En el mundo de SQL Server, hay dos tipos de personas:aquellos a los que les gusta que todos sus objetos tengan un prefijo y aquellos a los que no. El primer grupo se divide en dos categorías:aquellos que anteponen procedimientos almacenados con sp_ , y aquellos que eligen otros prefijos (como usp_ o proc_ ). Una recomendación de larga data ha sido evitar el sp_ prefijo, tanto por razones de rendimiento como para evitar ambigüedades o colisiones si elige un nombre que ya existe en el catálogo del sistema. Las colisiones ciertamente siguen siendo un problema, pero suponiendo que haya investigado el nombre de su objeto, ¿sigue siendo un problema de rendimiento?
Versión TL;DR:SÍ.
El prefijo sp_ sigue siendo un no-no. Pero en esta publicación explicaré por qué, cómo SQL Server 2012 podría llevarlo a creer que este consejo de precaución ya no se aplica y algunos otros posibles efectos secundarios de elegir esta convención de nomenclatura.
¿Cuál es el problema con sp_?
El sp_ prefijo no significa lo que crees que significa:la mayoría de la gente piensa sp significa "procedimiento almacenado" cuando en realidad significa "especial". Procedimientos almacenados (así como tablas y vistas) almacenados en maestro con un sp_ prefijo son accesibles desde cualquier base de datos sin una referencia adecuada (suponiendo que no exista una versión local). Si el procedimiento está marcado como un objeto del sistema (usando sp_MS_marksystemobject (un procedimiento del sistema no documentado y no compatible que establece is_ms_shipped a 1), entonces el procedimiento en maestro se ejecutará en el contexto de la base de datos que llama. Veamos un ejemplo simple:
CREATE DATABASE sp_test;
GO
USE sp_test;
GO
CREATE TABLE dbo.foo(id INT);
GO
USE master;
GO
CREATE PROCEDURE dbo.sp_checktable
AS
SELECT DB_NAME(), name
FROM sys.tables WHERE name = N'foo';
GO
USE sp_test;
GO
EXEC dbo.sp_checktable; -- runs but returns 0 results
GO
EXEC master..sp_MS_marksystemobject N'dbo.sp_checktable';
GO
EXEC dbo.sp_checktable; -- runs and returns results
GO Resultados:
(0 row(s) affected) sp_test foo (1 row(s) affected)
El problema de rendimiento proviene del hecho de que el maestro puede verificarse en busca de un procedimiento almacenado equivalente, dependiendo de si existe una versión local del procedimiento y si, de hecho, hay un objeto equivalente en el maestro. Esto puede generar una sobrecarga de metadatos adicional, así como un SP:CacheMiss adicional. evento. La pregunta es si estos gastos generales son tangibles.
Entonces, consideremos un procedimiento muy simple en una base de datos de prueba:
CREATE DATABASE sp_prefix; GO USE sp_prefix; GO CREATE PROCEDURE dbo.sp_something AS BEGIN SELECT 'sp_prefix', DB_NAME(); END GO
Y procedimientos equivalentes en master:
USE master; GO CREATE PROCEDURE dbo.sp_something AS BEGIN SELECT 'master', DB_NAME(); END GO EXEC sp_MS_marksystemobject N'sp_something';
CacheMiss:¿realidad o ficción?
Si ejecutamos una prueba rápida desde nuestra base de datos de prueba, vemos que la ejecución de estos procedimientos almacenados nunca invocará las versiones del maestro, independientemente de si calificamos correctamente el procedimiento con la base de datos o el esquema (un error común) o si marcamos el versión maestra como objeto del sistema:
USE sp_prefix; GO EXEC sp_prefix.dbo.sp_something; GO EXEC dbo.sp_something; GO EXEC sp_something;
Resultados:
sp_prefix sp_prefix sp_prefix sp_prefix sp_prefix sp_prefix
Ejecutemos también un Quick TraceSP:CacheMiss eventos:
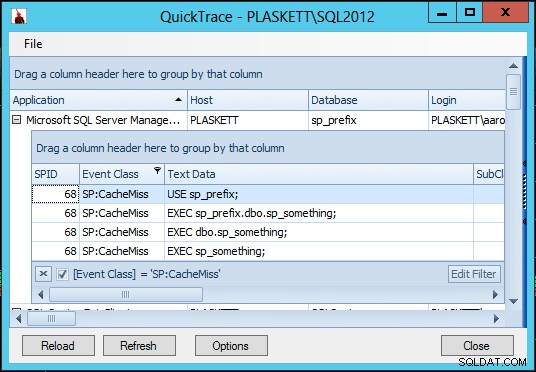
Vemos CacheMiss eventos para el lote ad hoc que llama al procedimiento almacenado (dado que SQL Server generalmente no se molesta en almacenar en caché un lote que consiste principalmente en llamadas a procedimientos), pero no para el procedimiento almacenado en sí. Con y sin sp_something procedimiento existente en el maestro (y cuando existe, con y sin estar marcado como un objeto del sistema), las llamadas a sp_something en la base de datos del usuario, nunca llame "accidentalmente" al procedimiento en el maestro, y nunca genere ningún CacheMiss eventos para el procedimiento.
