Estoy en el proceso de ordenar mi casa (demasiado tarde en el verano para tratar de hacerlo pasar por una limpieza de primavera). Ya sabes, limpiar armarios, revisar los juguetes de los niños y organizar el sótano. Es un proceso doloroso. Cuando nos mudamos a nuestra casa hace 10 años, teníamos MUCHO espacio. Ahora siento que hay cosas por todas partes, y hace que sea más difícil encontrar lo que realmente estoy buscando y lleva más y más tiempo limpiar y organizar.
¿Suena esto como cualquier base de datos que administres?
Muchos clientes con los que he trabajado se ocupan de la purga de datos como una ocurrencia tardía. En el momento de la implementación, todos quieren guardar todo. “Nunca sabemos cuándo podríamos necesitarlo”. Después de un año o dos, alguien se da cuenta de que hay muchas cosas adicionales en la base de datos, pero ahora la gente tiene miedo de deshacerse de ellas. "Necesitamos consultar con Legal para ver si podemos eliminarlo". Pero nadie consulta con Legal, o si alguien lo hace, Legal regresa a los dueños de negocios para preguntar qué conservar, y luego el proyecto se detiene. “No podemos llegar a un consenso sobre lo que se puede eliminar”. El proyecto se olvida, y luego de dos o cuatro años, la base de datos de repente es un terabyte, difícil de administrar, y la gente culpa de todos los problemas de rendimiento al tamaño de la base de datos. Escuchas las palabras "particionamiento" y "base de datos de archivo" y, a veces, solo puedes eliminar un montón de datos, lo que tiene sus propios problemas.
Idealmente, debe decidir sobre su estrategia de purga antes de la implementación, o dentro de los primeros seis a doce meses de la puesta en marcha. Pero como ya pasamos esa etapa, veamos qué impacto pueden tener estos datos adicionales.
Metodología de prueba
Para preparar el escenario, tomé una copia de la base de datos de crédito y la restauré en mi instancia de SQL Server 2012. Eliminé los tres índices no agrupados existentes y agregué dos propios:
USE [master]; GO RESTORE DATABASE [Credit] FROM DISK = N'C:\SQLskills\SampleDatabases\Credit\CreditBackup100.bak' WITH FILE = 1, MOVE N'CreditData' TO N'D:\Databases\SQL2012\CreditData.mdf', MOVE N'CreditLog' TO N'D:\Databases\SQL2012\CreditLog.ldf', STATS = 5; GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditData', SIZE = 14680064KB , FILEGROWTH = 524288KB ); GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditLog', SIZE = 2097152KB , FILEGROWTH = 524288KB ); GO USE [Credit]; GO DROP INDEX [dbo].[charge].[charge_category_link]; DROP INDEX [dbo].[charge].[charge_provider_link]; DROP INDEX [dbo].[charge].[charge_statement_link]; CREATE NONCLUSTERED INDEX [charge_chargedate] ON [dbo].[charge] ([charge_dt]); CREATE NONCLUSTERED INDEX [charge_provider] ON [dbo].[charge] ([provider_no]);
Luego aumenté el número de filas en la tabla a 14,4 millones, volviendo a insertar el conjunto original de filas varias veces, modificando ligeramente las fechas:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] - 175, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 2 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 79, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3
Finalmente, configuré un arnés de prueba para ejecutar una serie de declaraciones contra la base de datos cuatro veces cada una. Las declaraciones están a continuación:
ALTER INDEX ALL ON [dbo].[charge] REBUILD; DBCC CHECKDB (Credit) WITH ALL_ERRORMSGS, NO_INFOMSGS; BACKUP DATABASE [Credit] TO DISK = N'D:\Backups\SQL2012\Credit.bak' WITH NOFORMAT, INIT, NAME = N'Credit-Full Database Backup', STATS = 10; SELECT [charge_no], [member_no], [charge_dt], [charge_amt] FROM [dbo].[charge] WHERE [charge_no] = 841345; DECLARE @StartDate DATETIME = '1999-07-01'; DECLARE @EndDate DATETIME = '1999-07-31'; SELECT [charge_dt], COUNT([charge_dt]) FROM [dbo].[charge] WHERE [charge_dt] BETWEEN @StartDate AND @EndDate GROUP BY [charge_dt]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 475 GROUP BY [provider_no]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 140 GROUP BY [provider_no];
Antes de cada declaración que ejecuté
DBCC DROPCLEANBUFFERS; GO
para borrar el grupo de búfer. Obviamente, esto no es algo para ejecutar en un entorno de producción. Lo hice aquí para proporcionar un punto de partida consistente para cada prueba.
Después de cada ejecución, aumenté el tamaño de la tabla dbo.charge insertando los 14,4 millones de filas con las que comencé, pero aumenté charge_dt en un año por cada ejecución. Por ejemplo:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 365, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 14800000; GO
Después de agregar 14,4 millones de filas, volví a ejecutar el arnés de prueba. Repetí esto seis veces, esencialmente agregando seis "años" de datos. La tabla dbo.charge comenzó con datos de 1999 y, después de las inserciones repetidas, contenía datos hasta 2005.
