Las vistas indexadas se pueden crear en cualquier edición de SQL Server, pero hay una serie de comportamientos que debe tener en cuenta si desea aprovecharlos al máximo.
Las estadísticas automáticas requieren una sugerencia NOEXPAND
SQL Server puede crear estadísticas automáticamente para ayudar con la estimación de cardinalidad y la toma de decisiones basada en costos durante la optimización de consultas. Esta función funciona tanto con vistas indexadas como con tablas base, pero solo si la vista se nombra explícitamente en la consulta y NOEXPAND se especifica la sugerencia. (Siempre hay un objeto de estadísticas asociado con cada índice en una vista, es la generación automática y el mantenimiento de estadísticas no asociadas con un índice de lo que estamos hablando aquí).
Si está acostumbrado a trabajar con ediciones de SQL Server que no son Enterprise, es posible que nunca antes haya notado este comportamiento. Las ediciones inferiores de SQL Server requieren NOEXPAND sugerencia para producir un plan de consulta que acceda a una vista indexada. Cuando NOEXPAND se especifica, las estadísticas automáticas se crean en las vistas indexadas exactamente como sucede con las tablas ordinarias.
Ejemplo:Edición estándar con NOEXPAND
Usando SQL Server 2012 Standard Edition y la base de datos de muestra de Adventure Works, primero creamos una vista que une dos tablas de ventas y calcula la cantidad total de pedidos por cliente y producto:
CREATE VIEW dbo.CustomerOrders
WITH SCHEMABINDING AS
SELECT
SOH.CustomerID,
SOD.ProductID,
OrderQty = SUM(SOD.OrderQty),
NumRows = COUNT_BIG(*)
FROM Sales.SalesOrderDetail AS SOD
JOIN Sales.SalesOrderHeader AS SOH
ON SOH.SalesOrderID = SOD.SalesOrderID
GROUP BY
SOH.CustomerID,
SOD.ProductID; Para que esta vista admita estadísticas, debemos materializarla agregando un índice agrupado único. Se garantiza que la combinación de ID de cliente y producto es única en la vista (por definición), por lo que la usaremos como clave. Podríamos especificar las dos columnas de cualquier manera en el índice, pero asumiendo que esperamos que se filtren más consultas por producto, hacemos que Product ID sea la columna principal. Esta acción también crea estadísticas de índice, con un histograma creado a partir de valores de ID de producto.
CREATE UNIQUE CLUSTERED INDEX cuq ON dbo.CustomerOrders (ProductID, CustomerID);
Ahora se nos pide que escribamos una consulta que muestre la cantidad total de pedidos por cliente, para una gama particular de productos. Esperamos que un plan de ejecución que use la vista indexada sea una estrategia efectiva, porque evitará una combinación y operará en datos que ya están parcialmente agregados. Como estamos usando SQL Server Standard Edition, debemos especificar la vista explícitamente y usar un NOEXPAND sugerencia para generar un plan de consulta que acceda a la vista indexada:
SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO WITH (NOEXPAND)
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
CO.CustomerID; El plan de ejecución producido muestra una búsqueda en la vista indexada para encontrar filas para los productos de interés seguido de una agregación para calcular la cantidad total por cliente:
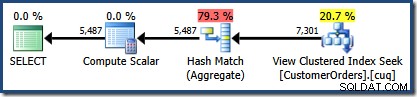
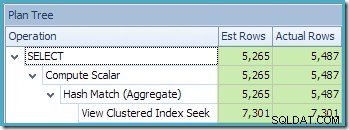
La vista de árbol del plan de SQL Sentry Plan Explorer muestra que la estimación de cardinalidad es exactamente correcta para la búsqueda de vista indexada y muy buena para el resultado del agregado:
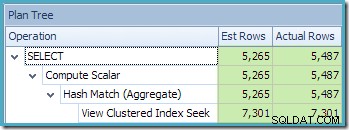
Como parte del proceso de compilación y optimización de esta consulta, SQL Server creó un objeto de estadísticas adicional en la columna Id. de cliente de la vista indexada. Esta estadística se crea porque el número esperado y la distribución de ID de cliente pueden ser importantes, por ejemplo, al elegir una estrategia de agregación. Podemos ver la nueva estadística usando Management Studio Object Explorer:
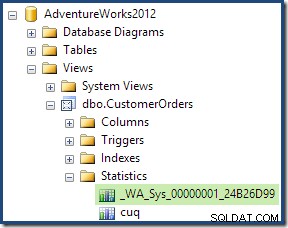
Al hacer doble clic en el objeto de estadísticas, se confirma que se creó a partir de la columna ID de cliente en la vista (no una tabla base):
