Algunas discusiones interesantes siempre se desarrollan en torno al tema de dividir hilos. En dos publicaciones de blog anteriores, "Dividir cadenas de la manera correcta, o la siguiente mejor manera" y "Dividir cadenas:un seguimiento", espero haber demostrado que perseguir la función de división T-SQL de "mejor rendimiento" es infructuoso. . Cuando la división es realmente necesaria, CLR siempre gana, y la siguiente mejor opción puede variar según la tarea real en cuestión. Pero en esas publicaciones insinué que la división en el lado de la base de datos puede no ser necesaria en primer lugar.
SQL Server 2008 introdujo parámetros con valores de tabla, una forma de pasar una "tabla" de una aplicación a un procedimiento almacenado sin tener que construir y analizar una cadena, serializar a XML o lidiar con esta metodología de división. Así que pensé en comprobar cómo se compara este método con el ganador de nuestras pruebas anteriores, ya que puede ser una opción viable, ya sea que pueda usar CLR o no. (Para conocer la biblia definitiva sobre los TVP, consulte el artículo completo de Erland Sommarskog, MVP de SQL Server).
Las Pruebas
Para esta prueba voy a pretender que estamos tratando con un conjunto de cadenas de versiones. Imagine una aplicación de C# que pasa un conjunto de estas cadenas (por ejemplo, que se recopilaron de un conjunto de usuarios) y necesitamos comparar las versiones con una tabla (por ejemplo, que indica las versiones de servicio que se aplican a un conjunto específico). de versiones). Obviamente, una aplicación real tendría más columnas que esta, pero solo para crear algo de volumen y mantener la tabla delgada (también uso NVARCHAR porque eso es lo que toma la función de división CLR y quiero eliminar cualquier ambigüedad debido a la conversión implícita) :
CREATE TABLE dbo.VersionStrings(left_post NVARCHAR(5), right_post NVARCHAR(5)); CREATE CLUSTERED INDEX x ON dbo.VersionStrings(left_post, right_post); ;WITH x AS ( SELECT lp = CONVERT(DECIMAL(4,3), RIGHT(RTRIM(s1.[object_id]), 3)/1000.0) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ) INSERT dbo.VersionStrings ( left_post, right_post ) SELECT lp - CASE WHEN lp >= 0.9 THEN 0.1 ELSE 0 END, lp + (0.1 * CASE WHEN lp >= 0.9 THEN -1 ELSE 1 END) FROM x;
Ahora que los datos están en su lugar, lo siguiente que debemos hacer es crear un tipo de tabla definida por el usuario que pueda contener un conjunto de cadenas. El tipo de tabla inicial para contener esta cadena es bastante simple:
CREATE TYPE dbo.VersionStringsTVP AS TABLE (VersionString NVARCHAR(5));
Luego necesitamos un par de procedimientos almacenados para aceptar las listas de C#. Para simplificar, de nuevo, solo contaremos para asegurarnos de realizar un análisis completo e ignoraremos el recuento en la aplicación:
CREATE PROCEDURE dbo.SplitTest_UsingCLR
@list NVARCHAR(MAX)
AS
BEGIN
SET NOCOUNT ON;
SELECT c = COUNT(*)
FROM dbo.VersionStrings AS v
INNER JOIN dbo.SplitStrings_CLR(@list, N',') AS s
ON s.Item BETWEEN v.left_post AND v.right_post;
END
GO
CREATE PROCEDURE dbo.SplitTest_UsingTVP
@list dbo.VersionStringsTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
SELECT c = COUNT(*)
FROM dbo.VersionStrings AS v
INNER JOIN @list AS l
ON l.VersionString BETWEEN v.left_post AND v.right_post;
END
GO Tenga en cuenta que un TVP pasado a un procedimiento almacenado debe marcarse como READONLY; actualmente no hay forma de realizar DML en los datos como lo haría con una variable de tabla o una tabla temporal. Sin embargo, Erland ha presentado una solicitud muy popular para que Microsoft haga que estos parámetros sean más flexibles (y mucha información más profunda detrás de su argumento aquí).
La belleza aquí es que SQL Server ya no tiene que lidiar con la división de una cadena, ni en T-SQL ni en entregarla a CLR, ya que se encuentra en una estructura establecida donde sobresale.
