Durante mucho tiempo se ha establecido que las variables de tabla con una gran cantidad de filas pueden ser problemáticas, ya que el optimizador siempre las ve como si tuvieran una fila. Sin una recompilación después de que se haya rellenado la variable de la tabla (ya que antes está vacía), no hay cardinalidad para la tabla y las recompilaciones automáticas no ocurren porque las variables de la tabla ni siquiera están sujetas a un umbral de recompilación. Los planes, por lo tanto, se basan en una cardinalidad de tabla de cero, no uno, pero el mínimo se incrementa a uno como describe Paul White (@SQL_Kiwi) en esta respuesta de dba.stackexchange.
La forma en que normalmente podemos solucionar este problema es agregar OPTION (RECOMPILE) a la consulta que hace referencia a la variable de la tabla, lo que obliga al optimizador a inspeccionar la cardinalidad de la variable de la tabla después de que se haya completado. Para evitar la necesidad de ir y cambiar manualmente cada consulta para agregar una sugerencia de recompilación explícita, se introdujo un nuevo indicador de rastreo (2453) en SQL Server 2012 Service Pack 2 y SQL Server 2014 Cumulative Update #3:
- KB #2952444:REVISIÓN:bajo rendimiento cuando usa variables de tabla en SQL Server 2012 o SQL Server 2014
Cuando el indicador de seguimiento 2453 está activo, el optimizador puede obtener una imagen precisa de la cardinalidad de la tabla después de que se haya creado la variable de la tabla. Esto puede ser A Good Thing™ para muchas consultas, pero probablemente no para todas, y debe saber cómo funciona de manera diferente a OPTION (RECOMPILE) . En particular, la optimización de incrustación de parámetros de la que habla Paul White en esta publicación se produce en OPTION (RECOMPILE) , pero no bajo esta nueva marca de rastreo.
Una prueba sencilla
Mi prueba inicial consistió simplemente en completar una variable de tabla y seleccionarla; esto arrojó el conteo de filas estimado demasiado familiar de 1. Aquí está la prueba que ejecuté (y agregué la sugerencia de recompilación para comparar):
DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, t.name FROM @t AS t; SELECT t.id, t.name FROM @t AS t OPTION (RECOMPILE); DBCC TRACEOFF(2453);
Usando SQL Sentry Plan Explorer, podemos ver que el plan gráfico para ambas consultas en este caso es idéntico, probablemente al menos en parte porque este es literalmente un plan trivial:

Plan gráfico para un escaneo de índice trivial contra @t
Sin embargo, las estimaciones no son las mismas. Aunque el indicador de seguimiento está habilitado, todavía obtenemos una estimación de 1 que sale del escaneo de índice si no usamos la sugerencia de recompilación:
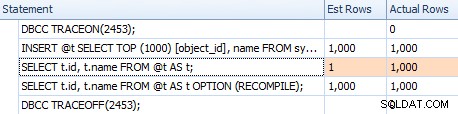
Comparación de estimaciones para un plan trivial en la cuadrícula de declaraciones
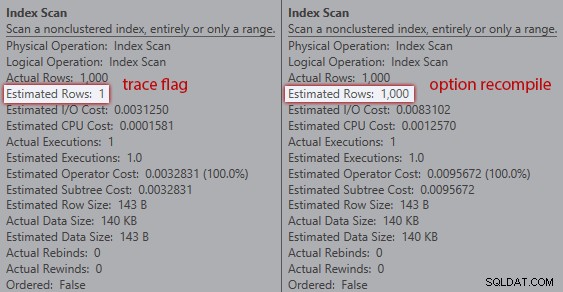
Comparación de estimaciones entre indicador de seguimiento (izquierda) y recompilación (derecha)
Si alguna vez has estado cerca de mí en persona, probablemente puedas imaginar la cara que hice en este momento. Estaba seguro de que el artículo de KB enumeraba el número de marca de seguimiento incorrecto o que necesitaba alguna otra configuración habilitada para que estuviera realmente activa.
