El año pasado, publiqué un consejo llamado Mejorar la eficiencia de SQL Server cambiando a INSTEAD OF Triggers.
La gran razón por la que tiendo a preferir un disparador EN LUGAR DE, particularmente en los casos en los que espero muchas violaciones de la lógica de negocios, es que parece intuitivo que sería más barato prevenir una acción por completo, que seguir adelante y llevarla a cabo (y ¡regístrelo!), solo para usar un disparador DESPUÉS para eliminar las filas infractoras (o revertir toda la operación). Los resultados que se muestran en ese consejo demostraron que, de hecho, este era el caso, y sospecho que serían aún más pronunciados con más índices no agrupados afectados por la operación.
Sin embargo, eso estaba en un disco lento y en un CTP temprano de SQL Server 2014. Al preparar una diapositiva para una nueva presentación que haré este año sobre activadores, descubrí que en una versión más reciente de SQL Server 2014:combinado con hardware actualizado:fue un poco más complicado demostrar el mismo delta en el rendimiento entre un disparador DESPUÉS y EN LUGAR DE. Así que me dispuse a descubrir por qué, aunque inmediatamente supe que esto iba a ser más trabajo del que había hecho para una sola diapositiva.
Una cosa que quiero mencionar es que los disparadores pueden usar tempdb de diferentes maneras, y esto podría explicar algunas de estas diferencias. Un activador DESPUÉS utiliza el almacén de versiones para las pseudotablas insertadas y eliminadas, mientras que un activador INSTEAD OF hace una copia de estos datos en una tabla de trabajo interna. La diferencia es sutil, pero vale la pena señalarla.
Las Variables
Voy a probar varios escenarios, incluyendo:
- Tres disparadores diferentes:
- Un activador DESPUÉS que elimina filas específicas que fallan
- Un activador DESPUÉS que revierte toda la transacción si alguna fila falla
- Un disparador INSTEAD OF que solo inserta las filas que pasan
- Diferentes modelos de recuperación y configuraciones de aislamiento de instantáneas:
- COMPLETO con INSTANTÁNEA habilitado
- COMPLETO con INSTANTÁNEA deshabilitado
- SIMPLE con INSTANTÁNEA habilitado
- SIMPLE con INSTANTÁNEA deshabilitado
- Diferentes diseños de disco*:
- Datos en SSD, inicie sesión en HDD de 7200 RPM
- Datos en SSD, inicie sesión en SSD
- Datos en HDD de 7200 RPM, inicie sesión en SSD
- Datos en HDD de 7200 RPM, inicie sesión en HDD de 7200 RPM
- Distintas tasas de error:
- 10 %, 25 % y 50 % de índice de errores en:
- Inserción de lote único de 20 000 filas
- 10 lotes de 2000 filas
- 100 lotes de 200 filas
- 1000 lotes de 20 filas
- 20 000 inserciones individuales
*
tempdbes un único archivo de datos en un disco lento de 7200 RPM. Esto es intencional y está destinado a amplificar cualquier cuello de botella causado por los diversos usos detempdb. Planeo volver a visitar esta prueba en algún momento cuandotempdbestá en un SSD más rápido. - 10 %, 25 % y 50 % de índice de errores en:
¡Está bien, TL;DR ya!
Si solo quieres saber los resultados, salta hacia abajo. Todo lo que hay en el medio es solo antecedentes y una explicación de cómo configuré y ejecuté las pruebas. No me rompe el corazón que no todo el mundo esté interesado en todas las minucias.
El escenario
Para este conjunto particular de pruebas, el escenario de la vida real es aquel en el que un usuario elige un nombre de pantalla y el activador está diseñado para detectar casos en los que el nombre elegido infringe algunas reglas. Por ejemplo, no puede ser ninguna variación de "ninny-muggins" (ciertamente puedes usar tu imaginación aquí).
