SQL Server tradicionalmente se ha negado a proporcionar soluciones nativas a algunas de las preguntas estadísticas más comunes, como calcular una mediana. Según WikiPedia, "la mediana se describe como el valor numérico que separa la mitad superior de una muestra, una población o una distribución de probabilidad de la mitad inferior. La mediana de una lista finita de números se puede encontrar organizando todas las observaciones de valor más bajo al valor más alto y seleccionando el medio. Si hay un número par de observaciones, entonces no hay un solo valor medio; la mediana generalmente se define como la media de los dos valores medios".
En términos de una consulta de SQL Server, la clave que sacará es que necesita "organizar" (ordenar) todos los valores. Ordenar en SQL Server suele ser una operación bastante costosa si no hay un índice de respaldo, y agregar un índice para respaldar una operación que probablemente no se solicite que a menudo no valga la pena.
Examinemos cómo hemos resuelto normalmente este problema en versiones anteriores de SQL Server. Primero, creemos una tabla muy simple para que podamos observar que nuestra lógica es correcta y derivar una mediana precisa. Podemos probar las siguientes dos tablas, una con un número par de filas y la otra con un número impar de filas:
CREATE TABLE dbo.EvenRows ( id INT PRIMARY KEY, val INT );
CREATE TABLE dbo.OddRows ( id INT PRIMARY KEY, val INT );
INSERT dbo.EvenRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4
UNION ALL SELECT 8, 9;
INSERT dbo.OddRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4;
DECLARE @Median DECIMAL(12, 2); Solo por observación casual, podemos ver que la mediana para la tabla con filas impares debe ser 6, y para la tabla par debe ser 7.5 ((6+9)/2). Así que ahora veamos algunas soluciones que se han utilizado a lo largo de los años:
Servidor SQL 2000
En SQL Server 2000, estábamos limitados a un dialecto T-SQL muy limitado. Estoy investigando estas opciones para comparar porque algunas personas aún ejecutan SQL Server 2000, y otras pueden haber actualizado pero, dado que sus cálculos medios se escribieron "en el pasado", el código aún podría verse así hoy.
2000_A:máximo de una mitad, mínimo de la otra
Este enfoque toma el valor más alto del primer 50 por ciento, el valor más bajo del último 50 por ciento, y luego los divide por dos. Esto funciona para filas pares o impares porque, en el caso par, los dos valores son las dos filas del medio, y en el caso impar, los dos valores son en realidad de la misma fila.
SELECT @Median = (
(SELECT MAX(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val, id) AS t)
+ (SELECT MIN(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val DESC, id DESC) AS b)
) / 2.0; 2000_B – #tabla temporal
Este ejemplo primero crea una tabla #temp y, usando el mismo tipo de matemática que arriba, determina las dos filas "centrales" con la ayuda de una IDENTITY contigua columna ordenada por la columna val. (El orden de asignación de IDENTITY solo se puede confiar en los valores debido al MAXDOP ajuste.)
CREATE TABLE #x
(
i INT IDENTITY(1,1),
val DECIMAL(12, 2)
);
CREATE CLUSTERED INDEX v ON #x(val);
INSERT #x(val)
SELECT val
FROM dbo.EvenRows
ORDER BY val OPTION (MAXDOP 1);
SELECT @Median = AVG(val)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE x.i - (SELECT MAX(i) / 2.0 FROM #x) IN (0, 0.5, 1)
);
Servidor SQL 2005, 2008, 2008 R2
SQL Server 2005 introdujo algunas funciones de ventana nuevas e interesantes, como ROW_NUMBER() , que puede ayudar a resolver problemas estadísticos como la mediana un poco más fácilmente que en SQL Server 2000. Todos estos enfoques funcionan en SQL Server 2005 y superior:
2005_A:números de fila en duelo
Este ejemplo usa ROW_NUMBER() para subir y bajar los valores una vez en cada dirección, luego encuentra la fila "media" o dos según ese cálculo. Esto es bastante similar al primer ejemplo anterior, con una sintaxis más sencilla:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT val,
ra = ROW_NUMBER() OVER (ORDER BY val, id),
rd = ROW_NUMBER() OVER (ORDER BY val DESC, id DESC)
FROM dbo.EvenRows
) AS x
WHERE ra BETWEEN rd - 1 AND rd + 1; 2005_B:número de fila + recuento
Este es bastante similar al anterior, utilizando un único cálculo de ROW_NUMBER() y luego usando el total COUNT() para encontrar la "media" una o dos filas:
SELECT @Median = AVG(1.0 * Val)
FROM
(
SELECT val,
c = COUNT(*) OVER (),
rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.EvenRows
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2); 2005_C:variación del número de fila + recuento
El compañero MVP Itzik Ben-Gan me mostró este método, que logra la misma respuesta que los dos métodos anteriores, pero de una manera ligeramente diferente:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT o.val, rn = ROW_NUMBER() OVER (ORDER BY o.val), c.c
FROM dbo.EvenRows AS o
CROSS JOIN (SELECT c = COUNT(*) FROM dbo.EvenRows) AS c
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2);
Servidor SQL 2012
En SQL Server 2012, tenemos nuevas capacidades de ventanas en T-SQL que permiten que los cálculos estadísticos como la mediana se expresen de manera más directa. Para calcular la mediana de un conjunto de valores, podemos usar PERCENTILE_CONT() . También podemos usar la nueva extensión "paginación" para ORDER BY cláusula (OFFSET / FETCH ).
