El particionamiento es una función de SQL Server que se implementa a menudo para aliviar los desafíos relacionados con la capacidad de administración, las tareas de mantenimiento o el bloqueo y bloqueo. La administración de tablas grandes puede volverse más fácil con el particionamiento y puede mejorar la escalabilidad y la disponibilidad. Además, un subproducto de la partición puede mejorar el rendimiento de las consultas. No es una garantía o un hecho, y no es la razón principal para implementar la partición, pero es algo que vale la pena revisar cuando se divide una tabla grande.
Antecedentes
Como repaso rápido, la función de partición de SQL Server solo está disponible en las ediciones Enterprise y Developer. El particionamiento se puede implementar durante el diseño inicial de la base de datos, o se puede implementar después de que una tabla ya tenga datos. Comprenda que cambiar una tabla existente con datos a una tabla particionada no siempre es rápido y simple, pero es bastante factible con una buena planificación y los beneficios se pueden obtener rápidamente.
Una tabla particionada es aquella en la que los datos se separan en estructuras físicas más pequeñas según el valor de una columna específica (llamada columna de partición, que se define en la función de partición). Si desea separar los datos por año, puede usar una columna llamada Fecha de venta como columna de partición, y todos los datos de 2013 residirían en una estructura, todos los datos de 2012 residirían en una estructura diferente, etc. Estos conjuntos de datos separados permitir un mantenimiento enfocado (puede reconstruir solo una partición de un índice, en lugar de todo el índice) y permitir que los datos se agreguen y eliminen rápidamente porque se pueden organizar antes de que se agreguen o eliminen realmente de la tabla.
La configuración
Para examinar las diferencias en el rendimiento de las consultas para una tabla con particiones y una sin particiones, creé dos copias de la tabla Sales.SalesOrderHeader de la base de datos AdventureWorks2012. La tabla sin particiones se creó solo con un índice agrupado en SalesOrderID, la clave principal tradicional de la tabla. La segunda tabla se dividió en OrderDate, con OrderDate y SalesOrderID como clave de agrupación, y no tenía índices adicionales. Tenga en cuenta que hay numerosos factores a considerar al decidir qué columna usar para la partición. La creación de particiones a menudo, pero ciertamente no siempre, utiliza un campo de fecha para definir los límites de la partición. Como tal, se seleccionó OrderDate para este ejemplo y se usaron consultas de muestra para simular la actividad típica en la tabla SalesOrderHeader. Las instrucciones para crear y completar ambas tablas se pueden descargar aquí.
Después de crear las tablas y agregar datos, se verificaron los índices existentes y luego se actualizaron las estadísticas con FULLSCAN:
EXEC sp_helpindex 'Sales.Big_SalesOrderHeader'; GO EXEC sp_helpindex 'Sales.Part_SalesOrderHeader'; GO UPDATE STATISTICS [Sales].[Big_SalesOrderHeader] WITH FULLSCAN; GO UPDATE STATISTICS [Sales].[Part_SalesOrderHeader] WITH FULLSCAN; GO SELECT sch.name + '.' + so.name AS [Table], ss.name AS [Statistic], sp.last_updated AS [Stats Last Updated], sp.rows AS [Rows], sp.rows_sampled AS [Rows Sampled], sp.modification_counter AS [Row Modifications] FROM sys.stats AS ss INNER JOIN sys.objects AS so ON ss.[object_id] = so.[object_id] INNER JOIN sys.schemas AS sch ON so.[schema_id] = sch.[schema_id] OUTER APPLY sys.dm_db_stats_properties(so.[object_id], ss.stats_id) AS sp WHERE so.[object_id] IN (OBJECT_ID(N'Sales.Big_SalesOrderHeader'), OBJECT_ID(N'Sales.Part_SalesOrderHeader')) AND ss.stats_id = 1;
Además, ambas tablas tienen exactamente la misma distribución de datos y mínima fragmentación.
Rendimiento para una consulta simple
Antes de que se agregaran índices adicionales, se ejecutó una consulta básica en ambas tablas para calcular los totales ganados por el vendedor para los pedidos realizados en diciembre de 2012:
SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Big_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GO SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GOESTADÍSTICAS SALIDA E/S
Mesa 'Mesa de trabajo'. Recuento de escaneo 0, lecturas lógicas 0, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tabla 'Big_SalesOrderHeader'. Recuento de escaneos 9, lecturas lógicas 2710440, lecturas físicas 2226, lecturas anticipadas 2658769, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Mesa 'Mesa de trabajo'. Recuento de escaneo 0, lecturas lógicas 0, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tabla 'Part_SalesOrderHeader'. Recuento de escaneos 9, lecturas lógicas 248128, lecturas físicas 3, lecturas anticipadas 245030, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.