Creé una tabla con 20 000 nombres de usuario únicos:
USE model; GO -- 20,000 distinct, good Names ;WITH distinct_Names AS ( SELECT Name FROM sys.all_columns UNION SELECT Name FROM sys.all_objects ) SELECT TOP (20000) Name INTO dbo.GoodNamesSource FROM ( SELECT Name FROM distinct_Names UNION SELECT Name + 'x' FROM distinct_Names UNION SELECT Name + 'y' FROM distinct_Names UNION SELECT Name + 'z' FROM distinct_Names ) AS x; CREATE UNIQUE CLUSTERED INDEX x ON dbo.GoodNamesSource(Name);
Luego creé una tabla que sería la fuente de mis "nombres traviesos" para verificar. En este caso es solo ninny-muggins-00001 a través de ninny-muggins-10000 :
USE model;
GO
CREATE TABLE dbo.NaughtyUserNames
(
Name NVARCHAR(255) PRIMARY KEY
);
GO
-- 10,000 "bad" names
INSERT dbo.NaughtyUserNames(Name)
SELECT N'ninny-muggins-' + RIGHT(N'0000' + RTRIM(n),5)
FROM
(
SELECT TOP (10000) n = ROW_NUMBER() OVER (ORDER BY Name)
FROM dbo.GoodNamesSource
) AS x;
Creé estas tablas en el model base de datos para que cada vez que cree una base de datos, exista localmente, y planeo crear muchas bases de datos para probar la matriz de escenarios mencionada anteriormente (en lugar de simplemente cambiar la configuración de la base de datos, borrar el registro, etc.). Tenga en cuenta que si crea objetos en el modelo con fines de prueba, asegúrese de eliminar esos objetos cuando haya terminado.
Aparte, voy a dejar intencionalmente las infracciones de claves y otros errores de manejo fuera de esto, haciendo la suposición ingenua de que el nombre elegido se verifica por su singularidad mucho antes de que se intente la inserción, pero dentro de la misma transacción (al igual que el la verificación contra la tabla de nombres traviesos podría haberse hecho por adelantado).
Para respaldar esto, también creé las siguientes tres tablas casi idénticas en model , con fines de aislamiento de prueba:
USE model; GO -- AFTER (rollback) CREATE TABLE dbo.UserNames_After_Rollback ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Rollback(DateCreated) INCLUDE(Name); -- AFTER (delete) CREATE TABLE dbo.UserNames_After_Delete ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Delete(DateCreated) INCLUDE(Name); -- INSTEAD CREATE TABLE dbo.UserNames_Instead ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_Instead(DateCreated) INCLUDE(Name); GO
Y los tres disparadores siguientes, uno para cada tabla:
USE model;
GO
-- AFTER (rollback)
CREATE TRIGGER dbo.trUserNames_After_Rollback
ON dbo.UserNames_After_Rollback
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
IF EXISTS
(
SELECT 1 FROM inserted AS i
WHERE EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
)
)
BEGIN
ROLLBACK TRANSACTION;
END
END
GO
-- AFTER (delete)
CREATE TRIGGER dbo.trUserNames_After_Delete
ON dbo.UserNames_After_Delete
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
DELETE d
FROM inserted AS i
INNER JOIN dbo.NaughtyUserNames AS n
ON i.Name = n.Name
INNER JOIN dbo.UserNames_After_Delete AS d
ON i.UserID = d.UserID;
END
GO
-- INSTEAD
CREATE TRIGGER dbo.trUserNames_Instead
ON dbo.UserNames_Instead
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserNames_Instead(Name)
SELECT i.Name
FROM inserted AS i
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
);
END
GO Probablemente desee considerar un manejo adicional para notificar al usuario que su elección se revirtió o se ignoró, pero esto también se omite por simplicidad.
La configuración de la prueba
Creé datos de muestra que representan las tres tasas de falla que quería probar, cambié el 10 por ciento a 25 y luego a 50, y agregué estas tablas también a model :
USE model;
GO
DECLARE @pct INT = 10, @cap INT = 20000;
-- change this ----^^ to 25 and 50
DECLARE @good INT = @cap - (@cap*(@pct/100.0));
SELECT Name, rn = ROW_NUMBER() OVER (ORDER BY NEWID())
INTO dbo.Source10Percent FROM
-- change this ^^ to 25 and 50
(
SELECT Name FROM
(
SELECT TOP (@good) Name FROM dbo.GoodNamesSource ORDER BY NEWID()
) AS g
UNION ALL
SELECT Name FROM
(
SELECT TOP (@cap-@good) Name FROM dbo.NaughtyUserNames ORDER BY NEWID()
) AS b
) AS x;
CREATE UNIQUE CLUSTERED INDEX x ON dbo.Source10Percent(rn);
-- and here as well -------------------------^^ Cada tabla tiene 20 000 filas, con una combinación diferente de nombres que pasarán y fallarán, y la columna de número de fila facilita la división de datos en diferentes tamaños de lote para diferentes pruebas, pero con tasas de falla repetibles para todas las pruebas.
