto a #CPU y #filas
La línea verde representa los costos de las diferentes consultas (con los diferentes números de filas) usando un plan serial. Las demás líneas representan los costos de los planes paralelos con diferente número de UCPs lógicas, y su respectivo DOP para costeo. La línea roja representa el punto donde el costo de la consulta en serie es 5, el umbral de costo predeterminado para la configuración de paralelismo. A la izquierda de este punto (menos filas para agrupar y agregar), normalmente, el optimizador no considerará un plan paralelo. Para poder investigar los costos de los planes paralelos por debajo del umbral de costo para el paralelismo, puede hacer una de dos cosas. Una opción es usar la sugerencia de consulta ENABLE_PARALLEL_PLAN_PREFERENCE, pero como recordatorio, esta opción maximiza el paralelismo en lugar de simplemente forzarlo. Si ese no es el efecto deseado, simplemente puede deshabilitar el umbral de costo para el paralelismo, así:
EXEC sp_configure 'show advanced options', 1; RECONFIGURE; EXEC sp_configure 'cost threshold for parallelism', 0; EXEC sp_configure 'show advanced options', 0; RECONFIGURE;
Obviamente, ese no es un movimiento inteligente en un sistema de producción, pero es perfectamente útil para fines de investigación. Eso es lo que hice para generar la información para el gráfico de la Figura 8.
Comenzando con filas de 100 000 y agregando incrementos de 100 000, todos los gráficos parecen implicar que tener un umbral de costo para el paralelismo no era un factor, siempre se hubiera preferido un plan paralelo. De hecho, ese es el caso con nuestras consultas y la cantidad de filas involucradas. Sin embargo, pruebe con un número menor de filas, comenzando con 10 000 y aumentando en incrementos de 10 000 utilizando las siguientes cinco consultas (nuevamente, mantenga el umbral de costo para el paralelismo deshabilitado por ahora):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 990001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 980001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 970001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 960001 GROUP BY empid; SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 950001 GROUP BY empid;
La Figura 9 muestra los costos de consulta con planes paralelos y en serie (emulando 4 CPU, DOP para el costo de 2).
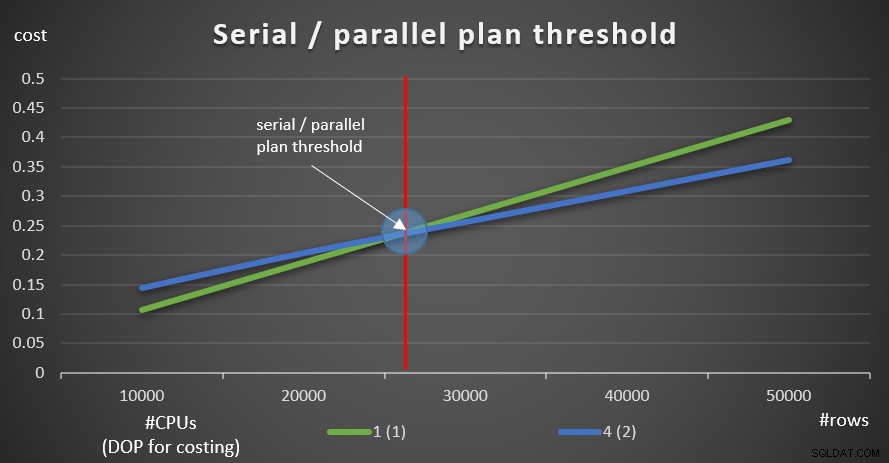 Figura 9:Serie / umbral del plan paralelo
Figura 9:Serie / umbral del plan paralelo
Como puede ver, hay un umbral de optimización hasta el cual se prefiere el plan en serie y por encima del cual se prefiere el plan paralelo. Como se mencionó, en un sistema normal en el que mantiene el umbral de costo para la configuración de paralelismo en el valor predeterminado de 5 o superior, el umbral efectivo es de todos modos más alto que en este gráfico.
Anteriormente mencioné que cuando SQL Server elige la estrategia de paralelismo de agregación y agrupación simple, las estimaciones de cardinalidad de los planes en serie y en paralelo son las mismas. La pregunta es, ¿cómo maneja SQL Server las estimaciones de cardinalidad para la estrategia de paralelismo local/global?
Para resolver esto, usaré la Consulta 3 y la Consulta 4 de nuestros ejemplos anteriores:
-- Query 3: Local parallel global parallel SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY empid; -- Query 4: Local parallel global serial SELECT shipperid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid >= 300001 GROUP BY shipperid;
En un sistema con 8 CPU lógicas y un DOP efectivo para el valor de costeo de 4, obtuve los planes que se muestran en la Figura 10.
