
Recientemente me regañaron por sugerir que, en algunos casos, un índice no agrupado funcionará mejor para una consulta en particular que el índice agrupado. Esta persona afirmó que el índice agrupado siempre es mejor porque siempre cubre por definición, y que cualquier índice no agrupado con algunas o todas las mismas columnas clave siempre era redundante.
Estaré felizmente de acuerdo en que el índice agrupado siempre está cubriendo (y para evitar cualquier ambigüedad aquí, nos ceñiremos a las tablas basadas en disco con índices de árbol B tradicionales).
 Sin embargo, no estoy de acuerdo con que un índice agrupado siempre más rápido que un índice no agrupado. Tampoco estoy de acuerdo con que siempre sea redundante crear un índice no agrupado o una restricción única que consista en las mismas (o algunas de las mismas) columnas en la clave de agrupación.
Sin embargo, no estoy de acuerdo con que un índice agrupado siempre más rápido que un índice no agrupado. Tampoco estoy de acuerdo con que siempre sea redundante crear un índice no agrupado o una restricción única que consista en las mismas (o algunas de las mismas) columnas en la clave de agrupación.
Tomemos este ejemplo, Warehouse.StockItemTransactions , de WideWorldImporters. El índice agrupado se implementa a través de una clave principal solo en StockItemTransactionID columna (bastante típico cuando tienes algún tipo de ID sustituto generado por una IDENTIDAD o una SECUENCIA).
Es algo bastante común requerir un recuento de toda la tabla (aunque en muchos casos hay mejores formas). Esto puede ser para una inspección casual o como parte de un procedimiento de paginación. La mayoría de la gente lo hará de esta manera:
SELECT COUNT(*) FROM Warehouse.StockItemTransactions;
Con el esquema actual, esto usará un índice no agrupado:
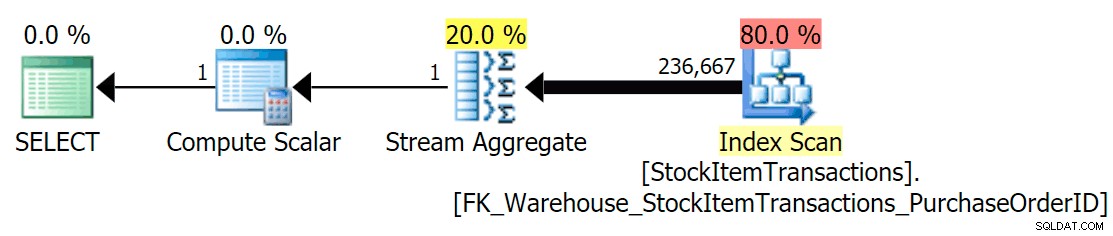
Sabemos que el índice no agrupado no contiene todas las columnas del índice agrupado. La operación de conteo solo necesita asegurarse de que se incluyan todas las filas, sin importar qué columnas estén presentes, por lo que SQL Server generalmente elegirá el índice con la menor cantidad de páginas (en este caso, el índice elegido tiene ~414 páginas).
Ahora ejecutemos la consulta nuevamente, esta vez comparándola con una consulta sugerida que fuerza el uso del índice agrupado.
SELECT COUNT(*) FROM Warehouse.StockItemTransactions; SELECT COUNT(*) /* with hint */ FROM Warehouse.StockItemTransactions WITH (INDEX(1));
Obtenemos una forma de plan casi idéntica, pero podemos ver una gran diferencia en las lecturas (414 para el índice elegido frente a 1982 para el índice agrupado):
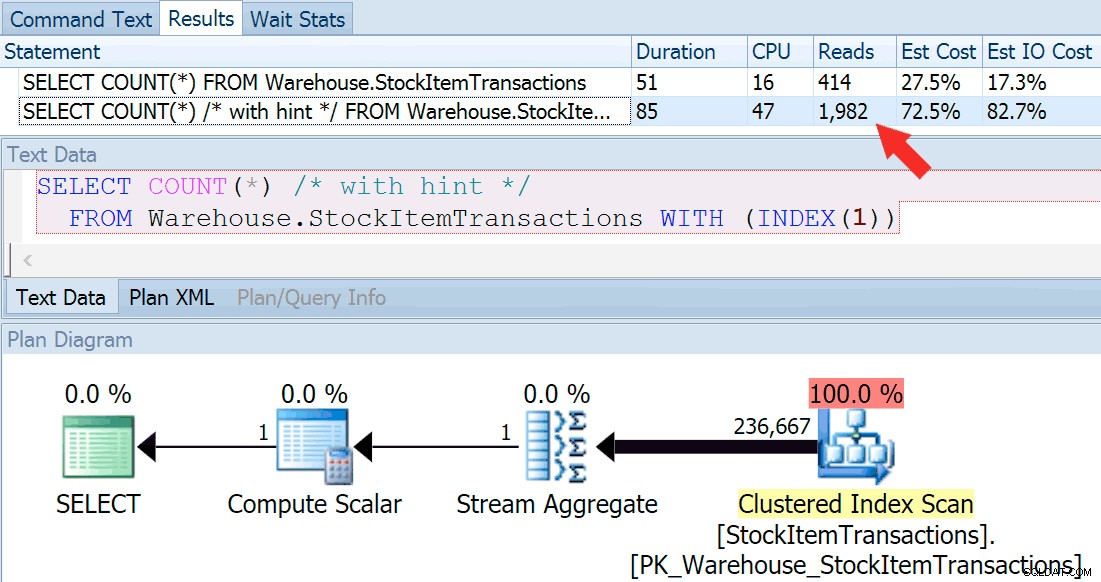
La duración es ligeramente mayor para el índice agrupado, pero la diferencia es insignificante cuando se trata de una pequeña cantidad de datos almacenados en caché en un disco rápido. Esa discrepancia sería mucho más pronunciada con más datos, en un disco lento o en un sistema con presión de memoria.
