En mi última publicación ("Amigo, ¿quién es el dueño de esa tabla #temp?"), sugerí que en SQL Server 2012 y versiones posteriores, podría usar eventos extendidos para monitorear la creación de tablas #temp. Esto le permitiría correlacionar objetos específicos que ocupan mucho espacio en tempdb con la sesión que los creó (por ejemplo, para determinar si la sesión podría cerrarse para intentar liberar espacio). Lo que no discutí es la sobrecarga de este seguimiento:esperamos que los eventos extendidos sean más ligeros que el seguimiento, pero ningún monitoreo es completamente gratuito.
Dado que la mayoría de las personas dejan habilitado el seguimiento predeterminado, lo dejaremos en su lugar. Probaremos ambos montones usando SELECT INTO (que el seguimiento predeterminado no recopilará) e índices agrupados (que lo hará), y programaremos el lote por sí solo como referencia, luego ejecutaremos el lote nuevamente con la sesión de eventos extendidos en ejecución. También probaremos contra SQL Server 2012 y SQL Server 2014. El lote en sí es bastante simple:
SET NOCOUNT ON; SELECT SYSDATETIME(); GO -- run this portion for only the heap batch: SELECT TOP (100) [object_id] INTO #foo FROM sys.all_objects ORDER BY [object_id]; DROP TABLE #foo; -- run this portion for only the CIX batch: CREATE TABLE #bar(id INT PRIMARY KEY); INSERT #bar(id) SELECT TOP (100) [object_id] FROM sys.all_objects ORDER BY [object_id]; DROP TABLE #bar; GO 100000 SELECT SYSDATETIME();