Por supuesto que necesitamos un lugar para capturar los resultados. Elegí usar una base de datos separada para esto, ejecutando cada prueba varias veces, simplemente capturando la duración.
CREATE DATABASE ControlDB; GO USE ControlDB; GO CREATE TABLE dbo.Tests ( TestID INT, DiskLayout VARCHAR(15), RecoveryModel VARCHAR(6), TriggerType VARCHAR(14), [snapshot] VARCHAR(3), FailureRate INT, [sql] NVARCHAR(MAX) ); CREATE TABLE dbo.TestResults ( TestID INT, BatchDescription VARCHAR(15), Duration INT );
Llené el dbo.Tests table con el siguiente script, de modo que pudiera ejecutar diferentes partes para configurar las cuatro bases de datos para que coincidan con los parámetros de prueba actuales. Tenga en cuenta que D:\ es un SSD, mientras que G:\ es un disco de 7200 RPM:
TRUNCATE TABLE dbo.Tests;
TRUNCATE TABLE dbo.TestResults;
;WITH d AS
(
SELECT DiskLayout FROM (VALUES
('DataSSD_LogHDD'),
('DataSSD_LogSSD'),
('DataHDD_LogHDD'),
('DataHDD_LogSSD')) AS d(DiskLayout)
),
t AS
(
SELECT TriggerType FROM (VALUES
('After_Delete'),
('After_Rollback'),
('Instead')) AS t(TriggerType)
),
m AS
(
SELECT RecoveryModel = 'FULL'
UNION ALL SELECT 'SIMPLE'
),
s AS
(
SELECT IsSnapshot = 0
UNION ALL SELECT 1
),
p AS
(
SELECT FailureRate = 10
UNION ALL SELECT 25
UNION ALL SELECT 50
)
INSERT ControlDB.dbo.Tests
(
TestID,
DiskLayout,
RecoveryModel,
TriggerType,
IsSnapshot,
FailureRate,
Command
)
SELECT
TestID = ROW_NUMBER() OVER
(
ORDER BY d.DiskLayout, t.TriggerType, m.RecoveryModel, s.IsSnapshot, p.FailureRate
),
d.DiskLayout,
m.RecoveryModel,
t.TriggerType,
s.IsSnapshot,
p.FailureRate,
[sql]= N'SET NOCOUNT ON;
CREATE DATABASE ' + QUOTENAME(d.DiskLayout)
+ N' ON (name = N''data'', filename = N''' + CASE d.DiskLayout
WHEN 'DataSSD_LogHDD' THEN N'D:\data\data1.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data1.ldf'');'
WHEN 'DataSSD_LogSSD' THEN N'D:\data\data2.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data2.ldf'');'
WHEN 'DataHDD_LogHDD' THEN N'G:\data\data3.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data3.ldf'');'
WHEN 'DataHDD_LogSSD' THEN N'G:\data\data4.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data4.ldf'');' END
+ '
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET RECOVERY ' + m.RecoveryModel + ';'';'
+ CASE WHEN s.IsSnapshot = 1 THEN
'
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET ALLOW_SNAPSHOT_ISOLATION ON;'';
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET READ_COMMITTED_SNAPSHOT ON;'';'
ELSE '' END
+ '
DECLARE @d DATETIME2(7), @i INT, @LoopID INT, @loops INT, @perloop INT;
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT LoopID, loops, perloop FROM dbo.Loops;
OPEN c;
