Considere la siguiente consulta de AdventureWorks que devuelve los ID de transacción de la tabla de historial para el ID de producto 421:
SELECT TH.TransactionID FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 421;
El optimizador de consultas encuentra rápidamente un plan de ejecución eficiente con una estimación de cardinalidad (recuento de filas) que es exactamente correcta, como se muestra en SQL Sentry Plan Explorer:

Ahora supongamos que queremos encontrar los ID de transacciones del historial para el producto AdventureWorks denominado "Metal Plate 2". Hay muchas formas de expresar esta consulta en T-SQL. Una formulación natural es:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); El plan de ejecución es el siguiente:
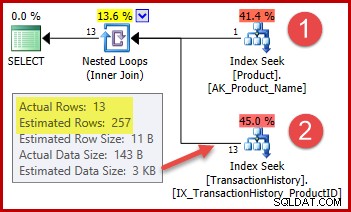
La estrategia es:
- Busque el ID del producto en la tabla Producto del nombre dado
- Ubique filas para ese ID de producto en la tabla Historial
El número estimado de filas para el paso 1 es exactamente correcto porque el índice utilizado se declara como único y se ingresa solo en el nombre del producto. Por lo tanto, se garantiza que la prueba de igualdad en "Metal Plate 2" devolverá exactamente una fila (o cero filas si especificamos un nombre de producto que no existe).
La estimación de 257 filas resaltada para el paso dos es menos precisa:en realidad solo se encuentran 13 filas. Esta discrepancia surge porque el optimizador no sabe qué ID de producto en particular está asociado con el producto denominado "Metal Plate 2". Trata el valor como desconocido, generando una estimación de cardinalidad utilizando información de densidad promedio. El cálculo utiliza elementos del objeto de estadísticas que se muestra a continuación:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH STAT_HEADER, DENSITY_VECTOR;
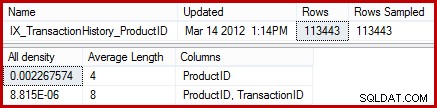
Las estadísticas muestran que la tabla contiene 113443 filas con 441 ID de producto únicos (1/0,002267574 =441). Suponiendo que la distribución de filas entre los ID de productos es uniforme, la estimación de cardinalidad espera que coincida un ID de producto (113443/441) =257,24 filas en promedio. Resulta que la distribución no es particularmente uniforme; solo hay 13 filas para el producto "Metal Plate 2".
Un aparte
Quizás esté pensando que la estimación de 257 filas debería ser más precisa. Por ejemplo, dado que los ID y los nombres de los productos están limitados a ser únicos, SQL Server podría mantener automáticamente información sobre esta relación uno a uno. Entonces sabría que "Metal Plate 2" está asociado con el ID de producto 479 y usaría esa información para generar una estimación más precisa usando el histograma de ProductID:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH HISTOGRAM;
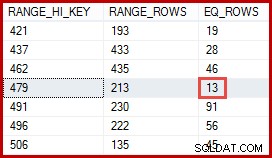
Una estimación de 13 filas obtenida de esta manera habría sido exactamente correcta. Sin embargo, la estimación de 257 filas no era irrazonable, dada la información estadística disponible y los supuestos simplificadores normales (como la distribución uniforme) aplicados por la estimación de cardinalidad en la actualidad. Las estimaciones exactas siempre son buenas, pero las estimaciones "razonables" también son perfectamente aceptables.
Combinando las dos consultas
Digamos que ahora queremos ver todos los ID del historial de transacciones donde el ID del producto es 421 O el nombre del producto es "Metal Plate 2". Una forma natural de combinar las dos consultas anteriores es:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); El plan de ejecución es un poco más complejo ahora, pero aún contiene elementos reconocibles de los planes de un solo predicado:
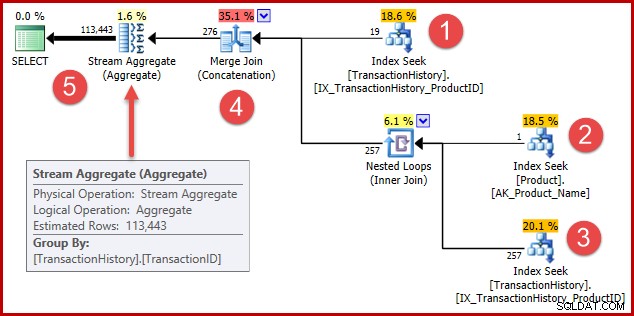
La estrategia es:
- Buscar registros de historial para el producto 421
- Busque el ID del producto denominado "Metal Plate 2"
- Encuentre registros de historial para la identificación del producto que se encuentra en el paso 2
- Combina filas de los pasos 1 y 3
- Elimine cualquier duplicado (porque el producto 421 también podría ser el que se llama "Metal Plate 2")
Los pasos 1 a 3 son exactamente los mismos que antes. Las mismas estimaciones se producen por las mismas razones. El paso 4 es nuevo, pero muy simple:concatena las 19 filas esperadas con las 257 filas esperadas, para dar una estimación de 276 filas.
