[ Parte 1 | Parte 2 | Parte 3 | Parte 4 ]
El Problema de Halloween puede tener una serie de efectos importantes en los planes de ejecución. En esta parte final de la serie, analizamos los trucos que puede emplear el optimizador para evitar el problema de Halloween al compilar planes para consultas que agregan, cambian o eliminan datos.
Antecedentes
A lo largo de los años, se han intentado varios enfoques para evitar el problema de Halloween. Una de las primeras técnicas consistía simplemente en evitar la creación de planes de ejecución que implicaran leer y escribir en claves del mismo índice. Esto no fue muy exitoso desde el punto de vista del rendimiento, sobre todo porque a menudo significaba escanear la tabla base en lugar de usar un índice no agrupado selectivo para ubicar las filas para cambiar.
Un segundo enfoque fue separar por completo las fases de lectura y escritura de una consulta de actualización, ubicando primero todas las filas que califican para el cambio, almacenándolas en algún lugar y solo luego comenzando a realizar los cambios. En SQL Server, esta separación completa de fases se logra colocando el ahora familiar Eager Table Spool en el lado de entrada del operador de actualización:
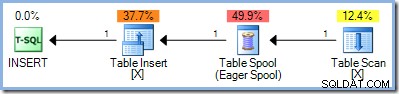
El spool lee todas las filas de su entrada y las almacena en un tempdb oculto. mesa de trabajo. Las páginas de esta tabla de trabajo pueden permanecer en la memoria o pueden requerir espacio en disco físico si el conjunto de filas es grande o si el servidor está bajo presión de memoria.
La separación completa de fases puede ser menos que ideal porque generalmente queremos ejecutar la mayor parte posible del plan como una canalización, donde cada fila se procesa por completo antes de pasar a la siguiente. La canalización tiene muchas ventajas, como evitar la necesidad de almacenamiento temporal y tocar cada fila solo una vez.
El Optimizador de SQL Server
SQL Server va mucho más allá de las dos técnicas descritas hasta ahora, aunque, por supuesto, incluye ambas opciones. El optimizador de consultas de SQL Server detecta consultas que requieren protección de Halloween y determina cuánto se requiere protección y utiliza basado en costos análisis para encontrar el método más económico para brindar esa protección.
La forma más fácil de entender este aspecto del Problema de Halloween es mirar algunos ejemplos. En las siguientes secciones, la tarea es agregar un rango de números a una tabla existente, pero solo números que aún no existen:
CREATE TABLE dbo.Test
(
pk integer NOT NULL,
CONSTRAINT PK_Test
PRIMARY KEY CLUSTERED (pk)
); 5 filas
El primer ejemplo procesa un rango de números del 1 al 5 inclusive:
INSERT dbo.Test (pk)
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 5
AND NOT EXISTS
(
SELECT NULL
FROM dbo.Test AS t
WHERE t.pk = Num.n
); Dado que esta consulta lee y escribe en las claves del mismo índice en la tabla de prueba, el plan de ejecución requiere protección de Halloween. En este caso, el optimizador utiliza una separación de fase completa mediante un Eager Table Spool:
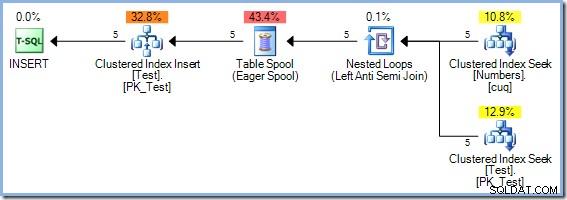
50 filas
Con cinco filas ahora en la tabla de prueba, ejecutamos la misma consulta nuevamente, cambiando WHERE cláusula para procesar los números del 1 al 50 inclusive :
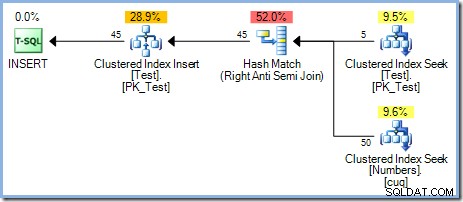
Este plan brinda la protección correcta contra el Problema de Halloween, pero no presenta un carrete de mesa ansioso. El optimizador reconoce que el operador de combinación Hash Match está bloqueando su entrada de compilación; todas las filas se leen en una tabla hash antes de que el operador inicie el proceso de coincidencia utilizando las filas de la entrada de la sonda. Como consecuencia, este plan proporciona de forma natural la separación de fases (solo para la mesa de prueba) sin necesidad de un carrete.
