Ser responsable del rendimiento de SQL Server puede ser una tarea abrumadora. Hay muchas áreas que tenemos que monitorear y comprender. También se espera que podamos estar al tanto de todas esas métricas y saber qué sucede en nuestros servidores en todo momento. Me gusta preguntar a los administradores de bases de datos qué es lo primero que piensan cuando escuchan la frase "ajustar SQL Server"; la respuesta abrumadora que recibo es "ajuste de consulta". Estoy de acuerdo en que ajustar las consultas es muy importante y es una tarea interminable a la que nos enfrentamos porque las cargas de trabajo cambian continuamente.
Sin embargo, hay muchos otros aspectos a considerar cuando se piensa en el rendimiento de SQL Server. Hay muchas configuraciones a nivel de instancia, sistema operativo y base de datos que deben modificarse a partir de los valores predeterminados. Ser consultor me permite trabajar en muchas líneas de negocios diferentes y exponerme a todo tipo de problemas de rendimiento. Cuando trabajo con un nuevo cliente, trato de realizar siempre una auditoría de salud del servidor para saber con qué estoy tratando. Al realizar estas auditorías, una de las cosas que he encontrado repetidamente ha sido latencias de lectura y escritura excesivas en los discos donde residen los datos y los archivos de registro de SQL Server.
Latencia de lectura/escritura
Para ver las latencias de su disco en SQL Server, puede consultar rápida y fácilmente el DMV sys.dm_io_virtual_file_stats . Este DMV acepta dos parámetros:database_id y file_id . Lo asombroso es que puedes pasar NULL como ambos valores y devolver las latencias para todos los archivos para todas las bases de datos. Las columnas de salida incluyen:
- id_base_de_datos
- id_archivo
- muestra_ms
- num_of_reads
- num_of_bytes_read
- io_stall_read_ms
- num_of_writes
- num_of_bytes_escritos
- io_stall_write_ms
- io_stall
- tamaño_en_disk_bytes
- identificador_de_archivo
Como puede ver en la lista de columnas, hay información realmente útil que recupera este DMV, sin embargo, basta con ejecutar SELECT * FROM sys.dm_io_virtual_file_stats(NULL, NULL); no ayuda mucho a menos que hayas memorizado tu base de datos_ids y puedas hacer algunos cálculos mentalmente.
Cuando consulto las estadísticas del archivo, utilizo una consulta de la publicación de blog de Paul Randal, "Cómo examinar las latencias del subsistema IO desde SQL Server". Este script hace que los nombres de las columnas sean más fáciles de leer, incluye la unidad en la que se encuentra el archivo, el nombre de la base de datos y la ruta al archivo.
Al consultar este DMV, puede saber fácilmente dónde están los puntos calientes de E/S para sus archivos. Puede ver dónde están las latencias de escritura y lectura más altas y qué bases de datos son las culpables. Saber esto le permitirá comenzar a buscar oportunidades de ajuste para esas bases de datos específicas. Esto podría incluir el ajuste del índice, verificar si el grupo de búfer está bajo presión de memoria, posiblemente mover la base de datos a una parte más rápida del subsistema de E/S o posiblemente particionar la base de datos y distribuir los grupos de archivos entre otros LUN.
Así que ejecuta la consulta y devuelve muchos valores en ms para la latencia:¿qué valores están bien y cuáles son malos?
¿Qué valores son buenos o malos?
Si pregunta a SQLskills, le diremos algo como:
- Excelente:<1ms
- Muy bien:<5ms
- Bueno:5 - 10ms
- Pobre:10 - 20ms
- Malo:20 - 100ms
- Muy malo:100 – 500ms
- ¡Dios mío!:> 500 ms
Si realiza una búsqueda en Bing, encontrará artículos de Microsoft con recomendaciones similares a:
- Bien:<10ms
- Bien:10 - 20ms
- Malo:20 – 50ms
- Muy malo:> 50ms
Como puede ver, hay algunas ligeras variaciones en los números, pero el consenso es que cualquier valor superior a 20 ms puede considerarse problemático. Dicho esto, su latencia de escritura promedio puede ser de 20 ms y eso es 100% aceptable para su organización y está bien. Necesita conocer las latencias de E/S generales de su sistema para que, cuando las cosas se pongan mal, sepa lo que es normal.
Mis latencias de lectura/escritura son malas, ¿qué debo hacer?