Benjamin Nevarez (@BenjaminNevarez) rápidamente me señaló que necesitaba mirar más de cerca el artículo de KB "Errores corregidos en SQL Server 2012 Service Pack 2". Si bien han oscurecido el texto detrás de una viñeta oculta en Destacados> Motor relacional, el artículo de la lista de correcciones hace un trabajo un poco mejor al describir el comportamiento de la marca de seguimiento que el artículo original (énfasis mío):
Si una variable de tabla se une a otras tablas en SQL Server, puede resultar en un rendimiento lento debido a la selección ineficiente del plan de consulta porque SQL Server no admite estadísticas ni rastrea el número de filas en una variable de tabla mientras compila un plan de consulta.Por lo tanto, a partir de esta descripción, parecería que el indicador de seguimiento solo está destinado a abordar el problema cuando la variable de la tabla participa en una combinación. (Por qué esa distinción no se hace en el artículo original, no tengo idea). Pero también funciona si hacemos que las consultas funcionen un poco más:el optimizador considera que la consulta anterior es trivial, y el indicador de seguimiento no Ni siquiera intentes hacer algo en ese caso. Pero se activará si se realiza una optimización basada en costos, incluso sin una combinación; la bandera de rastreo simplemente no tiene efecto en los planes triviales. Este es un ejemplo de un plan no trivial que no implica una unión:
DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT TOP (100) t.id, t.name FROM @t AS t ORDER BY NEWID(); SELECT TOP (100) t.id, t.name FROM @t AS t ORDER BY NEWID() OPTION (RECOMPILE); DBCC TRACEOFF(2453);
Este plan ya no es baladí; la optimización está marcada como completa. La mayor parte del costo se traslada a un operador de clasificación:
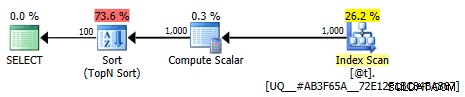
Plan gráfico menos trivial
Y las estimaciones se alinean para ambas consultas (esta vez te guardaré la información sobre herramientas, pero puedo asegurarte que son las mismas):

Cuadrícula de declaraciones para planes menos triviales con y sin la sugerencia de recompilación
Entonces, parece que el artículo de KB no es exactamente exacto:pude forzar el comportamiento esperado del indicador de seguimiento sin introducir una unión. Pero también quiero probarlo con una combinación.
Una mejor prueba
Tomemos este ejemplo simple, con y sin la marca de rastreo:
--DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; --DBCC TRACEOFF(2453);
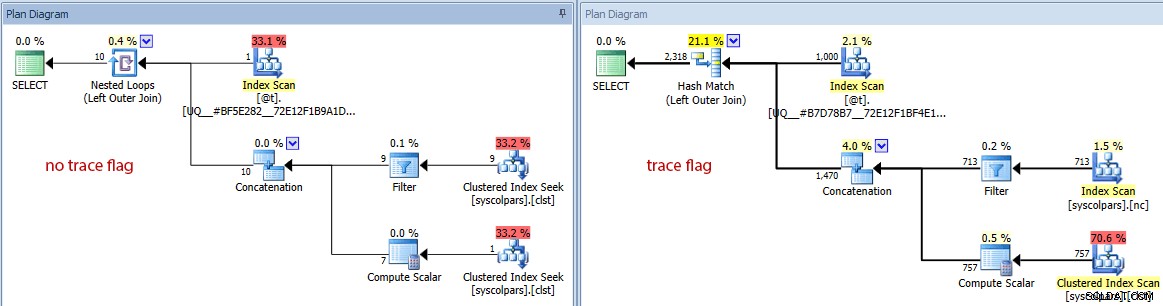
