La forma más rápida de calcular una mediana utiliza SQL Server 2012 OFFSET extensión al ORDER BY cláusula. En segundo lugar, la siguiente solución más rápida utiliza un cursor dinámico (posiblemente anidado) que funciona en todas las versiones. Este artículo analiza un ROW_NUMBER común anterior a 2012 solución al problema de cálculo de la mediana para ver por qué funciona peor y qué se puede hacer para que vaya más rápido.
Prueba de mediana única
Los datos de muestra para esta prueba consisten en una sola tabla de diez millones de filas (reproducida del artículo original de Aaron Bertrand):
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); La solución COMPENSACIÓN
Para establecer el punto de referencia, aquí está la solución OFFSET de SQL Server 2012 (o posterior) creada por Peter Larsson:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - (@Count % 2)) ROWS ONLY
) AS SQ1;
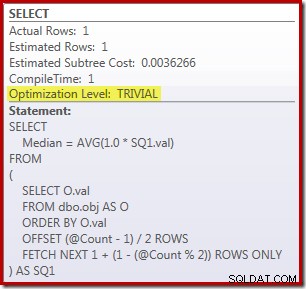
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); La consulta para contar las filas de la tabla se comenta y se reemplaza con un valor codificado para concentrarse en el rendimiento del código principal. Con una caché activa y una recopilación de planes de ejecución desactivada, esta consulta se ejecuta durante 910 ms. en promedio en mi máquina de prueba. El plan de ejecución se muestra a continuación:

Como nota al margen, es interesante que esta consulta moderadamente compleja califique para un plan trivial:
La solución ROW_NUMBER
Para los sistemas que ejecutan SQL Server 2008 R2 o anterior, la mejor solución de las alternativas utiliza un cursor dinámico como se mencionó anteriormente. Si no puede (o no quiere) considerar eso como una opción, es natural pensar en emular el OFFSET de 2012 plan de ejecución usando ROW_NUMBER .
La idea básica es numerar las filas en el orden apropiado, luego filtrar solo una o dos filas necesarias para calcular la mediana. Hay varias formas de escribir esto en Transact SQL; una versión compacta que captura todos los elementos clave es la siguiente:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
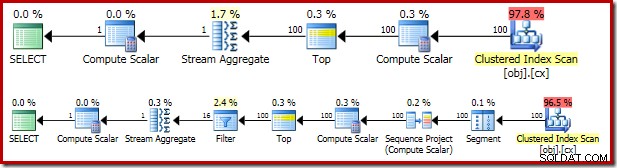
El plan de ejecución resultante es bastante similar al OFFSET versión:

Vale la pena mirar a cada uno de los operadores del plan para comprenderlos completamente:
- El operador de segmento es redundante en este plan. Sería necesario si el
ROW_NUMBERla función de clasificación tenía unaPARTITION BYcláusula, pero no lo hace. Aun así, se mantiene en el plan final. - El proyecto de secuencia agrega un número de fila calculado a la secuencia de filas.
- El Compute Scalar define una expresión asociada con la necesidad de convertir implícitamente el
valcolumna a numérico para que pueda multiplicarse por la constante literal1.0en la consulta Este cálculo se pospone hasta que lo necesite un operador posterior (que resulta ser Stream Aggregate). Esta optimización del tiempo de ejecución significa que la conversión implícita solo se realiza para las dos filas procesadas por Stream Aggregate, no las 5 000 001 filas indicadas para Compute Scalar. - El operador superior es introducido por el optimizador de consultas. Reconoce que, como máximo, solo el primer
(@Count + 2) / 2la consulta necesita filas. Podríamos haber agregado unTOP ... ORDER BYen la subconsulta para hacer esto explícito, pero esta optimización lo hace en gran medida innecesario. - El filtro implementa la condición en
WHEREcláusula, filtrando todas menos las dos filas 'centrales' necesarias para calcular la mediana (el Top introducido también se basa en esta condición). - El Stream Aggregate calcula el
SUMyCOUNTde las dos filas medianas. - El cálculo escalar final calcula el promedio a partir de la suma y el conteo.
Rendimiento bruto
Comparado con el OFFSET plan, podemos esperar que los operadores adicionales de segmento, proyecto de secuencia y filtro tengan algún efecto adverso en el rendimiento. Vale la pena tomarse un momento para comparar el estimado costos de los dos planes:
El OFFSET plan tiene un costo estimado de 0.0036266 unidades, mientras que el ROW_NUMBER el plan se estima en 0.0036744 unidades. Estos son números muy pequeños y hay poca diferencia entre los dos.
Entonces, tal vez sea sorprendente que el ROW_NUMBER la consulta realmente se ejecuta durante 4000 ms de media, en comparación con 910 ms promedio para el OFFSET solución. Parte de este aumento seguramente puede explicarse por los gastos generales de los operadores del plan adicional, pero un factor de cuatro parece excesivo. Debe haber algo más.
Probablemente también haya notado que las estimaciones de cardinalidad para los dos planes estimados anteriores son bastante incorrectas. Esto se debe al efecto de los operadores Top, que tienen una expresión que hace referencia a una variable como límite de recuento de filas. El optimizador de consultas no puede ver el contenido de las variables en el momento de la compilación, por lo que recurre a su estimación predeterminada de 100 filas. Ambos planes en realidad encuentran 5,000,001 filas en tiempo de ejecución.
Todo esto es muy interesante, pero no explica directamente por qué ROW_NUMBER la consulta es más de cuatro veces más lenta que OFFSET versión. Después de todo, la estimación de cardinalidad de 100 filas es igual de incorrecta en ambos casos.
Mejorar el rendimiento de la solución ROW_NUMBER
En mi artículo anterior, vimos cómo el rendimiento de la mediana agrupada OFFSET la prueba podría casi duplicarse simplemente agregando un PAGLOCK insinuación. Esta sugerencia anula la decisión normal del motor de almacenamiento de adquirir y liberar bloqueos compartidos en la granularidad de la fila (debido a la baja cardinalidad esperada).
Como recordatorio adicional, el PAGLOCK la sugerencia era innecesaria en la mediana única OFFSET prueba debido a una optimización interna separada que puede omitir los bloqueos compartidos a nivel de fila, lo que da como resultado que solo se tome una pequeña cantidad de bloqueos compartidos por intención a nivel de página.
Podríamos esperar el ROW_NUMBER solución mediana única para beneficiarse de la misma optimización interna, pero no lo hace. Supervisión de la actividad de bloqueo mientras ROW_NUMBER la consulta se ejecuta, vemos más de medio millón de bloqueos compartidos de nivel de fila individual siendo tomado y liberado.
Entonces, ahora que sabemos cuál es el problema, podemos mejorar el rendimiento de bloqueo de la misma manera que lo hicimos anteriormente:ya sea con un PAGLOCK sugerencia de granularidad de bloqueo, o aumentando la estimación de cardinalidad utilizando el indicador de seguimiento documentado 4138.
Deshabilitar el "objetivo de fila" mediante el indicador de seguimiento es la solución menos satisfactoria por varios motivos. Primero, solo es efectivo en SQL Server 2008 R2 o posterior. Lo más probable es que prefiramos el OFFSET solución en SQL Server 2012, por lo que esto limita efectivamente la corrección del indicador de seguimiento solo a SQL Server 2008 R2. En segundo lugar, la aplicación de la marca de seguimiento requiere permisos de nivel de administrador, a menos que se aplique a través de una guía del plan. Una tercera razón es que deshabilitar los objetivos de fila para toda la consulta puede tener otros efectos no deseados, especialmente en planes más complejos.
Por el contrario, el PAGLOCK La sugerencia es eficaz, está disponible en todas las versiones de SQL Server sin ningún permiso especial y no tiene efectos secundarios importantes más allá de la granularidad de bloqueo.
Aplicando el PAGLOCK sugerencia para el ROW_NUMBER la consulta aumenta drásticamente el rendimiento:desde 4000 ms a 1500 ms:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK) -- New!
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Los 1500ms el resultado sigue siendo significativamente más lento que los 910 ms para el OFFSET solución, pero al menos ahora está en el mismo estadio. La diferencia de rendimiento restante se debe simplemente al trabajo adicional en el plan de ejecución:

En el OFFSET plan, se procesan cinco millones de filas hasta el Top (con las expresiones definidas en Compute Scalar diferidas como se discutió anteriormente). En el ROW_NUMBER plan, el segmento, el proyecto de secuencia, la parte superior y el filtro deben procesar la misma cantidad de filas.