Resultados
Los resultados de las ejecuciones se pueden ver aquí:
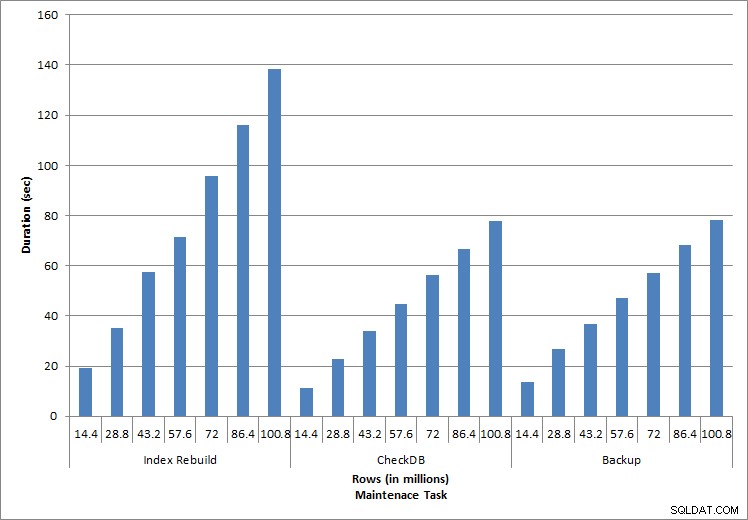
Duración de las tareas de mantenimiento
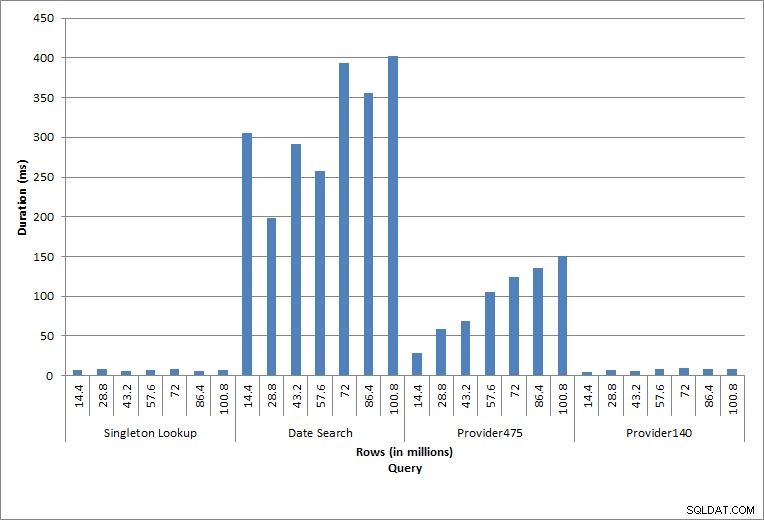
Duración de consultas
Las declaraciones individuales ejecutadas reflejan la actividad típica de la base de datos. Las reconstrucciones de índices, las comprobaciones de integridad y las copias de seguridad forman parte del mantenimiento regular de la base de datos. Las consultas en la tabla de cargos representan una búsqueda de singleton, así como tres variaciones de escaneos de rango específicos para los datos de la tabla.
Reconstrucciones de índices, CHECKDB y copias de seguridad
Como era de esperar para las tareas de mantenimiento, la duración y los valores de IO aumentaron a medida que se agregaban más filas a la base de datos. El tamaño de la base de datos aumentó en un factor de 10 y, aunque las duraciones no aumentaron al mismo ritmo, se observó un aumento constante. Inicialmente, cada tarea de mantenimiento tardó menos de 20 segundos en completarse, pero a medida que se agregaron más filas, la duración de las tareas aumentó a casi 1 minuto y 20 segundos para 100 millones de filas (y a más de 2 minutos para la reconstrucción del índice). Esto refleja el tiempo adicional que requiere SQL Server para completar la tarea debido a los datos adicionales.
Búsqueda de elementos únicos
La consulta contra dbo.charge para un charge_no específico siempre produjo una fila, y habría producido una fila independientemente del valor utilizado, ya que charge_no es una identidad única. Hay una variación mínima para esta búsqueda. A medida que se agregan continuamente filas a la tabla, el índice puede aumentar en profundidad uno o dos niveles (más a medida que la tabla se hace más ancha), por lo que se agregan un par de IO, pero esta es una búsqueda única con muy pocas IO.