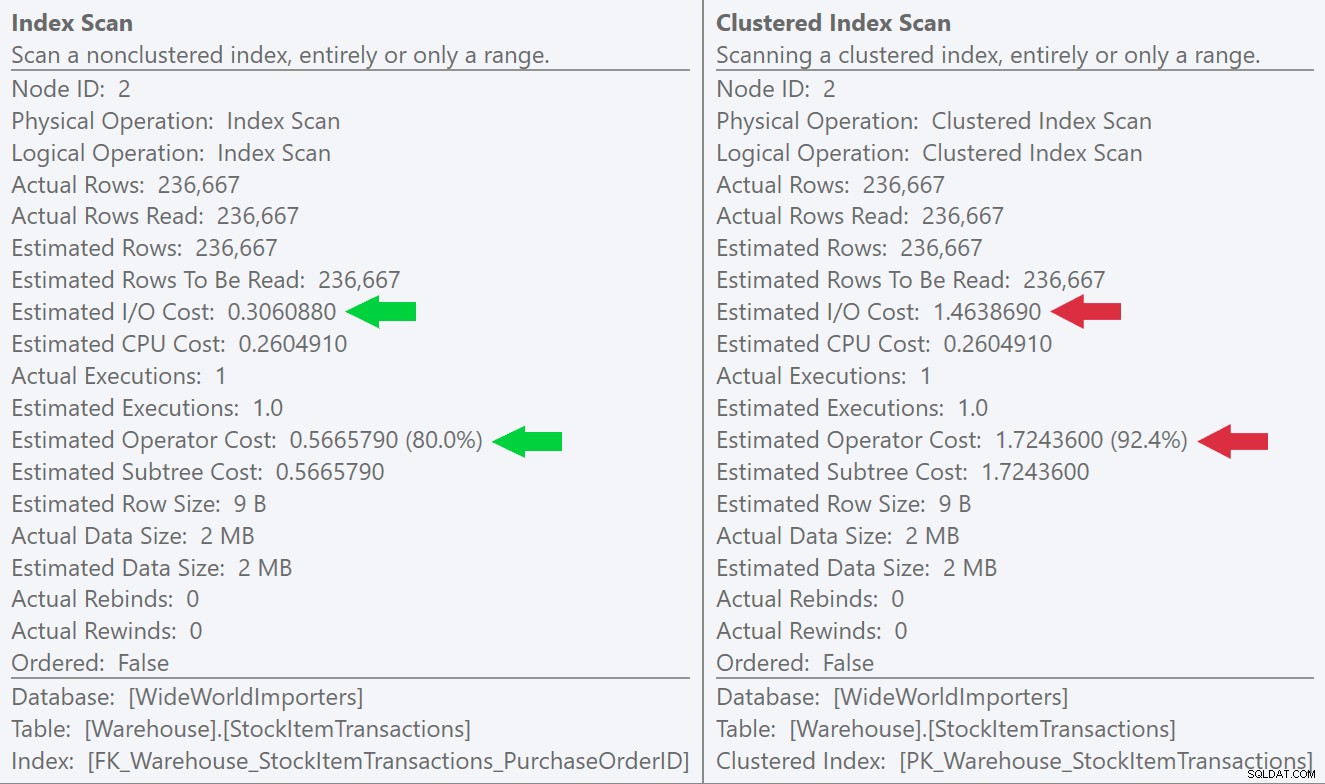
Si observamos la información sobre herramientas para las operaciones de exploración, podemos ver que, si bien la cantidad de filas y los costos de CPU estimados son idénticos, la gran diferencia proviene del costo de E/S estimado (porque SQL Server sabe que hay más páginas en el índice agrupado que el índice no agrupado):
Podemos ver esta diferencia aún más claramente si creamos un índice nuevo y único solo en la columna ID (haciéndolo "redundante" con el índice agrupado, ¿verdad?):
CREATE UNIQUE INDEX NewUniqueNCIIndex ON Warehouse.StockItemTransactions(StockItemTransactionID);
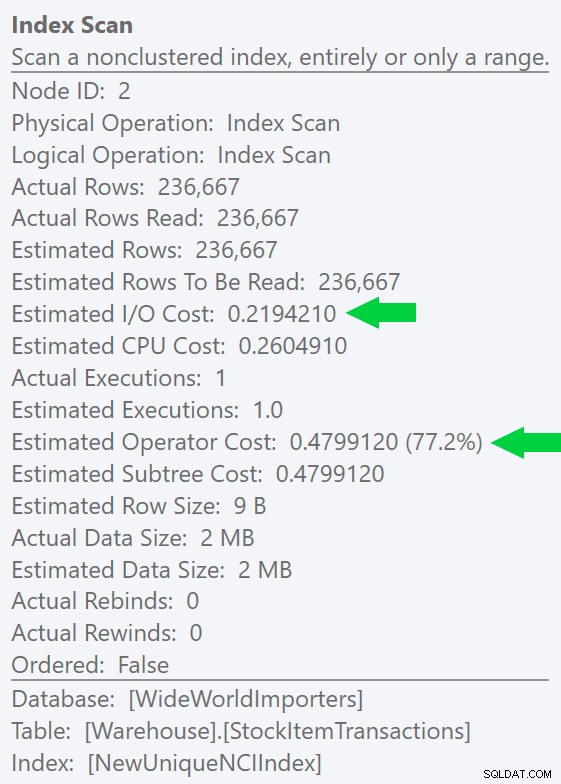 Ejecutar una consulta similar con una sugerencia de índice explícita produce la misma forma de plan, pero una E/S estimada aún más baja costo (e incluso duraciones más bajas):vea la imagen a la derecha. Y si ejecuta la consulta original sin la sugerencia, verá que SQL Server ahora también elige este índice.
Ejecutar una consulta similar con una sugerencia de índice explícita produce la misma forma de plan, pero una E/S estimada aún más baja costo (e incluso duraciones más bajas):vea la imagen a la derecha. Y si ejecuta la consulta original sin la sugerencia, verá que SQL Server ahora también elige este índice.
Puede parecer obvio, pero mucha gente creería que el índice agrupado es la mejor opción aquí. SQL Server casi siempre favorecerá en gran medida cualquier método que proporcione la forma más económica de realizar todas las operaciones de E/S y, en el caso de un análisis completo, ese será el índice "más delgado". Esto también puede ocurrir con ambos tipos de búsquedas (escaneos de un solo tono y de rango), al menos cuando el índice está cubriendo.