El paso 5 es el interesante. El agregado de flujo de eliminación de duplicados tiene una entrada estimada de 276 filas y una salida estimada de 113443 filas. Un agregado que genera más filas de las que recibe parece imposible, ¿verdad?
* Verá una estimación de 102099 filas aquí si está utilizando el modelo de estimación de cardinalidad anterior a 2014.
El error de estimación de cardinalidad
La estimación imposible de Stream Aggregate en nuestro ejemplo se debe a un error en la estimación de cardinalidad. Es un ejemplo interesante, así que lo exploraremos con un poco de detalle.
Eliminación de subconsultas
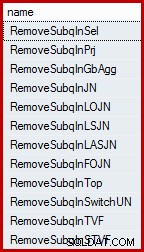
Puede que le sorprenda saber que el optimizador de consultas de SQL Server no funciona directamente con las subconsultas. Se eliminan del árbol de consulta lógica al principio del proceso de compilación y se reemplazan con una construcción equivalente con la que el optimizador está configurado para trabajar y razonar. El optimizador tiene una serie de reglas que eliminan las subconsultas. Estos se pueden enumerar por nombre mediante la siguiente consulta (el DMV al que se hace referencia está mínimamente documentado, pero no es compatible):
SELECT name FROM sys.dm_exec_query_transformation_stats WHERE name LIKE 'RemoveSubq%';
Resultados (en SQL Server 2014):
La consulta de prueba combinada tiene dos predicados ("selecciones" en términos relacionales) en la tabla de historial, conectados por OR . Uno de estos predicados incluye una subconsulta. Todo el subárbol (tanto los predicados como la subconsulta) se transforma mediante la primera regla de la lista ("eliminar la subconsulta en la selección") en una semi-unión sobre la unión de los predicados individuales. Si bien no es posible representar el resultado de esta transformación interna exactamente usando la sintaxis de T-SQL, está bastante cerca de ser:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
)
OPTION (QUERYRULEOFF ApplyUAtoUniSJ); Es un poco desafortunado que mi aproximación T-SQL del árbol interno después de la eliminación de la subconsulta contenga una subconsulta, pero en el lenguaje del procesador de consultas no la contiene (es una combinación parcial). Si prefiere ver el formulario interno sin procesar en lugar de mi intento de un equivalente de T-SQL, tenga la seguridad de que estará disponible momentáneamente.
La sugerencia de consulta no documentada incluida en el T-SQL anterior existe para evitar una transformación posterior para aquellos de ustedes que desean ver la lógica transformada en forma de plan de ejecución. Las anotaciones a continuación muestran las posiciones de los dos predicados después de la transformación:
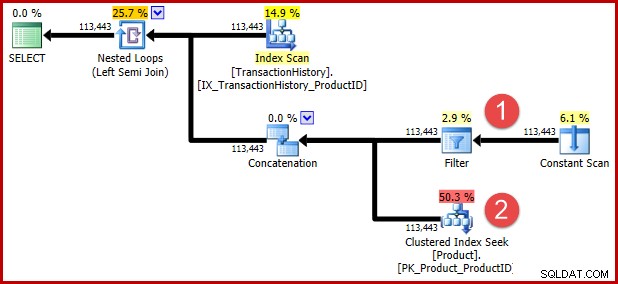
La intuición detrás de la transformación es que una fila de historial califica si cualquiera de los predicados se cumple. Independientemente de lo útil que encuentre mi T-SQL aproximado y la ilustración del plan de ejecución, espero que al menos quede razonablemente claro que la reescritura expresa el mismo requisito que la consulta original.