Ambas instancias tienen tempdb configurado con cuatro archivos de datos y con TF 1117 y TF 1118 habilitados, en una VM con cuatro CPU, 16 GB de memoria y solo SSD. Intencionalmente creé pequeñas tablas #temp para amplificar cualquier impacto observado en el lote en sí (que se ahogaría si la creación de las tablas #temp tomara mucho tiempo o causara eventos de crecimiento automático excesivos).
Ejecuté estos lotes en cada escenario y estos fueron los resultados, medidos en la duración del lote en segundos:
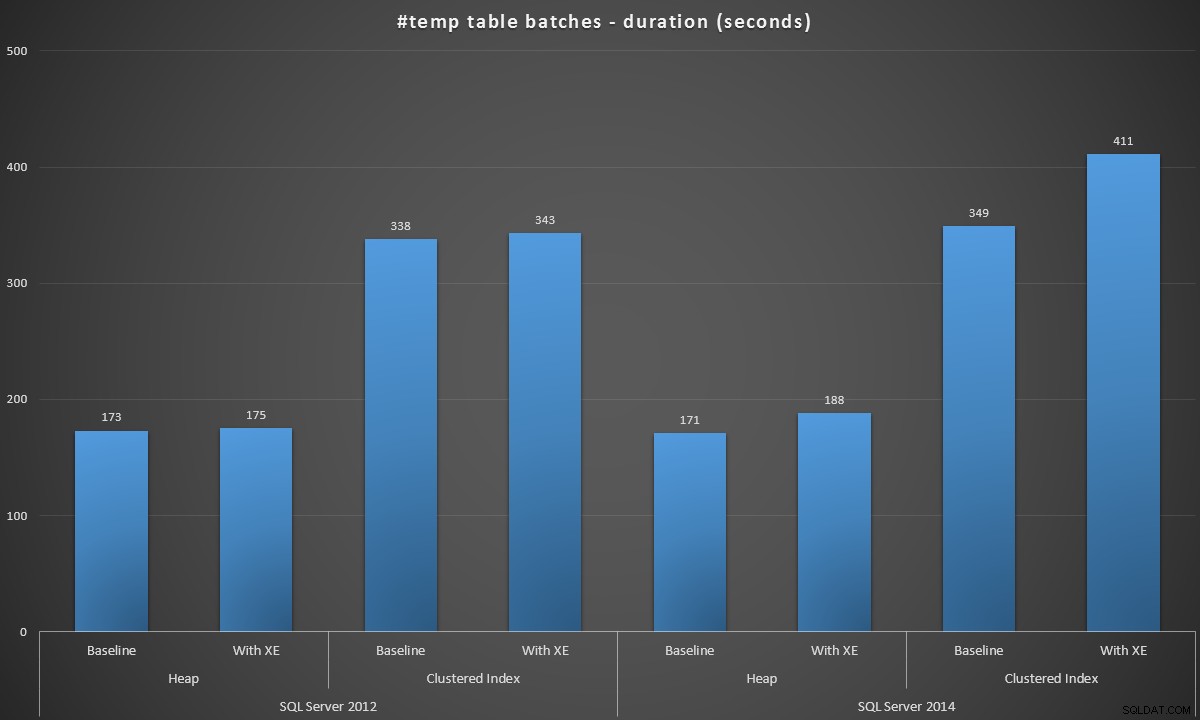
Duración del lote, en segundos, de la creación de 100 000 tablas #temp
Expresando los datos de forma un poco diferente, si dividimos 100 000 por la duración, podemos mostrar la cantidad de tablas #temp que podemos crear por segundo en cada escenario (léase:rendimiento). Aquí están esos resultados:
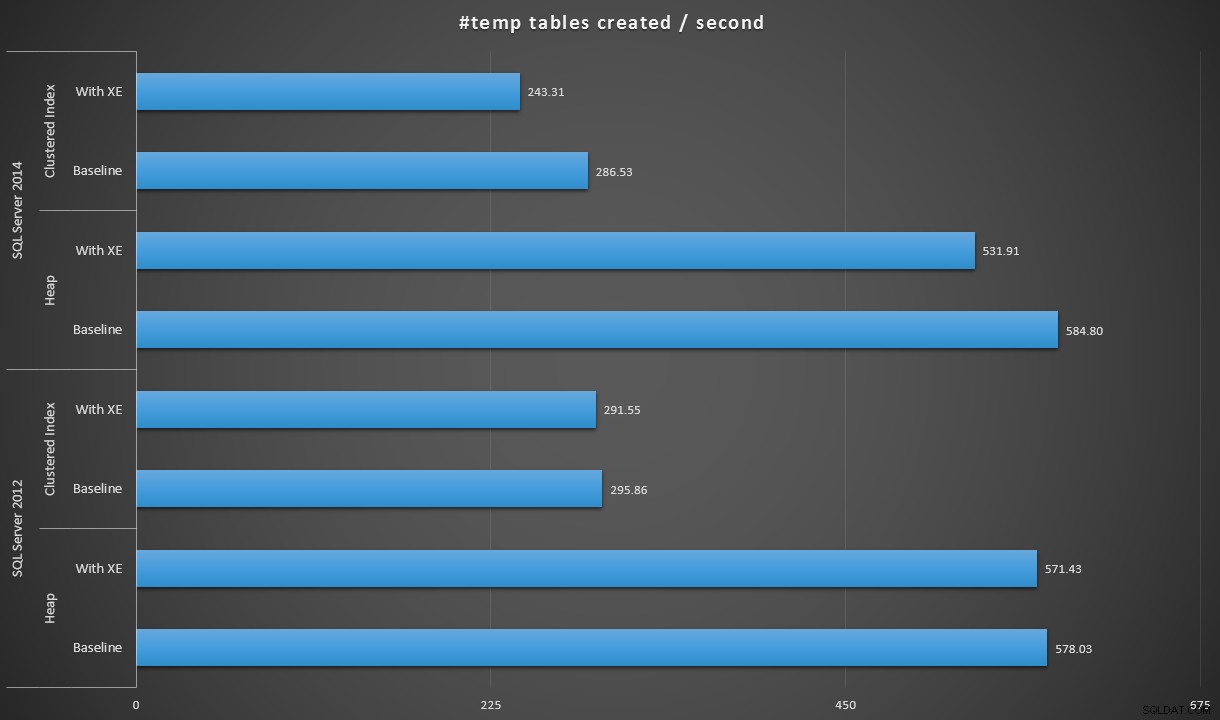
#tablas temporales creadas por segundo en cada escenario
Los resultados me sorprendieron un poco:esperaba que, con las mejoras de SQL Server 2014 en la lógica de escritura ansiosa, la población del montón, como mínimo, se ejecutaría mucho más rápido. El montón en 2014 fue dos míseros segundos más rápido que en 2012 en la configuración de referencia, pero los eventos extendidos aumentaron bastante el tiempo (aproximadamente un 10 % de aumento con respecto a la referencia); mientras que el tiempo del índice agrupado fue comparable al de 2012 en la línea de base, pero aumentó casi un 18 % con los eventos extendidos habilitados. En 2012, los deltas para montones e índices agrupados fueron mucho más modestos:1,1 % y 1,5 %, respectivamente. (Y para que quede claro, no se produjeron eventos de crecimiento automático durante ninguna de las pruebas).