Esto fue en SQL Server 2012. Repetí las mismas pruebas anteriores en SQL Server 2008 R2 y encontré resultados ligeramente diferentes:
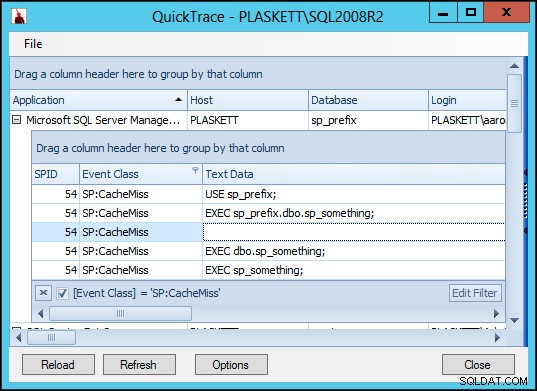
Así que en SQL Server 2008 R2 vemos un CacheMiss adicional evento que no ocurre en SQL Server 2012. Esto ocurre en todos los escenarios (ningún objeto maestro equivalente, un objeto en el maestro marcado como un objeto del sistema y un objeto en el maestro no marcado como un objeto del sistema). Inmediatamente tuve curiosidad por saber si este evento adicional tendría un impacto notable en el rendimiento.
Problema de rendimiento:¿realidad o ficción?
Hice un procedimiento adicional sin el sp_ prefijo para comparar el rendimiento bruto, CacheMiss aparte:
USE sp_prefix; GO CREATE PROCEDURE dbo.proc_something AS BEGIN SELECT 'sp_prefix', DB_NAME(); END GO
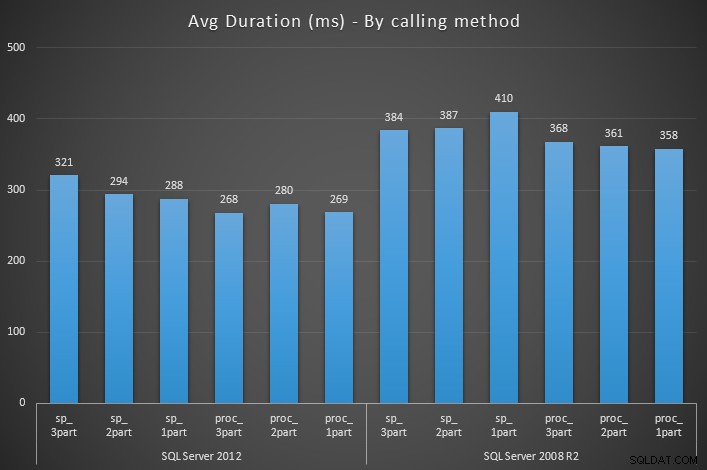
Así que la única diferencia entre sp_something y proc_something . Luego creé procedimientos de contenedor para ejecutarlos 1000 veces cada uno, usando EXEC sp_prefix.dbo.<procname> , EXEC dbo.<procname> y EXEC <procname> sintaxis, con procedimientos almacenados equivalentes viviendo en el maestro y marcados como un objeto del sistema, viviendo en el maestro pero no marcados como un objeto del sistema, y no viviendo en el maestro en absoluto.
USE sp_prefix;
GO
CREATE PROCEDURE dbo.wrap_sp_3part
AS
BEGIN
DECLARE @i INT = 1;
WHILE @i <= 1000
BEGIN
EXEC sp_prefix.dbo.sp_something;
SET @i += 1;
END
END
GO
CREATE PROCEDURE dbo.wrap_sp_2part
AS
BEGIN
DECLARE @i INT = 1;
WHILE @i <= 1000
BEGIN
EXEC dbo.sp_something;
SET @i += 1;
END
END
GO
CREATE PROCEDURE dbo.wrap_sp_1part
AS
BEGIN
DECLARE @i INT = 1;
WHILE @i <= 1000
BEGIN
EXEC sp_something;
SET @i += 1;
END
END
GO
-- repeat for proc_something
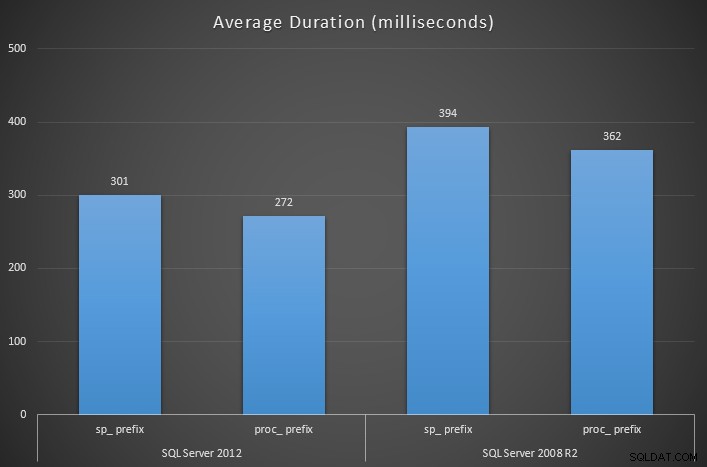
Al medir la duración del tiempo de ejecución de cada procedimiento contenedor con SQL Sentry Plan Explorer, los resultados muestran que usar sp_ El prefijo tiene un impacto significativo en la duración promedio en casi todos los casos (y ciertamente en el promedio):