FETCH c INTO @LoopID, @loops, @perloop;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC sp_executesql N''TRUNCATE TABLE '
+ QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + ';'';
SELECT @d = SYSDATETIME(), @i = 1;
WHILE @i <= @loops
BEGIN
BEGIN TRY
INSERT ' + QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + '(Name)
SELECT Name FROM ' + QUOTENAME(d.DiskLayout) + '.dbo.Source' + RTRIM(p.FailureRate) + 'Percent
WHERE rn > (@i-1)*@perloop AND rn <= @i*@perloop;
END TRY
BEGIN CATCH
SET @TestID = @TestID;
END CATCH
SET @i += 1;
END
INSERT ControlDB.dbo.TestResults(TestID, LoopID, Duration)
SELECT @TestID, @LoopID, DATEDIFF(MILLISECOND, @d, SYSDATETIME());
FETCH c INTO @LoopID, @loops, @perloop;
END
CLOSE c;
DEALLOCATE c;
DROP DATABASE ' + QUOTENAME(d.DiskLayout) + ';'
FROM d, t, m, s, p; -- implicit CROSS JOIN! Do as I say, not as I do! :-) Entonces fue sencillo ejecutar todas las pruebas varias veces:
USE ControlDB;
GO
SET NOCOUNT ON;
DECLARE @TestID INT, @Command NVARCHAR(MAX), @msg VARCHAR(32);
DECLARE d CURSOR LOCAL FAST_FORWARD FOR
SELECT TestID, Command
FROM ControlDB.dbo.Tests ORDER BY TestID;
OPEN d;
FETCH d INTO @TestID, @Command;
WHILE @@FETCH_STATUS <> -1
BEGIN
SET @msg = 'Starting ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
EXEC sp_executesql @Command, N'@TestID INT', @TestID;
SET @msg = 'Finished ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
FETCH d INTO @TestID, @Command;
END
CLOSE d;
DEALLOCATE d;
GO 10
En mi sistema, esto tomó cerca de 6 horas, así que prepárate para dejar que esto siga su curso sin interrupciones. Además, asegúrese de no tener conexiones activas o ventanas de consulta abiertas contra el model base de datos; de lo contrario, puede recibir este error cuando el script intenta crear una base de datos:
No se pudo obtener el bloqueo exclusivo en la base de datos 'modelo'. Vuelva a intentar la operación más tarde.
Resultados
Hay muchos puntos de datos para mirar (y todas las consultas utilizadas para derivar los datos se mencionan en el Apéndice). Tenga en cuenta que cada duración promedio indicada aquí supera las 10 pruebas y está insertando un total de 100 000 filas en la tabla de destino.
Gráfico 1:Agregados generales
El primer gráfico muestra los agregados generales (duración promedio) para las diferentes variables de forma aislada (por lo tanto, *todas* las pruebas usan un disparador DESPUÉS que elimina, *todas* las pruebas usan un disparador DESPUÉS que revierte, etc.).
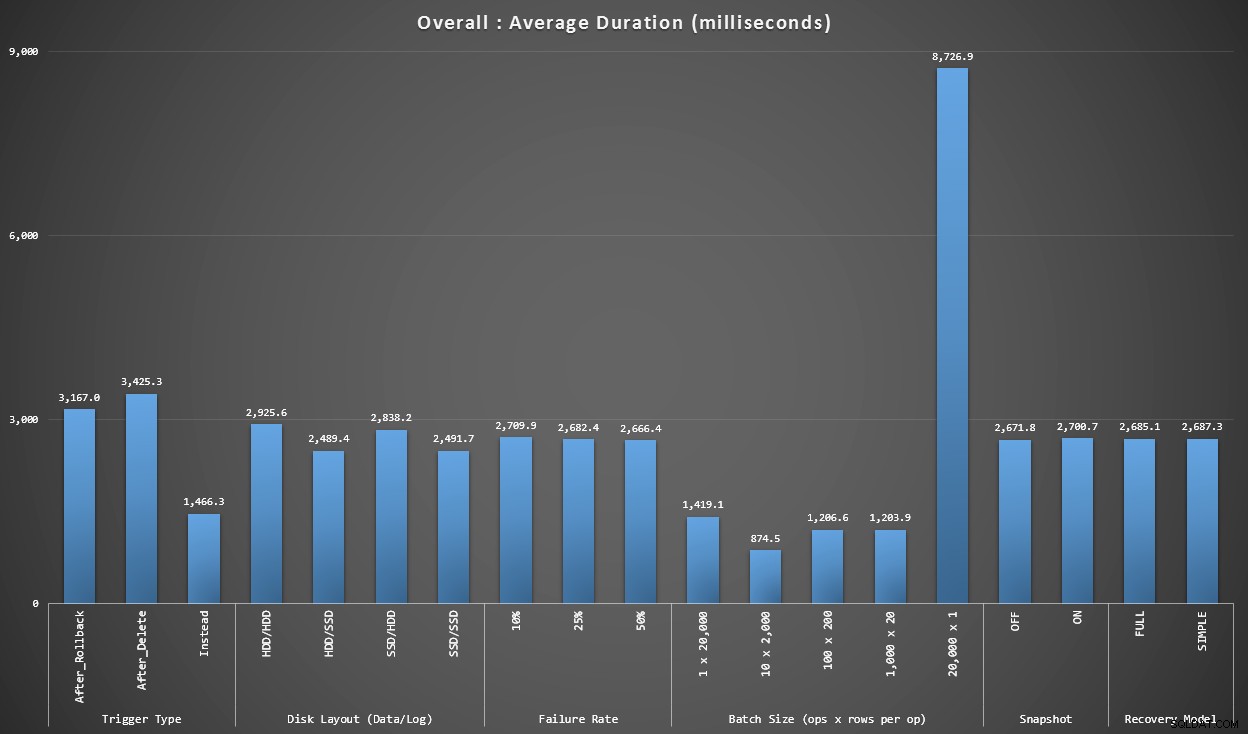
Duración promedio, en milisegundos, para cada variable aisladamente
Algunas cosas saltan a la vista de inmediato:
- El activador INSTEAD OF aquí es el doble de rápido que los dos activadores DESPUÉS.