Entonces, pensé, ¿qué pasa si creo una sesión de eventos extendidos más eficiente y más eficiente? Seguramente podría eliminar algunas de esas columnas de acción; tal vez solo necesite el nombre de inicio de sesión y el spid, y pueda ignorar el nombre de la aplicación, el nombre del host y el sql_text potencialmente costoso. Tal vez podría descartar el filtro adicional contra la confirmación (recopilar el doble de eventos, pero gastar menos CPU en el filtrado) y permitir la pérdida de múltiples eventos para reducir el impacto potencial en la carga de trabajo. Esta sesión más ligera se ve así:
CREATE EVENT SESSION [TempTableCreation2014_LeanerMeaner] ON SERVER
ADD EVENT sqlserver.object_created
(
ACTION
(
sqlserver.server_principal_name,
sqlserver.session_id
)
WHERE
(
sqlserver.like_i_sql_unicode_string([object_name], N'#%')
)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = 'c:\temp\TempTableCreation2014_LeanerMeaner.xel',
MAX_FILE_SIZE = 32768,
MAX_ROLLOVER_FILES = 10
)
WITH
(
EVENT_RETENTION_MODE = ALLOW_MULTIPLE_EVENT_LOSS
);
GO
ALTER EVENT SESSION [TempTableCreation2014_LeanerMeaner] ON SERVER STATE = START; Por desgracia, no, los mismos resultados. Algo más de tres minutos para el montón y algo menos de siete minutos para el índice agrupado. Para profundizar en dónde se gastaba el tiempo adicional, observé la instancia de 2014 con SQL Sentry y ejecuté solo el lote de índice agrupado sin ninguna sesión de eventos extendidos configurada. Luego volví a ejecutar el lote, esta vez con la sesión XE más ligera configurada. Los tiempos de los lotes fueron 5:47 (347 segundos) y 6:55 (415 segundos), muy en línea con el lote anterior (me alegró ver que nuestro monitoreo no contribuyó más a la duración :-)) . Verifiqué que no se eliminaron eventos y, nuevamente, que no se produjeron eventos de crecimiento automático.
