Nota:esta publicación se publicó originalmente solo en nuestro libro electrónico, Técnicas de alto rendimiento para SQL Server, Volumen 3. Puede obtener más información sobre nuestros libros electrónicos aquí.
Un requisito que veo ocasionalmente es que se devuelva una consulta con pedidos agrupados por cliente, que muestre el total máximo adeudado visto para cualquier pedido hasta la fecha (un "máximo acumulado"). Así que imagina estas filas de muestra:
| Id. de pedido de venta | ID de cliente | Fecha del pedido | Total adeudado |
|---|---|---|---|
| 12 | 2 | 2014-01-01 | 37,55 |
| 23 | 1 | 2014-01-02 | 45.29 |
| 31 | 2 | 2014-01-03 | 24.56 |
| 32 | 2 | 2014-01-04 | 89.84 |
| 37 | 1 | 2014-01-05 | 32.56 |
| 44 | 2 | 2014-01-06 | 45.54 |
| 55 | 1 | 2014-01-07 | 99.24 |
| 62 | 2 | 2014-01-08 | 12.55 |
Algunas filas de datos de muestra
Los resultados deseados de los requisitos establecidos son los siguientes:en términos sencillos, ordene los pedidos de cada cliente por fecha y enumere cada pedido. Si ese es el valor TotalDue más alto para todos los pedidos vistos hasta esa fecha, imprima el total de ese pedido; de lo contrario, imprima el valor TotalDue más alto de todos los pedidos anteriores:
| Id. de pedido de venta | ID de cliente | Fecha del pedido | Total adeudado | MaxTotalDue |
|---|---|---|---|---|
| 12 | 1 | 2014-01-02 | 45.29 | 45.29 |
| 23 | 1 | 2014-01-05 | 32.56 | 45.29 |
| 31 | 1 | 2014-01-07 | 99.24 | 99.24 |
| 32 | 2 | 2014-01-01 | 37,55 | 37,55 |
| 37 | 2 | 2014-01-03 | 24,56 | 37,55 |
| 44 | 2 | 2014-01-04 | 89,84 | 89,84 |
| 55 | 2 | 2014-01-06 | 45.54 | 89,84 |
| 62 | 2 | 2014-01-08 | 12.55 | 89,84 |
Ejemplos de resultados deseados
Mucha gente instintivamente querría usar un cursor o un ciclo while para lograr esto, pero existen varios enfoques que no involucran estas construcciones.
Subconsulta correlacionada
Este enfoque parece ser el más simple y directo para el problema, pero se ha demostrado una y otra vez que no escala, ya que las lecturas crecen exponencialmente a medida que la tabla se hace más grande:
SELECT /* Correlated Subquery */ SalesOrderID, CustomerID, OrderDate, TotalDue,
MaxTotalDue = (SELECT MAX(TotalDue)
FROM Sales.SalesOrderHeader
WHERE CustomerID = h.CustomerID
AND SalesOrderID <= h.SalesOrderID)
FROM Sales.SalesOrderHeader AS h
ORDER BY CustomerID, SalesOrderID; Aquí está el plan contra AdventureWorks2014, usando SQL Sentry Plan Explorer:
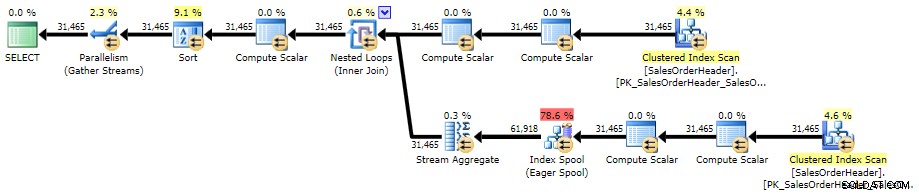 Plan de ejecución para la subconsulta correlacionada (haga clic para ampliar)
Plan de ejecución para la subconsulta correlacionada (haga clic para ampliar)
APLICACIÓN CRUZADA autorreferencial
Este enfoque es casi idéntico al enfoque de subconsulta correlacionada, en términos de sintaxis, forma del plan y rendimiento a escala.
