Escribí anteriormente sobre la propiedad Lectura de filas reales. Le dice cuántas filas son realmente leídas por una búsqueda de índice, para que pueda ver qué tan selectivo es el predicado de búsqueda, en comparación con la selectividad del predicado de búsqueda más el predicado residual combinados.
Pero echemos un vistazo a lo que realmente sucede dentro del operador Seek. Porque no estoy convencido de que "Lectura de filas reales" sea necesariamente una descripción precisa de lo que está sucediendo.
Quiero ver un ejemplo que consulta direcciones de tipos de direcciones particulares para un cliente, pero el principio aquí se aplicaría fácilmente a muchas otras situaciones si la forma de su consulta se ajusta, como buscar atributos en una tabla de par clave-valor, por ejemplo.
SELECT AddressTypeID, FullAddress FROM dbo.Addresses WHERE CustomerID = 783 AND AddressTypeID IN (2,4,5);
Sé que no les he mostrado nada sobre los metadatos; volveré a eso en un minuto. Pensemos en esta consulta y qué tipo de índice nos gustaría tener para ella.
En primer lugar, conocemos exactamente el CustomerID. Una coincidencia de igualdad como esta generalmente lo convierte en un excelente candidato para la primera columna de un índice. Si tuviéramos un índice en esta columna, podríamos sumergirnos directamente en las direcciones de ese cliente, así que diría que es una suposición segura.
Lo siguiente a considerar es ese filtro en AddressTypeID. Agregar una segunda columna a las claves de nuestro índice es perfectamente razonable, así que hagámoslo. Nuestro índice ahora está activado (CustomerID, AddressTypeID). Y vamos a INCLUIR FullAddress también, para que no tengamos que hacer ninguna búsqueda para completar la imagen.
Y creo que hemos terminado. Deberíamos poder asumir con seguridad que el índice ideal para esta consulta es:
CREATE INDEX ixIdealIndex ON dbo.Addresses (CustomerID, AddressTypeID) INCLUDE (FullAddress);
Podríamos declararlo potencialmente como un índice único; veremos el impacto de eso más adelante.
Entonces, creemos una tabla (estoy usando tempdb, porque no necesito que persista más allá de esta publicación de blog) y pruébalo.
CREATE TABLE dbo.Addresses ( AddressID INT IDENTITY(1,1) PRIMARY KEY, CustomerID INT NOT NULL, AddressTypeID INT NOT NULL, FullAddress NVARCHAR(MAX) NOT NULL, SomeOtherColumn DATE NULL );
No estoy interesado en las restricciones de clave externa, o qué otras columnas podría haber. Solo me interesa mi índice ideal. Así que crea eso también, si aún no lo has hecho.
Mi plan parece bastante perfecto.
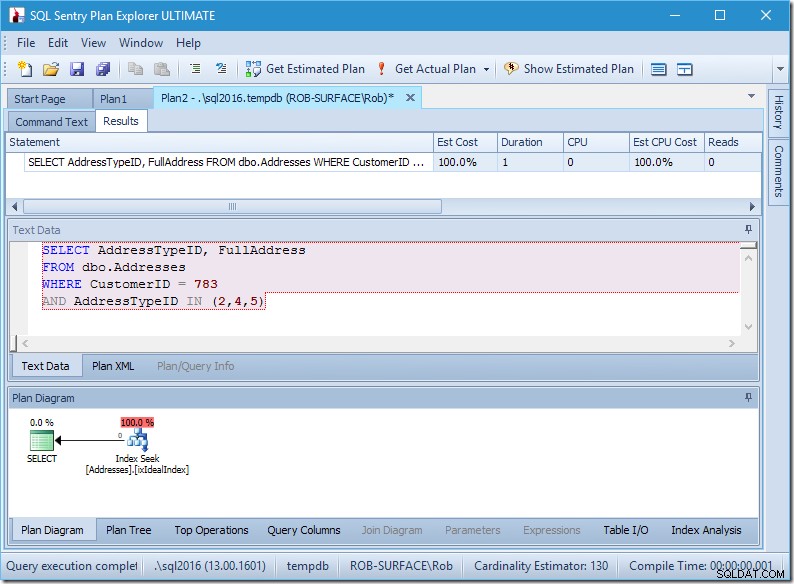
Tengo una búsqueda de índice, y eso es todo.