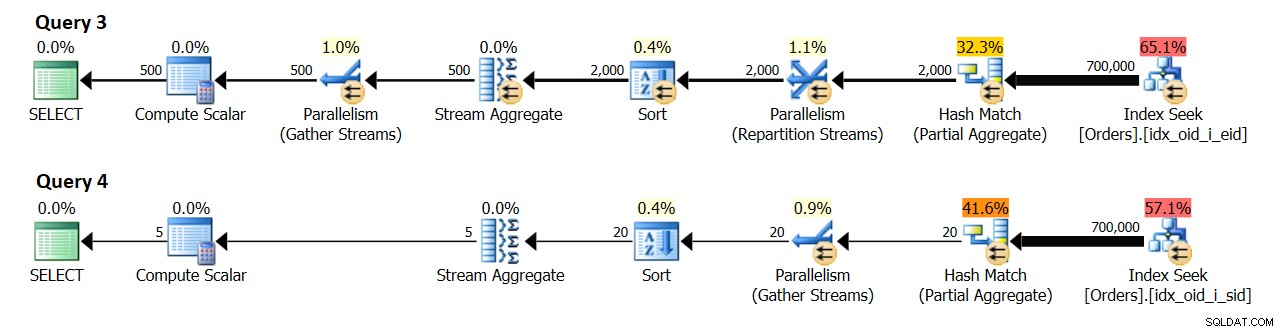 Figura 10:Estimación de cardinalidad
Figura 10:Estimación de cardinalidad
La consulta 3 agrupa los pedidos por empid. Se esperan 500 grupos distintos de empleados eventualmente.
La consulta 4 agrupa los pedidos por shipperid. Se esperan 5 grupos distintos de cargadores eventualmente.
Curiosamente, parece que la cardinalidad estimada para el número de grupos producidos por el agregado local es {número de grupos distintos esperados por cada subproceso} * {DOP para costeo}. En la práctica, se da cuenta de que el número suele ser el doble, ya que lo que cuenta es el DOP para la ejecución (también conocido como DOP), que se basa principalmente en el número de CPU lógicas. Esta parte es un poco complicada de emular con fines de investigación, ya que el comando DBCC OPTIMIZER_WHATIF con la opción de CPU afecta el cálculo del DOP para el cálculo de costos, pero el DOP para la ejecución no será mayor que la cantidad real de CPU lógicas que ve su instancia de SQL Server. Este número se basa esencialmente en el número de planificadores con los que comienza SQL Server. Tu puedes controle la cantidad de programadores que SQL Server comienza con el uso del parámetro de inicio -P{ #schedulers }, pero esa es una herramienta de investigación un poco más agresiva en comparación con una opción de sesión.
En cualquier caso, sin emular ningún recurso, mi máquina de prueba tiene 4 CPU lógicas, lo que da como resultado DOP por coste 2 y DOP por ejecución 4. En mi entorno, el agregado local en el plan para la consulta 3 muestra una estimación de 1000 grupos de resultados (500 x 2), y un real de 2.000 (500 x 4). De manera similar, el agregado local en el plan para la Consulta 4 muestra una estimación de 10 grupos de resultados (5 x 2) y un real de 20 (5 x 4).
Cuando haya terminado de experimentar, ejecute el siguiente código para la limpieza:
-- Set cost threshold for parallelism to default EXEC sp_configure 'show advanced options', 1; RECONFIGURE; EXEC sp_configure 'cost threshold for parallelism', 5; EXEC sp_configure 'show advanced options', 0; RECONFIGURE; GO -- Reset OPTIMIZER_WHATIF options DBCC OPTIMIZER_WHATIF(ResetAll); -- Drop indexes DROP INDEX idx_oid_i_sid ON dbo.Orders; DROP INDEX idx_oid_i_eid ON dbo.Orders; DROP INDEX idx_oid_i_cid ON dbo.Orders;
Conclusión
En este artículo, describí una serie de estrategias de paralelismo que usa SQL Server para manejar la agrupación y la agregación. Un concepto importante a comprender en la optimización de consultas con planes paralelos es el grado de paralelismo (DOP) para el cálculo de costos. Mostré una serie de umbrales de optimización, incluido un umbral entre planes en serie y paralelos, y el umbral de costo de configuración para el paralelismo. La mayoría de los conceptos que describí aquí no son exclusivos de la agrupación y la agregación, sino que son igualmente aplicables a las consideraciones de planes paralelos en SQL Server en general. El próximo mes continuaré la serie discutiendo la optimización con reescrituras de consultas.