Hay muchos casos de uso para generar una secuencia de valores en SQL Server. No estoy hablando de una IDENTITY persistente columna (o la nueva SEQUENCE en SQL Server 2012), sino un conjunto transitorio que se usará solo durante el tiempo de vida de una consulta. O incluso los casos más simples, como simplemente agregar un número de fila a cada fila en un conjunto de resultados, lo que podría implicar agregar un ROW_NUMBER() función a la consulta (o, mejor aún, en el nivel de presentación, que tiene que recorrer los resultados fila por fila de todos modos).
Estoy hablando de casos un poco más complicados. Por ejemplo, puede tener un informe que muestre las ventas por fecha. Una consulta típica podría ser:
SELECT OrderDate = CONVERT(DATE, OrderDate), OrderCount = COUNT(*) FROM dbo.Orders GROUP BY CONVERT(DATE, OrderDate) ORDER BY OrderDate;
El problema de esta consulta es que, si no hay pedidos en un día determinado, no habrá fila para ese día. Esto puede generar confusión, datos engañosos o incluso cálculos incorrectos (piense en promedios diarios) para los consumidores intermedios de los datos.
Por lo tanto, es necesario llenar esos vacíos con las fechas que no están presentes en los datos. Y a veces la gente mete sus datos en una tabla #temp y usa un WHILE bucle o un cursor para completar las fechas que faltan una por una. No mostraré ese código aquí porque no quiero recomendar su uso, pero lo he visto por todas partes.
Sin embargo, antes de profundizar demasiado en las fechas, hablemos primero de los números, ya que siempre se puede usar una secuencia de números para derivar una secuencia de fechas.
Tabla de números
Durante mucho tiempo he sido un defensor de almacenar una "tabla de números" auxiliar en el disco (y, para el caso, también una tabla de calendario).
Aquí hay una forma de generar una tabla de números simples con 1,000,000 de valores:
SELECT TOP (1000000) n = CONVERT(INT, ROW_NUMBER() OVER (ORDER BY s1.[object_id])) INTO dbo.Numbers FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 OPTION (MAXDOP 1); CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(n) -- WITH (DATA_COMPRESSION = PAGE) ;
¿Por qué MAXDOP 1? Vea la publicación de blog de Paul White y su artículo de Connect relacionado con los objetivos de las filas.
Sin embargo, muchas personas se oponen al enfoque de la mesa auxiliar. Su argumento:¿por qué almacenar todos esos datos en el disco (y en la memoria) cuando pueden generar los datos sobre la marcha? Mi contador es ser realista y pensar en lo que estás optimizando; el cálculo puede ser costoso, y ¿está seguro de que calcular un rango de números sobre la marcha siempre será más barato? En cuanto al espacio, la tabla Numbers solo ocupa unos 11 MB comprimidos y 17 MB sin comprimir. Y si se hace referencia a la tabla con la suficiente frecuencia, siempre debe estar en la memoria, lo que agiliza el acceso.
Echemos un vistazo a algunos ejemplos y algunos de los enfoques más comunes utilizados para satisfacerlos. Espero que todos estemos de acuerdo en que, incluso con valores de 1000, no queremos resolver estos problemas usando un bucle o un cursor.
Generando una secuencia de 1000 números
Comenzando de manera simple, generemos un conjunto de números del 1 al 1000.
Tabla de números
Por supuesto, con una tabla de números, esta tarea es bastante simple:
SELECT TOP (1000) n FROM dbo.Numbers ORDER BY n;
Plano:
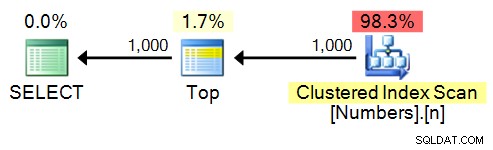
valores_spt
Esta es una tabla que utilizan los procedimientos almacenados internos para diversos fines. Su uso en línea parece ser bastante frecuente, a pesar de que no está documentado, no tiene soporte, puede desaparecer algún día y porque solo contiene un conjunto de valores finito, no único y no contiguo. Hay 2164 valores únicos y 2508 totales en SQL Server 2008 R2; en 2012 hay 2.167 únicos y 2.515 en total. Esto incluye duplicados, valores negativos e incluso si usa DISTINCT , muchas lagunas una vez que superas el número 2.048. Entonces, la solución es usar ROW_NUMBER() para generar una secuencia contigua, comenzando en 1, según los valores de la tabla.