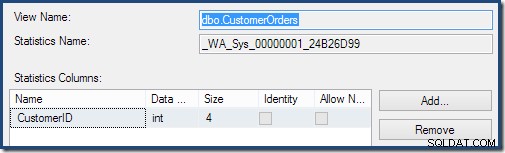
Las vistas indexadas pueden mejorar la estimación de cardinalidad
Todavía usando la Edición estándar, ahora soltamos y recreamos la vista indexada (que también quita las estadísticas de la vista) y ejecutamos la consulta nuevamente, esta vez con NOEXPAND pista comentada:
SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO --WITH (NOEXPAND)
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
CO.CustomerID;
Como era de esperar al usar la Edición estándar sin NOEXPAND , el plan de consulta resultante opera en las tablas base en lugar de la vista directamente:

El triángulo de advertencia en el operador raíz en el plan anterior nos alerta sobre un índice potencialmente útil en la tabla Detalle de órdenes de venta, que no es importante para nuestros propósitos actuales. Esta compilación no crea ninguna estadística en la vista indexada. La única estadística en la vista después de la compilación de consultas es la asociada con el índice agrupado:
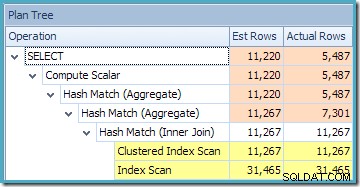
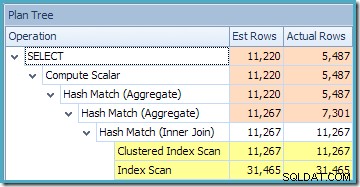
La vista de árbol del plan para la consulta muestra que la estimación de la cardinalidad es correcta para los dos recorridos de tabla y la combinación, pero bastante peor para los otros operadores del plan:
Usando la vista indexada con un NOEXPAND La sugerencia dio como resultado estimaciones más precisas para nuestra consulta de prueba porque la información de mejor calidad estaba disponible en las estadísticas de la vista, en particular, las estadísticas asociadas con el índice de vista.
Como regla general, la precisión de la información estadística se degrada con bastante rapidez a medida que pasa y es modificada por los operadores del plan de consulta. Las uniones simples a menudo no son tan malas en este sentido, pero la información sobre el resultado de una agregación a menudo no es mejor que una conjetura informada. Proporcionar al optimizador de consultas información más precisa utilizando estadísticas sobre vistas indexadas puede ser una técnica útil para aumentar la calidad y solidez del plan.
Una vista sin NOEXPAND puede producir un plan inferior
El plan de consulta que se muestra arriba (Edición estándar, sin NOEXPAND ) en realidad es menos óptimo que si hubiéramos escrito la consulta en las tablas base nosotros mismos, en lugar de permitir que el optimizador de consultas amplíe la vista. La consulta a continuación expresa el mismo requisito lógico, pero no hace referencia a la vista:
SELECT
SOH.CustomerID,
SUM(OrderQty)
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE
SOD.ProductID BETWEEN 711 AND 718
GROUP BY
SOH.CustomerID; Esta consulta produce el siguiente plan de ejecución:
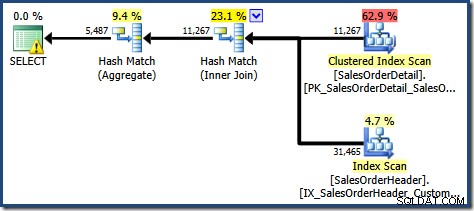
Este plan presenta una operación de agregación menos que antes. Cuando se utilizó la expansión de vistas, el optimizador de consultas lamentablemente no pudo eliminar una operación de agregación redundante, lo que resultó en un plan de ejecución menos eficiente. La estimación de cardinalidad final para la nueva consulta también es ligeramente mejor que cuando se hizo referencia a la vista indexada sin NOEXPAND :
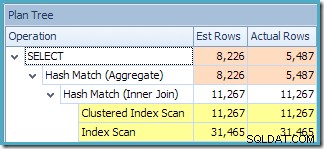
No obstante, las mejores estimaciones siguen siendo las que se producen al hacer referencia a la vista indexada con NOEXPAND (se repite a continuación por conveniencia):
Edición empresarial y Coincidencia de vistas
En una instancia de Enterprise Edition, el optimizador de consultas puede usar una vista indexada incluso si la consulta no menciona la vista explícitamente. Si el optimizador puede hacer coincidir parte del árbol de consulta con una vista indexada, puede optar por hacerlo, en función de su estimación de los costos de usar la vista o no. La lógica de coincidencia de vistas es razonablemente inteligente, pero tiene límites que son bastante fáciles de alcanzar en la práctica. Incluso cuando la coincidencia de vistas es exitosa, el optimizador aún puede ser engañado por estimaciones de costos inexactas.
