Está trabajando con un desarrollador que informa un rendimiento lento para la siguiente llamada de procedimiento almacenado:
EXEC [dbo].[charge_by_date] '2/28/2013';
Usted pregunta qué problema está viendo el desarrollador, pero la única información adicional que recibe es que se está "ejecutando lentamente". Entonces salta a la instancia de SQL Server y echa un vistazo a la real plan de ejecución. Hace esto porque le interesa no solo cómo se ve el plan de ejecución, sino también cuál es el número de filas estimado versus real para el plan:
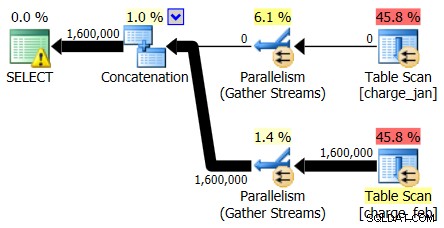
Mirando primero solo a los operadores del plan, puede ver algunos detalles dignos de mención:
- Hay una advertencia en el operador raíz
- Hay un escaneo de tabla para ambas tablas a las que se hace referencia en el nivel de hoja (charge_jan y charge_feb) y se pregunta por qué ambos siguen siendo montones y no tienen índices agrupados
- Ves que solo hay filas que fluyen a través de la tabla charge_feb y no de la tabla charge_jan
- Ves zonas paralelas en el plano
En cuanto a la advertencia en el iterador raíz, pasa el cursor sobre él y ve que faltan advertencias de índice con una recomendación para los siguientes índices:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_feb] ([charge_dt]) INCLUDE ([charge_no]) GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_jan] ([charge_dt]) INCLUDE ([charge_no]) GO
Le pregunta al desarrollador de la base de datos original por qué no hay un índice agrupado y la respuesta es "No lo sé".
Continuando con la investigación antes de realizar cualquier cambio, observa la pestaña Árbol del plan en el Explorador de planes de SQL Sentry y, de hecho, ve que hay sesgos significativos entre las filas estimadas y las filas reales para una de las tablas:

Parece que hay dos problemas:
- Una subestimación de las filas en el escaneo de la tabla charge_jan
- Una sobreestimación de filas en el escaneo de la tabla charge_feb
Así que las estimaciones de cardinalidad son sesgada, y te preguntas si esto está relacionado con la detección de parámetros. Decide verificar el valor compilado del parámetro y compararlo con el valor de tiempo de ejecución del parámetro, que puede ver en la pestaña Parámetros:

De hecho, existen diferencias entre el valor de tiempo de ejecución y el valor compilado. Copie la base de datos en un entorno de prueba similar a Prod y luego pruebe la ejecución del procedimiento almacenado con el valor de tiempo de ejecución de 28/2/2013 primero y luego 31/1/2013 después.
Los planes del 28/02/2013 y del 31/01/2013 tienen formas idénticas pero flujos de datos reales diferentes. El plan del 28/02/2013 y las estimaciones de cardinalidad fueron las siguientes:
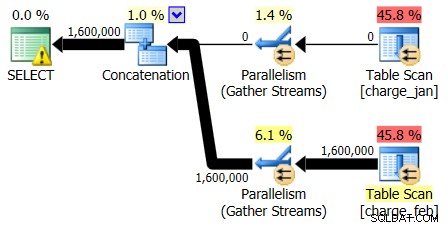

Y mientras que el plan del 28/02/2013 no muestra ningún problema de estimación de cardinalidad, el plan del 31/01/2013 sí:
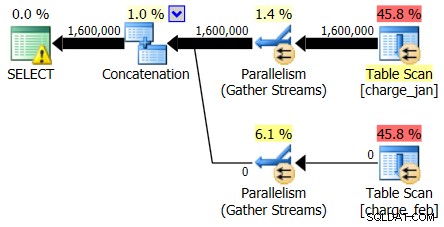

Entonces, el segundo plan muestra las mismas sobreestimaciones y subestimaciones, solo que al revés del plan original que miraste.
Decide agregar los índices sugeridos al entorno de prueba similar a prod para las tablas charge_jan y charge_feb y ver si eso ayuda en algo. Al ejecutar los procedimientos almacenados en el orden de enero/febrero, verá las siguientes formas de plan nuevas y las estimaciones de cardinalidad asociadas:
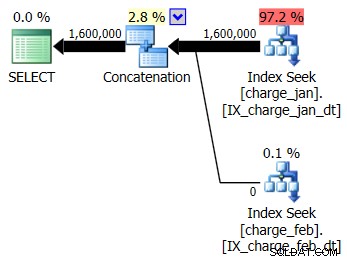