Miré el tablero de SQL Sentry en modo historial, lo que me permitió ver rápidamente las métricas de rendimiento de ambos lotes uno al lado del otro:
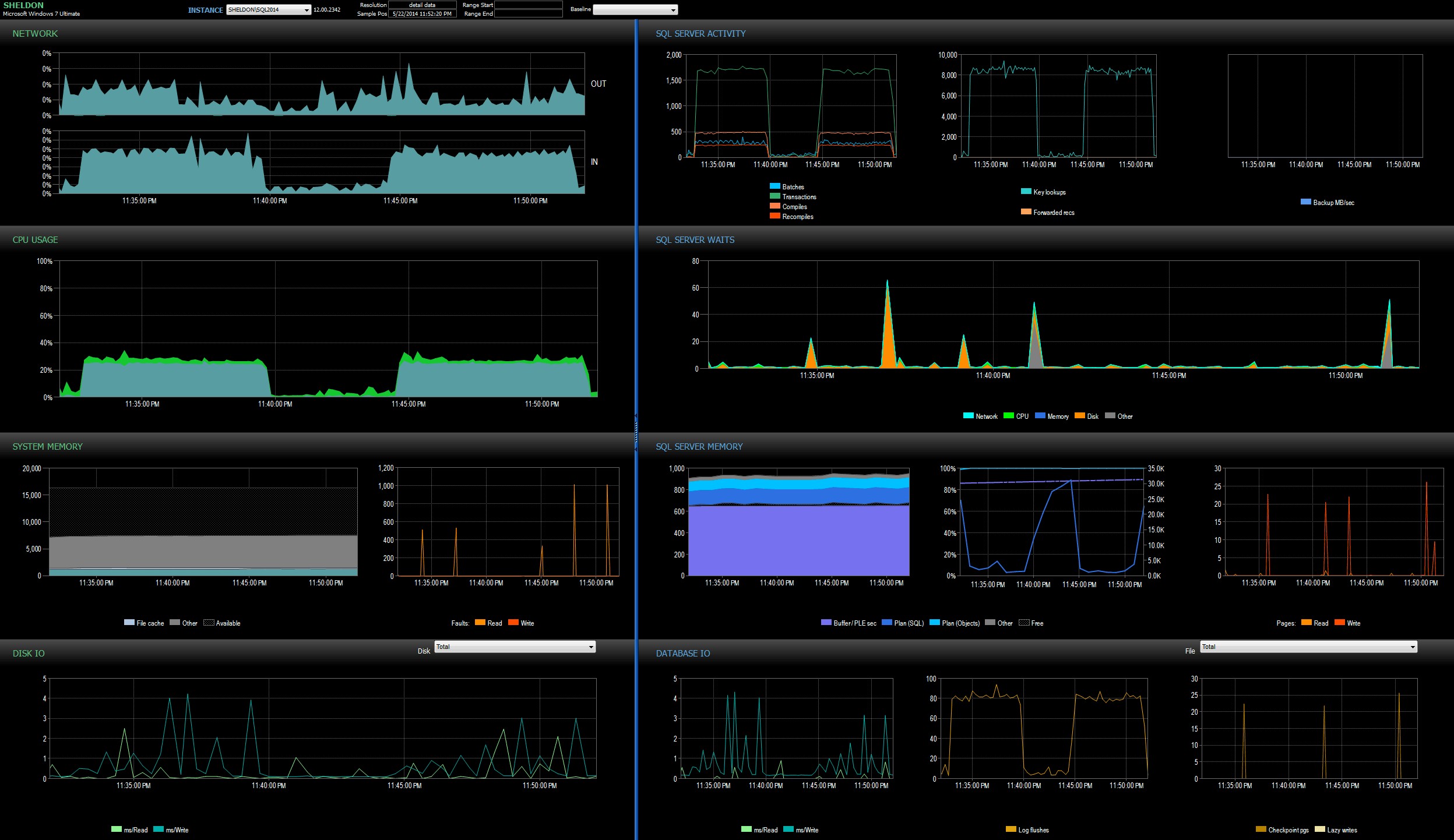
Panel de SQL Sentry, en modo historial, mostrando ambos lotes
Ambos lotes eran prácticamente idénticos en términos de red, CPU, transacciones, compilaciones, búsquedas de claves, etc. Hay una ligera diferencia en las esperas:los picos durante el primer lote fueron exclusivamente WRITELOG, mientras que se encontraron algunas esperas menores de CXPACKET en el segundo lote. Mi teoría de trabajo mucho después de la medianoche es que quizás una buena parte de la demora observada se debió al cambio de contexto causado por el proceso de eventos extendidos. Dado que no tenemos ninguna visibilidad de lo que XE está haciendo exactamente debajo de las sábanas, ni sabemos qué mecánicas subyacentes han cambiado en XE entre 2012 y 2014, esa es la historia con la que me quedaré por ahora, hasta que esté más cómodo con xperf y/o WinDbg.
Conclusión
En cualquier caso, está claro que el seguimiento de la creación de tablas #temp no es gratuito, y el costo puede variar según el tipo de tablas #temp que esté creando, la cantidad de información que esté recopilando en sus sesiones XE e incluso la versión. de SQL Server que está utilizando. De modo que puede ejecutar pruebas similares a las que he hecho aquí y decidir cuán valiosa es recopilar esta información en su entorno.