La sugerencia de consulta EXPAND VIEWS
Comenzando con las posibilidades más raras, puede haber ocasiones en las que una consulta haga referencia a una vista indexada, pero se obtendría un mejor plan accediendo a las tablas base. En estas circunstancias, la sugerencia de consulta EXPAND VIEWS se puede utilizar:
SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
CO.CustomerID
OPTION (EXPAND VIEWS);
En Enterprise Edition, esta consulta produce el mismo plan que se ve en Standard Edition cuando NOEXPAND se omitió la sugerencia (incluida la operación de agregación redundante):

Aparte, el EXPAND VIEWS La pista está mal nombrada, en mi opinión. SQL Server siempre expande las definiciones de vista en una consulta a menos que NOEXPAND se especifica la sugerencia. El EXPAND VIEWS sugerencia deshabilita las reglas en el optimizador que pueden hacer coincidir partes del árbol expandido con vistas indexadas. En ausencia de cualquiera de las sugerencias, SQL Server primero expande una vista a su definición de tabla base y luego considera volver a hacer coincidir las vistas indexadas. Un mejor nombre para EXPAND VIEWS la sugerencia podría haber sido DISABLE INDEXED VIEW MATCHING , porque eso es lo que hace.
El EXPAND VIEWS La sugerencia probablemente se usa con mayor frecuencia para evitar que una consulta en tablas base coincida con una vista indexada:
SELECT
SOH.CustomerID,
SUM(OrderQty)
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE
SOD.ProductID BETWEEN 711 AND 718
GROUP BY
SOH.CustomerID
OPTION (EXPAND VIEWS); La sugerencia de consulta da como resultado el mismo plan de ejecución y estimaciones que se vieron cuando usábamos la Edición estándar y la misma consulta solo de tabla base:
Coincidencia de vista empresarial y estadísticas
Incluso en Enterprise Edition, las estadísticas de vista no indexadas solo se crean si NOEXPAND se utiliza la sugerencia. Para ser absolutamente claro al respecto, la función de coincidencia de vistas solo para empresas nunca da como resultado que se creen o actualicen estadísticas de vistas. Vale la pena explorar un poco este comportamiento poco intuitivo, ya que puede tener efectos secundarios sorprendentes.
Ahora ejecutamos nuestra consulta básica contra la vista en una instancia de Enterprise Edition, sin ninguna sugerencia:
SELECT
CO.CustomerID,
SUM(CO.OrderQty)
FROM dbo.CustomerOrders AS CO
WHERE
CO.ProductID BETWEEN 711 AND 718
GROUP BY
CO.CustomerID;
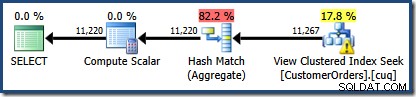
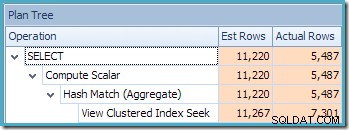
Una novedad es el triángulo de advertencia en Ver búsqueda de índice agrupado. La información sobre herramientas muestra los detalles:
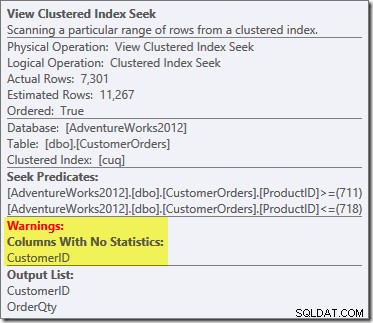
No usamos un NOEXPAND sugerencia, por lo que las estadísticas en la columna ID de cliente de la vista indexada no se crearon automáticamente. En este ejemplo simplificado, las estadísticas sobre el ID de cliente no son realmente muy importantes, pero no siempre será así.