A continuación, una aplicación de consola C# que hace lo siguiente:
- Acepta un número como argumento para indicar cuántos elementos de cadena deben definirse
- Construye una cadena CSV de esos elementos, usando StringBuilder, para pasar al procedimiento almacenado CLR
- Construye un DataTable con los mismos elementos para pasar al procedimiento almacenado TVP
- También prueba la sobrecarga de convertir una cadena CSV en una tabla de datos y viceversa antes de llamar a los procedimientos almacenados apropiados
El código de la aplicación C# se encuentra al final del artículo. Puedo deletrear C#, pero de ninguna manera soy un gurú; Estoy seguro de que hay ineficiencias que puede detectar allí que pueden hacer que el código funcione un poco mejor. Pero cualquier cambio de este tipo debería afectar a todo el conjunto de pruebas de manera similar.
Ejecuté la aplicación 10 veces usando 100, 1000, 2500 y 5000 elementos. Los resultados fueron los siguientes (esto muestra la duración promedio, en segundos, en las 10 pruebas):
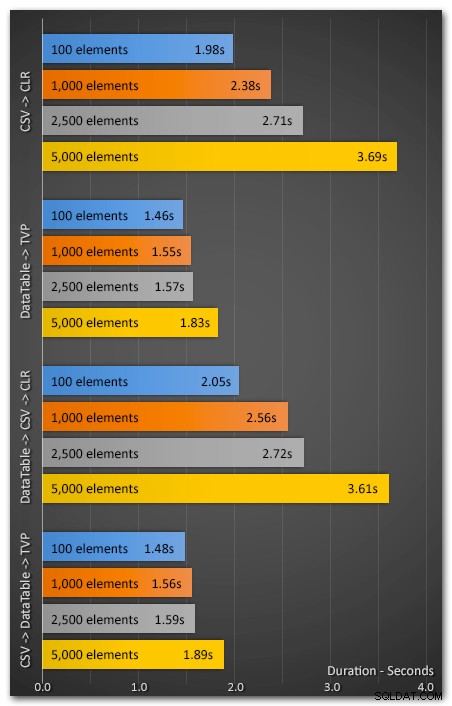
Aparte del rendimiento...
Además de la clara diferencia de rendimiento, los TVP tienen otra ventaja:los tipos de tabla son mucho más simples de implementar que los ensamblajes CLR, especialmente en entornos donde CLR ha sido prohibido por otras razones. Espero que las barreras para CLR desaparezcan gradualmente y que las nuevas herramientas hagan que la implementación y el mantenimiento sean menos dolorosos, pero dudo que la facilidad de implementación inicial para CLR sea más fácil que los enfoques nativos.
Por otro lado, además de la limitación de solo lectura, los tipos de tabla son como tipos de alias en el sentido de que son difíciles de modificar después del hecho. Si desea cambiar el tamaño de una columna o agregar una columna, no hay un comando ALTER TYPE, y para DROP el tipo y volver a crearlo, primero debe eliminar las referencias al tipo de todos los procedimientos que lo utilizan. . Entonces, por ejemplo, en el caso anterior, si necesitáramos aumentar la columna VersionString a NVARCHAR (32), tendríamos que crear un tipo ficticio y modificar el procedimiento almacenado (y cualquier otro procedimiento que lo esté usando):
CREATE TYPE dbo.VersionStringsTVPCopy AS TABLE (VersionString NVARCHAR(32)); GO ALTER PROCEDURE dbo.SplitTest_UsingTVP @list dbo.VersionStringsTVPCopy READONLY AS ... GO DROP TYPE dbo.VersionStringsTVP; GO CREATE TYPE dbo.VersionStringsTVP AS TABLE (VersionString NVARCHAR(32)); GO ALTER PROCEDURE dbo.SplitTest_UsingTVP @list dbo.VersionStringsTVP READONLY AS ... GO DROP TYPE dbo.VersionStringsTVPCopy; GO
(O alternativamente, descarte el procedimiento, descarte el tipo, vuelva a crear el tipo y vuelva a crear el procedimiento).