De acuerdo, no hay datos, por lo que no hay lecturas, ni CPU, y también se ejecuta bastante rápido. Ojalá todas las consultas pudieran ajustarse tan bien como esta.
Veamos qué está pasando un poco más de cerca, observando las propiedades de Seek.
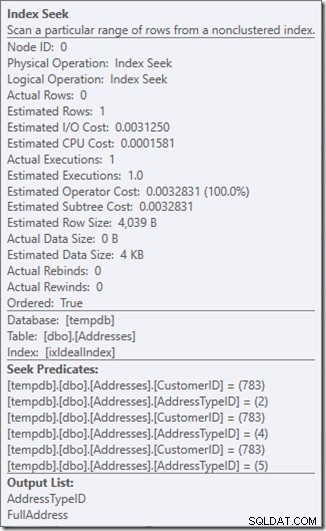
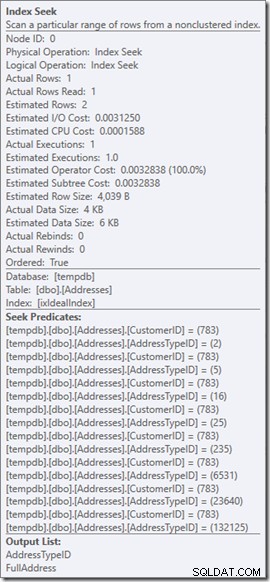
Podemos ver los predicados Seek. Hay seis. Tres sobre CustomerID y tres sobre AddressTypeID. Lo que realmente tenemos aquí son tres conjuntos de predicados de búsqueda, que indican tres operaciones de búsqueda dentro del único operador de búsqueda. La primera búsqueda busca Cliente 783 y Tipo de dirección 2. La segunda busca 783 y 4, y la última 783 y 5. Nuestro operador de búsqueda apareció una vez, pero había tres búsquedas en curso dentro de él.
Ni siquiera tenemos datos, pero podemos ver cómo se utilizará nuestro índice.
Pongamos algunos datos ficticios, para que podamos ver algunos de los efectos de esto. Voy a poner direcciones para los tipos 1 a 6. Cada cliente (más de 2000, según el tamaño de master..spt_values ) tendrá una dirección de tipo 1. Tal vez esa sea la dirección principal. Permito que el 80 % tenga una dirección de tipo 2, el 60 % una de tipo 3, y así sucesivamente, hasta el 20 % para la de tipo 5. La fila 783 obtendrá direcciones de tipo 1, 2, 3 y 4, pero no la 5. Preferiría haber ido con valores aleatorios, pero quiero asegurarme de que estamos en la misma página para los ejemplos.
WITH nums AS (
SELECT row_number() OVER (ORDER BY (SELECT 1)) AS num
FROM master..spt_values
)
INSERT dbo.Addresses (CustomerID, AddressTypeID, FullAddress)
SELECT num AS CustomerID, 1 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
UNION ALL
SELECT num AS CustomerID, 2 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 8
UNION ALL
SELECT num AS CustomerID, 3 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 6
UNION ALL
SELECT num AS CustomerID, 4 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 4
UNION ALL
SELECT num AS CustomerID, 5 AS AddressTypeID, N'Some sample text for the address' AS FullAddress
FROM nums
WHERE num % 10 < 2
; Ahora veamos nuestra consulta con datos. Salen dos filas. Es como antes, pero ahora vemos las dos filas que salen del operador Buscar y vemos seis lecturas (en la parte superior derecha).