Estimaciones curiosas de cardinalidad
La segunda cosa de interés es que las estimaciones de cardinalidad parecen ser peores que cualquier caso que hayamos encontrado hasta ahora, incluidos los ejemplos de la Edición estándar.
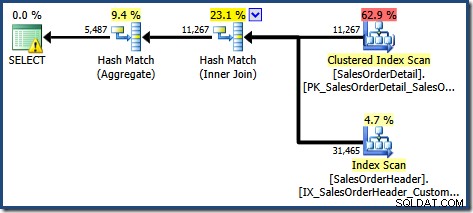
Inicialmente, es difícil ver de dónde provino la estimación de cardinalidad para Ver búsqueda de índice agrupado (11,267). Esperaríamos que la estimación se basara en la información del histograma de ID de producto de las estadísticas asociadas con el índice agrupado de la vista. La parte relevante de este histograma se muestra a continuación:
DBCC SHOW_STATISTICS
('dbo.CustomerOrders', 'cuq')
WITH HISTOGRAM;
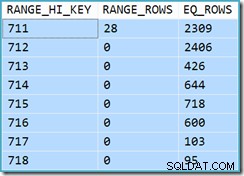
Dado que la tabla no se ha modificado desde que se crearon las estadísticas, esperaríamos que la estimación sea una simple suma de RANGE_ROWS y EQ_ROWS para los valores de ID de producto entre 711 y 718 (tenga en cuenta que la estimación debe excluir los 28 RANGE_ROWS que se muestran contra la entrada 711 ya que esas filas existen debajo del valor de la clave 711). La suma de las EQ_ROWS mostradas es 7301. Esta es exactamente la cantidad de filas que realmente devolvió la vista; entonces, ¿de dónde proviene la estimación de 11 267?
La respuesta está en la forma en que funciona actualmente la coincidencia de vistas. Nuestra consulta no especificó el NOEXPAND sugerencia, por lo que las estimaciones iniciales de cardinalidad se basan en el árbol de consulta de vista ampliada. Esto es más fácil de ver mirando nuevamente el plan estimado para la misma consulta con EXPAND VIEWS especificado:
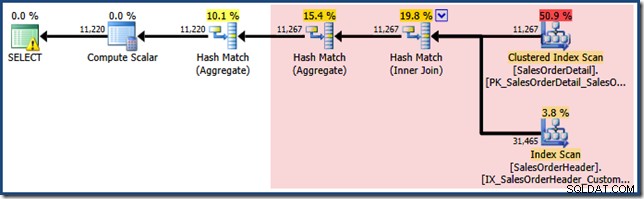
El área sombreada en rojo representa la parte del árbol que se reemplaza por la actividad de comparación de vistas. La cardinalidad de salida de esta área es 11.267. La parte no sombreada con la estimación de 11 220 no se ve afectada por la coincidencia de vistas. Estas son exactamente las estimaciones que queríamos explicar:
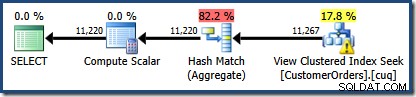
La coincidencia de vistas simplemente reemplazó el área sombreada en rojo con una búsqueda lógicamente equivalente en la vista indexada. No usó información estadística de la vista para volver a calcular la estimación de cardinalidad.
Hasta cierto punto, probablemente pueda apreciar por qué podría funcionar de esta manera:en general, hay pocas razones para esperar que una estimación calculada a partir de un conjunto de información estadística sea mejor que otra. Se podría argumentar que es más probable que las estadísticas de vistas indexadas sean más precisas aquí, en comparación con las estadísticas derivadas posteriores a la unión en el área sombreada en rojo, pero puede ser complicado generalizar eso, o explicar correctamente la rapidez con que varias fuentes de la información estadística puede quedar obsoleta a medida que cambian los datos subyacentes.
También se podría argumentar que si estuviéramos tan seguros de que la información de la vista indexada era mejor, habríamos usado un NOEXPAND pista.