El optimizador eligió un plan de combinación Hash Match en lugar de la combinación de bucles anidados que se ve en el plan de 5 filas por razones basadas en costos. El plan Hash Match de 50 filas tiene un coste total estimado de 0,0347345 unidades. Podemos forzar el plan de bucles anidados utilizado anteriormente con una pista para ver por qué el optimizador no eligió bucles anidados:
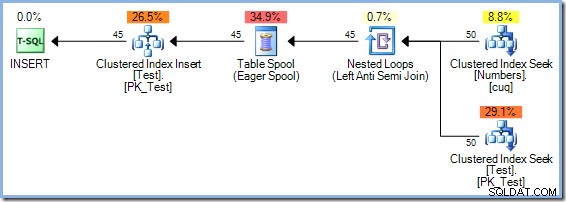
Este plan tiene un costo estimado de 0.0379063 unidades incluyendo el carrete, un poco más que el plan Hash Match.
500 filas
Con 50 filas ahora en la tabla Prueba, aumentamos aún más el rango de números a 500 :
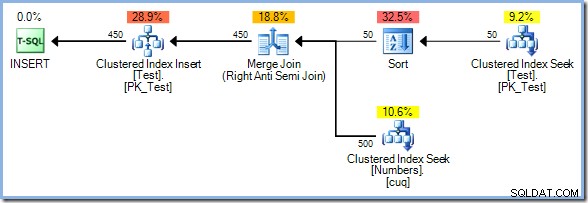
Esta vez, el optimizador elige Merge Join y nuevamente no hay Eager Table Spool. El operador Sort proporciona la separación de fases necesaria en este plan. Consume completamente su entrada antes de devolver la primera fila (la ordenación no puede saber qué fila ordena primero hasta que se hayan visto todas las filas). El optimizador decidió que clasificar 50 las filas de la tabla de prueba serían más baratas que las 450 ansiosas en cola filas justo antes del operador de actualización.
El plan Sort plus Merge Join tiene un costo estimado de 0.0362708 unidades. Las alternativas del plan Hash Match y Nested Loops salen a 0.0385677 unidades y 0,112433 unidades respectivamente.
Algo raro en Sort
Si ha estado ejecutando estos ejemplos usted mismo, es posible que haya notado algo extraño en el último ejemplo, especialmente si miró la información sobre herramientas del Explorador de planes para la tabla de prueba Buscar y Ordenar:
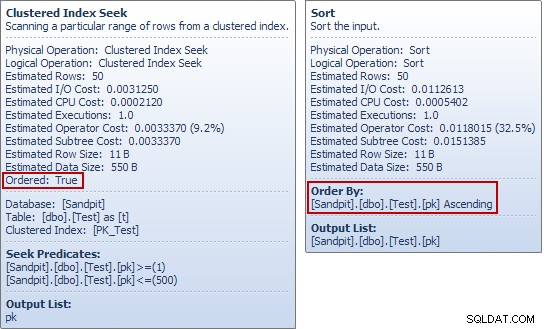
The Seek produce un ordenado flujo de pk valores, entonces, ¿cuál es el punto de ordenar en la misma columna inmediatamente después? Para responder a esa pregunta (muy razonable), comenzamos mirando solo el SELECT parte del INSERT consulta:
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 500
AND NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t
WHERE t.pk = Num.n
)
ORDER BY
Num.n;
Esta consulta produce el plan de ejecución a continuación (con o sin ORDER BY Agregué para abordar ciertas objeciones técnicas que podría tener):
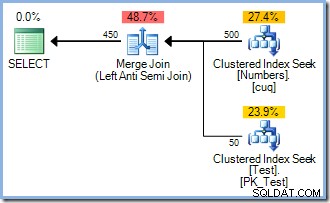
Observe la falta de un operador Ordenar. Entonces, ¿por qué INSERT ¿El plan incluye una ordenación? Simplemente para evitar el Problema de Halloween. El optimizador consideró que realizar una ordenación redundante (con su separación de fases integrada) era la forma más económica de ejecutar la consulta y garantizar resultados correctos. Inteligente.
