Cuando los usuarios solicitan datos de un sistema, generalmente les gusta verlos en un orden específico... incluso cuando devuelven miles de filas. Como saben muchos DBA y desarrolladores, ORDER BY puede causar estragos en un plan de consulta, porque requiere que se ordenen los datos. A veces, esto puede requerir un operador SORT como parte de la ejecución de la consulta, lo que puede ser una operación costosa, especialmente si las estimaciones no están bien y se derraman en el disco. En un mundo ideal, los datos ya están ordenados gracias a un índice (los índices y las clasificaciones son muy complementarios). A menudo hablamos de crear un índice de cobertura para satisfacer una consulta, de modo que el optimizador no tenga que volver a la tabla base o al índice agrupado para obtener columnas adicionales. Y es posible que haya escuchado a la gente decir que el orden de las columnas en el índice es importante. ¿Alguna vez ha considerado cómo afecta sus operaciones SORT?
Examinando ORDEN POR y Ordenaciones
Comenzaremos con una copia nueva de la base de datos AdventureWorks2014 en una instancia de SQL Server 2014 (versión 12.0.2000). Si ejecutamos una consulta SELECT simple contra Sales.SalesOrderHeader sin ORDER BY, vemos un escaneo de índice agrupado simple y antiguo (usando SQL Sentry Plan Explorer):
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader];
 Consulta sin ORDEN POR, escaneo de índice agrupado
Consulta sin ORDEN POR, escaneo de índice agrupado
Ahora agreguemos un ORDEN POR para ver cómo cambia el plan:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID];
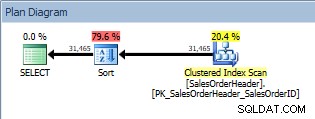 Consulta con ORDER BY, escaneo de índice agrupado y clasificación
Consulta con ORDER BY, escaneo de índice agrupado y clasificación
Además del escaneo de índice agrupado, ahora tenemos una ordenación introducida por el optimizador, y su costo estimado es significativamente mayor que el del escaneo. Ahora, el costo estimado es solo estimado, y no podemos decir con absoluta certeza que Sort se llevó el 79,6% del costo de la consulta. Para entender realmente lo caro que es Sort, también tendríamos que mirar las ESTADÍSTICAS IO, que está más allá del objetivo actual.
Ahora bien, si esta fuera una consulta que se ejecutara con frecuencia en su entorno, probablemente consideraría agregar un índice para respaldarla. En este caso, no hay cláusula WHERE, solo estamos recuperando cuatro columnas y ordenando por una de ellas. Un primer intento lógico en un índice sería:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_CustomerID_OrderDate_SubTotal] ON [Sales].[SalesOrderHeader]( [CustomerID] ASC) INCLUDE ( [OrderDate], [SubTotal]);
Volveremos a ejecutar nuestra consulta después de agregar el índice que tiene todas las columnas que queremos, y recordaremos que el índice ha hecho el trabajo de ordenar los datos. Ahora vemos un escaneo de índice contra nuestro nuevo índice no agrupado:
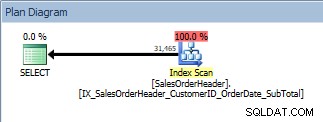 Consulta con ORDER BY, se escanea el nuevo índice no agrupado
Consulta con ORDER BY, se escanea el nuevo índice no agrupado
Estas son buenas noticias. Pero, ¿qué sucede si alguien modifica esa consulta, ya sea porque los usuarios pueden especificar por qué columnas quieren ordenar o porque un desarrollador solicitó un cambio? Por ejemplo, tal vez los usuarios deseen ver los ID de cliente y los ID de pedido de venta en orden descendente:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] DESC;
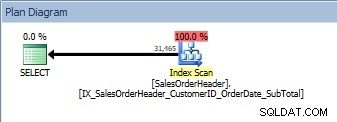 Consulta con dos columnas en ORDER BY, se escanea el nuevo índice no agrupado