Debo enfatizar que el optimizador no genera literalmente una sintaxis T-SQL alternativa ni produce planes de ejecución completos en etapas intermedias. Las representaciones de T-SQL y el plan de ejecución anteriores están destinadas únicamente a ayudar a la comprensión. Si está interesado en los detalles sin procesar, la representación interna prometida del árbol de consulta transformado (ligeramente editado para mayor claridad/espacio) es:
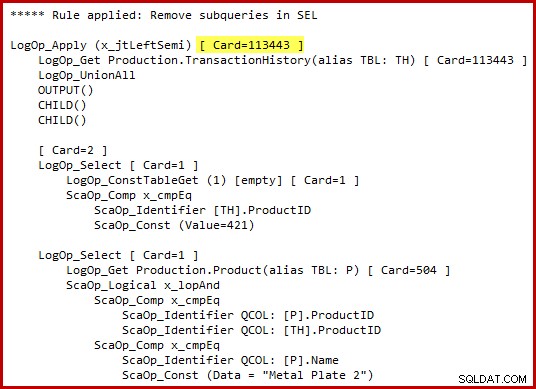
Observe la estimación de cardinalidad de semiunión de aplicación resaltada. Son 113443 filas cuando se usa el estimador de cardinalidad de 2014 (102099 filas si se usa el antiguo CE). Tenga en cuenta que la tabla de historial de AdventureWorks contiene 113443 filas en total, por lo que esto representa una selectividad del 100 % (90 % para el antiguo CE).
Anteriormente vimos que la aplicación de cualquiera de estos predicados solo da como resultado solo una pequeña cantidad de coincidencias:19 filas para el ID de producto 421 y 13 filas (estimado 257) para "Metal Plate 2". Estimando que la disyunción (OR) de los dos predicados devolverá todas las filas en la tabla base parece completamente loco.
Detalles del error
Los detalles del cálculo de selectividad para la combinación semi solo son visibles en SQL Server 2014 cuando se usa el nuevo estimador de cardinalidad con el indicador de seguimiento (no documentado) 2363. Probablemente sea posible ver algo similar con Extended Events, pero la salida del indicador de seguimiento es más conveniente para usar aquí. La sección relevante de la salida se muestra a continuación:
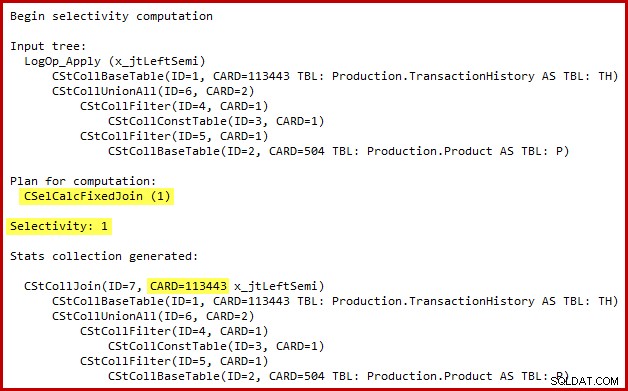
El estimador de cardinalidad utiliza la calculadora de combinación fija con una selectividad del 100 %. Como consecuencia, la cardinalidad de salida estimada de la unión semi es la misma que su entrada, lo que significa que se espera que califiquen las 113443 filas de la tabla de historial.
La naturaleza exacta del error es que el cálculo de la selectividad de la semiunión pierde cualquier predicado ubicado más allá de una unión en el árbol de entrada. En la ilustración a continuación, la falta de predicados en la semiunión en sí se considera que significa que todas las filas calificarán; ignora el efecto de los predicados debajo de la concatenación (unión de todos).
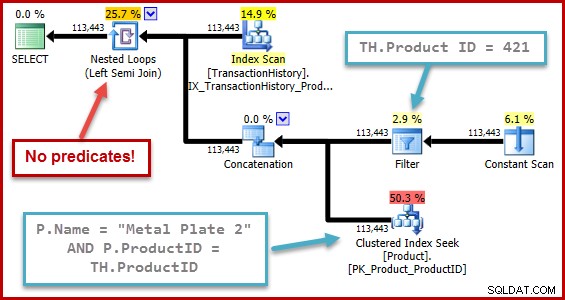
Este comportamiento es aún más sorprendente cuando considera que el cálculo de selectividad está operando en una representación de árbol que el optimizador generó por sí mismo (la forma del árbol y el posicionamiento de los predicados es el resultado de eliminar la subconsulta).