Totales por vendedor para diciembre:tabla sin particiones
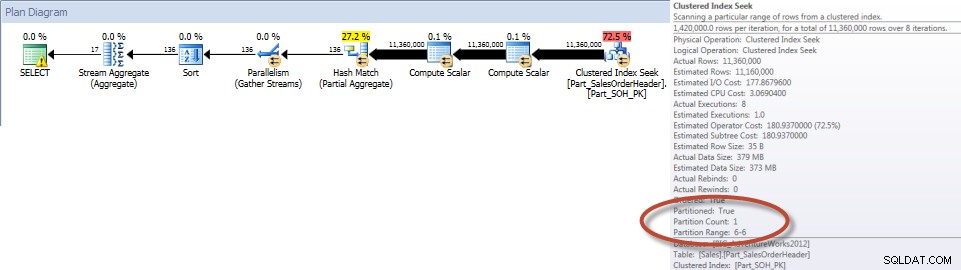
Totales por vendedor para diciembre:tabla dividida
Como era de esperar, la consulta en la tabla sin particiones tuvo que realizar un análisis completo de la tabla ya que no había un índice que la respaldara. Por el contrario, la consulta en la tabla particionada solo necesitaba acceder a una partición de la tabla.
Para ser justos, si esta fuera una consulta ejecutada repetidamente con diferentes rangos de fechas, existiría el índice no agrupado apropiado. Por ejemplo:
CREATE NONCLUSTERED INDEX [Big_SalesOrderHeader_SalesPersonID] ON [Sales].[Big_SalesOrderHeader] ([OrderDate]) INCLUDE ([SalesPersonID], [TotalDue]);
Con este índice creado, cuando se vuelve a ejecutar la consulta, las estadísticas de E/S caen y el plan cambia para usar el índice no agrupado:
ESTADÍSTICAS SALIDA E/S
Mesa 'Mesa de trabajo'. Recuento de escaneo 0, lecturas lógicas 0, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tabla 'Big_SalesOrderHeader'. Recuento de escaneos 9, lecturas lógicas 42901, lecturas físicas 3, lecturas anticipadas 42346, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.

Totales por vendedor para diciembre:NCI en tabla sin particiones
Con un índice de apoyo, la consulta en Sales.Big_SalesOrderHeader requiere muchas menos lecturas que el análisis de índice agrupado en Sales.Part_SalesOrderHeader, lo cual no es inesperado ya que el índice agrupado es mucho más amplio. Si creamos un índice no agrupado comparable para Sales.Part_SalesOrderHeader, vemos números de E/S similares:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_SalesPersonID] ON [Sales].[Part_SalesOrderHeader]([SalesPersonID]) INCLUDE ([TotalDue]);ESTADÍSTICAS SALIDA E/S
Tabla 'Part_SalesOrderHeader'. Recuento de escaneos 9, lecturas lógicas 42894, lecturas físicas 1, lecturas anticipadas 42378, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
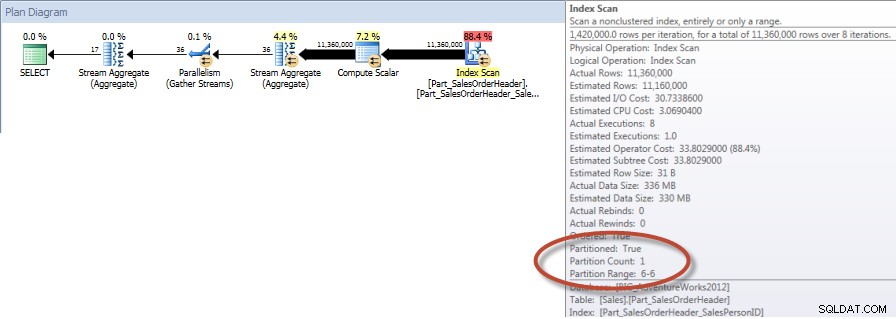
Totales por vendedor para diciembre:NCI en tabla dividida con eliminación
Y si observamos las propiedades del Index Scan no agrupado, podemos verificar que el motor accedió solo a una partición (6).
Como se indicó originalmente, la partición no suele implementarse para mejorar el rendimiento. En el ejemplo que se muestra arriba, la consulta en la tabla particionada no funciona significativamente mejor siempre que exista el índice no agrupado adecuado.
