El año pasado, presenté una solución para simular secundarios legibles de grupo de disponibilidad sin invertir en Enterprise Edition. No es para impedir que la gente compre Enterprise Edition, ya que hay muchos beneficios fuera de los AG, pero más aún para aquellos que no tienen ninguna posibilidad de tener Enterprise Edition en primer lugar:
- Secundarios legibles con un presupuesto
Intento ser un defensor incansable del cliente de la Edición estándar; es casi una broma corriente que seguramente, dada la cantidad de funciones que obtiene en cada nuevo lanzamiento, esa edición en su conjunto está en el camino de la obsolescencia. En reuniones privadas con Microsoft, presioné para que las funciones también se incluyeran en la Edición estándar, especialmente con funciones que son mucho más beneficiosas para las pequeñas empresas que aquellas con un presupuesto de hardware ilimitado.
Los clientes de Enterprise Edition disfrutan de los beneficios de capacidad de administración y rendimiento que ofrece la partición de tablas, pero esta característica no está disponible en Standard Edition. Recientemente se me ocurrió la idea de que hay una manera de lograr al menos algunas de las ventajas de la partición en cualquier edición, y no involucra vistas divididas. Esto no quiere decir que las vistas divididas no sean una opción viable que valga la pena considerar; estos están bien descritos por otros, incluidos Daniel Hutmacher (Vistas divididas sobre la partición de tablas) y Kimberly Tripp (Tablas divididas frente a Vistas divididas:¿por qué todavía existen?). Mi idea es un poco más simple de implementar.
Tu nuevo héroe:índices filtrados
Ahora, lo sé, esta característica es una palabra de cuatro letras para algunos; antes de continuar, debería estar felizmente cómodo con los índices filtrados, o al menos ser consciente de sus limitaciones. Un poco de lectura para darle un equilibrio justo antes de que intente venderlos:
- Hablo de varias deficiencias en Cómo los índices filtrados podrían ser una característica más poderosa, y señalo muchos elementos de Connect para que los vote;
- Paul White (@SQL_Kiwi) habla sobre problemas de ajuste en Limitaciones del optimizador con índices filtrados y también en Un efecto secundario inesperado de agregar un índice filtrado; y,
- Jes Borland (@grrl_geek) nos dice lo que puede (y no puede) hacer con los índices filtrados.
¿Leer todos esos? ¿Y sigues aquí? Genial.
El TL; DR de esto es que puede usar índices filtrados para mantener todos sus "datos calientes" en una estructura física separada, e incluso en hardware subyacente separado (es posible que tenga una unidad SSD o PCIe rápida disponible, pero no puede ' t sostener toda la mesa).
Un ejemplo rápido
Hay muchos casos de uso en los que una parte de los datos se consulta con mucha más frecuencia que el resto:piense en una tienda minorista que administra pedidos, una panadería que programa entregas de pasteles de boda o un estadio de fútbol que mide la asistencia y los datos de concesión. En estos casos, la mayor parte o la totalidad de la actividad de consulta diaria se refiere a datos "actuales".
Mantengámoslo simple; crearemos una base de datos con una tabla de pedidos muy estrecha:
CREATE DATABASE PoorManPartition; GO USE PoorManPartition; GO CREATE TABLE dbo.Orders ( OrderID INT IDENTITY(1,1) PRIMARY KEY, OrderDate DATE NOT NULL DEFAULT SYSUTCDATETIME(), OrderTotal DECIMAL(8,2) --, ...other columns... );
Ahora, supongamos que tiene suficiente espacio en su almacenamiento rápido para guardar un mes de datos (con mucho espacio libre para tener en cuenta la estacionalidad y el crecimiento futuro). Podemos agregar un nuevo grupo de archivos y colocar un archivo de datos en el disco rápido.