Sin el indicador de seguimiento, el optimizador estima que una fila provendrá del escaneo de índice contra la variable de la tabla. Sin embargo, con la marca de seguimiento habilitada, obtiene la explosión de 1000 filas en:
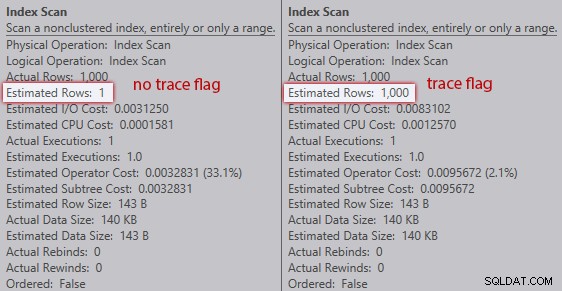
Comparación de estimaciones de exploración de índice (sin marca de seguimiento a la izquierda, marcar la bandera a la derecha)
Las diferencias no se detienen ahí. Si observamos más de cerca, podemos ver una variedad de decisiones diferentes que ha tomado el optimizador, todas derivadas de estas mejores estimaciones:
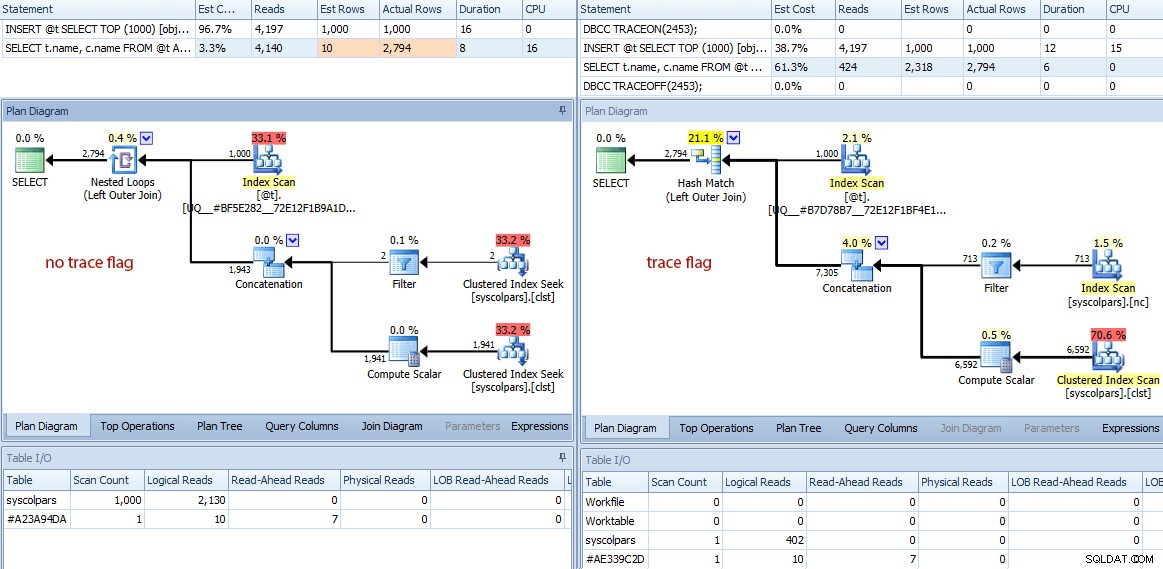
Comparación de planes (sin indicador de seguimiento a la izquierda, indicador de seguimiento a la derecha)
Un breve resumen de las diferencias:
- La consulta sin la marca de seguimiento ha realizado 4140 operaciones de lectura, mientras que la consulta con la estimación mejorada solo ha realizado 424 (aproximadamente una reducción del 90 %).
- El optimizador estimó que la consulta completa devolvería 10 filas sin la marca de seguimiento y 2318 filas mucho más precisas cuando se usa la marca de seguimiento.
- Sin la marca de seguimiento, el optimizador optó por realizar una combinación de bucles anidados (lo que tiene sentido cuando se estima que una de las entradas es muy pequeña). Esto condujo a que el operador de concatenación y ambos índices buscaran ejecutarse 1000 veces, en contraste con la coincidencia hash elegida bajo el indicador de seguimiento, donde el operador de concatenación y ambos escaneos solo se ejecutaron una vez.
- La pestaña Table I/O también muestra 1000 exploraciones (exploraciones de rango disfrazadas de búsquedas de índice) y un recuento de lecturas lógicas mucho más alto en comparación con
syscolpars(la tabla del sistema detrás desys.all_columns). - Si bien la duración no se vio afectada significativamente (24 milisegundos frente a 18 milisegundos), probablemente pueda imaginar el tipo de impacto que estas otras diferencias podrían tener en una consulta más seria.
- Si cambiamos el diagrama a costos estimados, podemos ver cuán diferente la variable de la tabla puede engañar al optimizador sin la marca de seguimiento:
Comparación de recuentos de filas estimados (sin marca de seguimiento a la izquierda, seguimiento bandera a la derecha)
Es claro y no sorprende que el optimizador haga un mejor trabajo al seleccionar el plan correcto cuando tiene una visión precisa de la cardinalidad involucrada. ¿Pero a qué precio?
