Lectura comprometida es el segundo más débil de los cuatro niveles de aislamiento definidos por el estándar SQL. No obstante, es el nivel de aislamiento predeterminado para muchos motores de bases de datos, incluido SQL Server. Esta publicación de una serie sobre los niveles de aislamiento y las propiedades ACID de las transacciones analiza las garantías lógicas y físicas que realmente proporciona el aislamiento de lectura confirmada.
Garantías Lógicas
El estándar SQL requiere que una transacción que se ejecute con aislamiento de lectura confirmada solo lea commited datos. Expresa este requisito al prohibir el fenómeno de concurrencia conocido como lectura sucia. Una lectura sucia ocurre cuando una transacción lee datos escritos por otra transacción, antes de que se complete la segunda transacción. Otra forma de expresar esto es decir que se produce una lectura sucia cuando una transacción lee datos no confirmados.
El estándar también menciona que una transacción que se ejecuta en el aislamiento de lectura confirmada podría encontrarse con los fenómenos de concurrencia conocidos como lecturas no repetibles. y fantasmas . Aunque muchos libros explican estos fenómenos en términos de que una transacción puede ver elementos de datos nuevos o modificados si los datos se vuelven a leer posteriormente, esta explicación puede reforzar el concepto erróneo que los fenómenos de concurrencia solo pueden ocurrir dentro de una transacción explícita que contiene múltiples declaraciones. Esto no es así. Una sola declaración sin una transacción explícita es igual de vulnerable a los fenómenos fantasma y de lectura no repetible, como veremos en breve.
Eso es prácticamente todo lo que el estándar tiene que decir sobre el tema del aislamiento de lectura confirmada. A primera vista, leer solo los datos comprometidos parece una garantía bastante buena de comportamiento sensato, pero como siempre, el problema está en los detalles. Tan pronto como empiece a buscar posibles lagunas en esta definición, se vuelve demasiado fácil encontrar instancias en las que nuestras transacciones de lectura confirmada podrían no producir los resultados que podríamos esperar. Nuevamente, discutiremos esto con más detalle en un momento o dos.
Distintas implementaciones físicas
Hay al menos dos cosas que significan que el comportamiento observado del nivel de aislamiento de confirmación de lectura puede ser bastante diferente en diferentes motores de bases de datos. En primer lugar, el requisito estándar de SQL de leer solo los datos confirmados no significa necesariamente que los datos confirmados leídos por una transacción serán los más recientes datos confirmados.
Un motor de base de datos puede leer una versión confirmada de una fila desde cualquier punto en el pasado y seguir cumpliendo con la definición estándar de SQL. Varios productos de base de datos populares implementan el aislamiento de confirmación de lectura de esta manera. Los resultados de las consultas obtenidos con esta implementación de aislamiento de lectura confirmada pueden estar arbitrariamente desactualizados. , en comparación con el estado confirmado actual de la base de datos. Cubriremos este tema según se aplica a SQL Server en la próxima publicación de la serie.
La segunda cosa sobre la que quiero llamar su atención es que la definición estándar de SQL no impedir que una implementación en particular proporcione protecciones de efecto de concurrencia adicionales más allá de prevenir lecturas sucias . El estándar solo especifica que no se permiten lecturas sucias, no requiere que se deban permitir otros fenómenos de concurrencia en cualquier nivel de aislamiento dado.
Para aclarar este segundo punto, un motor de base de datos compatible con los estándares podría implementar todos los niveles de aislamiento usando serializable comportamiento si así lo desea. Algunos de los principales motores de bases de datos comerciales también proporcionan una implementación de lectura confirmada que va mucho más allá de la simple prevención de lecturas sucias (aunque ninguno llega tan lejos como para proporcionar un aislamiento completo en el ACID sentido de la palabra).
Además de eso, para varios productos populares, leer comprometido el aislamiento es el más bajo nivel de aislamiento disponible; sus implementaciones de lectura no comprometida el aislamiento son exactamente los mismos que los de lectura confirmada. Esto está permitido por el estándar, pero este tipo de diferencias agregan complejidad a la ya difícil tarea de migrar código de una plataforma a otra. Cuando se habla de los comportamientos de un nivel de aislamiento, generalmente también es importante especificar la plataforma en particular.