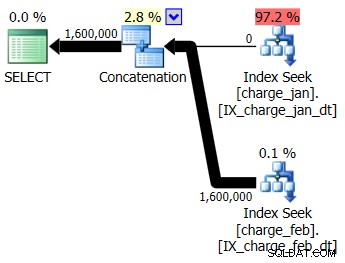

El nuevo plan usa una operación de búsqueda de índice de cada tabla, pero aún ve cero filas que fluyen de una tabla y no de la otra, y aún ve sesgos de estimación de cardinalidad basados en la detección de parámetros cuando el valor de tiempo de ejecución está en un mes diferente al de la compilación. valor de tiempo.
Su equipo tiene una política de no agregar índices sin prueba de beneficio suficiente y pruebas de regresión asociadas. Decide, por el momento, eliminar los índices no agrupados que acaba de crear. Si bien no aborda de inmediato los agrupados que faltan index, tú decides que te encargarás de eso más tarde.
En este punto, se da cuenta de que necesita profundizar en la definición del procedimiento almacenado, que es la siguiente:
CREATE PROCEDURE dbo.charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt GO
A continuación, mira la definición del objeto charge_view:
CREATE VIEW charge_view AS SELECT * FROM [charge_jan] UNION ALL SELECT * FROM [charge_feb] GO
La vista hace referencia a datos de cargos que están separados en diferentes tablas por fecha. Y luego se pregunta si el sesgo del plan de ejecución de la segunda consulta se puede evitar cambiando la definición del procedimiento almacenado.
¿Quizás si el optimizador sabe en tiempo de ejecución cuál es el valor, el problema de estimación de cardinalidad desaparecerá y mejorará el rendimiento general?
Continúe y redefina la llamada al procedimiento almacenado de la siguiente manera, agregando una sugerencia RECOMPILE (sabiendo que también ha escuchado que esto puede aumentar el uso de la CPU, pero dado que este es un entorno de prueba, se siente seguro si lo intenta):
ALTER PROCEDURE charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt OPTION (RECOMPILE); GO
Luego vuelve a ejecutar el procedimiento almacenado usando el valor 31/1/2013 y luego el valor 28/2/2013.
La forma del plan sigue siendo la misma, pero ahora se elimina el problema de estimación de cardinalidad.
Los datos estimados de cardinalidad del 31/1/2013 muestran:

Y los datos estimados de cardinalidad del 28/02/2013 muestran:

Eso lo hace feliz por un momento, pero luego se da cuenta de que la duración de la ejecución general de la consulta parece relativamente la misma que antes. Empiezas a tener dudas de que el desarrollador esté contento con tus resultados. Resolvió el sesgo de estimación de cardinalidad, pero sin el aumento de rendimiento esperado, no está seguro de haber ayudado de alguna manera significativa.
Es en este punto cuando se da cuenta de que el plan de ejecución de la consulta es solo un subconjunto de la información que podría necesitar, por lo que amplía aún más su exploración mirando la pestaña E/S de la tabla. Verá el siguiente resultado para la ejecución del 31/01/2013:

Y para la ejecución del 28/02/2013 se ven datos similares:

Es en ese momento cuando se pregunta si las operaciones de acceso a datos para ambos Las tablas son necesarias en cada plan. Si el optimizador sabe que solo necesita las filas de enero, ¿por qué acceder a febrero y viceversa? También recuerda que el optimizador de consultas no tiene garantías de que no las haya filas reales de los otros meses en la tabla "incorrecta", a menos que dichas garantías se hayan hecho explícitamente a través de restricciones en la tabla misma.
Verifica las definiciones de la tabla a través de sp_help para cada tabla y no ve ninguna restricción definida para ninguna de las tablas.
Entonces, como prueba, agrega las siguientes dos restricciones:
ALTER TABLE [dbo].[charge_jan] ADD CONSTRAINT charge_jan_chk CHECK (charge_dt >= '1/1/2013' AND charge_dt < '2/1/2013'); GO ALTER TABLE [dbo].[charge_feb] ADD CONSTRAINT charge_feb_chk CHECK (charge_dt >= '2/1/2013' AND charge_dt < '3/1/2013'); GO
Vuelve a ejecutar los procedimientos almacenados y ve las siguientes formas de plan y estimaciones de cardinalidad.
31/01/2013 ejecución:
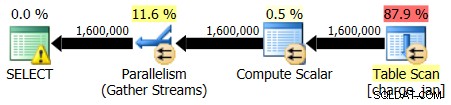

28/02/2013 ejecución:


Si mira de nuevo Table I/O, verá el siguiente resultado para la ejecución del 31/1/2013:

Y para la ejecución del 28/02/2013, verá datos similares, pero para la tabla charge_feb:

Recordando que aún tiene RECOMPILE en la definición del procedimiento almacenado, intente eliminarlo y vea si ve el mismo efecto. Después de hacer esto, verá que regresa el acceso a dos tablas, pero sin lecturas lógicas reales para la tabla que no tiene filas (en comparación con el plan original sin las restricciones). Por ejemplo, la ejecución del 31/1/2013 mostró la siguiente salida de E/S de tabla:

Decide seguir adelante con la prueba de carga de las nuevas restricciones CHECK y la solución RECOMPILE, eliminando el acceso a la tabla por completo del plan (y los operadores de plan asociados). También se prepara para un debate sobre la clave del índice agrupado y un índice no agrupado compatible adecuado que se adaptará a un conjunto más amplio de cargas de trabajo que actualmente acceden a las tablas asociadas.