Recompilaciones y gastos generales
Cuando usamos OPTION (RECOMPILE) con el lote anterior, sin el indicador de seguimiento habilitado, obtenemos el siguiente plan, que es prácticamente idéntico al plan con el indicador de seguimiento (la única diferencia notable es que las filas estimadas son 2316 en lugar de 2318):
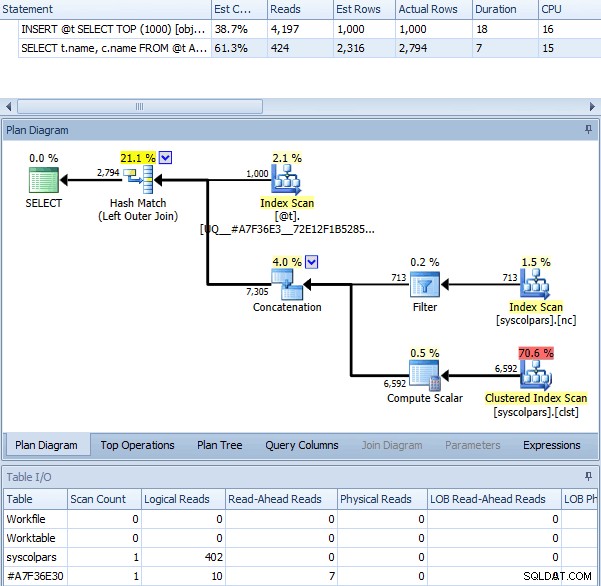
Misma consulta con OPCIÓN (RECOMPILAR)
Por lo tanto, esto podría llevarlo a creer que el indicador de rastreo logra resultados similares al desencadenar una recompilación para usted cada vez. Podemos investigar esto usando una sesión de eventos extendidos muy simple:
CREATE EVENT SESSION [CaptureRecompiles] ON SERVER
ADD EVENT sqlserver.sql_statement_recompile
(
ACTION(sqlserver.sql_text)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = N'C:\temp\CaptureRecompiles.xel'
);
GO
ALTER EVENT SESSION [CaptureRecompiles] ON SERVER STATE = START; Ejecuté el siguiente conjunto de lotes, que ejecutó 20 consultas con (a) ninguna opción de recompilación o marca de seguimiento, (b) la opción de recompilación y (c) una marca de seguimiento a nivel de sesión.
/* default - no trace flag, no recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; GO 20 /* recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id] OPTION (RECOMPILE); GO 20 /* trace flag */ DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.name, c.name FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DBCC TRACEOFF(2453); GO 20
Luego miré los datos del evento:
SELECT
sql_text = LEFT(sql_text, 255),
recompile_count = COUNT(*)
FROM
(
SELECT
x.x.value(N'(event/action[@name="sql_text"]/value)[1]',N'nvarchar(max)')
FROM
sys.fn_xe_file_target_read_file(N'C:\temp\CaptureRecompiles*.xel',NULL,NULL,NULL) AS f
CROSS APPLY (SELECT CONVERT(XML, f.event_data)) AS x(x)
) AS x(sql_text)
GROUP BY LEFT(sql_text, 255);
Los resultados muestran que no se realizaron recompilaciones en la consulta estándar, la declaración que hace referencia a la variable de la tabla se volvió a compilar una vez bajo el indicador de seguimiento y, como era de esperar, siempre con RECOMPILE opción:
| sql_text | recompilar_cuenta |
|---|---|
| /* recompilar */ DECLARE @t TABLE (i INT … | 20 |
| /* marca de rastreo */ DBCC TRACEON(2453); DECLARAR @t … | 1 |
Resultados de consulta contra datos de XEvents
Luego, apagué la sesión de eventos extendidos y luego cambié el lote para medir a escala. Esencialmente, el código mide 1,000 iteraciones de creación y llenado de una variable de tabla, luego selecciona sus resultados en una tabla #temp (una forma de suprimir la salida de tantos conjuntos de resultados desechables), usando cada uno de los tres métodos.