Si encuentra que las latencias de lectura y escritura son malas en su servidor, hay varios lugares donde puede comenzar a buscar problemas. Esta no es una lista exhaustiva, sino una guía de por dónde empezar.
- Analice su carga de trabajo. ¿Es correcta su estrategia de indexación? No tener los índices adecuados hará que se lean muchos más datos del disco. Exploraciones en lugar de búsquedas.
- ¿Están actualizadas sus estadísticas? Las malas estadísticas pueden generar malas decisiones para los planes de ejecución.
- ¿Tiene problemas de rastreo de parámetros que están causando planes de ejecución deficientes?
- ¿Está el grupo de búferes bajo presión de memoria, por ejemplo, debido a un caché de plan inflado?
- ¿Algún problema con la red? ¿Está funcionando correctamente su tejido SAN? Pida a su ingeniero de almacenamiento que valide la ruta y la red.
- Mueva los puntos calientes a diferentes arreglos de almacenamiento. En algunos casos, puede ser una sola base de datos o solo unas pocas bases de datos las que causan todos los problemas. Aislarlos en un conjunto diferente de disco o en un disco de gama alta más rápido, como SSD, puede ser la mejor solución lógica.
- ¿Puede particionar la base de datos para mover las tablas problemáticas a un disco diferente para distribuir la carga?
Estadísticas de espera
Al igual que monitorear las estadísticas de sus archivos, monitorear sus estadísticas de espera puede brindarle mucha información sobre los cuellos de botella en su entorno. Tenemos la suerte de tener otro DMV increíble (sys.dm_os_wait_stats ) que podemos consultar que extraerá toda la información de espera disponible recopilada desde el último reinicio o desde la última vez que se reiniciaron las esperas; también hay esperas relacionadas con el rendimiento del disco. Este DMV devolverá información importante que incluye:
- tipo_espera
- recuento_de_tareas_en_espera
- tiempo_de_espera_ms
- max_wait_time_ms
- señal_espera_tiempo_ms
Consultar este DMV en mi máquina SQL Server 2014 devolvió 771 tipos de espera. SQL Server siempre está esperando algo, pero hay muchas esperas de las que no deberíamos preocuparnos. Por esta razón, utilizo otra consulta de Paul Randal; su publicación de blog, "Estadísticas de espera, o por favor dime dónde duele", tiene un guión excelente que excluye un montón de esperas que realmente no nos importan. Paul también enumera muchas de las esperas problemáticas comunes y ofrece orientación para las esperas comunes.
¿Por qué son importantes las estadísticas de espera?
El monitoreo de tiempos de espera altos para ciertos eventos le indicará cuándo hay problemas. Necesita una línea de base para saber qué es normal y cuándo las cosas superan un umbral o nivel de dolor. Si tienes un PAGEIOLATCH_XX muy alto entonces sabe que SQL Server tiene que esperar a que se lea una página de datos del disco. Esto podría ser disco, memoria, cambio de carga de trabajo o una serie de otros problemas.
Un cliente reciente con el que estaba trabajando estaba viendo un comportamiento muy inusual. Cuando me conecté al servidor de la base de datos y pude observar el servidor bajo una carga de trabajo, inmediatamente comencé a verificar las estadísticas de los archivos, las estadísticas de espera, la utilización de la memoria, el uso de tempdb, etc. Una cosa que se destacó de inmediato fue WRITELOG siendo la espera más frecuente. Sé que esta espera tiene que ver con un vaciado de registros en el disco y me recordó la serie de Paul sobre Recortar la grasa del registro de transacciones. Alto WRITELOG las esperas generalmente se pueden identificar por latencias de escritura altas para el archivo de registro de transacciones. Entonces usé mi secuencia de comandos de estadísticas de archivos para revisar las latencias de lectura y escritura en el disco. Luego pude ver una alta latencia de escritura en el archivo de datos, pero no en mi archivo de registro. Al mirar el WRITELOG fue una espera alta pero el tiempo de espera en ms fue extremadamente bajo. Sin embargo, algo en la segunda publicación de la serie de Paul todavía estaba en mi cabeza. Debería mirar la configuración de crecimiento automático para la base de datos solo para descartar "Muerte por mil cortes". Al observar las propiedades de la base de datos, vi que el archivo de datos estaba configurado para crecer automáticamente en 1 MB y el registro de transacciones estaba configurado para crecer automáticamente en un 10%. Ambos archivos tenían casi 0 espacios sin usar. Compartí con el cliente lo que encontré y cómo esto estaba afectando su desempeño. Rápidamente hicimos el cambio apropiado y las pruebas continuaron, mucho mejor por cierto. Lamentablemente, esta no es la única vez que me he encontrado con este problema exacto. En otra ocasión, una base de datos tenía un tamaño de 66 GB, llegó allí con un crecimiento de 1 MB.
