[ Parte 1 | Parte 2 | Parte 3 | Parte 4 ]
Mucho se ha escrito a lo largo de los años sobre cómo comprender y optimizar SELECT consultas, pero menos sobre la modificación de datos. Esta serie de publicaciones analiza un problema que es específico de INSERT , UPDATE , DELETE y MERGE consultas:el problema de Halloween.
La frase "Problema de Halloween" se acuñó originalmente con referencia a SQL UPDATE consulta que se suponía daría un aumento del 10% a cada empleado que ganara menos de $25,000. El problema era que la consulta seguía dando aumentos del 10 % hasta que todos ganó al menos $ 25,000. Veremos más adelante en esta serie que el problema subyacente también se aplica a INSERT , DELETE y MERGE consultas, pero para esta primera entrada, será útil examinar el UPDATE problema con un poco de detalle.
Antecedentes
El lenguaje SQL proporciona una forma para que los usuarios especifiquen los cambios en la base de datos usando un UPDATE declaración, pero la sintaxis no dice nada sobre cómo el motor de la base de datos debe realizar los cambios. Por otro lado, el estándar SQL especifica que el resultado de una UPDATE debe ser igual que si se hubiera ejecutado en tres fases separadas y no superpuestas:
- Una búsqueda de solo lectura determina los registros que se cambiarán y los nuevos valores de columna
- Los cambios se aplican a los registros afectados
- Se verifican las restricciones de consistencia de la base de datos
La implementación de estas tres fases literalmente en un motor de base de datos produciría resultados correctos, pero el rendimiento podría no ser muy bueno. Los resultados intermedios en cada etapa requerirán memoria del sistema, lo que reduce la cantidad de consultas que el sistema puede ejecutar simultáneamente. La memoria requerida también puede exceder la que está disponible, lo que requiere que al menos una parte del conjunto de actualizaciones se escriba en el almacenamiento del disco y se vuelva a leer más tarde. Por último, pero no menos importante, cada fila de la tabla debe tocarse varias veces en este modelo de ejecución.
Una estrategia alternativa es procesar la UPDATE una fila a la vez. Esto tiene la ventaja de que solo toca cada fila una vez y, por lo general, no requiere memoria para el almacenamiento (aunque algunas operaciones, como una ordenación completa, deben procesar el conjunto de entrada completo antes de producir la primera fila de salida). Este modelo iterativo es el que utiliza el motor de ejecución de consultas de SQL Server.
El desafío para el optimizador de consultas es encontrar un plan de ejecución iterativo (fila por fila) que satisfaga el UPDATE semántica requerida por el estándar SQL, al mismo tiempo que conserva los beneficios de rendimiento y simultaneidad de la ejecución canalizada.
Procesamiento de actualizaciones
Para ilustrar el problema original, aplicaremos un aumento del 10 % a cada empleado que gane menos de 25 000 USD utilizando la función Employees. tabla a continuación:

CREATE TABLE dbo.Employees
(
Name nvarchar(50) NOT NULL,
Salary money NOT NULL
);
INSERT dbo.Employees
(Name, Salary)
VALUES
('Brown', $22000),
('Smith', $21000),
('Jones', $25000);
UPDATE e
SET Salary = Salary * $1.1
FROM dbo.Employees AS e
WHERE Salary < $25000; Estrategia de actualización en tres fases
La primera fase de solo lectura encuentra todos los registros que cumplen con WHERE predicado de la cláusula y guarda suficiente información para que la segunda fase haga su trabajo. En la práctica, esto significa registrar un identificador único para cada fila calificada (las claves de índice agrupadas o el identificador de fila del montón) y el nuevo valor de salario. Una vez que se completa la fase uno, todo el conjunto de información de actualización se pasa a la segunda fase, que ubica cada registro que se actualizará utilizando el identificador único y cambia el salario al nuevo valor. Luego, la tercera fase verifica que el estado final de la tabla no viole ninguna restricción de integridad de la base de datos.
Estrategia iterativa
Este enfoque lee una fila a la vez de la tabla de origen. Si la fila satisface el WHERE cláusula predicativa, se aplica el aumento de salario. Este proceso se repite hasta que se hayan procesado todas las filas desde el origen. A continuación se muestra un plan de ejecución de muestra que utiliza este modelo:

Como es habitual en la canalización basada en la demanda de SQL Server, la ejecución comienza en el operador más a la izquierda:el UPDATE en este caso. Solicita una fila de Table Update, que solicita una fila de Compute Scalar, y baja por la cadena hasta Table Scan:
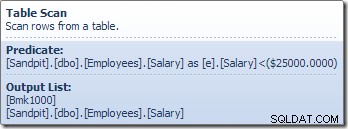
El operador Table Scan lee las filas una a la vez del motor de almacenamiento, hasta que encuentra una que satisface el predicado Salary. La lista de salida en el gráfico anterior muestra al operador Table Scan que devuelve un identificador de fila y el valor actual de la columna Salario para esta fila. Una sola fila que contiene referencias a estas dos piezas de información se pasa a Compute Scalar:
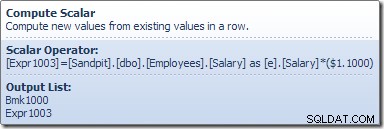
Compute Scalar define una expresión que aplica el aumento de salario a la fila actual. Devuelve una fila que contiene referencias al identificador de fila y el salario modificado a Table Update, que invoca al motor de almacenamiento para realizar la modificación de datos. Este proceso iterativo continúa hasta que Table Scan se queda sin filas. Se sigue el mismo proceso básico si la tabla tiene un índice agrupado:
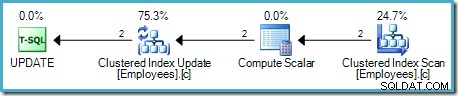
La principal diferencia es que las claves de índice agrupadas y el uniquifier (si está presente) se utilizan como identificador de fila en lugar de un RID de almacenamiento dinámico.
El problema
El cambio de la operación lógica de tres fases definida en el estándar SQL al modelo físico de ejecución iterativa ha introducido una serie de cambios sutiles, de los cuales solo veremos uno hoy. Puede ocurrir un problema en nuestro ejemplo en ejecución si hay un índice no agrupado en la columna Salario, que el optimizador de consultas decide usar para encontrar filas que califiquen (Salario <$25,000):
CREATE NONCLUSTERED INDEX nc1 ON dbo.Employees (Salary);
El modelo de ejecución fila por fila ahora puede producir resultados incorrectos o incluso entrar en un bucle infinito. Considere un plan de ejecución iterativo (imaginario) que busca el índice Salary, devolviendo una fila a la vez a Compute Scalar y, en última instancia, al operador Update:

Hay un par de Compute Scalars adicionales en este plan debido a una optimización que omite el mantenimiento del índice no agrupado si el valor del Salario no ha cambiado (solo es posible para un salario cero en este caso).
Ignorando eso, la característica importante de este plan es que ahora tenemos un escaneo de índice parcial ordenado que pasa una fila a la vez a un operador que modifica el mismo índice (el resaltado en verde en el gráfico anterior de SQL Sentry Plan Explorer deja en claro que el El operador de actualización de índice mantiene tanto la tabla base como el índice no agrupado).
De todos modos, el problema es que al procesar una fila a la vez, la Actualización puede mover la fila actual por delante de la posición de escaneo utilizada por Index Seek para ubicar filas para cambiar. Trabajar con el ejemplo debería hacer que la declaración sea un poco más clara:
El índice no agrupado está codificado y ordenado de forma ascendente según el valor del salario. El índice también contiene un puntero a la fila principal en la tabla base (ya sea un RID de montón o las claves de índice agrupadas más uniquifier si es necesario). Para que el ejemplo sea más fácil de seguir, suponga que la tabla base ahora tiene un índice agrupado único en la columna Nombre, por lo que el contenido del índice no agrupado al comienzo del procesamiento de la actualización es:
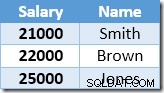
La primera fila devuelta por Index Seek es el salario de $21,000 de Smith. Este valor se actualiza a $23 100 en la tabla base y el índice no agrupado por el operador de índice agrupado. El índice no agrupado ahora contiene:
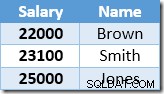
La siguiente fila devuelta por Index Seek será la entrada de $22 000 para Brown, que se actualiza a $24 200:
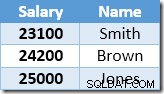
Ahora Index Seek encuentra el valor de $ 23,100 para Smith, que se actualiza nuevamente , a $ 25,410. Este proceso continúa hasta que todos los empleados tengan un salario de al menos $25,000, lo cual no es un resultado correcto para la UPDATE dada. consulta. El mismo efecto en otras circunstancias puede conducir a una actualización descontrolada que solo finaliza cuando el servidor se queda sin espacio de registro o se produce un error de desbordamiento (en este caso, podría ocurrir si alguien tuviera un salario cero). Este es el Problema de Halloween que se aplica a las actualizaciones.
Evitar el problema de Halloween para las actualizaciones
Los lectores con ojo de águila habrán notado que los porcentajes de costos estimados en el plan imaginario Index Seek no sumaron el 100%. Esto no es un problema con Plan Explorer:eliminé deliberadamente un operador clave del plan:

El optimizador de consultas reconoce que este plan de actualización canalizado es vulnerable al problema de Halloween e introduce un Eager Table Spool para evitar que ocurra. No hay indicios ni marcas de seguimiento para evitar la inclusión del spool en este plan de ejecución porque es necesario para la corrección.
Como sugiere su nombre, el spool consume con entusiasmo todas las filas de su operador secundario (el Index Seek) antes de devolver una fila a su Compute Scalar principal. El efecto de esto es introducir una separación de fases completa – todas las filas que califican se leen y se guardan en el almacenamiento temporal antes de realizar cualquier actualización.
Esto nos acerca a la semántica lógica de tres fases del estándar SQL, aunque tenga en cuenta que la ejecución del plan sigue siendo fundamentalmente iterativa, con operadores a la derecha del carrete que forman el cursor de lectura y operadores a la izquierda que forman el cursor de escritura . El contenido del spool todavía se lee y procesa fila por fila (no se pasa en masa como la comparación con el estándar SQL podría hacerle creer).
Los inconvenientes de la separación de fases son los mismos que se mencionaron anteriormente. Table Spool consume tempdb espacio (páginas en el grupo de búfer) y puede requerir lecturas y escrituras físicas en el disco bajo presión de memoria. El optimizador de consultas asigna un costo estimado al spool (sujeto a todas las advertencias habituales acerca de las estimaciones) y elegirá entre los planes que requieren protección contra el Problema de Halloween frente a los que no, en función del costo estimado normal. Naturalmente, el optimizador puede elegir incorrectamente entre las opciones por cualquiera de las razones normales.
En este caso, la compensación es entre el aumento de la eficiencia al buscar directamente los registros calificados (aquellos con un salario <$25,000) versus el costo estimado del carrete requerido para evitar el Problema de Halloween. Un plan alternativo (en este caso específico) es un análisis completo del índice agrupado (o montón). Esta estrategia no requiere la misma protección de Halloween porque las claves del índice agrupado no se modifican:

Debido a que las claves de índice son estables, las filas no pueden moverse de posición en el índice entre iteraciones, lo que evita el problema de Halloween en el presente caso. Según el costo del tiempo de ejecución de la exploración de índice agrupado en comparación con la combinación de Index Seek más Eager Table Spool vista anteriormente, un plan puede ejecutarse más rápido que el otro. Otra consideración es que el plan con Protección de Halloween adquirirá más bloqueos que el plan completamente canalizado, y los bloqueos se mantendrán por más tiempo.
Reflexiones finales
Comprender el Problema de Halloween y los efectos que puede tener en los planes de consulta de modificación de datos lo ayudará a analizar los planes de ejecución de cambio de datos y puede ofrecer oportunidades para evitar los costos y los efectos secundarios de la protección innecesaria donde hay una alternativa disponible.
Hay varias formas del Problema de Halloween, no todas causadas por la lectura y escritura de las claves de un índice común. El Problema de Halloween tampoco se limita a UPDATE consultas El optimizador de consultas tiene más trucos bajo la manga para evitar el problema de Halloween además de la separación de fases de fuerza bruta mediante un Eager Table Spool. Estos puntos (y más) se explorarán en las próximas entregas de esta serie.
[ Parte 1 | Parte 2 | Parte 3 | Parte 4 ]