Conclusión
El método TVP superó sistemáticamente al método de división CLR, y en un porcentaje mayor a medida que aumentaba el número de elementos. Incluso agregar la sobrecarga de convertir una cadena CSV existente en una tabla de datos produjo un rendimiento de extremo a extremo mucho mejor. Así que espero que, si no lo he convencido ya de que abandone sus técnicas de división de cadenas T-SQL en favor de CLR, lo he instado a darle una oportunidad a los parámetros con valores de tabla. Debería ser fácil de probar incluso si actualmente no está utilizando un DataTable (o algún equivalente).
El código C# utilizado para estas pruebas
Como dije, no soy un gurú de C#, por lo que probablemente haya muchas cosas ingenuas que estoy haciendo aquí, pero la metodología debería ser bastante clara.
using System;
using System.IO;
using System.Data;
using System.Data.SqlClient;
using System.Text;
using System.Collections;
namespace SplitTester
{
class SplitTester
{
static void Main(string[] args)
{
DataTable dt_pure = new DataTable();
dt_pure.Columns.Add("Item", typeof(string));
StringBuilder sb_pure = new StringBuilder();
Random r = new Random();
for (int i = 1; i <= Int32.Parse(args[0]); i++)
{
String x = r.NextDouble().ToString().Substring(0,5);
sb_pure.Append(x).Append(",");
dt_pure.Rows.Add(x);
}
using
(
SqlConnection conn = new SqlConnection(@"Data Source=.;
Trusted_Connection=yes;Initial Catalog=Splitter")
)
{
conn.Open();
// four cases:
// (1) pass CSV string directly to CLR split procedure
// (2) pass DataTable directly to TVP procedure
// (3) serialize CSV string from DataTable and pass CSV to CLR procedure
// (4) populate DataTable from CSV string and pass DataTable to TCP procedure
// ********** (1) ********** //
write(Environment.NewLine + "Starting (1)");
SqlCommand c1 = new SqlCommand("dbo.SplitTest_UsingCLR", conn);
c1.CommandType = CommandType.StoredProcedure;
c1.Parameters.AddWithValue("@list", sb_pure.ToString());
c1.ExecuteNonQuery();
c1.Dispose();
write("Finished (1)");
// ********** (2) ********** //
write(Environment.NewLine + "Starting (2)");
SqlCommand c2 = new SqlCommand("dbo.SplitTest_UsingTVP", conn);
c2.CommandType = CommandType.StoredProcedure;
SqlParameter tvp1 = c2.Parameters.AddWithValue("@list", dt_pure);
tvp1.SqlDbType = SqlDbType.Structured;
c2.ExecuteNonQuery();
c2.Dispose();
write("Finished (2)");
// ********** (3) ********** //
write(Environment.NewLine + "Starting (3)");
StringBuilder sb_fake = new StringBuilder();
foreach (DataRow dr in dt_pure.Rows)
{
sb_fake.Append(dr.ItemArray[0].ToString()).Append(",");
}
SqlCommand c3 = new SqlCommand("dbo.SplitTest_UsingCLR", conn);
c3.CommandType = CommandType.StoredProcedure;
c3.Parameters.AddWithValue("@list", sb_fake.ToString());
c3.ExecuteNonQuery();
c3.Dispose();
write("Finished (3)");
// ********** (4) ********** //
write(Environment.NewLine + "Starting (4)");
DataTable dt_fake = new DataTable();
dt_fake.Columns.Add("Item", typeof(string));
string[] list = sb_pure.ToString().Split(',');
for (int i = 0; i < list.Length; i++)
{
if (list[i].Length > 0)
{
dt_fake.Rows.Add(list[i]);
}
}
SqlCommand c4 = new SqlCommand("dbo.SplitTest_UsingTVP", conn);
c4.CommandType = CommandType.StoredProcedure;
SqlParameter tvp2 = c4.Parameters.AddWithValue("@list", dt_fake);
tvp2.SqlDbType = SqlDbType.Structured;
c4.ExecuteNonQuery();
c4.Dispose();
write("Finished (4)");
}
}
static void write(string msg)
{
Console.WriteLine(msg + ": "
+ DateTime.UtcNow.ToString("HH:mm:ss.fffff"));
}
}
}