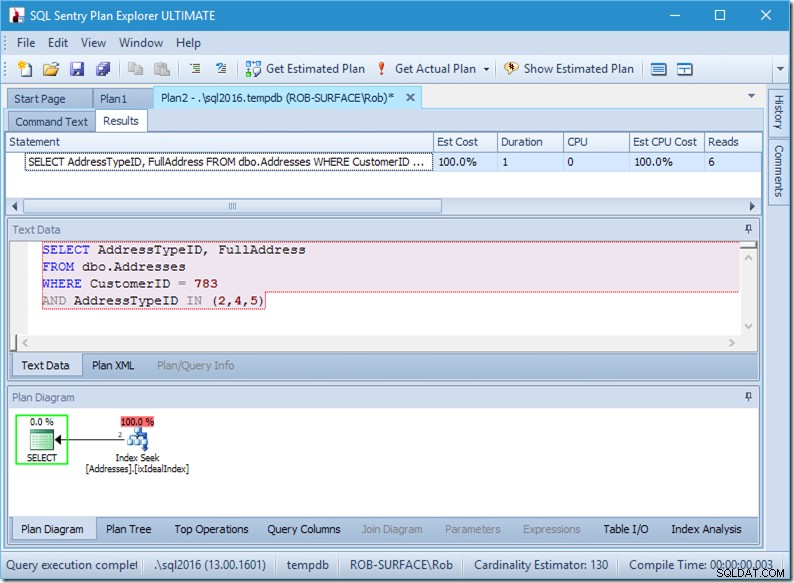
Seis lecturas tienen sentido para mí. Tenemos una mesa pequeña y el índice se ajusta a solo dos niveles. Estamos haciendo tres búsquedas (dentro de nuestro único operador), por lo que el motor está leyendo la página raíz, averiguando a qué página bajar y leyendo eso, y haciéndolo tres veces.
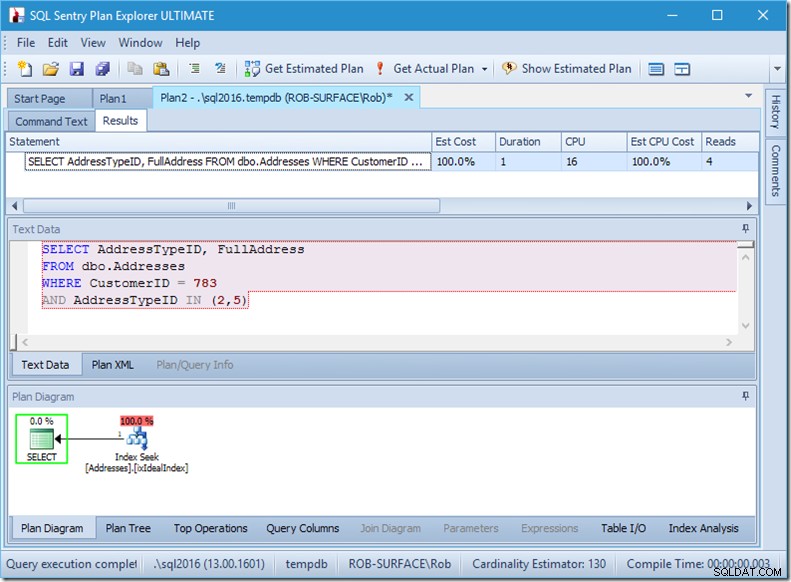
Si solo buscáramos dos AddressTypeID, veríamos solo 4 lecturas (y en este caso, se generaría una sola fila). Excelente.
Y si estuviéramos buscando 8 tipos de direcciones, veríamos 16.