Un problema similar ocurre con el estimador de cardinalidad anterior a 2014, pero la estimación final se fija en el 90 % de la entrada de semiunión estimada (por razones entretenidas relacionadas con una estimación de predicado invertida fija del 10 % que es una distracción demasiado grande para obtener en).
Ejemplos
Como se mencionó anteriormente, este error se manifiesta cuando se realiza una estimación para una unión semi con predicados relacionados ubicados más allá de una unión total. Que esta disposición interna se produzca durante la optimización de consultas depende de la sintaxis T-SQL original y de la secuencia precisa de las operaciones de optimización interna. Los siguientes ejemplos muestran algunos casos en los que el error ocurre y no ocurre:
Ejemplo 1
Este primer ejemplo incorpora un cambio trivial a la consulta de prueba:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- The only change
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); El plan de ejecución estimado es:
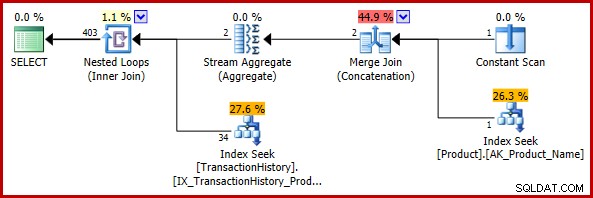
La estimación final de 403 filas es inconsistente con las estimaciones de entrada de la combinación de bucles anidados, pero sigue siendo razonable (en el sentido discutido anteriormente). Si se hubiera encontrado el error, la estimación final sería de 113443 filas (o 102099 filas si se usa el modelo CE anterior a 2014).
Ejemplo 2
En caso de que estuviera a punto de apresurarse y reescribir todas sus comparaciones constantes como subconsultas triviales para evitar este error, mire lo que sucede si hacemos otro cambio trivial, esta vez reemplazando la prueba de igualdad en el segundo predicado con IN. El significado de la consulta permanece sin cambios:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- Change 1
OR TH.ProductID IN -- Change 2
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); El error devuelve:
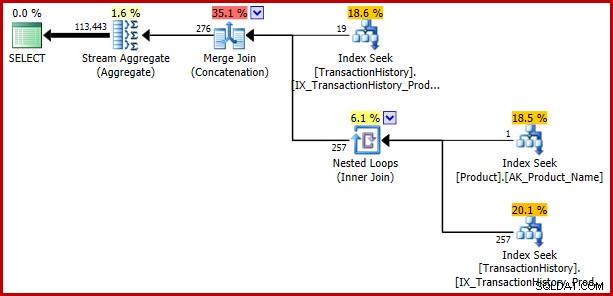
Ejemplo 3
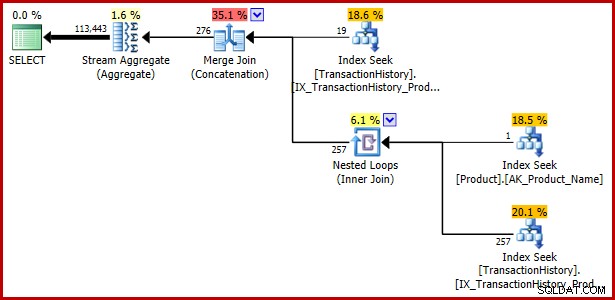
Aunque hasta ahora este artículo se ha concentrado en un predicado disyuntivo que contiene una subconsulta, el siguiente ejemplo muestra que la misma especificación de consulta expresada mediante EXISTS y UNION ALL también es vulnerable:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
); Plan de ejecución:
Ejemplo 4
Aquí hay dos formas más de expresar la misma consulta lógica en T-SQL:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
);
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
JOIN Production.Product AS P
ON P.ProductID = TH.ProductID
AND P.Name = N'Metal Plate 2'; Ninguna consulta encuentra el error y ambas producen el mismo plan de ejecución:
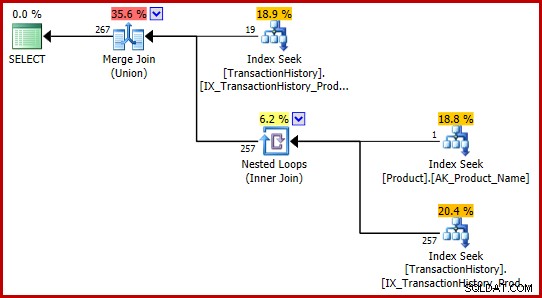
Estas formulaciones de T-SQL producen un plan de ejecución con estimaciones totalmente coherentes (y razonables).