SET NOCOUNT ON; /* default - no trace flag, no recompile */ SELECT SYSDATETIME(); GO DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DROP TABLE #x; GO 1000 SELECT SYSDATETIME(); GO /* recompile */ DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id] OPTION (RECOMPILE); DROP TABLE #x; GO 1000 SELECT SYSDATETIME(); GO /* trace flag */ DBCC TRACEON(2453); DECLARE @t TABLE(id INT PRIMARY KEY, name SYSNAME NOT NULL UNIQUE); INSERT @t SELECT TOP (1000) [object_id], name FROM sys.all_objects; SELECT t.id, c.name INTO #x FROM @t AS t LEFT OUTER JOIN sys.all_columns AS c ON t.id = c.[object_id]; DROP TABLE #x; DBCC TRACEOFF(2453); GO 1000 SELECT SYSDATETIME(); GO
Corrí este lote 10 veces y saqué los promedios; ellos fueron:
| Método | Duración media (milisegundos) |
|---|---|
| Predeterminado | 23.148,4 |
| Recompilar | 29.959,3 |
| Bandera de seguimiento | 22.100,7 |
Duración promedio de 1000 iteraciones
En este caso, obtener las estimaciones correctas cada vez que se usó la sugerencia de recompilación fue mucho más lento que el comportamiento predeterminado, pero usar la marca de seguimiento fue un poco más rápido. Esto tiene sentido porque, si bien ambos métodos corrigen el comportamiento predeterminado de usar una estimación falsa (y obtener un mal plan como resultado), las recompilaciones toman recursos y, cuando no dan o no pueden producir un plan más eficiente, tienden a contribuyen a la duración total del lote.
Parece sencillo, pero espera...
La prueba anterior es levemente, e intencionalmente, defectuosa. Estamos insertando el mismo número de filas (1000) en la variable de la tabla todas las veces . ¿Qué sucede si la población inicial de la variable de la tabla varía para diferentes lotes? Seguramente veremos recompilaciones entonces, incluso bajo el indicador de seguimiento, ¿verdad? Tiempo para otra prueba. Configuremos una sesión de eventos extendidos ligeramente diferente, solo con un nombre de archivo de destino diferente (para no mezclar ningún dato de la otra sesión):
CREATE EVENT SESSION [CaptureRecompiles_v2] ON SERVER
ADD EVENT sqlserver.sql_statement_recompile
(
ACTION(sqlserver.sql_text)
)
ADD TARGET package0.asynchronous_file_target
(
SET FILENAME = N'C:\temp\CaptureRecompiles_v2.xel'
);
GO
ALTER EVENT SESSION [CaptureRecompiles_v2] ON SERVER STATE = START;
Ahora, inspeccionemos este lote, configurando recuentos de filas para cada iteración que sean significativamente diferentes. Ejecutaremos esto tres veces, eliminando los comentarios apropiados para que tengamos un lote sin un indicador de seguimiento o recompilación explícita, un lote con el indicador de seguimiento y un lote con OPTION (RECOMPILE) (tener un comentario preciso al principio hace que estos lotes sean más fáciles de identificar en lugares como la salida de eventos extendidos):
/* default, no trace flag or recompile */
/* recompile */
/* trace flag */
DECLARE @i INT = 1;
WHILE @i <= 6
BEGIN
--DBCC TRACEON(2453); -- uncomment this for trace flag
DECLARE @t TABLE(id INT PRIMARY KEY);
INSERT @t SELECT TOP (CASE @i
WHEN 1 THEN 24
WHEN 2 THEN 1782
WHEN 3 THEN 1701
WHEN 4 THEN 12
WHEN 5 THEN 15
WHEN 6 THEN 1560
END) [object_id]
FROM sys.all_objects;
SELECT t.id, c.name
FROM @t AS t
INNER JOIN sys.all_objects AS c
ON t.id = c.[object_id]
--OPTION (RECOMPILE); -- uncomment this for recompile
--DBCC TRACEOFF(2453); -- uncomment this for trace flag
DELETE @t;
SET @i += 1;
END
Ejecuté estos lotes en Management Studio, los abrí individualmente en Plan Explorer y filtré el árbol de declaraciones solo en SELECT consulta. Podemos ver el comportamiento diferente en los tres lotes mirando las filas estimadas y reales:

Comparación de tres lotes, mirando filas estimadas versus filas reales
En la cuadrícula más a la derecha, puede ver claramente dónde no se realizaron recompilaciones bajo la marca de rastreo