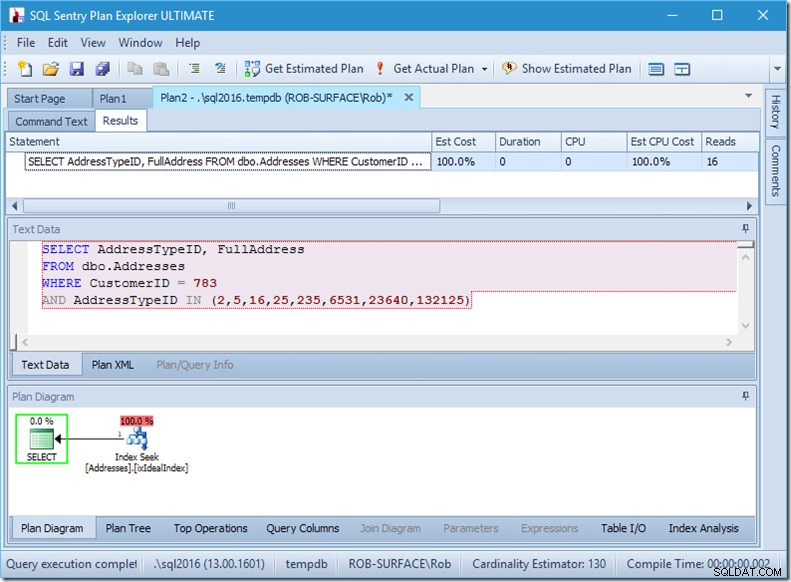
Sin embargo, cada uno de estos muestra que la lectura de filas reales coincide exactamente con las filas reales. ¡Ninguna ineficiencia en absoluto!
Volvamos a nuestra consulta original, buscando los tipos de dirección 2, 4 y 5 (que devuelven 2 filas) y pensemos en lo que sucede dentro de la búsqueda.
Voy a suponer que el motor de consulta ya ha hecho el trabajo para determinar que Index Seek es la operación correcta y que tiene a mano el número de página de la raíz del índice.
En este punto, carga esa página en la memoria, si aún no está allí. Esa es la primera lectura que se cuenta en la ejecución de la búsqueda. Luego localiza el número de página de la fila que está buscando y lee esa página. Esa es la segunda lectura.
Pero a menudo pasamos por alto el bit "ubica el número de página".
Usando DBCC IND(2, N'dbo.Address', 2); (el primer 2 es la identificación de la base de datos porque estoy usando tempdb; el segundo 2 es el ID de índice de ixIdealIndex ), puedo descubrir que el 712 en el archivo 1 es la página con el IndexLevel más alto. En la captura de pantalla a continuación, puedo ver que la página 668 es IndexLevel 0, que es la página raíz.

Ahora puedo usar DBCC TRACEON(3604); DBCC PAGE (2,1,712,3); para ver el contenido de la página 712. En mi máquina, recibo 84 filas y puedo decir que CustomerID 783 estará en la página 1004 del archivo 5.
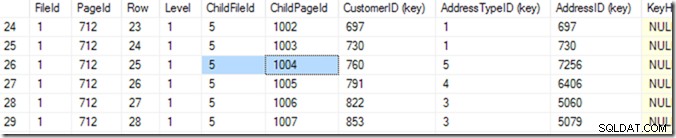
Pero sé esto al desplazarme por mi lista hasta que veo el que quiero. Empecé desplazándome un poco hacia abajo y luego volví a subir, hasta que encontré la fila que quería. Una computadora llama a esto una búsqueda binaria, y es un poco más precisa que yo. Está buscando la fila donde la combinación (CustomerID, AddressTypeID) es más pequeña que la que estoy buscando, y la siguiente página es más grande o igual. Digo “lo mismo” porque puede haber dos que coincidan, repartidos en dos páginas. Sabe que hay 84 filas (0 a 83) de datos en esa página (lo lee en el encabezado de la página), por lo que comenzará comprobando la fila 41. A partir de ahí, sabe en qué mitad buscar y (en este ejemplo), leerá la fila 20. Algunas lecturas más (haciendo 6 o 7 en total)* y sabe que la fila 25 (mire la columna llamada 'Fila' para este valor, no el número de fila proporcionado por SSMS ) es demasiado pequeño, pero la fila 26 es demasiado grande, ¡así que 25 es la respuesta!
*En una búsqueda binaria, la búsqueda puede ser marginalmente más rápida si tiene suerte cuando divide el bloque en dos si no hay un espacio intermedio, y dependiendo de si el espacio intermedio se puede eliminar o no.