Hasta donde yo sé, SQL Server es único entre los principales motores de bases de datos comerciales al proporcionar dos implementaciones del nivel de aislamiento de lectura comprometida, cada una con comportamientos físicos muy diferentes. Esta publicación cubre el primero de estos, bloqueo lectura confirmada.
Lectura confirmada de bloqueo de SQL Server
Si la opción de base de datos READ_COMMITTED_SNAPSHOT está OFF , SQL Server usa un bloqueo implementación del nivel de aislamiento de lectura confirmada, donde se toman bloqueos compartidos para evitar que una transacción simultánea modifique los datos al mismo tiempo, porque la modificación requeriría un bloqueo exclusivo, que no es compatible con el bloqueo compartido.
La diferencia clave entre el bloqueo de lectura confirmada de SQL Server y el bloqueo de lectura repetible (que también toma bloqueos compartidos al leer datos) es que la lectura confirmada libera el bloqueo compartido lo antes posible , mientras que la lectura repetible mantiene estos bloqueos hasta el final de la transacción adjunta.
Cuando el bloqueo de lectura confirmada adquiere bloqueos en la granularidad de fila, el bloqueo compartido tomado en una fila se libera. cuando se toma un bloqueo compartido en la siguiente fila . En la granularidad de la página, el bloqueo de la página compartida se libera cuando se lee la primera fila de la página siguiente, y así sucesivamente. A menos que se proporcione una sugerencia de granularidad de bloqueo con la consulta, el motor de la base de datos decide con qué nivel de granularidad empezar. Tenga en cuenta que las sugerencias de granularidad solo se tratan como sugerencias por parte del motor, es posible que aún se tome inicialmente un bloqueo menos granular que el solicitado. Los bloqueos también pueden escalarse durante la ejecución desde el nivel de fila o página hasta el nivel de partición o tabla, según la configuración del sistema.
El punto importante aquí es que los bloqueos compartidos generalmente se mantienen solo durante un tiempo muy corto. mientras se ejecuta la instrucción. Para abordar explícitamente un concepto erróneo común, el bloqueo de lectura confirmada no mantener bloqueos compartidos hasta el final de la instrucción.
Bloqueo de comportamientos comprometidos de lectura
Los bloqueos compartidos a corto plazo utilizados por la implementación de confirmación de lectura de bloqueo de SQL Server proporcionan muy pocas de las garantías que los programadores de T-SQL suelen esperar de una transacción de base de datos. En particular, una declaración que se ejecuta bajo el bloqueo read commit aislamiento:
- Puede encontrar la misma fila varias veces;
- Puede omitir algunas filas por completo; y
- ¿no proporcionar una vista de un punto en el tiempo de los datos
Esa lista puede parecer más una descripción de los comportamientos extraños que podrías asociar más con el uso de NOLOCK sugerencias, pero todas estas cosas realmente pueden suceder, y suceden cuando se usa el bloqueo de aislamiento de confirmación de lectura.
Ejemplo
Considere la tarea simple de contar las filas en una tabla, usando la consulta obvia de una sola declaración. Bajo el bloqueo de aislamiento de confirmación de lectura con granularidad de bloqueo de filas, nuestra consulta tomará un bloqueo compartido en la primera fila, lo leerá, liberará el bloqueo compartido, pasará a la siguiente fila y así sucesivamente hasta que llegue al final de la estructura. está leyendo. Por el bien de este ejemplo, supongamos que nuestra consulta está leyendo un índice b-tree en orden de clave ascendente (aunque también podría usar un orden descendente o cualquier otra estrategia).