Propiedades y niveles de protección de Halloween
El optimizador de SQL Server tiene características específicas que le permiten razonar sobre el nivel de Halloween Protection (HP) requerido en cada punto del plan de consulta y el efecto detallado que tiene cada operador. Estas funciones adicionales se incorporan al mismo marco de propiedades que utiliza el optimizador para realizar un seguimiento de cientos de otros datos importantes durante sus actividades de búsqueda.
Cada operador tiene un requerido Propiedad de HP y un entregado Propiedad de HP. El requerido La propiedad indica el nivel de HP necesario en ese punto del árbol para obtener resultados correctos. El entregado propiedad refleja el HP provisto por el operador actual y el acumulativo Efectos HP proporcionados por su subárbol.
El optimizador contiene lógica para determinar cómo cada operador físico (por ejemplo, Compute Scalar) afecta el nivel de HP. Al explorar una amplia gama de planes alternativos y rechazar planes en los que los HP entregados son menores que los HP requeridos por el operador de actualización, el optimizador tiene una manera flexible de encontrar planes correctos y eficientes que no siempre requieren un Eager Table Spool.
Cambios en el plan para la protección de Halloween
Vimos que el optimizador agregó una ordenación redundante para la protección de Halloween en el ejemplo anterior de Merge Join. ¿Cómo podemos estar seguros de que esto es más eficiente que un simple Eager Table Spool? ¿Y cómo podemos saber qué características de un plan de actualización solo están disponibles para la Protección de Halloween?
Ambas preguntas se pueden responder (en un entorno de prueba, naturalmente) utilizando el indicador de seguimiento no documentado 8692 , lo que obliga al optimizador a usar un Eager Table Spool para la protección de Halloween. Recuerde que el plan Merge Join con el tipo redundante tenía un costo estimado de 0.0362708 unidades optimizadoras mágicas. Podemos comparar eso con la alternativa de Eager Table Spool recompilando la consulta con el indicador de rastreo 8692 habilitado:
INSERT dbo.Test (pk)
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 500
AND NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t
WHERE t.pk = Num.n
)
OPTION (QUERYTRACEON 8692);
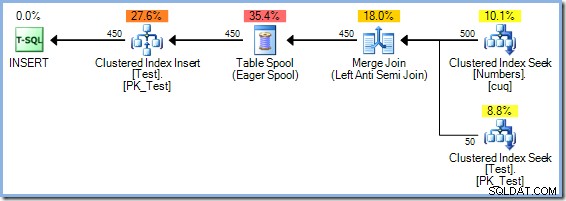
El plan Eager Spool tiene un costo estimado de 0.0378719 unidades (desde 0.0362708 con el tipo redundante). Las diferencias de costos que se muestran aquí no son muy significativas debido a la naturaleza trivial de la tarea y al tamaño pequeño de las filas. Las consultas de actualización del mundo real con árboles complejos y conteos de filas más grandes a menudo producen planes que son mucho más eficientes gracias a la capacidad del optimizador de SQL Server para pensar profundamente en la Protección de Halloween.