Ahora puede ir a la página 1004 en el archivo 5. Usemos DBCC PAGE en ese.
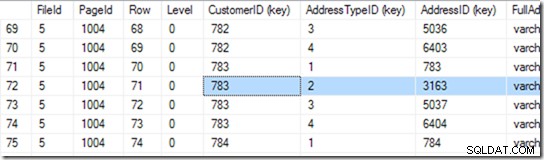
Este me da 94 filas. Hace otra búsqueda binaria para encontrar el inicio del rango que está buscando. Tiene que mirar a través de 6 o 7 filas para encontrar eso.
"¿Comienzo del rango?" Puedo oírte preguntar. Pero estamos buscando el tipo de dirección 2 del cliente 783.
Correcto, pero no declaramos este índice como único. Así que podría haber dos. Si es único, la búsqueda puede realizar una búsqueda de singleton y podría tropezar con él durante la búsqueda binaria, pero en este caso, debe completar la búsqueda binaria para encontrar la primera fila en el rango. En este caso, es la fila 71.
Pero no nos detenemos aquí. ¡Ahora tenemos que ver si realmente hay una segunda! Así que lee la fila 72 también, y encuentra que el par CustomerID+AddressTypeiD es demasiado grande, y su búsqueda está hecha.
Y esto sucede tres veces. La tercera vez, no encuentra una fila para el cliente 783 y el tipo de dirección 5, pero no lo sabe con anticipación y aún necesita completar la búsqueda.
Entonces, las filas que realmente se leen en estas tres búsquedas (para encontrar dos filas para generar) son mucho más que el número que se devuelve. Hay alrededor de 7 en el nivel de índice 1 y alrededor de 7 más en el nivel de hoja solo para encontrar el comienzo del rango. Luego lee la fila que nos interesa y luego la fila siguiente. Eso suena más como 16 para mí, y lo hace tres veces, formando alrededor de 48 filas.
Pero Actual Rows Read no se trata de la cantidad de filas realmente leídas, sino de la cantidad de filas devueltas por Seek Predicate, que se prueban con Residual Predicate. Y en eso, solo las 2 filas son encontradas por las 3 búsquedas.
Podrías estar pensando en este punto que hay una cierta cantidad de ineficacia aquí. La segunda búsqueda también habría leído la página 712, verificado las mismas 6 o 7 filas allí, y luego leído la página 1004, y buscado a través de ella... al igual que la tercera búsqueda.
Entonces, tal vez hubiera sido mejor obtener esto en una sola búsqueda, leyendo la página 712 y la página 1004 solo una vez cada una. Después de todo, si estuviera haciendo esto con un sistema basado en papel, habría hecho una búsqueda para encontrar al cliente 783 y luego escaneado todos sus tipos de direcciones. Porque sé que un cliente no suele tener muchas direcciones. Esa es una ventaja que tengo sobre el motor de base de datos. El motor de la base de datos sabe a través de sus estadísticas que una búsqueda será la mejor, pero no sabe que la búsqueda solo debe bajar un nivel, cuando puede decir que tiene lo que parece ser el índice ideal.
