Si usa el particionamiento de tablas con una o más particiones almacenadas en un grupo de archivos de solo lectura, las instrucciones de actualización y eliminación de SQL pueden fallar y generar un error. Por supuesto, este es el comportamiento esperado si alguna de las modificaciones requiere escribir en un grupo de archivos de solo lectura; sin embargo, también es posible encontrar esta condición de error donde los cambios están restringidos a grupos de archivos marcados como lectura-escritura.
Base de datos de muestra
Para demostrar el problema, crearemos una base de datos simple con un solo grupo de archivos personalizado que luego marcaremos como de solo lectura. Tenga en cuenta que deberá agregar la ruta del nombre de archivo para adaptarse a su instancia de prueba.
USE master;
GO
CREATE DATABASE Test;
GO
-- This filegroup will be marked read-only later
ALTER DATABASE Test
ADD FILEGROUP ReadOnlyFileGroup;
GO
-- Add a file to the new filegroup
ALTER DATABASE Test
ADD FILE
(
NAME = 'Test_RO',
FILENAME = '<...your path...>\MSSQL\DATA\Test_ReadOnly.ndf'
)
TO FILEGROUP ReadOnlyFileGroup; Función y esquema de partición
Ahora crearemos una función de partición básica y un esquema que dirigirá filas con datos antes del 1 de enero de 2000 a la partición de sólo lectura. Los datos posteriores se mantendrán en el grupo de archivos principal de lectura y escritura:
USE Test;
GO
CREATE PARTITION FUNCTION PF (datetime)
AS RANGE RIGHT
FOR VALUES ({D '2000-01-01'});
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
TO (ReadOnlyFileGroup, [PRIMARY]); La especificación de rango correcto significa que las filas con el valor de límite 1 de enero de 2000 estarán en la partición de lectura y escritura.
Tabla e índices particionados
Ahora podemos crear nuestra tabla de prueba:
CREATE TABLE dbo.Test
(
dt datetime NOT NULL,
c1 integer NOT NULL,
c2 integer NOT NULL,
CONSTRAINT PK_dbo_Test__c1_dt
PRIMARY KEY CLUSTERED (dt)
ON PS (dt)
)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c1
ON dbo.Test (c1)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c2
ON dbo.Test (c2)
ON PS (dt); La tabla tiene una clave principal agrupada en la columna de fecha y hora y también está dividida en esa columna. Hay índices no agrupados en las otras dos columnas de enteros, que están particionados de la misma manera (los índices están alineados con la tabla base).
Datos de muestra
Finalmente, agregamos un par de filas de datos de ejemplo y hacemos que la partición de datos anterior a 2000 sea de solo lectura:
INSERT dbo.Test WITH (TABLOCKX)
(dt, c1, c2)
VALUES
({D '1999-12-31'}, 1, 1), -- Read only
({D '2000-01-01'}, 2, 2); -- Writable
GO
ALTER DATABASE Test
MODIFY FILEGROUP
ReadOnlyFileGroup READ_ONLY;
Puede usar las siguientes declaraciones de actualización de prueba para confirmar que los datos en la partición de solo lectura no se pueden modificar, mientras que los datos con un dt el valor a partir del 1 de enero de 2000 se puede escribir a:
-- Will fail, as expected
UPDATE dbo.Test
SET c2 = 1
WHERE dt = {D '1999-12-31'};
-- Will succeed, as expected
UPDATE dbo.Test
SET c2 = 999
WHERE dt = {D '2000-01-01'};
-- Reset the value of c2
UPDATE dbo.Test
SET c2 = 2
WHERE dt = {D '2000-01-01'}; Un fracaso inesperado
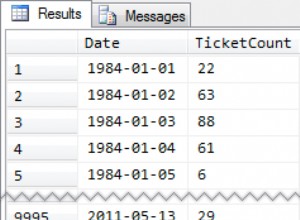
Tenemos dos filas:una de solo lectura (1999-12-31); y uno de lectura-escritura (2000-01-01):

Ahora intente la siguiente consulta. Identifica la misma fila de escritura "2000-01-01" que acabamos de actualizar con éxito, pero usa un predicado de cláusula where diferente:
UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;
El plan estimado (pre-ejecución) es:

Los cuatro (!) Compute Scalars no son importantes para esta discusión. Se utilizan para determinar si es necesario mantener el índice no agrupado para cada fila que llega al operador Actualización de índice agrupado.
Lo más interesante es que esta declaración de actualización falla con un error similar a:
Mensaje 652, nivel 16, estado 1El índice "PK_dbo_Test__c1_dt" para la tabla "dbo.Test" (RowsetId 72057594039042048) reside en un grupo de archivos de solo lectura ("ReadOnlyFileGroup"), que no se puede modificar.
Sin eliminación de particiones
Si ha trabajado con particiones antes, puede estar pensando que la 'eliminación de particiones' podría ser la razón. La lógica sería algo así:
En las declaraciones anteriores, se proporcionó un valor literal para la columna de partición en la cláusula where, por lo que SQL Server podría determinar inmediatamente a qué partición(es) acceder. Al cambiar la cláusula where para que ya no haga referencia a la columna de partición, hemos obligado a SQL Server a acceder a todas las particiones mediante un escaneo de índice agrupado.
Todo eso es cierto, en general, pero no es la razón por la que la declaración de actualización falla aquí.
El comportamiento esperado es que SQL Server debería poder leer desde cualquiera y todas las particiones durante la ejecución de la consulta. Una operación de modificación de datos solo debería fallar si el motor de ejecución realmente intenta modificar una fila almacenada en un grupo de archivos de solo lectura.
Para ilustrar, hagamos un pequeño cambio a la consulta anterior:
UPDATE dbo.Test
SET c2 = 2,
dt = dt
WHERE c1 = 2; La cláusula where es exactamente igual que antes. La única diferencia es que ahora estamos (deliberadamente) configurando la columna de partición igual a sí misma. Esto no cambiará el valor almacenado en esa columna, pero afectará el resultado. La actualización ahora tiene éxito (aunque con un plan de ejecución más complejo):

El optimizador introdujo nuevos operadores Split, Sort y Collapse, y agregó la maquinaria necesaria para mantener cada índice no agrupado potencialmente afectado por separado (mediante una estrategia amplia o por índice).
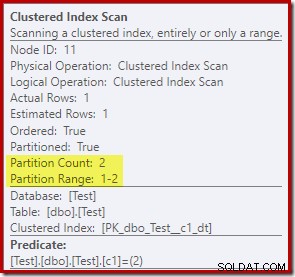
Las propiedades del análisis de índice agrupado muestran que ambas particiones de la tabla fueron accedidos al leer:
Por el contrario, la actualización del índice agrupado muestra que solo se accedió a la partición de lectura y escritura para escribir:
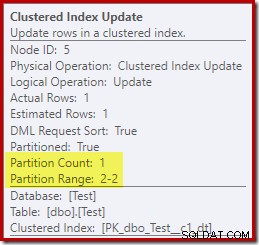
Cada uno de los operadores de actualización de índices no agrupados muestra información similar:solo la partición de escritura (#2) se modificó en tiempo de ejecución, por lo que no ocurrió ningún error.
La Razón Revelada
El nuevo plan tiene no éxito porque los índices no agrupados se mantienen por separado; ni es (directamente) debido a la combinación Split-Sort-Collapse necesaria para evitar errores transitorios de clave duplicada en el índice único.
La verdadera razón es algo que mencioné brevemente en mi artículo anterior, "Optimización de las consultas de actualización", una optimización interna conocida como Rowset Sharing. . Cuando se utiliza, la Actualización de índice agrupado comparte el mismo conjunto de filas del motor de almacenamiento subyacente que un Análisis de índice agrupado, Búsqueda o Búsqueda de clave en el lado de lectura del plan.
Con la optimización de Rowset Sharing, SQL Server busca grupos de archivos sin conexión o de solo lectura al leer En los planes en los que la actualización del índice agrupado utiliza un conjunto de filas independiente, la verificación fuera de línea/solo lectura solo se realiza para cada fila en el iterador de actualización (o eliminación).
Soluciones alternativas no documentadas
Primero, eliminemos las cosas divertidas, geek, pero poco prácticas.
La optimización del conjunto de filas compartido solo se puede aplicar cuando la ruta desde la búsqueda de índice agrupado, el escaneo o la búsqueda de clave es una tubería. . No se permiten operadores de bloqueo o semibloqueo. Dicho de otra manera, cada fila debe poder pasar del origen de lectura al destino de escritura antes de que se lea la siguiente fila.
Como recordatorio, aquí están los datos de muestra, la declaración y el plan de ejecución para el fallido actualizar de nuevo:
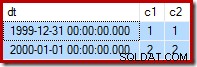
--Change the read-write row UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;

Protección de Halloween
Una forma de introducir un operador de bloqueo en el plan es requerir una Protección de Halloween (HP) explícita para esta actualización. Separar la lectura de la escritura con un operador de bloqueo evitará que se use la optimización para compartir el conjunto de filas (sin canalización). El indicador de seguimiento 8692 no documentado y no compatible (¡solo en el sistema de prueba!) agrega un Eager Table Spool para HP explícito:
-- Works (explicit HP) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8692);
El plan de ejecución real (disponible porque ya no se genera el error) es:

La combinación Ordenar en Dividir-Ordenar-Contraer que se vio en la actualización exitosa anterior proporciona el bloqueo necesario para deshabilitar el uso compartido de conjuntos de filas en esa instancia.
El indicador de rastreo de uso compartido anti-Rowset
Hay otra marca de seguimiento no documentada que deshabilita la optimización para compartir el conjunto de filas. Esto tiene la ventaja de no introducir un operador de bloqueo potencialmente costoso. Por supuesto, no se puede usar en la práctica (a menos que se comunique con el Soporte de Microsoft y obtenga algo por escrito que le recomiende habilitarlo, supongo). Sin embargo, con fines de entretenimiento, aquí está el indicador de rastreo 8746 en acción:
-- Works (no rowset sharing) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8746);
El plan de ejecución real para esa instrucción es:

Siéntase libre de experimentar con diferentes valores (unos que realmente cambien los valores almacenados si lo desea) para convencerse de la diferencia aquí. Como mencioné en mi publicación anterior, también puede usar el indicador de seguimiento no documentado 8666 para exponer la propiedad de uso compartido del conjunto de filas en el plan de ejecución.
Si desea ver el error de uso compartido del conjunto de filas con una declaración de eliminación, simplemente reemplace las cláusulas de actualización y configuración con una eliminación, mientras usa la misma cláusula where.
Soluciones alternativas admitidas
Hay varias formas posibles de garantizar que el uso compartido de conjuntos de filas no se aplique en consultas del mundo real sin usar marcas de seguimiento. Ahora que sabe que el problema central requiere un plan de lectura y escritura de índice agrupado compartido y canalizado, probablemente pueda crear el suyo propio. Aun así, hay un par de ejemplos que vale la pena mirar aquí.
Índice forzado / Índice de cobertura
Una idea natural es obligar al lado de lectura del plan a usar un índice no agrupado en lugar del índice agrupado. No podemos agregar una sugerencia de índice directamente a la consulta de prueba tal como está escrita, pero los alias de la tabla permiten esto:
UPDATE T SET c2 = 2 FROM dbo.Test AS T WITH (INDEX(IX_dbo_Test_c1)) WHERE c1 = 2;
Esta podría parecer la solución que el optimizador de consultas debería haber elegido en primer lugar, ya que tenemos un índice no agrupado en la columna de predicado de la cláusula where c1. El plan de ejecución muestra por qué el optimizador eligió lo que hizo:
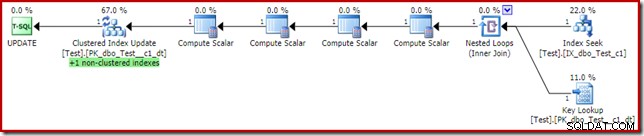
El costo de Key Lookup es suficiente para convencer al optimizador de usar el índice agrupado para la lectura. La búsqueda es necesaria para obtener el valor actual de la columna c2, por lo que Compute Scalars puede decidir si es necesario mantener el índice no agrupado.
Agregar la columna c2 al índice no agrupado (clave o incluir) evitaría el problema. El optimizador elegiría el índice de cobertura actual en lugar del índice agrupado.
Dicho esto, no siempre es posible anticipar qué columnas se necesitarán, o incluirlas todas aunque se conozca el conjunto. Recuerde, la columna es necesaria porque c2 está en la cláusula set de la declaración de actualización. Si las consultas son ad-hoc (por ejemplo, enviadas por usuarios o generadas por una herramienta), cada índice no agrupado debería incluir todas las columnas para que esta sea una opción sólida.
Una cosa interesante sobre el plan con la búsqueda de claves anterior es que no generar un error. Esto es a pesar de la búsqueda de claves y la actualización del índice agrupado mediante un conjunto de filas compartido. La razón es que la Búsqueda de índice no agrupada ubica la fila con c1 =2 antes Key Lookup toca el índice agrupado. La verificación del conjunto de filas compartido para grupos de archivos fuera de línea/de solo lectura aún se realiza en la búsqueda, pero no toca la partición de solo lectura, por lo que no se genera ningún error. Como último punto de interés (relacionado), tenga en cuenta que Index Seek toca ambas particiones, pero Key Lookup solo toca una.
Excluyendo la partición de solo lectura
Una solución trivial es confiar en la eliminación de particiones para que el lado de lectura del plan nunca toque la partición de solo lectura. Esto se puede hacer con un predicado explícito, por ejemplo cualquiera de estos:
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND dt >= {D '2000-01-01'};
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND $PARTITION.PF(dt) > 1; -- Not partition #1 Donde sea imposible, o inconveniente, cambiar cada consulta para agregar un predicado de eliminación de partición, otras soluciones como la actualización a través de una vista pueden ser adecuadas. Por ejemplo:
CREATE VIEW dbo.TestWritablePartitions
WITH SCHEMABINDING
AS
-- Only the writable portion of the table
SELECT
T.dt,
T.c1,
T.c2
FROM dbo.Test AS T
WHERE
$PARTITION.PF(dt) > 1;
GO
-- Succeeds
UPDATE dbo.TestWritablePartitions
SET c2 = 2
WHERE c1 = 2; Una desventaja de usar una vista es que una actualización o eliminación que se dirija a la parte de solo lectura de la tabla base tendrá éxito sin que las filas se vean afectadas, en lugar de fallar con un error. Un disparador en lugar de en la tabla o vista podría ser una solución para eso en algunas situaciones, pero también puede presentar más problemas... pero estoy divagando.
Como se mencionó anteriormente, hay muchas posibles soluciones admitidas. El objetivo de este artículo es mostrar cómo el uso compartido de conjuntos de filas causó el error de actualización inesperado.