Consulta con dos columnas en ORDER BY, se escanea el nuevo índice no agrupado
Tenemos el mismo plan; no se agregó ningún operador Ordenar. Si miramos el índice usando sp_helpindex de Kimberly Tripp (algunas columnas colapsaron para ahorrar espacio), podemos ver por qué el plan no cambió:
 Resultado de sp_helpindex
Resultado de sp_helpindex
La columna clave para el índice es CustomerID, pero dado que SalesOrderID es la columna clave para el índice agrupado, también forma parte de la clave del índice, por lo que los datos se ordenan por CustomerID y luego por SalesOrderID. La consulta solicitó los datos ordenados por esas dos columnas, en orden descendente. El índice se creó con ambas columnas ascendentes, pero debido a que es una lista doblemente enlazada, el índice se puede leer hacia atrás. Puede ver esto en el panel Propiedades en Management Studio para el operador de escaneo de índice no agrupado:
 Panel de propiedades del escaneo de índice no agrupado, que muestra que estaba al revés
Panel de propiedades del escaneo de índice no agrupado, que muestra que estaba al revés
Genial, no hay problema con esa consulta... pero ¿qué pasa con esta:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] ASC;
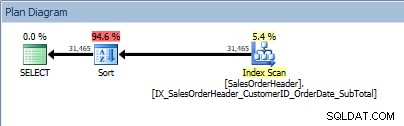 Consulta con dos columnas en ORDER BY y se agrega una clasificación
Consulta con dos columnas en ORDER BY y se agrega una clasificación
Vuelve a aparecer nuestro operador SORT, porque los datos provenientes del índice no están ordenados en el orden solicitado. Veremos el mismo comportamiento si ordenamos en una de las columnas incluidas:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] ASC, [OrderDate] ASC;
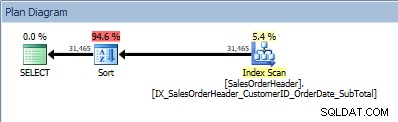 Consulta con dos columnas en ORDER BY y se agrega una clasificación
Consulta con dos columnas en ORDER BY y se agrega una clasificación
¿Qué sucede si (finalmente) agregamos un predicado y cambiamos ligeramente nuestro ORDER BY?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] = 13464 ORDER BY [SalesOrderID];
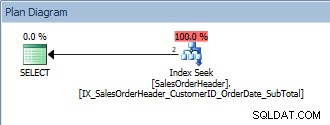 Consulta con un solo predicado y ORDEN POR
Consulta con un solo predicado y ORDEN POR
Esta consulta está bien porque, nuevamente, SalesOrderID es parte de la clave de índice. Para este CustomerID, los datos ya están ordenados por SalesOrderID. ¿Qué pasa si consultamos un rango de CustomerID, ordenados por SalesOrderID?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 13464 AND 13466 ORDER BY [SalesOrderID];
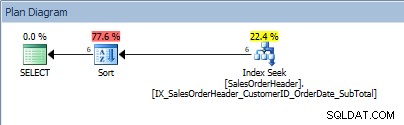 Consulta con un rango de valores en el predicado y un ORDEN POR
Consulta con un rango de valores en el predicado y un ORDEN POR
Ratas, nuestro SORT ha vuelto. El hecho de que los datos estén ordenados por CustomerID solo ayuda a buscar el índice para encontrar ese rango de valores; para ORDER BY SalesOrderID, el optimizador tiene que intercalar Sort para colocar los datos en el pedido solicitado.
Ahora, en este punto, es posible que se pregunte por qué estoy obsesionado con el operador Ordenar que aparece en los planes de consulta. Es porque es caro. Puede ser costoso en términos de recursos (memoria, IO) y/o duración.
La duración de la consulta puede verse afectada por una ordenación porque es una operación intermitente. El conjunto completo de datos debe ordenarse antes de que pueda ocurrir la siguiente operación en el plan. Si solo se tienen que ordenar unas pocas filas de datos, eso no es gran cosa. ¿Si son miles o millones de filas? Ahora estamos esperando.