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY number) FROM [master]..spt_values ORDER BY n;
Plano:

Dicho esto, para solo 1000 valores, podría escribir una consulta un poco más simple para generar la misma secuencia:
SELECT DISTINCT n = number FROM master..[spt_values] WHERE number BETWEEN 1 AND 1000;
Esto conduce a un plan más simple, por supuesto, pero se descompone bastante rápido (una vez que la secuencia debe tener más de 2048 filas):
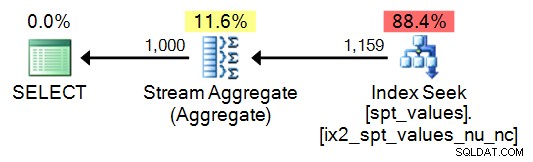
En cualquier caso, no recomiendo el uso de esta tabla; Lo incluyo con fines comparativos, solo porque sé cuánto de esto existe y lo tentador que puede ser simplemente reutilizar el código que encuentras.
sys.todos_los_objetos
Otro enfoque que ha sido uno de mis favoritos a lo largo de los años es usar sys.all_objects . Me gusta spt_values , no existe una forma confiable de generar una secuencia contigua directamente, y tenemos los mismos problemas con un conjunto finito (poco menos de 2000 filas en SQL Server 2008 R2 y poco más de 2000 filas en SQL Server 2012), pero para 1000 filas podemos usar el mismo ROW_NUMBER() truco. La razón por la que me gusta este enfoque es que (a) hay menos preocupación de que esta vista desaparezca pronto, (b) la vista en sí está documentada y es compatible, y (c) se ejecutará en cualquier base de datos en cualquier versión desde SQL Server. 2005 sin tener que cruzar los límites de la base de datos (incluidas las bases de datos independientes).
SELECT TOP (1000) n = ROW_NUMBER() OVER (ORDER BY [object_id]) FROM sys.all_objects ORDER BY n;
Plano:

CTE apilados
Creo que Itzik Ben-Gan merece el máximo crédito por este enfoque; básicamente, construye un CTE con un pequeño conjunto de valores, luego crea el producto cartesiano contra sí mismo para generar la cantidad de filas que necesita. Y de nuevo, en lugar de intentar generar un conjunto contiguo como parte de la consulta subyacente, podemos simplemente aplicar ROW_NUMBER() al resultado final.
;WITH e1(n) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
), -- 10
e2(n) AS (SELECT 1 FROM e1 CROSS JOIN e1 AS b), -- 10*10
e3(n) AS (SELECT 1 FROM e1 CROSS JOIN e2) -- 10*100
SELECT n = ROW_NUMBER() OVER (ORDER BY n) FROM e3 ORDER BY n; Plano:
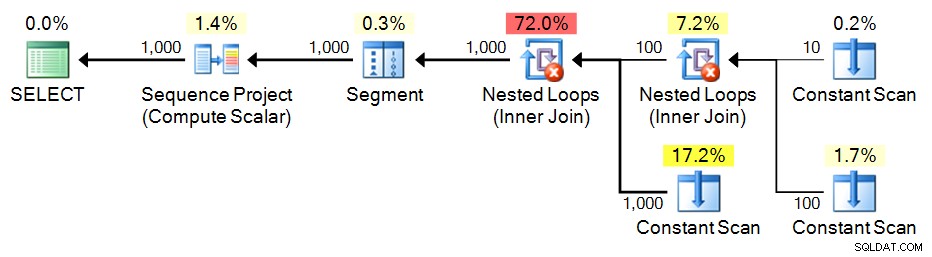
CTE recursivo
Finalmente, tenemos un CTE recursivo, que usa 1 como ancla y agrega 1 hasta que alcanzamos el máximo. Por seguridad, especifico el máximo tanto en WHERE cláusula de la porción recursiva, y en el MAXRECURSION entorno. Dependiendo de cuántos números necesite, es posible que deba configurar MAXRECURSION a 0 .