SELECT /* CROSS APPLY */ h.SalesOrderID, h.CustomerID, h.OrderDate, h.TotalDue, x.MaxTotalDue
FROM Sales.SalesOrderHeader AS h
CROSS APPLY
(
SELECT MaxTotalDue = MAX(TotalDue)
FROM Sales.SalesOrderHeader AS i
WHERE i.CustomerID = h.CustomerID
AND i.SalesOrderID <= h.SalesOrderID
) AS x
ORDER BY h.CustomerID, h.SalesOrderID; El plan es bastante similar al plan de subconsultas correlacionadas, con la única diferencia de la ubicación de un tipo:
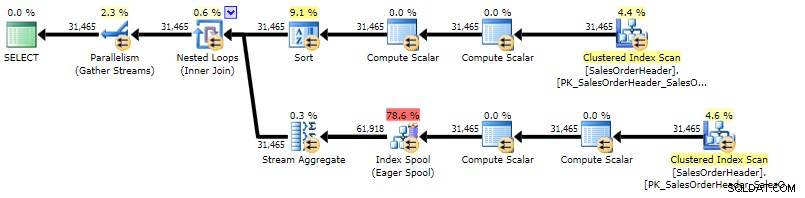 Plan de ejecución para CROSS APPLY (haga clic para ampliar)
Plan de ejecución para CROSS APPLY (haga clic para ampliar)
CTE recursivo
Detrás de escena, esto usa bucles, pero hasta que realmente lo ejecutemos, podemos fingir que no lo hace (aunque fácilmente es la pieza de código más complicada que me gustaría escribir para resolver este problema en particular):
;WITH /* Recursive CTE */ cte AS
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue
FROM
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue = TotalDue,
rn = ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID)
FROM Sales.SalesOrderHeader
) AS x
WHERE rn = 1
UNION ALL
SELECT r.SalesOrderID, r.CustomerID, r.OrderDate, r.TotalDue,
MaxTotalDue = CASE
WHEN r.TotalDue > cte.MaxTotalDue THEN r.TotalDue
ELSE cte.MaxTotalDue
END
FROM cte
CROSS APPLY
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue,
rn = ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID)
FROM Sales.SalesOrderHeader AS h
WHERE h.CustomerID = cte.CustomerID
AND h.SalesOrderID > cte.SalesOrderID
) AS r
WHERE r.rn = 1
)
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue
FROM cte
ORDER BY CustomerID, SalesOrderID
OPTION (MAXRECURSION 0); Inmediatamente puede ver que el plan es más complejo que los dos anteriores, lo cual no es sorprendente dada la consulta más compleja:
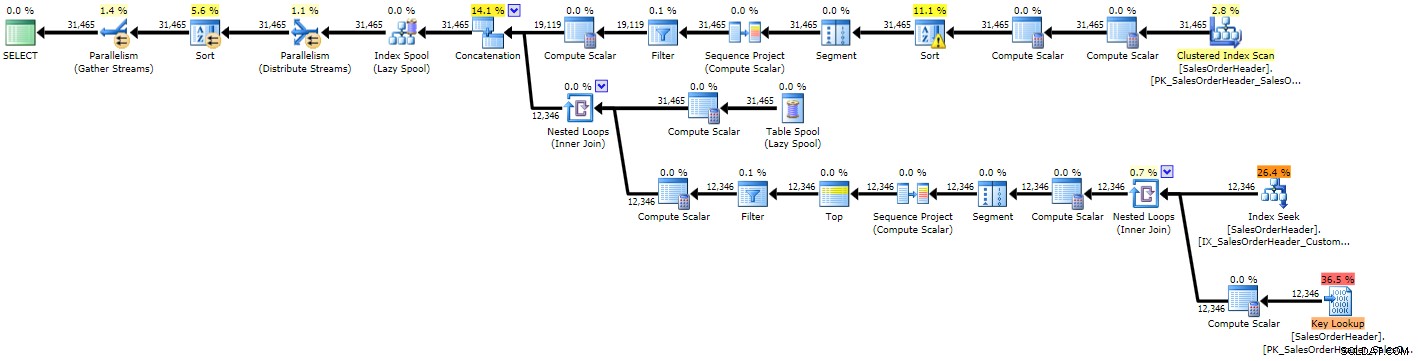 Plan de ejecución para CTE recursivo (haga clic para ampliar)
Plan de ejecución para CTE recursivo (haga clic para ampliar)
Debido a algunas malas estimaciones, vemos una búsqueda de índice con una búsqueda de clave adjunta que probablemente debería haber sido reemplazada por un solo escaneo, y también obtenemos una operación de ordenación que finalmente debe pasar a tempdb (puede ver esto en la información sobre herramientas si pasa el cursor sobre el operador de clasificación con el icono de advertencia):

MAX() SOBRE (FILAS SIN LÍMITES)
Esta es una solución que solo está disponible en SQL Server 2012 y superior, ya que utiliza extensiones recientemente introducidas para funciones de ventana.
SELECT /* MAX() OVER() */ SalesOrderID, CustomerID, OrderDate, TotalDue,
MaxTotalDue = MAX(TotalDue) OVER
(
PARTITION BY CustomerID ORDER BY SalesOrderID
ROWS UNBOUNDED PRECEDING
)
FROM Sales.SalesOrderHeader
ORDER BY CustomerID, SalesOrderID; El plan muestra exactamente por qué escala mejor que todos los demás; solo tiene una operación de escaneo de índice agrupado, a diferencia de dos (o la mala elección de un escaneo y una búsqueda + búsqueda en el caso del CTE recursivo):
 Plan de ejecución para MAX() OVER() (haga clic para ampliar)
Plan de ejecución para MAX() OVER() (haga clic para ampliar)
Comparación de rendimiento
Los planes ciertamente nos llevan a creer que el nuevo MAX() OVER() La capacidad en SQL Server 2012 es un verdadero ganador, pero ¿qué hay de las métricas de tiempo de ejecución tangibles? Así es como se compararon las ejecuciones:

Las dos primeras consultas fueron casi idénticas; mientras que en este caso el CROSS APPLY fue mejor en términos de duración general por un pequeño margen, la subconsulta correlacionada a veces lo supera un poco. El CTE recursivo es sustancialmente más lento cada vez, y puede ver los factores que contribuyen a eso, a saber, las malas estimaciones, la gran cantidad de lecturas, la búsqueda de clave y la operación de clasificación adicional. Y como he demostrado antes con los totales acumulados, la solución SQL Server 2012 es mejor en casi todos los aspectos.
Conclusión
Si está en SQL Server 2012 o superior, definitivamente querrá familiarizarse con todas las extensiones de las funciones de ventana que se introdujeron por primera vez en SQL Server 2005; es posible que le brinden mejoras de rendimiento bastante importantes al revisar el código que aún se está ejecutando. la vieja manera". Si desea obtener más información sobre algunas de estas nuevas capacidades, le recomiendo el libro de Itzik Ben-Gan, Microsoft SQL Server 2012 High-Performance T-SQL Using Window Functions.
Si aún no está en SQL Server 2012, al menos en esta prueba, puede elegir entre CROSS APPLY y la subconsulta correlacionada. Como siempre, debe probar varios métodos con los datos de su hardware.