Cuando un plan de ejecución incluye un escaneo de una estructura de índice de árbol b, el motor de almacenamiento puede poder elegir entre dos estrategias de acceso físico cuando se ejecuta el plan:
- Siga la estructura de árbol b del índice; o,
- ubique páginas usando información interna de asignación de páginas.
Cuando hay una opción disponible, el motor de almacenamiento toma la decisión de tiempo de ejecución en cada ejecución. Una recopilación de planes no necesario para que cambie de opinión.
La estrategia del árbol b comienza en la raíz del árbol, desciende hasta un borde extremo del nivel de la hoja (dependiendo de si el escaneo es hacia adelante o hacia atrás), luego sigue los enlaces de la página del nivel de la hoja hasta llegar al otro extremo del índice. . La estrategia de asignación utiliza estructuras de mapa de asignación de índices (IAM) para ubicar las páginas de la base de datos asignadas al índice. Cada página de IAM asigna asignaciones a un intervalo de 4 GB en un solo archivo de base de datos físico, por lo que escanear las cadenas de IAM asociadas con un índice tiende a acceder a las páginas de índice en el orden del archivo físico (al menos hasta donde SQL Server puede decir).
Las principales diferencias entre las dos estrategias son:
- Un escaneo de árbol b puede entregar filas al procesador de consultas en orden de clave de índice; un análisis controlado por IAM no puede;
- Es posible que un análisis de árbol b no pueda emitir solicitudes de E/S de lectura anticipada grandes si las páginas de índice lógicamente contiguas no son también físicamente contiguas (por ejemplo, como resultado de la división de páginas en el índice).
Un escaneo de árbol B siempre está disponible para un índice. Las condiciones citadas a menudo para que los escaneos de órdenes de asignación estén disponibles son:
- El plan de consulta debe permitir un escaneo desordenado del índice;
- el índice debe tener al menos 64 páginas; y,
- ya sea un
TABLOCKoNOLOCKse debe especificar la pista.
La primera condición simplemente significa que el optimizador de consultas debe haber marcado el escaneo con Ordered:False propiedad. Marcando el escaneo Ordered:False significa que los resultados correctos del plan de ejecución no requieren el escaneo para devolver filas en orden de clave de índice (aunque puede hacerlo si es conveniente o necesario).
La segunda condición (tamaño) se aplica solo a SQL Server 2005 y versiones posteriores. Refleja el hecho de que existe un cierto costo inicial para realizar un escaneo basado en IAM, por lo que debe haber una cantidad mínima de páginas para que los ahorros potenciales reembolsen la inversión inicial. Las "64 páginas" se refieren al valor de data_pages para el IN_ROW_DATA solo unidad de asignación, como se informa en sys.allocation_units.
Por supuesto, solo puede haber una recompensa de un escaneo de orden de asignación si las consideraciones de lectura anticipada posiblemente más grandes realmente entran en juego, pero SQL Server actualmente no considera este factor. En particular, no tiene en cuenta la cantidad del índice que se encuentra actualmente en la memoria, ni le importa cuán fragmentado esté el índice.
La tercera condición es probablemente la descripción menos completa de la lista. De hecho, las sugerencias no son obligatorias , aunque pueden usarse para cumplir con los requisitos reales:los datos deben estar garantizados de no cambiar durante el escaneo, o (más controvertido) debemos indicar que no nos importa sobre resultados potencialmente inexactos, realizando el análisis en el nivel de aislamiento de lectura no confirmada.
Incluso con estas aclaraciones, la lista de condiciones para un escaneo ordenado por asignación aún no está completa. Hay una serie de advertencias y excepciones importantes, a las que nos referiremos en breve.
Demostración
La siguiente consulta utiliza la base de datos de ejemplo AdventureWorks:
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P; Tenga en cuenta que la tabla Person contiene 3869 páginas. El plan posterior a la ejecución (real) es el siguiente (se muestra en SQL Sentry Plan Explorer):
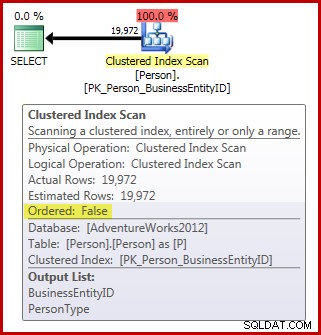
En cuanto a los requisitos de escaneo del orden de asignación, tenemos hasta ahora:
- El plan tiene el
Ordered:Falserequerido propiedad; y, - la tabla tiene más de 64 páginas; pero,
- no hemos hecho nada para garantizar que los datos no cambien durante el análisis. Asumiendo que nuestra sesión está usando la lectura confirmada predeterminada nivel de aislamiento, el análisis no se realiza en el lectura no confirmada nivel de aislamiento tampoco.