;WITH n(n) AS
(
SELECT 1
UNION ALL
SELECT n+1 FROM n WHERE n < 1000
)
SELECT n FROM n ORDER BY n
OPTION (MAXRECURSION 1000); Plano:
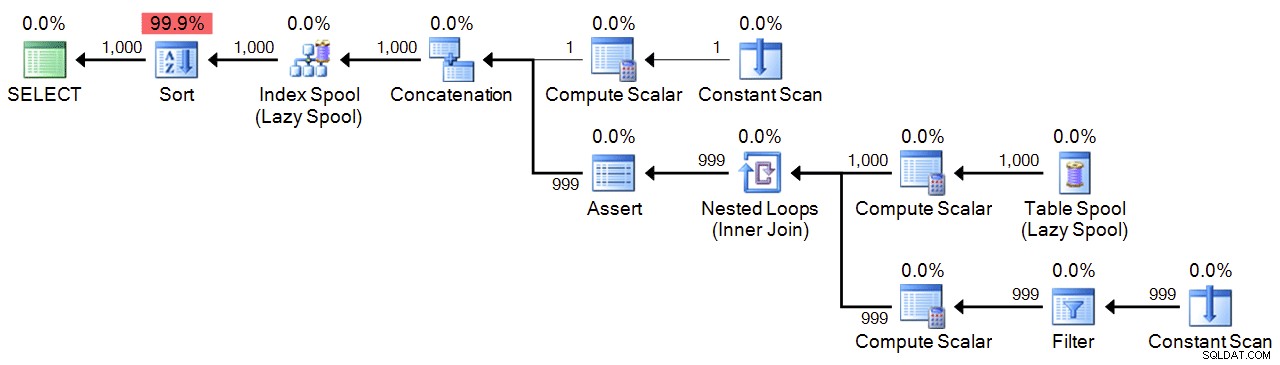
Rendimiento
Por supuesto, con 1000 valores, las diferencias en el rendimiento son insignificantes, pero puede ser útil ver cómo funcionan estas diferentes opciones:
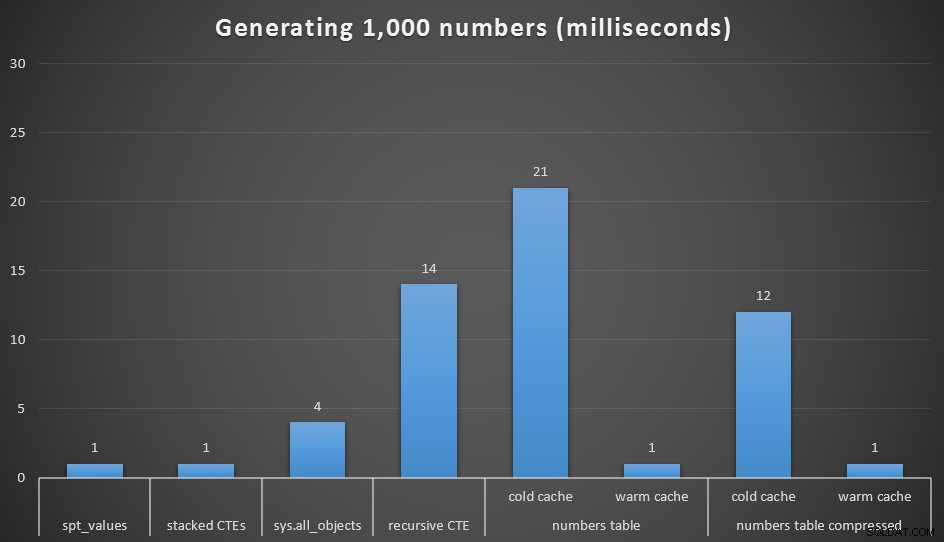
Tiempo de ejecución, en milisegundos, para generar 1000 números contiguos
Ejecuté cada consulta 20 veces y tomé tiempos de ejecución promedio. También probé el dbo.Numbers tabla, tanto en formato comprimido como sin comprimir, y con una caché fría y una caché cálida. Con un caché tibio, compite muy de cerca con las otras opciones más rápidas que existen (spt_values , no recomendado y CTE apilados), pero el primer golpe es relativamente caro (aunque casi me río llamándolo así).
Continuará...
Si este es su caso de uso típico y no se aventurará mucho más allá de las 1000 filas, entonces espero haber mostrado las formas más rápidas de generar esos números. Si su caso de uso es un número mayor, o si está buscando soluciones para generar secuencias de fechas, esté atento. Más adelante en esta serie, exploraré la generación de secuencias de 50 000 y 1 000 000 de números, y de intervalos de fechas que van desde una semana hasta un año.
[ Parte 1 | Parte 2 | Parte 3 ]