Dado que solo una fila está compartido bloqueado en un momento dado, es claramente posible que las transacciones simultáneas modifiquen las filas desbloqueadas en el índice que atraviesa nuestra consulta. Si estas modificaciones simultáneas cambian los valores de la clave del índice, harán que las filas se muevan dentro de la estructura del índice. Con esa posibilidad en mente, el siguiente diagrama ilustra dos escenarios problemáticos que pueden ocurrir:
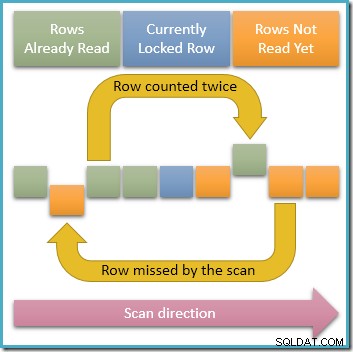
La flecha superior muestra una fila que ya hemos contado y cuya clave de índice se modifica al mismo tiempo para que la fila se mueva por delante de la posición de escaneo actual en el índice, lo que significa que la fila se contará dos veces . La segunda flecha muestra una fila que nuestro escaneo aún no ha encontrado moviéndose detrás de la posición de escaneo, lo que significa que la fila no se contará. en absoluto.
No es una vista puntual
La sección anterior mostró cómo el bloqueo de lectura confirmada puede perder datos por completo o contar el mismo elemento varias veces (más de dos veces, si no tenemos suerte). La tercera viñeta en la lista de comportamientos inesperados indicó que bloquear la lectura confirmada tampoco proporciona una vista puntual de los datos.
El razonamiento detrás de esa declaración ahora debería ser fácil de ver. Nuestra consulta de conteo, por ejemplo, podría leer fácilmente los datos que se insertaron mediante transacciones simultáneas después de que nuestra consulta comenzó a ejecutarse. Del mismo modo, los datos que ve nuestra consulta pueden verse modificados por la actividad simultánea después de que se inicie nuestra consulta y antes de que se complete. Finalmente, los datos que hemos leído y contado pueden ser eliminados por una transacción simultánea antes de que se complete nuestra consulta.
Claramente, los datos vistos por una declaración o transacción que se ejecuta bajo el aislamiento de confirmación de lectura bloqueada corresponde a ningún estado único de la base de datos en cualquier momento en el tiempo . Los datos que encontramos bien podrían provenir de una variedad de puntos diferentes en el tiempo, con el único factor común que cada elemento representaba el último valor comprometido de esos datos en el momento en que se leyeron (aunque bien podría haber cambiado o desaparecido desde entonces).
¿Qué tan serios son estos problemas?
Todo esto puede parecer un estado de cosas bastante confuso si está acostumbrado a pensar en sus consultas de una sola declaración y transacciones explícitas como si se ejecutaran lógicamente de forma instantánea, o como si se ejecutaran en un único estado de punto en el tiempo comprometido de la base de datos cuando se usa el nivel de aislamiento predeterminado de SQL Server. Ciertamente no encaja bien con el concepto de aislamiento en el sentido ACID.
Dada la aparente debilidad de las garantías proporcionadas al bloquear el aislamiento de confirmación de lectura, es posible que comience a preguntarse cómo cualquiera de su código T-SQL de producción ha funcionado correctamente alguna vez. Por supuesto, podemos aceptar que usar un nivel de aislamiento por debajo del serializable significa que renunciamos al aislamiento total de transacciones ACID a cambio de otros beneficios potenciales, pero ¿qué tan serios podemos esperar que estos problemas sean en la práctica?
Filas faltantes y contadas dos veces
Estos dos primeros problemas se basan esencialmente en la actividad simultánea que cambia las claves. en una estructura de índice que actualmente estamos escaneando. Tenga en cuenta que escanear aquí incluye la porción de escaneo de rango parcial de una búsqueda de índice , así como el índice familiar sin restricciones o la exploración de tablas.
Si estamos escaneando (rango) una estructura de índice cuyas claves normalmente no se modifican por ninguna actividad concurrente, estos dos primeros problemas no deberían ser un gran problema práctico. Sin embargo, es difícil estar seguro de esto, porque los planes de consulta pueden cambiar para usar un método de acceso diferente, y el nuevo índice buscado puede incorporar claves volátiles.
También debemos tener en cuenta que muchas consultas de producción realmente solo necesitan un valor aproximado. o respuesta de mejor esfuerzo a algunos tipos de preguntas de todos modos. El hecho de que algunas filas falten o se cuenten dos veces podría no importar mucho en el esquema más amplio de las cosas. En un sistema con muchos cambios simultáneos, incluso podría ser difícil estar seguro de que el resultado fue inexacta, dado que los datos cambian con tanta frecuencia. En ese tipo de situación, una respuesta más o menos correcta podría ser lo suficientemente buena para los propósitos del consumidor de datos.