Rendimiento para una consulta ad-hoc
Una consulta contra la tabla particionada puede superar la misma consulta en la tabla no particionada en algunos casos, por ejemplo, cuando la consulta tiene que usar el índice agrupado. Si bien es ideal tener la mayoría de las consultas respaldadas por índices no agrupados, algunos sistemas permiten consultas ad-hoc de los usuarios y otros tienen consultas que pueden ejecutarse con tan poca frecuencia que no garantizan índices compatibles. En la tabla SalesOrderHeader, un usuario podría ejecutar la siguiente consulta para encontrar pedidos de diciembre de 2012 que debían enviarse antes de fin de año pero no lo hicieron, para un conjunto particular de clientes y con un TotalDue superior a $1000:
SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Big_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GO SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Part_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GOESTADÍSTICAS SALIDA E/S
Tabla 'Big_SalesOrderHeader'. Recuento de escaneos 9, lecturas lógicas 2711220, lecturas físicas 8386, lecturas anticipadas 2662400, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tabla 'Part_SalesOrderHeader'. Recuento de escaneos 9, lecturas lógicas 248128, lecturas físicas 0, lecturas anticipadas 243792, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
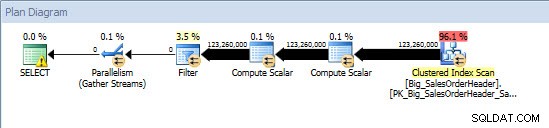
Consulta ad-hoc:tabla sin particiones
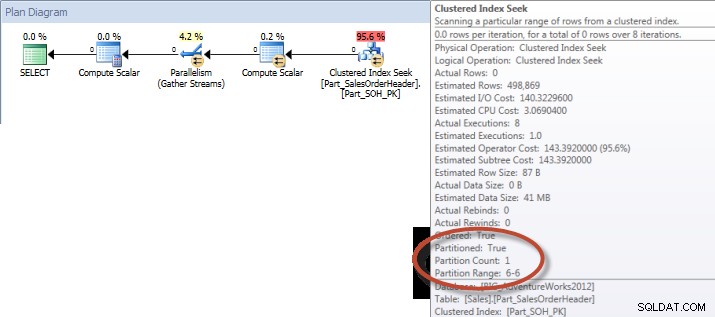
Consulta ad-hoc:tabla particionada
Contra la tabla no particionada, la consulta requirió un escaneo completo contra el índice agrupado, pero contra la tabla particionada, la consulta realizó una búsqueda de índice del índice agrupado, ya que el motor usó la eliminación de partición y solo leyó los datos que era absolutamente necesario. En este ejemplo, es una diferencia significativa en términos de E/S y, dependiendo del hardware, podría ser una diferencia dramática en el tiempo de ejecución. La consulta podría optimizarse agregando el índice apropiado, pero normalmente no es factible indexar para todos soltero consulta. En particular, para las soluciones que permiten consultas ad-hoc, es justo decir que nunca se sabe qué van a hacer los usuarios. Una consulta puede ejecutarse una vez y nunca volver a ejecutarse, y crear un índice después del hecho es inútil. Por lo tanto, al cambiar de una tabla sin particiones a una tabla con particiones, es importante aplicar el mismo esfuerzo y enfoque que el ajuste de índice regular; desea verificar que existen los índices apropiados para admitir la mayoría de las consultas.
Alineación de rendimiento e índice
Un factor adicional a considerar al crear índices para una tabla particionada es si alinear el índice o no. Los índices deben estar alineados con la tabla si planea cambiar los datos dentro y fuera de las particiones. La creación de un índice no agrupado en una tabla particionada crea un índice alineado de forma predeterminada, donde la columna de partición se agrega como una columna incluida en el índice.
Un índice no alineado se crea especificando un esquema de partición diferente o un grupo de archivos diferente. La columna de partición puede ser parte del índice como una columna clave o una columna incluida, pero si no se usa el esquema de partición de la tabla, o si se usa un grupo de archivos diferente, el índice no se alineará.