Como consecuencia, esperaríamos que este escaneo se realice escaneando el árbol b en lugar de estar controlado por IAM. Los resultados de la consulta indican que es probable que esto sea cierto:
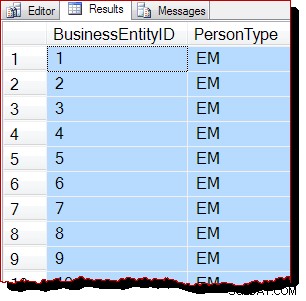
Las filas se devuelven en orden de clave de índice agrupado (por BusinessEntityID ). Debo dejar claro que este orden de resultados no está garantizado en absoluto , y no se debe confiar en él. Los resultados ordenados solo están garantizados por un ORDER BY de nivel superior adecuado cláusula.
Sin embargo, el orden de salida observado es evidencia circunstancial de que el escaneo se realizó esta vez siguiendo la estructura de árbol b del índice agrupado. Si se necesita más evidencia, podemos adjuntar un depurador y mirar la ruta del código que SQL Server está ejecutando durante el escaneo:

La pila de llamadas muestra claramente el escaneo siguiendo el árbol b.
Agregar una sugerencia de bloqueo de tabla
Ahora modificamos la consulta para incluir una sugerencia de bloqueo de tabla:
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK); En el nivel de aislamiento confirmado de lectura de bloqueo predeterminado, el bloqueo de nivel de tabla compartida evita cualquier posible modificación simultánea de los datos. Una vez cumplidas las tres condiciones previas para los análisis controlados por IAM, ahora esperaríamos que SQL Server utilice un análisis de orden de asignación. El plan de ejecución es el mismo que antes, así que no lo repetiré, pero los resultados de la consulta ciertamente se ven diferentes:
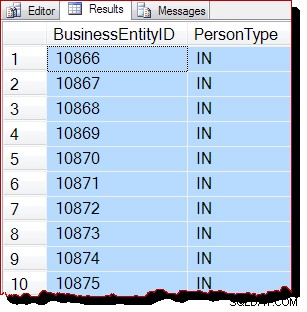
Aparentemente, los resultados todavía están ordenados por BusinessEntityID , pero el punto de partida (10866) es diferente. De hecho, si nos desplazamos hacia abajo en los resultados, pronto encontramos secciones que están más obviamente fuera de orden clave:
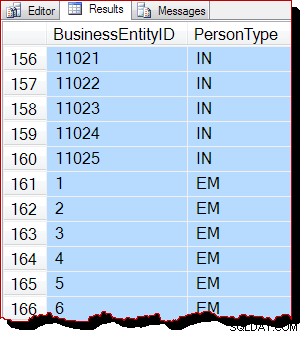
La ordenación parcial se debe a que el escaneo de orden de asignación procesa una página de índice completa a la vez. Los resultados dentro de una página aparecen ordenados por la clave de índice, pero el orden de las páginas escaneadas ahora es diferente. Nuevamente, debo enfatizar que los resultados pueden verse diferentes para usted:no hay garantía de orden de salida, incluso dentro de una página, sin un ORDER BY de nivel superior en la consulta original.
Para comparar con la pila de llamadas que se mostró anteriormente, este es un seguimiento de la pila obtenido mientras SQL Server procesaba la consulta con TABLOCK pista:
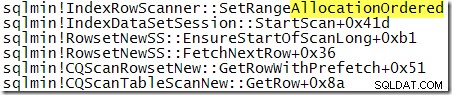
Pisando un poco más a través de la ejecución:

Claramente, SQL Server realiza un análisis ordenado por asignación cuando se especifica el bloqueo de la tabla. Es una pena que no haya ninguna indicación en un plan posterior a la ejecución de qué tipo de análisis se utilizó en el tiempo de ejecución. Como recordatorio, el motor de almacenamiento elige el tipo de escaneo y puede cambiar entre ejecuciones sin una recompilación del plan.
Otras formas de cumplir la tercera condición
Dije antes que para obtener un escaneo controlado por IAM, debemos asegurarnos de que los datos no puedan cambiar debajo del escaneo mientras está en progreso, o debemos ejecutar la consulta en el nivel de aislamiento de lectura no confirmada. Hemos visto que una sugerencia de bloqueo de tabla para bloquear el aislamiento de confirmación de lectura es suficiente para cumplir con el primero de esos requisitos, y es fácil demostrar que usar un NOLOCK/READUNCOMMITTED sugerencia también habilita un escaneo de orden de asignación con la consulta de demostración.