Sin vista de punto en el tiempo
El tercer problema (la cuestión de la denominada vista puntual "consistente" de los datos) también se reduce al mismo tipo de consideraciones. Para propósitos de informes, donde las inconsistencias tienden a generar preguntas incómodas por parte de los consumidores de datos, con frecuencia es preferible una vista instantánea. En otros casos, el tipo de inconsistencias que surgen de la falta de una vista puntual de los datos puede ser tolerable.
Escenarios problemáticos
También hay muchos casos en los que las preocupaciones enumeradas se se Importante. Por ejemplo, si escribe código que aplica reglas comerciales en T-SQL, debe tener cuidado al seleccionar un nivel de aislamiento (o tomar otra acción adecuada) para garantizar la corrección. Muchas reglas comerciales se pueden aplicar utilizando claves externas o restricciones, donde el motor de la base de datos maneja automáticamente las complejidades de la selección del nivel de aislamiento. Como regla general, usar el conjunto integrado de integridad declarativa características es preferible a construir sus propias reglas en T-SQL.
Hay otra clase amplia de consulta que no aplica una regla comercial per se , pero que, sin embargo, podría tener consecuencias desafortunadas cuando se ejecuta en el nivel de aislamiento confirmado de lectura de bloqueo predeterminado. Estos escenarios no siempre son tan obvios como los ejemplos citados a menudo de transferir dinero entre cuentas bancarias, o garantizar que el saldo de varias cuentas vinculadas nunca caiga por debajo de cero. Por ejemplo, considere la siguiente consulta que identifica las facturas vencidas como una entrada para algún proceso que envía cartas de recordatorio redactadas con severidad:
INSERT dbo.OverdueInvoices
SELECT I.InvoiceNumber
FROM dbo.Invoices AS INV
WHERE INV.TotalDue >
(
SELECT SUM(P.Amount)
FROM dbo.Payments AS P
WHERE P.InvoiceNumber = I.InvoiceNumber
); Claramente, no querríamos enviar una carta a alguien que haya pagado su factura en cuotas, simplemente porque la actividad simultánea de la base de datos en el momento en que se ejecutó nuestra consulta hizo que calculáramos una suma incorrecta. de pagos recibidos. Por supuesto, las consultas reales sobre sistemas de producción reales suelen ser mucho más complejas que el simple ejemplo anterior.
Para terminar por hoy, eche un vistazo a la siguiente consulta y vea si puede detectar cuántas oportunidades hay para que ocurra algo no deseado, si varias consultas de este tipo se ejecutan simultáneamente en el nivel de aislamiento confirmado de lectura de bloqueo (quizás mientras otras transacciones no relacionadas también están modificando la tabla Casos):
-- Allocate the oldest unallocated case ID to
-- the current case worker, while ensuring
-- the worker never has more than three
-- active cases at once.
UPDATE dbo.Cases
SET WorkerID = @WorkerID
WHERE
CaseID =
(
-- Find the oldest unallocated case ID
SELECT TOP (1)
C2.CaseID
FROM dbo.Cases AS C2
WHERE
C2.WorkerID IS NULL
ORDER BY
C2.DateCreated DESC
)
AND
(
SELECT COUNT_BIG(*)
FROM dbo.Cases AS C3
WHERE C3.WorkerID = @WorkerID
) < 3; Una vez que comienza a buscar todas las pequeñas formas en que una consulta puede fallar en este nivel de aislamiento, puede ser difícil detenerse. Tenga en cuenta las advertencias señaladas anteriormente sobre la necesidad real de resultados precisos completamente aislados y puntuales. Está perfectamente bien tener consultas que devuelvan resultados suficientemente buenos, siempre y cuando esté al tanto de las ventajas y desventajas que está haciendo al usar la confirmación de lectura.
La próxima vez
La siguiente parte de esta serie analiza la segunda implementación física del aislamiento de lectura confirmada disponible en SQL Server, el aislamiento de instantáneas de lectura confirmada.
[ Ver el índice de toda la serie ]