ALTER DATABASE PoorManPartition ADD FILEGROUP HotData; GO ALTER DATABASE PoorManPartition ADD FILE ( Name = N'HotData', FileName = N'Z:\folder\HotData.mdf', Size = 100MB, FileGrowth = 25MB ) TO FILEGROUP HotData;
Ahora, creemos un índice filtrado en nuestro grupo de archivos HotData, donde el filtro incluye todo desde principios de noviembre de 2015, y las columnas comunes involucradas en las consultas basadas en el tiempo están en la lista clave o de inclusión:
CREATE INDEX FilteredIndex
ON dbo.Orders(OrderDate)
INCLUDE(OrderTotal)
WHERE OrderDate >= '20151101'
AND OrderDate < '20151201'
ON HotData; Podemos insertar algunas filas y verificar el plan de ejecución para asegurarnos de que las consultas cubiertas puedan, de hecho, usar el índice:
INSERT dbo.Orders(OrderDate) VALUES('20151001'),('20151103'),('20151127');
GO
SELECT index_id, rows
FROM sys.partitions
WHERE object_id = OBJECT_ID(N'dbo.Orders');
/*
Results:
index_id rows
-------- ----
1 3
2 2
*/
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151102'
AND OrderDate < '20151106'; El plan de ejecución resultante, por supuesto, usa el índice filtrado (aunque el predicado de filtro en la consulta no coincide exactamente con la definición del índice):
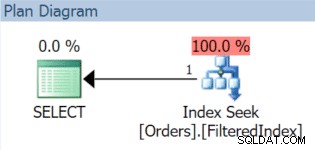
Ahora, el 1 de diciembre llega y es hora de cambiar nuestros datos de noviembre y reemplazarlos con diciembre. Simplemente podemos volver a crear el índice filtrado con un nuevo predicado de filtro y usar el DROP_EXISTING opción:
CREATE INDEX FilteredIndex
ON dbo.Orders(OrderDate)
INCLUDE(OrderTotal)
WHERE OrderDate >= '20151201'
AND OrderDate < '20160101'
WITH (DROP_EXISTING = ON)
ON HotData; Ahora, podemos agregar algunas filas más, verificar las estadísticas de partición y ejecutar nuestra consulta anterior y una nueva para verificar los índices utilizados:
INSERT dbo.Orders(OrderDate) VALUES('20151202'),('20151205');
GO
SELECT index_id, rows
FROM sys.partitions
WHERE object_id = OBJECT_ID(N'dbo.Orders');
/*
Results:
index_id rows
-------- ----
1 5
2 2
*/
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151102'
AND OrderDate < '20151106';
SELECT OrderID, OrderDate, OrderTotal
FROM dbo.Orders
WHERE OrderDate >= '20151202'
AND OrderDate < '20151204'; En este caso, obtenemos un escaneo de índice agrupado con la consulta de noviembre:
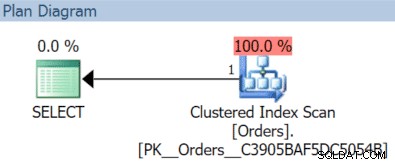
(Pero eso sería diferente si tuviéramos un índice separado no filtrado con OrderDate como clave).
Y no lo volveré a mostrar, pero con la consulta de diciembre, obtenemos la misma búsqueda de índice filtrada que antes.
También puede mantener varios índices, uno para el mes actual, uno para el mes anterior, etc., y puede administrarlos por separado (el 1 de diciembre simplemente elimina el índice de octubre y deja el de noviembre, por ejemplo) . También puede mantener múltiples índices de períodos de tiempo más cortos o más largos (semana actual y anterior, trimestre actual y anterior), etc. La solución es bastante flexible.
Debido a las limitaciones de los índices filtrados, no intentaré presentar esto como una solución perfecta, ni como un reemplazo completo para la partición de tablas o las vistas divididas. Cambiar una partición, por ejemplo, es una operación de metadatos, mientras se vuelve a crear un índice con DROP_EXISTING puede tener mucho registro (y dado que no está en Enterprise Edition, no se puede ejecutar en línea). También puede encontrar que las vistas con particiones son más su velocidad:hay más trabajo en torno al mantenimiento de tablas físicas separadas y las restricciones que hacen posible la vista con particiones, pero la recompensa en términos de rendimiento de la consulta podría ser mejor en algunos casos.
Automatización
El acto de volver a crear el índice se puede automatizar con bastante facilidad, utilizando un trabajo simple que hace algo como esto una vez al mes (o cualquiera que sea el tamaño de su ventana "caliente"):
DECLARE @sql NVARCHAR(MAX), @dt DATE = DATEADD(DAY, 1-DAY(GETDATE()), GETDATE()); SET @sql = N'CREATE INDEX FilteredIndex ON dbo.Orders(OrderDate) INCLUDE(OrderTotal) WHERE OrderDate >= ''' + CONVERT(CHAR(8), @dt, 112) + N''' WITH (DROP_EXISTING = ON) ON HotData;'; EXEC PoorManPartition.sys.sp_executesql @sql;
También podría estar creando varios índices con meses de anticipación, de forma muy similar a la creación de particiones futuras por adelantado; después de todo, los índices futuros no ocuparán ningún espacio hasta que haya datos relevantes para sus predicados. Y puede eliminar los índices que estaban segmentando los datos más antiguos que ahora desea que se enfríen.
Retrospectiva
Después de terminar este artículo, por supuesto, me encontré con otra de las publicaciones de Kimberly Tripp, que deberías leer antes de continuar con lo que estoy defendiendo aquí (y que había leído antes de comenzar):
- ¿Qué hay de los índices filtrados en lugar de la partición?
Por múltiples razones, Kimberly está mucho más a favor de las vistas con particiones para implementar algo similar a las particiones en la Edición estándar; sin embargo, para ciertos escenarios, el uso de índices filtrados todavía me intriga lo suficiente como para continuar con mi experimentación. Una de las áreas en las que los índices filtrados pueden ser beneficiosos es cuando sus datos "calientes" tienen múltiples criterios, no solo divididos por fecha, sino también por otros atributos (tal vez desee consultas rápidas en todos los pedidos de este mes que son para un nivel específico de cliente o por encima de cierta cantidad en dólares).
A continuación...
En una publicación futura, jugaré con este concepto en un sistema de gama alta, con algo de volumen y carga de trabajo del mundo real. Quiero descubrir las diferencias de rendimiento entre esta solución, un índice de cobertura no filtrado, una vista particionada y una tabla particionada. Dentro de una máquina virtual en una computadora portátil con solo SSD disponibles probablemente no produciría pruebas realistas o justas a escala.