Escaneos de rango
La consulta de un rango de fechas (charge_dt) se modificó después de cada inserción para buscar los datos del año más reciente para julio (por ejemplo, '2005-07-01' a '2005-07-01' para el último conjunto de pruebas), pero devolvió poco más de 1,2 millones de filas cada vez. En un escenario del mundo real, no esperaríamos que se devuelva la misma cantidad de filas para el mismo mes, año tras año, ni esperaríamos que se devuelva la misma cantidad de filas para cada mes en un año. Pero los recuentos de filas podrían permanecer dentro del mismo rango entre meses, con ligeros aumentos con el tiempo. Existen fluctuaciones en la duración de esta consulta, pero una revisión de los datos de IO capturados de sys.dm_io_virtual_file_stats muestra coherencia en la cantidad de lecturas.
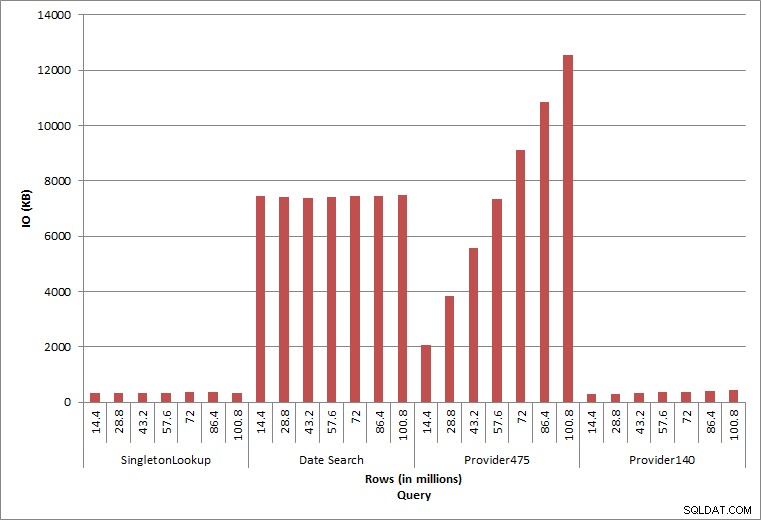
Consultar E/S
Las dos consultas finales, para dos valores de Provider_no diferentes, muestran el verdadero efecto de conservar los datos. En la tabla inicial de dbo.charge, el proveedor n.º 475 tenía más de 126 000 filas y el proveedor n.º 140 tenía más de 1700 filas. Por cada 14,4 millones de filas que se agregaron, se agregó aproximadamente el mismo número de filas para cada proveedor_no. En un entorno de producción, este tipo de distribución de datos no es infrecuente y las consultas de estos datos pueden funcionar bien en los primeros años de la solución, pero pueden degradarse con el tiempo a medida que se agregan más filas. La duración de la consulta aumenta en un factor de cinco (de 31 ms a 153 ms) entre la ejecución inicial y final para el proveedor_no 475. Si bien este impacto puede no parecer significativo, tenga en cuenta el aumento paralelo en IO (arriba). Si esta fuera una consulta que se ejecutó con alta frecuencia y/o hubo consultas similares que se ejecutaron con frecuencia regular, la carga adicional puede acumularse y afectar el uso general de recursos. Además, considere el impacto cuando trabaja con tablas que tienen miles de millones de filas y se utilizan en consultas con uniones complejas, y el impacto en sus tareas de mantenimiento regulares y extremadamente críticas. Finalmente, tenga en cuenta el tiempo de recuperabilidad. Su plan de recuperación ante desastres debe basarse en los tiempos de restauración y, a medida que crece el tamaño de la base de datos, tardará más tiempo en restaurarse en su totalidad. Si no está probando y cronometrando regularmente sus restauraciones, la recuperación de un desastre podría llevar más tiempo de lo que pensaba.
Resumen
Los ejemplos que se muestran aquí son ilustraciones simples de lo que puede suceder cuando no se determina una estrategia de archivo de datos durante la implementación de la base de datos, y hay muchos otros escenarios para explorar y probar. Los datos antiguos a los que rara vez se accede, si es que alguna vez se accede a ellos, afectan más que solo el espacio en el disco. Puede afectar el rendimiento de las consultas y la duración de las tareas de mantenimiento. Como DBA que administra varias bases de datos en una instancia, una base de datos que contiene datos históricos puede afectar el rendimiento y las tareas de mantenimiento de otras bases de datos. Además, si los informes se ejecutan con datos históricos, esto puede causar estragos en un entorno OLTP que ya está ocupado.
Desde el principio, es fundamental que se determine la vida útil de los datos en una base de datos y se establezca un plan de acción. Para algunas soluciones, es necesario conservar todos los datos para siempre. En este caso, emplee estrategias para mantener manejable el tamaño de la base de datos, por ejemplo:archive los datos en una tabla separada o en una base de datos separada de manera regular. En caso de que no sea necesario almacenar los datos durante años y años, implemente una estrategia de depuración que elimine los datos de forma regular. De esta manera, puedes tirar los juguetes con los que ya no juegas, la ropa que ya no te queda y la basura que no usas cada tres meses... en lugar de una vez cada 10 años.