Estimaciones de cardinalidad aún más curiosas
Surge una situación aún más interesante con Enterprise Edition si escribimos la consulta en las tablas base y confiamos en la coincidencia de vista automatizada:
SELECT
SOH.CustomerID,
SUM(OrderQty)
FROM Sales.SalesOrderHeader AS SOH
JOIN Sales.SalesOrderDetail AS SOD
ON SOD.SalesOrderID = SOH.SalesOrderID
WHERE
SOD.ProductID BETWEEN 711 AND 718
GROUP BY
SOH.CustomerID;
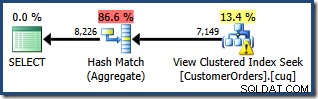
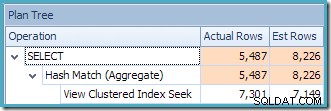
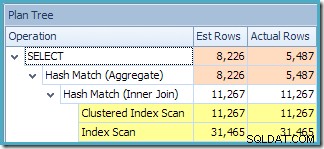
La advertencia de estadísticas faltantes es la misma que antes y tiene la misma explicación. La característica más interesante es que ahora tenemos una estimación más baja de la cantidad de filas producidas por View Clustered Index Seek (7149) y una estimación mayor de la cantidad de filas devueltas por la agregación (8226).
Para enfatizar el punto, este plan de consulta parece estar basado en la idea de que se pueden agregar 7149 filas de origen para producir 8226 filas.
Parte de la explicación es la misma que antes. El EXPAND VIEWS el plan de consulta, que muestra la región roja que será reemplazada por la coincidencia de vistas, se muestra a continuación:
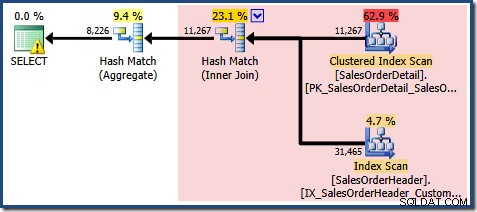
Esto explica de dónde viene la estimación final de 8226, pero ¿qué pasa con la estimación de 7149 filas? Siguiendo la lógica vista anteriormente, parece que la vista debería mostrar una estimación de 11 267 filas.
La respuesta es que la estimación de 7149 es una conjetura. Sí, en serio. La vista indexada contiene 79.433 filas en total. El porcentaje de conjetura mágica para el predicado ID de producto ENTRE es del 9%, lo que da 0,09 * 79433 =7148,97 filas. El plan de consulta de SSMS muestra que este cálculo es exactamente correcto, incluso antes del redondeo:
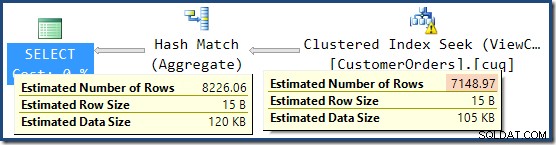
En esta situación, el optimizador de SQL Server parece haber preferido una suposición basada en la cardinalidad de vista indexada sobre la estimación de cardinalidad posterior a la unión del subárbol reemplazado. Curioso.
Resumen
Usando el NOEXPAND La sugerencia garantiza que se usará una vista indexada en el plan de consulta final y permite que el optimizador de consultas cree, mantenga y use automáticamente estadísticas que no son de índice. Usando NOEXPAND también garantiza que las estimaciones iniciales de cardinalidad se basen en información de vista indexada en lugar de derivarse de tablas base.
Si NOEXPAND no se especifica, las referencias de vista siempre se reemplazan con sus definiciones de tabla base antes de que comience la compilación de la consulta (y, por lo tanto, antes de la estimación de cardinalidad inicial). Solo en los SKU empresariales, las vistas indexadas se pueden volver a sustituir en el árbol de consultas más adelante en el proceso de optimización.
El EXPAND VIEWS la sugerencia de consulta evita que el optimizador realice coincidencias de vistas indexadas de Enterprise Edition. Esto se aplica ya sea que la consulta hiciera referencia originalmente a una vista indexada o no. Cuando se realiza la comparación de vistas, una estimación de cardinalidad existente puede reemplazarse con una conjetura en algunas circunstancias.
Las estadísticas que se muestran como faltantes en una vista indexada se pueden crear manualmente, pero el optimizador generalmente no las usará para consultas que no usen un NOEXPAND pista.
El uso de vistas indexadas puede mejorar la estimación de la cardinalidad, especialmente si la vista contiene uniones o agregaciones. Las consultas tienen la mejor oportunidad de beneficiarse de estadísticas de visualización más precisas si NOEXPAND se especifica.