Un índice alineado se particiona como la tabla (los datos existirán en estructuras separadas) y, por lo tanto, se puede eliminar la partición. Un índice no alineado existe como una estructura física y es posible que no brinde el beneficio esperado para una consulta, según el predicado. Considere una consulta que cuente las ventas por número de cuenta, agrupadas por mes:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);
Si no está tan familiarizado con la creación de particiones, puede crear un índice como este para respaldar la consulta (tenga en cuenta que se especifica el grupo de archivos PRIMARIO):
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_NotAL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]) ON [PRIMARY];
Este índice no está alineado, aunque incluye OrderDate porque es parte de la clave principal. Las columnas también se incluyen si creamos un índice alineado, pero tenga en cuenta la diferencia en la sintaxis:
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_AL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]);
Podemos verificar qué columnas existen en el índice utilizando sp_helpindex de Kimberly Tripp:
EXEC sp_SQLskills_SQL2008_helpindex 'Sales.Part_SalesOrderHeader’;

sp_helpindex para Sales.Part_SalesOrderHeader
Cuando ejecutamos nuestra consulta y la obligamos a usar el índice no alineado, se escanea todo el índice. Aunque OrderDate es parte del índice, no es la columna principal, por lo que el motor tiene que verificar el valor de OrderDate para cada AccountNumber para ver si se encuentra entre el 1 de enero de 2013 y el 31 de julio de 2013:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_NotAL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);ESTADÍSTICAS SALIDA E/S
Mesa 'Mesa de trabajo'. Recuento de escaneo 0, lecturas lógicas 0, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tabla 'Part_SalesOrderHeader'. Recuento de escaneos 9, lecturas lógicas 786861, lecturas físicas 1, lecturas anticipadas 770929, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
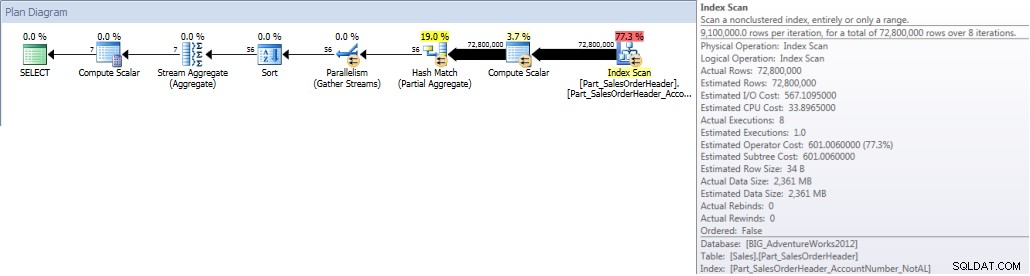
Totales de cuenta por mes (enero a julio de 2013) utilizando NCI alineado (obligado)
Por el contrario, cuando se obliga a la consulta a usar el índice alineado, se puede usar la eliminación de particiones y se requieren menos E/S, aunque OrderDate no sea una columna inicial en el índice.
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_AL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);ESTADÍSTICAS SALIDA E/S
Mesa 'Mesa de trabajo'. Recuento de escaneo 0, lecturas lógicas 0, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tabla 'Part_SalesOrderHeader'. Recuento de escaneos 9, lecturas lógicas 456258, lecturas físicas 16, lecturas anticipadas 453241, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
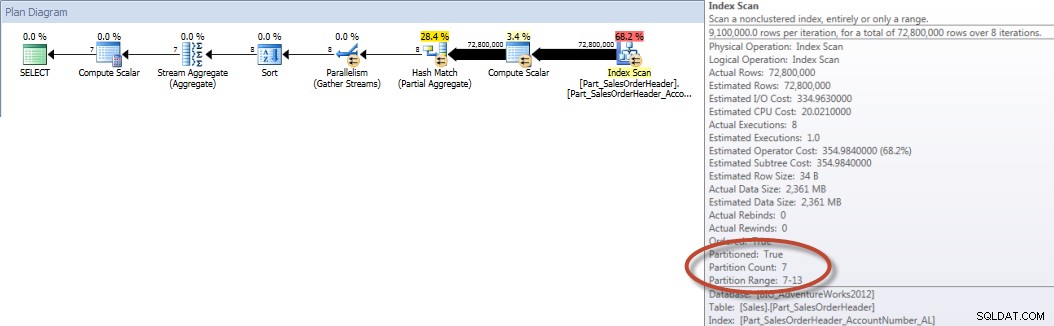
Totales de cuenta por mes (enero a julio de 2013) usando NCI alineado (forzado)
Resumen
La decisión de implementar la partición requiere la debida consideración y planificación. La facilidad de administración, la escalabilidad y la disponibilidad mejoradas, y la reducción de los bloqueos son razones comunes para particionar tablas. Mejorar el rendimiento de las consultas no es una razón para emplear la partición, aunque puede ser un efecto secundario beneficioso en algunos casos. En términos de rendimiento, es importante asegurarse de que su plan de implementación incluya una revisión del rendimiento de las consultas. Confirme que sus índices continúan respaldando adecuadamente sus consultas después la tabla está particionada y verifique que las consultas que utilizan los índices agrupados y no agrupados se beneficien de la eliminación de particiones cuando corresponda.