Ejemplo 5
Quizás se pregunte si la estimación inexacta es importante. En los casos presentados hasta ahora, no lo es, al menos no directamente. Los problemas surgen cuando el error ocurre en una consulta más grande y la estimación incorrecta afecta las decisiones del optimizador en otros lugares. Como ejemplo mínimamente extendido, considere devolver los resultados de nuestra consulta de prueba en un orden aleatorio:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
)
ORDER BY NEWID(); -- New El plan de ejecución muestra que la estimación incorrecta afecta operaciones posteriores. Por ejemplo, es la base para la concesión de memoria reservada para el tipo:
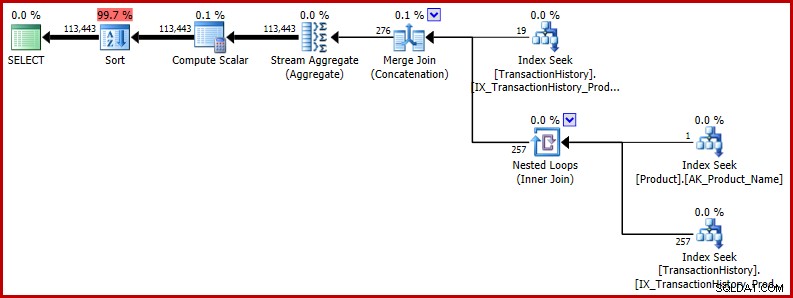
Si desea ver un ejemplo más real del impacto potencial de este error, eche un vistazo a esta pregunta reciente de Richard Mansell en el sitio de preguntas y respuestas de SQLPerformance.com, answers.SQLPerformance.com.
Resumen y reflexiones finales
Este error se activa cuando el optimizador realiza una estimación de cardinalidad para una combinación semi, en circunstancias específicas. Es un error difícil de detectar y solucionar por varias razones:
- No existe una sintaxis T-SQL explícita para especificar una unión semi, por lo que es difícil saber de antemano si una consulta en particular será vulnerable a este error.
- El optimizador puede introducir una semiunión en una amplia variedad de circunstancias, no todas las cuales son candidatos obvios para una semiunión.
- La semiunión problemática a menudo se transforma en otra cosa por la actividad posterior del optimizador, por lo que ni siquiera podemos confiar en que haya una operación de semiunión en el plan de ejecución final.
- No todas las estimaciones de cardinalidad extrañas se deben a este error. De hecho, muchos ejemplos de este tipo son un efecto secundario esperado e inofensivo del funcionamiento normal del optimizador.
- La estimación de selectividad de semiunión errónea siempre será el 90 % o el 100 % de su entrada, pero esto no suele corresponder a la cardinalidad de una tabla utilizada en el plan. Además, es posible que la cardinalidad de entrada de semiunión utilizada en el cálculo ni siquiera sea visible en el plan de ejecución final.
- Por lo general, hay muchas formas de expresar la misma consulta lógica en T-SQL. Algunos de estos activarán el error, mientras que otros no.
Estas consideraciones hacen que sea difícil ofrecer consejos prácticos para detectar o solucionar este error. Sin duda, vale la pena verificar los planes de ejecución en busca de estimaciones "escandalosas" e investigar consultas con un rendimiento mucho peor de lo esperado, pero ambos pueden tener causas que no se relacionan con este error. Dicho esto, vale la pena comprobar especialmente las consultas que incluyen una disyunción de predicados y una subconsulta. Como muestran los ejemplos de este artículo, esta no es la única forma de encontrar el error, pero espero que sea común.
Si tiene la suerte de estar ejecutando SQL Server 2014, con el nuevo estimador de cardinalidad habilitado, puede confirmar el error comprobando manualmente la salida de la marca de seguimiento 2363 para una estimación de selectividad fija del 100 % en una combinación semi, pero esto es apenas conveniente. Naturalmente, no querrá utilizar marcas de rastreo no documentadas en un sistema de producción.
El informe de error de User Voice para este problema se puede encontrar aquí. Vote y comente si desea que se investigue este problema (y posiblemente se solucione).