Capturando sus datos
Muchos profesionales de datos han creado procesos para capturar archivos y esperar estadísticas de forma regular para su análisis. Dado que las estadísticas de espera son acumulativas, querrá capturarlas y comparar los deltas entre diferentes momentos del día o antes y después de que se ejecuten ciertos procesos. Esto no es demasiado complicado y hay numerosas publicaciones de blog disponibles donde las personas comparten cómo lograron esto. La parte importante es medir estos datos para poder monitorearlos. ¿Cómo sabe hoy que las cosas están mejor o peor en su servidor de base de datos a menos que conozca los datos de ayer?
¿Cómo puede ayudar SQL Sentry?
¡Me alegra que hayas preguntado! SQL Sentry Performance Advisor brinda latencia y espera al frente y al centro en el tablero. Cualquier anomalía es fácil de detectar; puede cambiar al modo histórico y ver la tendencia anterior y compararla también con períodos anteriores. Esto puede resultar invaluable al analizar esos "¿qué pasó?" momentos Todos han recibido esa llamada:"Ayer, alrededor de las 3:00 p. m., el sistema pareció congelarse, ¿puede decirnos qué sucedió?" Um, claro, déjame abrir Profiler y retroceder en el tiempo. Si tiene una herramienta de monitoreo como Performance Advisor, tendría esa información histórica al alcance de su mano.
Además de los cuadros y gráficos en el tablero, tiene la capacidad de usar alertas integradas para condiciones tales como esperas de disco altas, recuentos de VLF altos, CPU alta, expectativa de vida de página baja y muchas más. También tiene la capacidad de crear sus propias condiciones personalizadas y puede aprender de los ejemplos en el sitio de SQL Sentry o a través de Condition Exchange (Aaron Bertrand ha escrito en su blog sobre esto). Toqué el lado de las alertas de esto en mi último artículo sobre Alertas del Agente SQL Server.
En la pestaña Espacio en disco de Performance Advisor, es muy fácil ver cosas como configuraciones de crecimiento automático y conteos altos de VLF. Debería saberlo, pero en caso de que no lo sepa, el crecimiento automático de 1 MB o 10 % no es la mejor configuración. Si ve estos valores (Performance Advisor los resalta por usted), puede tomar nota rápidamente y programar el tiempo para realizar los ajustes adecuados. También me encanta cómo muestra los VLF totales; demasiados VLF pueden ser muy problemáticos. Debería leer la publicación de Kimberly "VLF de registro de transacciones:¿demasiados o demasiado pocos?" si aún no lo has hecho.
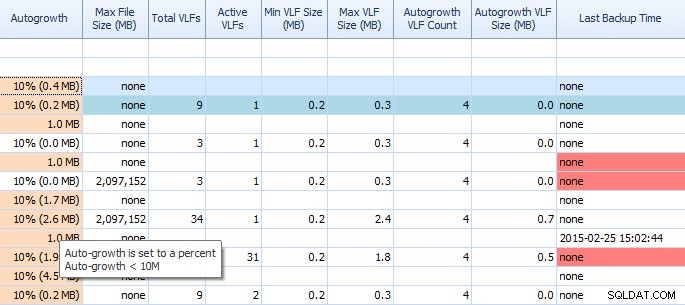 Cuadrícula parcial en la pestaña Espacio en disco de Performance Advisor
Cuadrícula parcial en la pestaña Espacio en disco de Performance Advisor
Otra forma en que Performance Advisor puede ayudar es a través de su módulo de actividad de disco patentado. Aquí puede ver que tempdb en F:está experimentando una latencia de escritura sustancial; se nota por las gruesas líneas rojas debajo de los gráficos del disco. También puede notar que F:es la única letra de unidad cuyo disco está representado en rojo; esta es una señal visual de que la unidad tiene una partición desalineada, lo que puede contribuir a problemas de E/S.