Podemos verificar los datos de XEvents para ver qué sucedió realmente con las recompilaciones:
SELECT
sql_text = LEFT(sql_text, 255),
recompile_count = COUNT(*)
FROM
(
SELECT
x.x.value(N'(event/action[@name="sql_text"]/value)[1]',N'nvarchar(max)')
FROM
sys.fn_xe_file_target_read_file(N'C:\temp\CaptureRecompiles_v2*.xel',NULL,NULL,NULL) AS f
CROSS APPLY (SELECT CONVERT(XML, f.event_data)) AS x(x)
) AS x(sql_text)
GROUP BY LEFT(sql_text, 255); Resultados:
| sql_text | recompilar_cuenta |
|---|---|
| /* recompilar */ DECLARE @i INT =1; MIENTRAS... | 6 |
| /* marca de seguimiento */ DECLARE @i INT =1; MIENTRAS... | 4 |
Resultados de consulta contra datos de XEvents
¡Muy interesante! Bajo el indicador de seguimiento, *vemos* recompilaciones, pero solo cuando el valor del parámetro de tiempo de ejecución ha variado significativamente del valor almacenado en caché. Cuando el valor del tiempo de ejecución es diferente, pero no mucho, no obtenemos una recompilación y se utilizan las mismas estimaciones. Entonces, está claro que el indicador de seguimiento introduce un umbral de recompilación para las variables de la tabla, y he confirmado (a través de una prueba separada) que esto usa el mismo algoritmo que el descrito para las tablas #temp en este documento "antiguo" pero aún relevante. Probaré esto en una publicación de seguimiento.
Nuevamente, probaremos el rendimiento, ejecutando el lote 1000 veces (con la sesión de eventos extendidos desactivada) y midiendo la duración:
| Método | Duración media (milisegundos) |
|---|---|
| Predeterminado | 101.285,4 |
| Recompilar | 111.423,3 |
| Bandera de seguimiento | 110.318,2 |
Duración promedio de 1000 iteraciones
En este escenario específico, perdemos alrededor del 10 % del rendimiento al forzar una recompilación cada vez o al usar una marca de rastreo. No estoy exactamente seguro de cómo se distribuyó el delta:¿los planes se basaron en mejores estimaciones no significativamente ¿mejor? ¿Compensaron las recompilaciones las ganancias de rendimiento en tanto? ? No quiero dedicar demasiado tiempo a esto, y fue un ejemplo trivial, pero demuestra que jugar con la forma en que funciona el optimizador puede ser un asunto impredecible. A veces puede estar mejor con el comportamiento predeterminado de cardinalidad =1, sabiendo que nunca provocará recompilaciones indebidas. El indicador de seguimiento podría tener mucho sentido si tiene consultas en las que completa repetidamente las variables de la tabla con el mismo conjunto de datos (por ejemplo, una tabla de búsqueda de código postal) o si siempre usa 50 o 1000 filas (por ejemplo, completa una variable de tabla para usar en la paginación). En cualquier caso, sin duda debería probar el impacto que esto tiene en cualquier carga de trabajo en la que planee introducir el indicador de seguimiento o recompilaciones explícitas.
TVP y tipos de mesa
También tenía curiosidad sobre cómo afectaría esto a los tipos de tablas y si veríamos alguna mejora en la cardinalidad de los TVP, donde existe este mismo síntoma. Así que creé un tipo de tabla simple que imita la variable de tabla en uso hasta el momento:
USE MyTestDB; GO CREATE TYPE dbo.t AS TABLE ( id INT PRIMARY KEY );
Luego tomé el lote anterior y simplemente reemplacé DECLARE @t TABLE(id INT PRIMARY KEY); con DECLARE @t dbo.t; – todo lo demás permaneció exactamente igual. Ejecuté los mismos tres lotes y esto es lo que vi:

Comparación de estimaciones y datos reales entre el comportamiento predeterminado, opción de recompilación y marca de seguimiento 2453
Así que sí, parece que la marca de seguimiento funciona exactamente de la misma manera con los TVP:las recompilaciones generan nuevas estimaciones para el optimizador cuando el recuento de filas supera el umbral de recompilación y se omiten cuando el recuento de filas está "lo suficientemente cerca".