- Tener el registro de transacciones en SSD marcó una pequeña diferencia. La ubicación del archivo de datos mucho menos.
- El lote de 20 000 inserciones singleton fue entre 7 y 8 veces más lento que cualquier otra distribución por lotes.
- La inserción de un solo lote de 20 000 filas fue más lenta que cualquiera de las distribuciones que no son de un solo elemento.
- La tasa de fallas, el aislamiento de instantáneas y el modelo de recuperación tuvieron poco o ningún impacto en el rendimiento.
Gráfico 2:los 10 mejores en general
Este gráfico muestra los 10 resultados más rápidos cuando se consideran todas las variables. Todos estos son disparadores INSTEAD OF donde falla el mayor porcentaje de filas (50%). Sorprendentemente, el más rápido (aunque no por mucho) tenía datos e inicio de sesión en el mismo HDD (no SSD). Aquí hay una combinación de diseños de disco y modelos de recuperación, pero los 10 tenían habilitado el aislamiento de instantáneas, y los 7 resultados principales involucraron el tamaño de lote de 10 x 2000 filas.
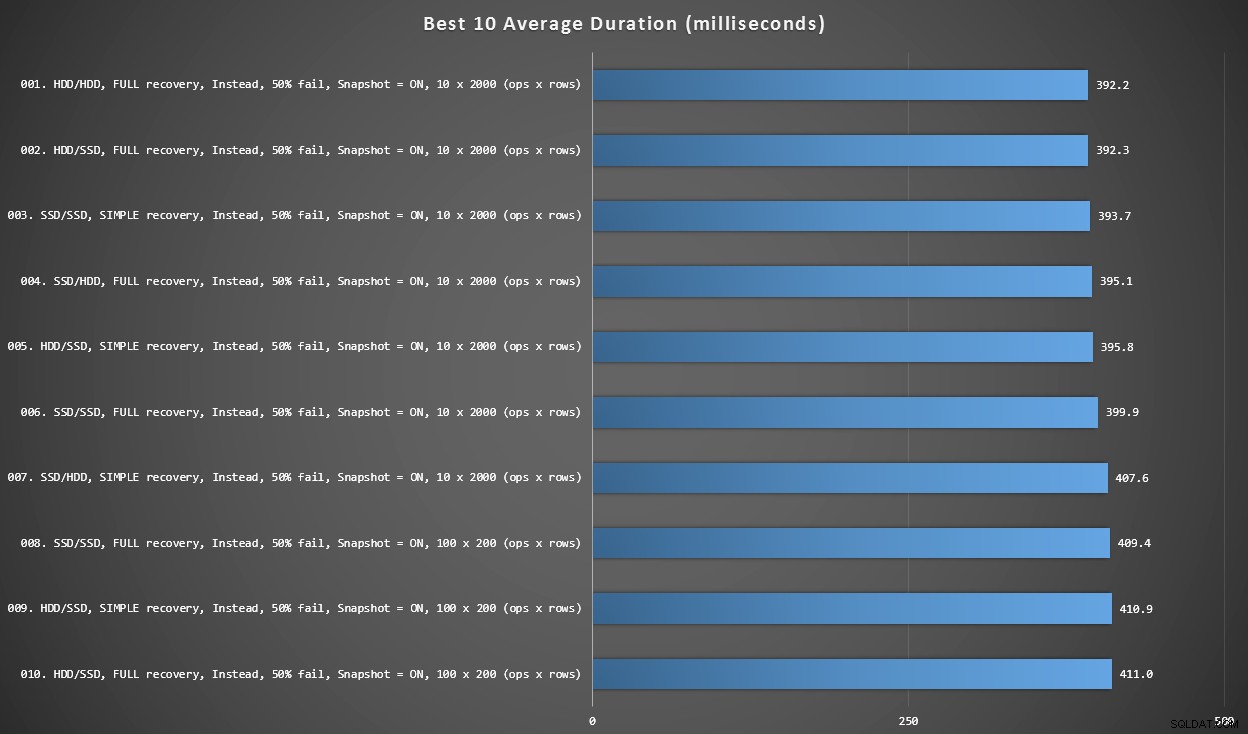
Las 10 mejores duraciones, en milisegundos, considerando cada variable
El disparador AFTER más rápido, una variante ROLLBACK con una tasa de fallas del 10 % en el tamaño de lote de 100 x 200 filas, llegó en la posición n.º 144 (806 ms).