Ahora, como siempre, eso no de ninguna manera significa que debe ir y crear índices adicionales en todas sus tablas para satisfacer las consultas de conteo. No solo es una forma ineficiente de verificar el tamaño de la tabla (nuevamente, vea este artículo), sino un índice de soporte que tendría que significar que está ejecutando esa consulta con más frecuencia de lo que está actualizando los datos. Recuerde que cada índice requiere espacio en el disco, espacio en la memoria, y todas las escrituras en la tabla también deben tocar todos los índices (aparte de los índices filtrados).
Resumen
Podría encontrar muchos otros ejemplos que muestren cuándo un índice no agrupado puede ser útil y vale la pena el costo de mantenimiento, incluso cuando se duplican las columnas clave del índice agrupado. Los índices no agrupados se pueden crear con las mismas columnas de clave pero en un orden de clave diferente, o con ASC/DESC diferentes en las propias columnas para admitir mejor un orden de presentación alternativo. También puede tener índices no agrupados que solo contengan un pequeño subconjunto de las filas mediante el uso de un filtro. Finalmente, si puede satisfacer sus consultas más comunes con índices más delgados y no agrupados, también es mejor para el consumo de memoria.
Pero en realidad, mi punto de esta serie es simplemente mostrar un contraejemplo que ilustra la locura de hacer declaraciones generales como esta. Los dejo con una explicación de Paul White quien, en una respuesta de DBA.SE, explica por qué un índice no agrupado de este tipo puede funcionar mucho mejor que un índice agrupado. Esto es cierto incluso cuando ambos usan cualquier tipo de búsqueda:
- Diferencia entre búsqueda de índice agrupado y búsqueda de índice no agrupado