Otras opciones sin carrete
Posicionar un operador de bloqueo de manera óptima dentro de un plan no es la única estrategia abierta al optimizador para minimizar el costo de brindar protección contra el Problema de Halloween. También puede razonar sobre el rango de valores que se procesan, como demuestra el siguiente ejemplo:
CREATE TABLE #Test
(
pk integer IDENTITY PRIMARY KEY,
some_value integer
);
CREATE INDEX i ON #Test (some_value);
-- Pretend the table has lots of data in it
UPDATE STATISTICS #Test
WITH ROWCOUNT = 123456, PAGECOUNT = 1234;
UPDATE #Test
SET some_value = 10
WHERE some_value = 5; El plan de ejecución no muestra la necesidad de Protección de Halloween, a pesar de que estamos leyendo y actualizando las claves de un índice común:
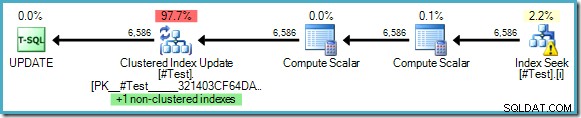
El optimizador puede ver que cambiar 'algún_valor' de 5 a 10 nunca podría hacer que Index Seek vea una fila actualizada por segunda vez (que solo busca filas donde algún_valor es 5). Este razonamiento solo es posible cuando se utilizan valores literales en la consulta, o cuando la consulta especifica OPTION (RECOMPILE) , lo que permite al optimizador detectar los valores de los parámetros para un plan de ejecución único.
Incluso con valores literales en la consulta, se puede evitar que el optimizador aplique esta lógica si la opción de base de datos FORCED PARAMETERIZATION está ON . En ese caso, los valores literales de la consulta se reemplazan por parámetros y el optimizador ya no puede estar seguro de que no se requiere la Protección de Halloween (o no se requerirá cuando el plan se reutilice con valores de parámetros diferentes):

En caso de que se pregunte qué sucede si FORCED PARAMETERIZATION está habilitado y la consulta especifica OPTION (RECOMPILE) , la respuesta es que el optimizador compila un plan para los valores rastreados y, por lo tanto, puede aplicar la optimización. Como siempre con OPTION (RECOMPILE) , el plan de consulta de valor específico no se almacena en caché para su reutilización.
Superior
Este último ejemplo muestra cómo el Top el operador puede eliminar la necesidad de Protección de Halloween:
UPDATE TOP (1) t SET some_value += 1 FROM #Test AS t WHERE some_value <= 10;

No se requiere protección porque solo estamos actualizando una fila. Index Seek no puede encontrar el valor actualizado porque la canalización de procesamiento se detiene tan pronto como se actualiza la primera fila. Nuevamente, esta optimización solo se puede aplicar si se usa un valor literal constante en el TOP , o si una variable que devuelve el valor '1' se rastrea usando OPTION (RECOMPILE) .
Si cambiamos el TOP (1) en la consulta a un TOP (2) , el optimizador elige un análisis de índice agrupado en lugar de búsqueda de índice:

No estamos actualizando las claves del índice agrupado, por lo que este plan no requiere Protección de Halloween. Forzar el uso del índice no agrupado con una pista en TOP (2) consulta hace que el costo de la protección sea aparente:

El optimizador estimó que el escaneo de índice agrupado sería más económico que este plan (con su protección extra de Halloween).
Probabilidades y extremos
Hay un par de otros puntos que quiero mencionar sobre la Protección de Halloween que no han encontrado un lugar natural en la serie hasta ahora. La primera es la cuestión de la protección de Halloween cuando se utiliza un nivel de aislamiento de versiones de filas.
Versión de filas
SQL Server proporciona dos niveles de aislamiento, READ COMMITTED SNAPSHOT y SNAPSHOT ISOLATION que usan un almacén de versiones en tempdb para proporcionar una vista coherente a nivel de declaración o transacción de la base de datos. SQL Server podría evitar la Protección de Halloween por completo con estos niveles de aislamiento, ya que el almacén de versiones puede proporcionar datos que no se verán afectados por los cambios que la instrucción en ejecución actual pueda haber realizado hasta el momento. Actualmente, esta idea no está implementada en una versión lanzada de SQL Server, aunque Microsoft ha presentado una patente que describe cómo funcionaría, por lo que quizás una versión futura incorpore esta tecnología.