Gráfico 3:los 10 peores en general
Este gráfico muestra los 10 resultados más lentos cuando se consideran todas las variables; todas son variantes DESPUÉS, todas involucran las 20,000 inserciones singleton, y todas tienen datos e inician sesión en el mismo HDD lento.
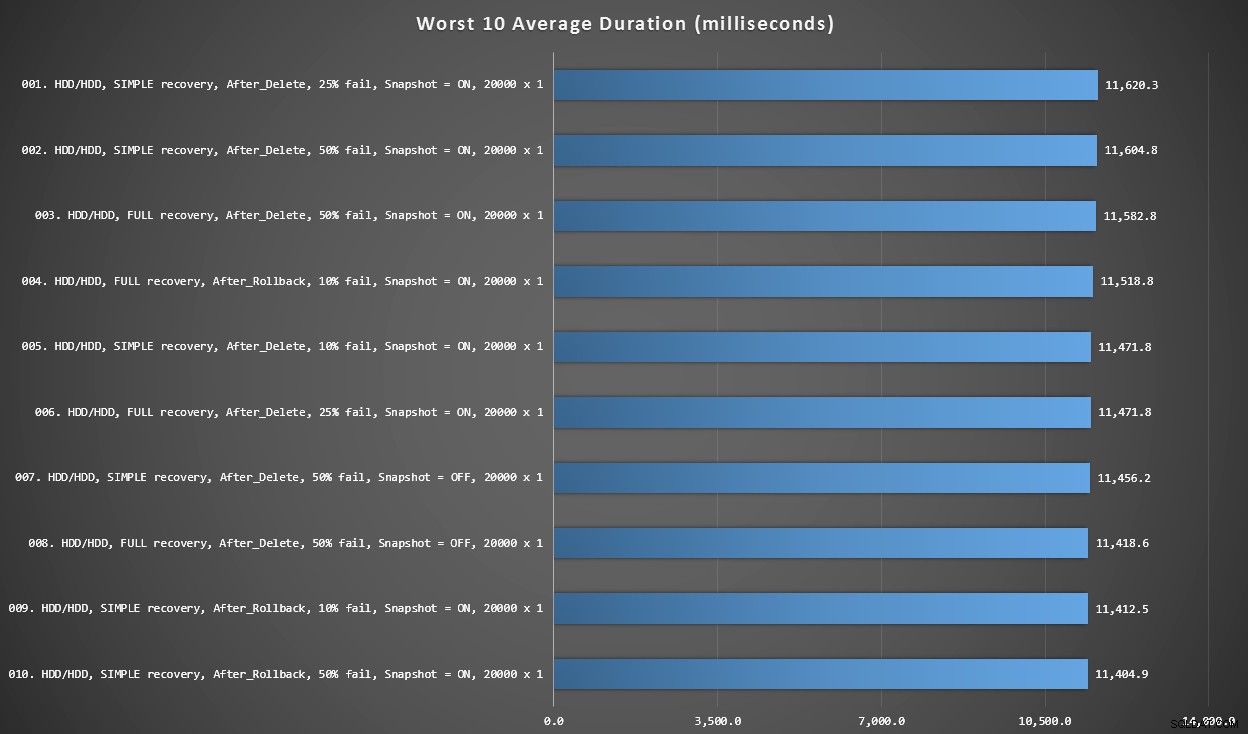
Las 10 peores duraciones, en milisegundos, considerando todas las variables
La prueba INSTEAD OF más lenta fue en la posición n.º 97, a 5680 ms, una prueba de inserción de 20 000 singleton en la que falla el 10 %. También es interesante observar que ni un solo disparador DESPUÉS que utilizó el tamaño de lote de inserción de 20 000 singleton obtuvo mejores resultados; de hecho, el peor resultado número 96 fue una prueba DESPUÉS (eliminación) que llegó a los 10 219 ms, casi el doble del siguiente resultado más lento.