Además de la duración general de la consulta, también debemos pensar en el uso de recursos. Tomemos las 31 465 filas con las que hemos estado trabajando y pasémoslas a una variable de tabla, luego ejecutemos esa consulta inicial con ORDER BY en CustomerID:
DECLARE @t TABLE (CustomerID INT, SalesOrderID INT, OrderDate DATETIME, SubTotal MONEY); INSERT @t SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader]; SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM @t ORDER BY [CustomerID];
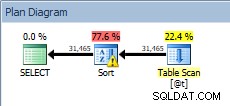 Consulta contra la variable de tabla, con orden
Consulta contra la variable de tabla, con orden
Nuestro SORT está de regreso, y esta vez tiene una advertencia (observe el triángulo amarillo con el signo de exclamación). Las advertencias no son buenas. Si observamos las Propiedades del tipo, podemos ver la advertencia "El operador usó tempdb para derramar datos durante la ejecución con el nivel de derrame 1":
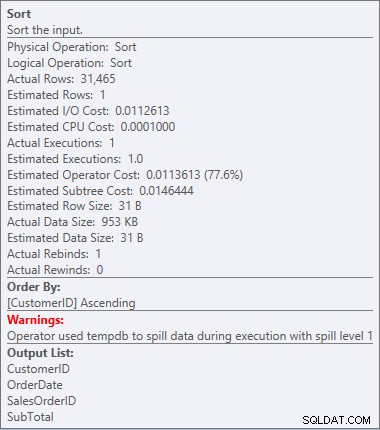 Ordenar advertencia
Ordenar advertencia
Esto no es algo que quiero ver en un plan. El optimizador hizo una estimación de cuánto espacio necesitaría en la memoria para ordenar los datos y solicitó esa memoria. Pero cuando realmente tenía todos los datos y fue a ordenarlos, el motor se dio cuenta de que no había suficiente memoria (¡el optimizador pidió muy poca!), por lo que la operación Ordenar se derramó. En algunos casos, esto puede extenderse al disco, lo que significa lecturas y escrituras, que son lentas. No solo estamos esperando para poner los datos en orden, sino que es aún más lento porque no podemos hacerlo todo en la memoria. ¿Por qué el optimizador no solicitó suficiente memoria? Tenía una mala estimación sobre los datos que necesitaba clasificar:
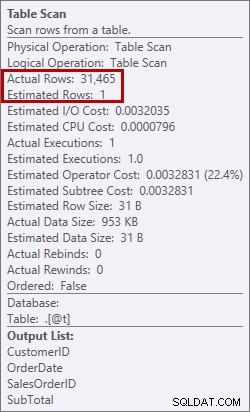 Estimación de 1 fila frente a 31 465 filas reales
Estimación de 1 fila frente a 31 465 filas reales
En este caso forcé una mala estimación usando una variable de tabla. Hay problemas conocidos con las estimaciones de estadísticas y las variables de la tabla (Aaron Bertrand tiene una excelente publicación sobre las opciones para tratar de abordar esto), y aquí, el optimizador creía que solo se devolvería 1 fila del escaneo de la tabla, no 31,465.
Opciones
Entonces, ¿qué puede hacer usted, como DBA o desarrollador, para evitar SORT en sus planes de consulta? La respuesta rápida es:"No solicite sus datos". Pero eso no siempre es realista. En algunos casos, puede descargar esa clasificación al cliente o a una capa de aplicación, pero los usuarios todavía tienen que esperar para clasificar los datos en eso. capa. En las situaciones en las que no puede modificar el funcionamiento de la aplicación, puede comenzar mirando sus índices.
Si admite una aplicación que permite a los usuarios ejecutar consultas ad-hoc, o cambiar el orden de clasificación para que puedan ver los datos ordenados como ellos quieren... lo pasará muy mal (pero no es una causa perdida, así que ¡No dejes de leer todavía!). No puede indexar para cada opción. Es ineficiente y creará más problemas de los que resuelve. Tu mejor apuesta aquí es hablar con los usuarios (lo sé, a veces da miedo dejar tu rincón del bosque, pero inténtalo). Para las consultas que los usuarios ejecutan con mayor frecuencia, averigüe cómo les gusta ver los datos. Sí, también puede obtener esto del caché del plan:puede recuperar consultas y planes hasta que esté satisfecho para ver lo que están haciendo. Pero es más rápido hablar con los usuarios. El beneficio adicional es que puede explicar por qué está preguntando y por qué la idea de "ordenar todas las columnas porque puedo" no es tan buena. Saber es la mitad de la batalla. Si puede dedicar algo de tiempo a educar a sus usuarios avanzados y a los usuarios que capacitan a los nuevos, es posible que pueda hacer algo bueno.
Si admite una aplicación con opciones de ORDEN POR limitadas, entonces puede hacer un análisis real. Revise qué variaciones ORDER BY existen, determine qué combinaciones se ejecutan con mayor frecuencia e indexe para respaldar esas consultas. Probablemente no llegue a todos, pero aún puede tener un impacto. Puede ir un paso más allá al hablar con sus desarrolladores y educarlos sobre el problema y cómo solucionarlo.
Por último, cuando busque planes de consulta con operaciones SORT, no se concentre solo en eliminar la ordenación. Mira dónde el Ordenar ocurre en el plan. Si sucede muy a la izquierda del plan y es típicamente unas pocas filas, puede haber otras áreas con un mayor factor de mejora en las que centrarse. La Ordenación de la izquierda es el patrón en el que nos enfocamos hoy, pero una Ordenación no siempre ocurre debido a un ORDEN POR. Si ve una ordenación en el extremo derecho del plan y hay muchas filas moviéndose a través de esa parte del plan, sabe que ha encontrado un buen lugar para comenzar a ajustar.