De hecho, hay muchas formas de cumplir con la tercera condición, que incluyen:
- Alterar el índice para permitir solo bloqueos de tablas;
- hacer que la base de datos sea de solo lectura (para garantizar que los datos no cambien); o,
- cambiar la sesión nivel de aislamiento a
READ UNCOMMITTED.
Sin embargo, existen variaciones mucho más interesantes sobre este tema que significan que debemos modificar las tres condiciones establecidas anteriormente...
Niveles de aislamiento de versiones de fila
Habilite el aislamiento de instantáneas confirmadas de lectura (RCSI) en la base de datos AdventureWorks y ejecute la prueba con TABLOCK sugerencia de nuevo (al leer el aislamiento confirmado):
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT ON
WITH ROLLBACK IMMEDIATE;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
GO
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK);
GO
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT OFF
WITH ROLLBACK IMMEDIATE;
Con RCSI activo, un ordenado por índice el escaneo se usa con TABLOCK , no el escaneo de orden de asignación que vimos antes. El motivo es el TABLOCK sugerencia especifica un bloqueo compartido a nivel de tabla, pero con RCSI habilitado, sin bloqueos compartidos están tomados. Sin el bloqueo de tabla compartida, no hemos cumplido con el requisito de evitar modificaciones simultáneas a los datos mientras el análisis está en curso, por lo que no se puede utilizar un análisis ordenado por asignación.
Sin embargo, es posible lograr un escaneo ordenado por asignación cuando RCSI está habilitado. Una forma es usar un TABLOCKX sugerencia (para un nivel de tabla exclusivo lock) en lugar de TABLOCK . También podríamos conservar el TABLOCK pista y agregue otra como READCOMMITTEDLOCK , o REPEATABLE READ o SERIALIZABLE … y así. Todos estos funcionan evitando la posibilidad de modificaciones concurrentes al tomar un bloqueo de tabla compartido, a costa de perder los beneficios de RCSI . También podemos lograr un escaneo de orden de asignación usando un NOLOCK o READUNCOMMITTED pista, por supuesto.
La situación bajo el aislamiento de instantáneas (SI) es muy similar a RCSI y no se explora en detalle por razones de espacio.
TABLESAMPLE siempre* realiza un escaneo de orden de asignación
El TABLESAMPLE cláusula es una excepción interesante a muchas de las cosas que hemos discutido hasta ahora.
Especificando un TABLESAMPLE La cláusula always* da como resultado un escaneo de orden de asignación, incluso bajo RCSI o SI, e incluso sin sugerencias. Para que quede claro, el análisis del orden de asignación que resulta del uso de TABLESAMPLE conserva la semántica RCSI/SI:el escaneo usa versiones de fila y la lectura no bloquea la escritura (y viceversa).
Una segunda sorpresa es que TABLESAMPLE always* realiza un análisis controlado por IAM incluso si la tabla tiene menos de 64 páginas . Esto tiene sentido porque la documentación al menos sugiere que el SYSTEM El método de muestreo utiliza la estructura IAM (por lo que no hay más remedio que hacer un escaneo de orden de asignación):
SISTEMA Es un método de muestreo dependiente de la implementación especificado por las normas ISO. En SQL Server, este es el único método de muestreo disponible y se aplica de forma predeterminada. SYSTEM aplica un método de muestreo basado en páginas en el que se elige un conjunto aleatorio de páginas de la tabla para la muestra y todas las filas de esas páginas se devuelven como el subconjunto de muestra.
* Se produce una excepción si ROWS o PERCENT especificación en TABLESAMPLE la cláusula significa el 100% de la tabla. Especificando más ROWS de lo que indican los metadatos que están actualmente en la tabla tampoco funcionará. Usando TABLESAMPLE SYSTEM (100 PERCENT) o equivalente no forzar un escaneo de orden de asignación.
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
TABLESAMPLE SYSTEM (50 ROWS)
REPEATABLE (12345678)
--WITH (TABLOCK); Resultados:
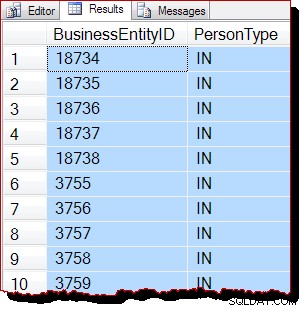
El efecto de TOP y SET ROWCOUNT
En resumen, ninguno de estos tiene ningún efecto sobre la decisión de utilizar o no un escaneo de orden de asignación. Esto puede parecer sorprendente en casos en los que es "obvio" que se escanearán menos de 64 páginas.