Gráfico 4:tipo de disco de registro, inserciones Singleton
Los gráficos anteriores nos dan una idea aproximada de los principales puntos débiles, pero están demasiado ampliados o no lo suficiente. Este gráfico filtra datos basados en la realidad:en la mayoría de los casos, este tipo de operación será una inserción única. Pensé que lo desglosaría por tasa de error y el tipo de disco en el que se encuentra el registro, pero solo observe las filas donde el lote se compone de 20 000 inserciones individuales.
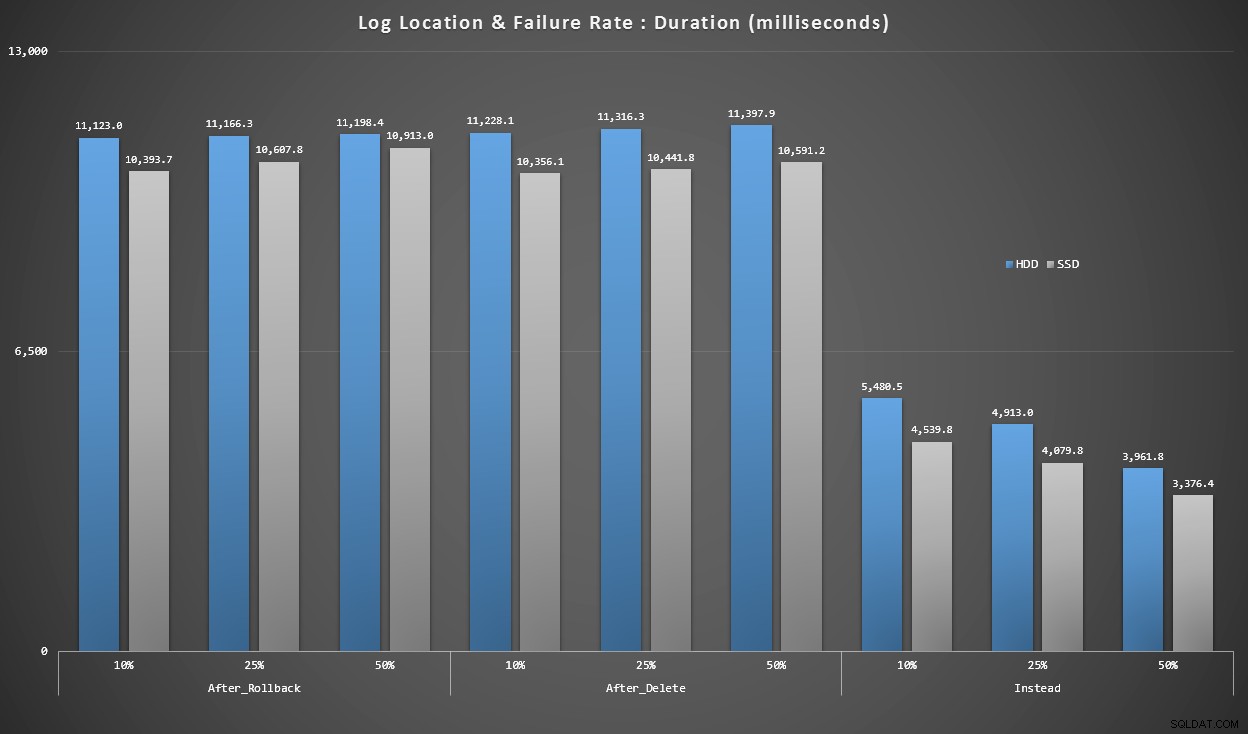
Duración, en milisegundos, agrupada por tasa de error y ubicación del registro, para 20.000 inserciones individuales
Aquí vemos que todos los desencadenantes DESPUÉS promedian en el rango de 10 a 11 segundos (dependiendo de la ubicación del registro), mientras que todos los desencadenantes EN LUGAR DE están muy por debajo de la marca de 6 segundos.