Si cambio mi consulta para obtener un rango de tipos de direcciones, de 2 a 5, obtengo casi el comportamiento que quiero:
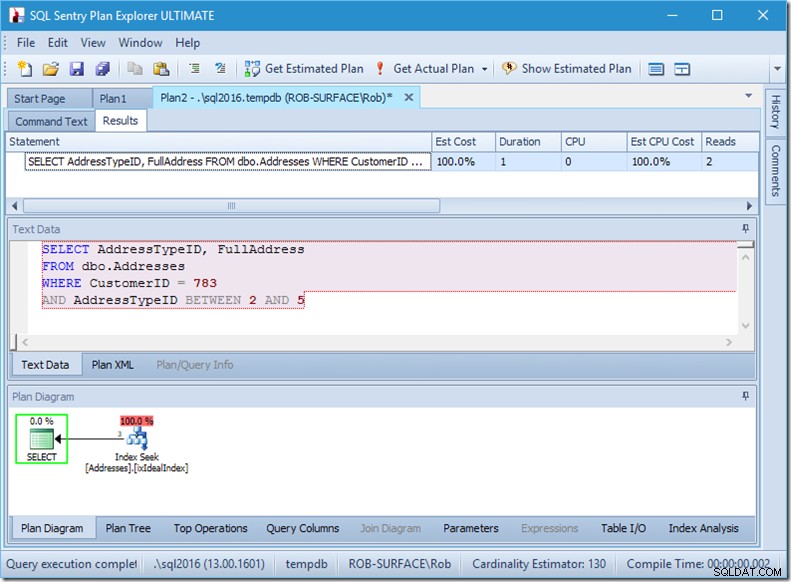
Mire, las lecturas se han reducido a 2 y sé qué páginas son...
… pero mis resultados son incorrectos. Porque solo quiero los tipos de dirección 2, 4 y 5, no 3. Necesito decirle que no tenga 3, pero tengo que tener cuidado con cómo lo hago. Mira los siguientes dos ejemplos.
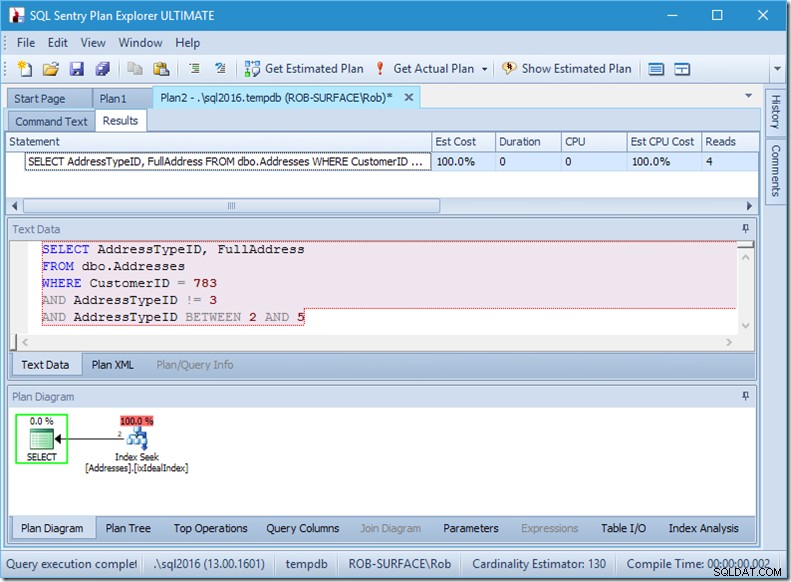
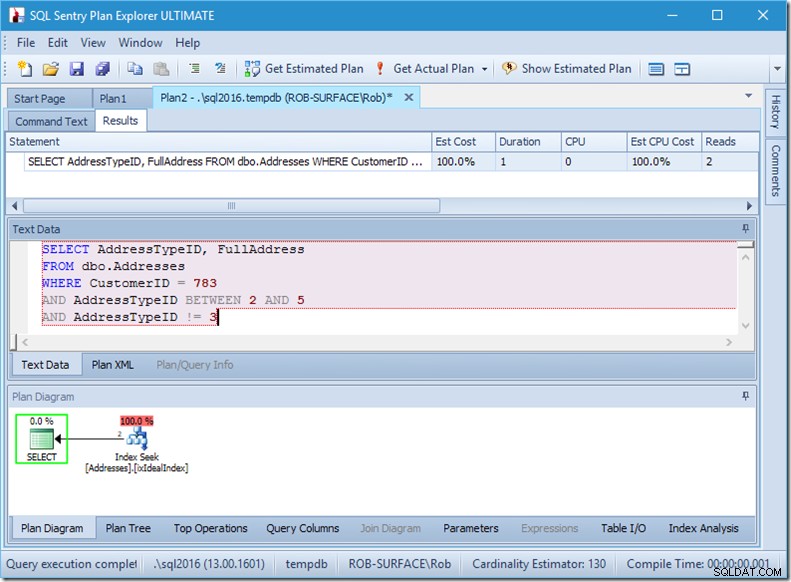
Les puedo asegurar que el orden de los predicados no importa, pero aquí claramente sí. Si ponemos el "no 3" primero, hace dos búsquedas (4 lecturas), pero si ponemos el "no 3" en segundo lugar, hace una sola búsqueda (2 lecturas).