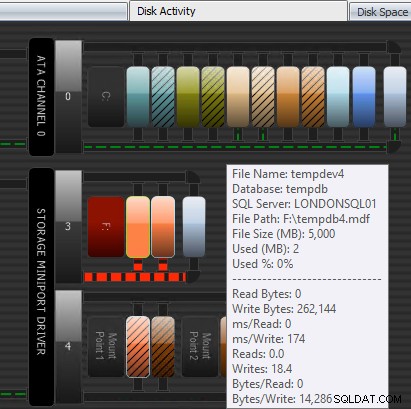 Performance Advisor Disk Activity module
Performance Advisor Disk Activity module
Y puede correlacionar esta información en las cuadrículas a continuación:los problemas también se resaltan en las cuadrículas allí, y eche un vistazo a ms/Write columna:
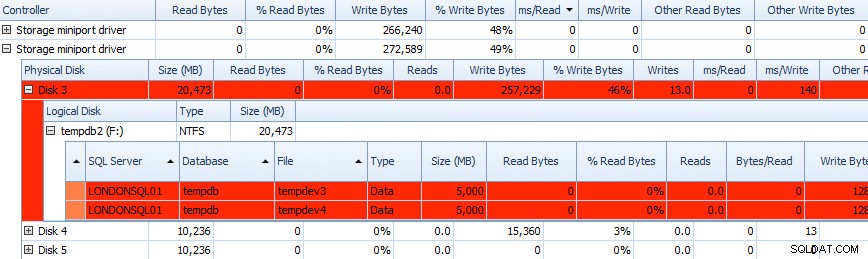 Cuadrícula parcial de datos de actividad de disco de Performance Advisor
Cuadrícula parcial de datos de actividad de disco de Performance Advisor
También puede consultar esta información de forma retroactiva; Si alguien se queja de un cuello de botella percibido en el disco ayer por la tarde o el martes pasado, simplemente puede regresar usando los selectores de fecha en la barra de herramientas y ver el rendimiento y la latencia promedio para cualquier rango. Para obtener más información sobre el módulo Actividad del disco, consulte la Guía del usuario.
Performance Advisor también tiene una gran cantidad de informes integrados en las categorías Rendimiento, Bloqueo, Top SQL, Espacio en disco/archivo y Interbloqueos. La siguiente imagen le muestra cómo llegar a los informes de espacio en disco/archivo. Tener los informes a solo unos clics del mouse es muy valioso para poder profundizar y ver de inmediato lo que está (o estaba) sucediendo en su servidor.
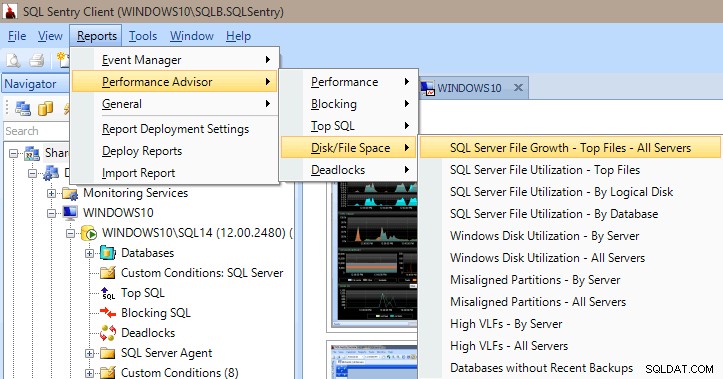 Informes del asesor de rendimiento
Informes del asesor de rendimiento
Resumen
La conclusión importante de esta publicación es conocer sus métricas de rendimiento. Una afirmación común entre los profesionales de datos es que el disco es nuestro principal cuello de botella. Conocer las estadísticas de archivos de su servidor ayudará en gran medida a comprender los puntos débiles de su servidor. Junto con las estadísticas de archivos, las estadísticas de espera también son un excelente lugar para buscar. Mucha gente, incluyéndome a mí, empieza por ahí. Tener una herramienta como SQL Sentry Performance Advisor puede ayudarlo drásticamente a solucionar y encontrar problemas de rendimiento antes de que se vuelvan demasiado problemáticos; sin embargo, si no tiene esa herramienta, familiarícese con sys.dm_os_wait_stats y sys.dm_io_virtual_file_stats te servirá bien para empezar a poner a punto tu servidor.