Conclusión
Hasta ahora, me parece claro que el activador INSTEAD OF es un ganador en la mayoría de los casos, en algunos casos más que en otros (por ejemplo, a medida que aumenta la tasa de fallas). Otros factores, como el modelo de recuperación, parecen tener un impacto mucho menor en el rendimiento general.
Si tiene otras ideas sobre cómo desglosar los datos, o desea una copia de los datos para realizar su propio rebanado y troceado, hágamelo saber. Si desea ayuda para configurar este entorno para que pueda ejecutar sus propias pruebas, también puedo ayudarlo con eso.
Si bien esta prueba muestra que definitivamente vale la pena considerar los disparadores INSTEAD OF, no es toda la historia. Literalmente junte estos disparadores usando la lógica que pensé que tenía más sentido para cada escenario, pero el código disparador, como cualquier declaración T-SQL, se puede ajustar para obtener planes óptimos. En una publicación de seguimiento, echaré un vistazo a una posible optimización que puede hacer que el activador DESPUÉS sea más competitivo.
Apéndice
Consultas utilizadas para la sección Resultados:
Gráfico 1:Agregados generales
SELECT RTRIM(l.loops) + ' x ' + RTRIM(l.perloop), AVG(r.Duration*1.0) FROM dbo.TestResults AS r INNER JOIN dbo.Loops AS l ON r.LoopID = l.LoopID GROUP BY RTRIM(l.loops) + ' x ' + RTRIM(l.perloop); SELECT t.IsSnapshot, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.IsSnapshot; SELECT t.RecoveryModel, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.RecoveryModel; SELECT t.DiskLayout, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.DiskLayout; SELECT t.TriggerType, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.TriggerType; SELECT t.FailureRate, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.FailureRate;
Gráficos 2 y 3:10 mejores y peores
;WITH src AS
(
SELECT DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
Batch = RTRIM(l.loops) + ' x ' + RTRIM(l.perloop),
Duration = AVG(Duration*1.0)
FROM dbo.Tests AS t
INNER JOIN dbo.TestResults AS tr
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON tr.LoopID = l.LoopID
GROUP BY DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
RTRIM(l.loops) + ' x ' + RTRIM(l.perloop)
),
agg AS
(
SELECT label = REPLACE(REPLACE(DiskLayout,'Data',''),'_Log','/')
+ ', ' + RecoveryModel + ' recovery, ' + TriggerType
+ ', ' + RTRIM(FailureRate) + '% fail'
+ ', Snapshot = ' + CASE IsSnapshot WHEN 1 THEN 'ON' ELSE 'OFF' END
+ ', ' + Batch + ' (ops x rows)',
best10 = ROW_NUMBER() OVER (ORDER BY Duration),
worst10 = ROW_NUMBER() OVER (ORDER BY Duration DESC),
Duration
FROM src
)
SELECT grp, label, Duration FROM
(
SELECT TOP (20) grp = 'best', label = RIGHT('0' + RTRIM(best10),2) + '. ' + label, Duration
FROM agg WHERE best10 <= 10
ORDER BY best10 DESC
UNION ALL
SELECT TOP (20) grp = 'worst', label = RIGHT('0' + RTRIM(worst10),2) + '. ' + label, Duration
FROM agg WHERE worst10 <= 10
ORDER BY worst10 DESC
) AS b
ORDER BY grp; Gráfico 4:tipo de disco de registro, inserciones Singleton
;WITH x AS
(
SELECT
TriggerType,FailureRate,
LogLocation = RIGHT(DiskLayout,3),
Duration = AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON l.LoopID = tr.LoopID
WHERE l.loops = 20000
GROUP BY RIGHT(DiskLayout,3), FailureRate, TriggerType
)
SELECT TriggerType, FailureRate,
HDDDuration = MAX(CASE WHEN LogLocation = 'HDD' THEN Duration END),
SSDDuration = MAX(CASE WHEN LogLocation = 'SSD' THEN Duration END)
FROM x
GROUP BY TriggerType, FailureRate
ORDER BY TriggerType, FailureRate;