Montones y registros reenviados
Si está familiarizado con el funcionamiento interno de las estructuras de almacenamiento dinámico, es posible que se pregunte si puede ocurrir un problema de Halloween en particular cuando se generan registros reenviados en una tabla de almacenamiento dinámico. En caso de que esto sea nuevo para usted, se reenviará un registro de montón si se actualiza una fila existente de modo que ya no quepa en la página de datos original. El motor deja un resguardo de reenvío y mueve el registro expandido a otra página.
Podría ocurrir un problema si un plan que contiene una exploración del montón actualiza un registro para que se reenvíe. La exploración del montón puede volver a encontrar la fila cuando la posición de exploración alcance la página con el registro reenviado. En SQL Server, este problema se evita porque el motor de almacenamiento garantiza que siempre seguirá los punteros de reenvío de inmediato. Si el análisis encuentra un registro que se ha reenviado, lo ignora. Con esta salvaguarda implementada, el optimizador de consultas no tiene que preocuparse por este escenario.
SCHEMABINDING y funciones escalares T-SQL
Hay muy pocas ocasiones en las que usar una función escalar T-SQL es una buena idea, pero si debe usar una, debe tener en cuenta un efecto importante que puede tener con respecto a la Protección de Halloween. A menos que se declare una función escalar con SCHEMABINDING opción, SQL Server asume que la función accede a las tablas. Para ilustrar, considere la función escalar T-SQL simple a continuación:
CREATE FUNCTION dbo.ReturnInput
(
@value integer
)
RETURNS integer
AS
BEGIN
RETURN @value;
END;
Esta función no accede a ninguna tabla; de hecho, no hace nada excepto devolver el valor del parámetro que se le pasó. Ahora mira lo siguiente INSERT consulta:
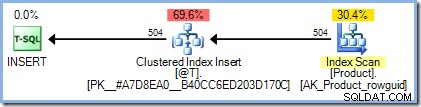
DECLARE @T AS TABLE (ProductID integer PRIMARY KEY); INSERT @T (ProductID) SELECT p.ProductID FROM AdventureWorks2012.Production.Product AS p;
El plan de ejecución es exactamente como esperábamos, sin necesidad de protección de Halloween:
Sin embargo, agregar nuestra función de no hacer nada tiene un efecto dramático:
DECLARE @T AS TABLE (ProductID integer PRIMARY KEY); INSERT @T (ProductID) SELECT dbo.ReturnInput(p.ProductID) FROM AdventureWorks2012.Production.Product AS p;

El plan de ejecución ahora incluye un Eager Table Spool para la protección de Halloween. SQL Server asume que la función accede a los datos, lo que podría incluir la lectura de la tabla Producto nuevamente. Como recordará, un INSERT El plan que contiene una referencia a la tabla de destino en el lado de lectura del plan requiere una protección completa de Halloween y, por lo que sabe el optimizador, ese podría ser el caso aquí.
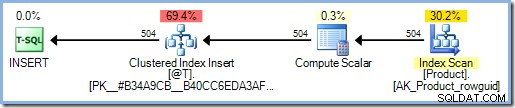
Agregando el SCHEMABINDING opción a la definición de la función significa que SQL Server examina el cuerpo de la función para determinar a qué tablas accede. No encuentra dicho acceso, por lo que no agrega ninguna Protección de Halloween:
ALTER FUNCTION dbo.ReturnInput
(
@value integer
)
RETURNS integer
WITH SCHEMABINDING
AS
BEGIN
RETURN @value;
END;
GO
DECLARE @T AS TABLE (ProductID int PRIMARY KEY);
INSERT @T (ProductID)
SELECT p.ProductID
FROM AdventureWorks2012.Production.Product AS p;
Este problema con las funciones escalares de T-SQL afecta a todas las consultas de actualización:INSERT , UPDATE , DELETE y MERGE . Saber cuándo se está enfrentando a este problema se hace más difícil porque la Protección de Halloween innecesaria no siempre se mostrará como un Eager Table Spool adicional, y las llamadas a funciones escalares pueden estar ocultas en vistas o definiciones de columnas calculadas, por ejemplo.
[ Parte 1 | Parte 2 | Parte 3 | Parte 4 ]