Pros, contras y advertencias
Una ventaja de la marca de seguimiento es que puede evitar algunos vuelve a compilar y aún ve la cardinalidad de la tabla, siempre que espere que el número de filas en la variable de la tabla sea estable o no observe desviaciones significativas del plan debido a la cardinalidad variable. Otra es que puede habilitarlo globalmente o a nivel de sesión y no tener que introducir sugerencias de recompilación en todas sus consultas. Y, por último, al menos en el caso en que la cardinalidad de la variable de la tabla fuera estable, las estimaciones adecuadas generaron un mejor rendimiento que el valor predeterminado y también un mejor rendimiento que el uso de la opción de recompilación:todas esas compilaciones sin duda pueden sumarse.
También hay algunas desventajas, por supuesto. Uno que mencioné anteriormente es el que se compara con OPTION (RECOMPILE) se pierde ciertas optimizaciones, como la incrustación de parámetros. Otra es que la marca de rastreo no tendrá el impacto esperado en los planes triviales. Y una que descubrí en el camino es que usar QUERYTRACEON la sugerencia para hacer cumplir el indicador de seguimiento en el nivel de consulta no funciona; por lo que puedo decir, el indicador de seguimiento debe estar en su lugar cuando se crea y / o completa la variable de tabla o TVP para que el optimizador vea la cardinalidad arriba 1.
Tenga en cuenta que ejecutar el indicador de seguimiento globalmente presenta la posibilidad de regresiones del plan de consulta a cualquier consulta que involucre una variable de tabla (razón por la cual esta función se introdujo bajo un indicador de seguimiento en primer lugar), así que asegúrese de probar toda su carga de trabajo no importa cómo use la marca de rastreo. Además, cuando esté probando este comportamiento, hágalo en una base de datos de usuario; algunas de las optimizaciones y simplificaciones que normalmente espera que ocurran simplemente no ocurren cuando el contexto se establece en tempdb, por lo que cualquier comportamiento que observe allí puede no ser consistente cuando mueva el código y la configuración a una base de datos de usuario.
Conclusión
Si usa variables de tabla o TVP con un número de filas grande pero relativamente constante, puede que le resulte beneficioso habilitar este indicador de seguimiento para ciertos lotes o procedimientos a fin de obtener una cardinalidad de tabla precisa sin forzar manualmente una recompilación en consultas individuales. También puede usar el indicador de seguimiento en el nivel de instancia, lo que afectará a todas las consultas. Pero como cualquier cambio, en cualquier caso, deberá ser diligente para probar el rendimiento de toda su carga de trabajo, buscar explícitamente cualquier regresión y asegurarse de que desea el comportamiento de la marca de seguimiento porque puede confiar en la estabilidad de su variable de tabla. número de filas.
Me alegra ver que se agregó el indicador de seguimiento a SQL Server 2014, pero sería mejor si se convirtiera en el comportamiento predeterminado. No es que haya una ventaja significativa en el uso de variables de tablas grandes sobre tablas #temp grandes, pero sería bueno ver más paridad entre estos dos tipos de estructuras temporales que podrían dictarse a un nivel superior. Cuanta más paridad tengamos, menos personas tendrán que deliberar sobre cuál deben usar (o al menos tendrán menos criterios para considerar al elegir). Martin Smith tiene una excelente sesión de preguntas y respuestas en dba.stackexchange que probablemente ahora debe actualizarse:¿Cuál es la diferencia entre una tabla temporal y una variable de tabla en SQL Server?
Nota importante
Si va a instalar SQL Server 2012 Service Pack 2 (ya sea para hacer uso de este indicador de seguimiento o no), consulte también mi publicación sobre una regresión en SQL Server 2012 y 2014 que puede, en casos excepcionales, introducir posible pérdida o corrupción de datos durante las reconstrucciones de índices en línea. Hay actualizaciones acumulativas disponibles para SQL Server 2012 SP1 y SP2 y también para SQL Server 2014. No habrá solución para la rama RTM 2012.
Más pruebas
Tengo otras cosas en mi lista para probar. Por un lado, me gustaría ver si este indicador de seguimiento tiene algún efecto en los tipos de tablas en memoria en SQL Server 2014. También voy a demostrar sin lugar a dudas que el indicador de seguimiento 2453 utiliza el mismo umbral de recompilación para la tabla variables y TVP como lo hace con las tablas #temp.