Por ejemplo, las siguientes consultas utilizan un análisis controlado por IAM para devolver 5 filas de un análisis:
SELECT TOP (5)
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 5;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 0; Los resultados son los mismos para ambos:
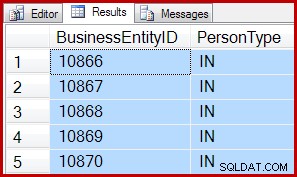
Esto significa que TOP y SET ROWCOUNT consultas podrían incurrir en la sobrecarga de configurar un escaneo de orden de asignación, incluso si se escanean menos de 64 páginas. Como mitigación, las consultas TOP más complejas con predicados selectivos insertados en el escaneo aún podrían beneficiarse de un escaneo de orden de asignación. Si el escaneo debe procesar 10 000 páginas para encontrar las primeras 5 filas que coincidan, un escaneo por orden de asignación aún podría ser una victoria.
Evitar todos* los escaneos en orden de asignación en toda la instancia
Esto no es algo que probablemente haría intencionalmente, pero hay una configuración de servidor que evitará los escaneos de orden de asignación para todas las consultas de usuarios en todas las bases de datos.
Por improbable que parezca, la configuración en cuestión es la opción de configuración del servidor de umbral de cursor, que tiene la siguiente descripción en Books Online:
La opción de umbral de cursor especifica el número de filas en el conjunto de cursores en las que los conjuntos de claves de cursor se generan de forma asíncrona. Cuando los cursores generan un conjunto de claves para un conjunto de resultados, el optimizador de consultas estima el número de filas que se devolverán para ese conjunto de resultados. Si el optimizador de consultas estima que el número de filas devueltas es mayor que este umbral, el cursor se genera de forma asíncrona, lo que permite al usuario obtener filas del cursor mientras el cursor continúa llenándose. De lo contrario, el cursor se genera sincrónicamente y la consulta espera hasta que se devuelven todas las filas.
Si el cursor threshold está establecida en cualquier otra cosa que no sea –1 (el valor predeterminado), no se realizarán análisis de orden de asignación para las consultas de los usuarios en ninguna base de datos en la instancia de SQL Server.
En otras palabras, si la población de cursores asincrónicos está habilitada, no se realizarán análisis controlados por IAM.
* La excepción es (no 100%) TABLESAMPLE consultas Las consultas internas generadas por el sistema para la creación de estadísticas y las actualizaciones de estadísticas también continúan utilizando escaneos ordenados por asignación.
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
-- WARNING! Disables allocation-order scans instance-wide
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = 5000;
RECONFIGURE WITH OVERRIDE;
GO
-- Would normally result in an allocation-order scan
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (READUNCOMMITTED);
GO
-- Reset to default allocation-order scans
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = -1;
RECONFIGURE WITH OVERRIDE; Resultados (sin escaneo de orden de asignación):
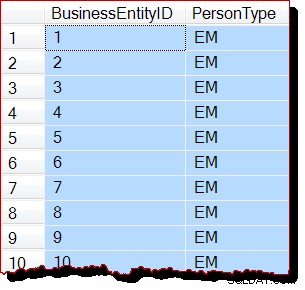
Uno solo puede suponer que la población de cursores asíncronos no funciona bien con escaneos de orden de asignación por alguna razón. Es totalmente inesperado que esta restricción afecte a todas las consultas de usuarios que no utilizan cursor. aunque también ¿Quizás es demasiado difícil para SQL Server detectar si una consulta se está ejecutando como parte de un cursor API emitido externamente? Quién sabe.
Sería bueno si este efecto secundario se documentara oficialmente en alguna parte, aunque es difícil saber exactamente dónde debería ir en los Libros en línea. Me pregunto cuántos sistemas de producción no utilizan escaneos de orden de asignación debido a esto. Tal vez no muchos, pero nunca se sabe.
Para terminar, aquí hay un resumen. Un escaneo ordenado por asignación está disponible si:
- La opción de servidor
cursor thresholdse establece en –1 (el valor predeterminado); y, - el operador de exploración del plan de consulta tiene el
Ordered:Falsepropiedad; y, - las páginas_de_datos totales del
IN_ROW_DATAunidades de asignación es al menos 64; y, - ya sea:
- SQL Server tiene una garantía aceptable de que las modificaciones simultáneas son imposibles; o,
- el análisis se ejecuta en el nivel de aislamiento de lectura no confirmada.
Independientemente de todo lo anterior, un escaneo con un TABLESAMPLE La cláusula siempre usa exploraciones ordenadas por asignación (con la única excepción técnica que se indica en el texto principal).