El problema es que AddressTypeID !=3 se convierte en (AddressTypeID> 3 OR AddressTypeID <3), que luego se ve como dos predicados de búsqueda muy útiles.
Entonces, mi preferencia es usar un predicado no sargable para decirle que solo quiero los tipos de dirección 2, 4 y 5. Y puedo hacerlo modificando AddressTypeID de alguna manera, como agregarle cero.
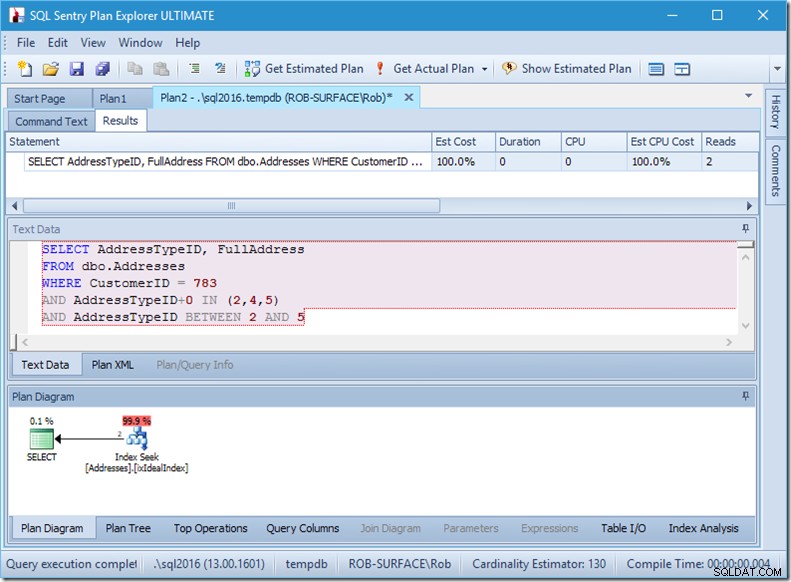
Ahora tengo un escaneo agradable y de rango estrecho dentro de una sola búsqueda, y todavía me estoy asegurando de que mi consulta arroje solo las filas que quiero.
Oh, ¿pero esa propiedad de lectura de filas reales? Eso ahora es más alto que la propiedad Filas reales, porque el Predicado de búsqueda encuentra el tipo de dirección 3, que el Predicado residual rechaza.
Cambié tres búsquedas perfectas por una sola búsqueda imperfecta, que estoy arreglando con un predicado residual.
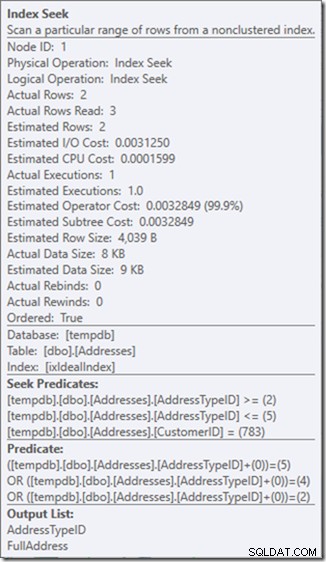
Y para mí, ese es a veces un precio que vale la pena pagar, obtener un plan de consultas con el que estoy mucho más feliz. No es considerablemente más barato, aunque solo tiene un tercio de las lecturas (porque solo habría dos lecturas físicas), pero cuando pienso en el trabajo que está haciendo, me siento mucho más cómodo con lo que le estoy pidiendo. hacerlo de esta manera.