2012_A:nueva funcionalidad de distribución
Esta solución utiliza un cálculo muy sencillo mediante la distribución (si no desea el promedio entre los dos valores medios en el caso de un número par de filas).
SELECT @Median = PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY val) OVER () FROM dbo.EvenRows;
2012_B:truco de buscapersonas
Este ejemplo implementa un uso inteligente de OFFSET / FETCH (y no exactamente uno para el que estaba destinado):simplemente nos movemos a la fila que es uno antes de la mitad del conteo, luego tomamos las siguientes una o dos filas dependiendo de si el conteo fue par o impar. Gracias a Itzik Ben-Gan por señalar este enfoque.
DECLARE @c BIGINT = (SELECT COUNT(*) FROM dbo.EvenRows);
SELECT AVG(1.0 * val)
FROM (
SELECT val FROM dbo.EvenRows
ORDER BY val
OFFSET (@c - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @c % 2) ROWS ONLY
) AS x;
¿Pero cuál funciona mejor?
Hemos verificado que todos los métodos anteriores producen los resultados esperados en nuestra mesita y sabemos que la versión de SQL Server 2012 tiene la sintaxis más limpia y lógica. Pero, ¿cuál debería usar en su ajetreado entorno de producción? Podemos construir una tabla mucho más grande a partir de los metadatos del sistema, asegurándonos de tener muchos valores duplicados. Este script producirá una tabla con 10 000 000 enteros no únicos:
USE tempdb; GO CREATE TABLE dbo.obj(id INT IDENTITY(1,1), val INT); CREATE CLUSTERED INDEX x ON dbo.obj(val, id); INSERT dbo.obj(val) SELECT TOP (10000000) o.[object_id] FROM sys.all_columns AS c CROSS JOIN sys.all_objects AS o CROSS JOIN sys.all_objects AS o2 WHERE o.[object_id] > 0 ORDER BY c.[object_id];
En mi sistema, la mediana de esta tabla debería ser 146 099 561. Puedo calcular esto bastante rápido sin una verificación manual de 10,000,000 de filas usando la siguiente consulta:
SELECT val FROM
(
SELECT val, rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.obj
) AS x
WHERE rn IN (4999999, 5000000, 5000001); Resultados:
val rn ---- ---- 146099561 4999999 146099561 5000000 146099561 5000001
Entonces, ahora podemos crear un procedimiento almacenado para cada método, verificar que cada uno produzca el resultado correcto y luego medir las métricas de rendimiento, como la duración, la CPU y las lecturas. Realizaremos todos estos pasos con la tabla existente y también con una copia de la tabla que no se beneficie del índice agrupado (la descartaremos y volveremos a crear la tabla como un montón).
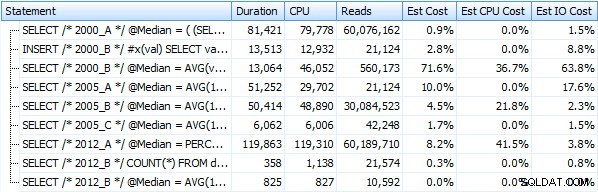
He creado siete procedimientos que implementan los métodos de consulta anteriores. Por brevedad, no los enumeraré aquí, pero cada uno se llama dbo.Median_<version> , p.ej. dbo.Median_2000_A , dbo.Median_2000_B , etc. correspondientes a los enfoques descritos anteriormente. Si ejecutamos estos siete procedimientos con SQL Sentry Plan Explorer gratuito, esto es lo que observamos en términos de duración, CPU y lecturas (tenga en cuenta que ejecutamos DBCC FREEPROCCACHE y DBCC DROPCLEANBUFFERS entre ejecuciones):
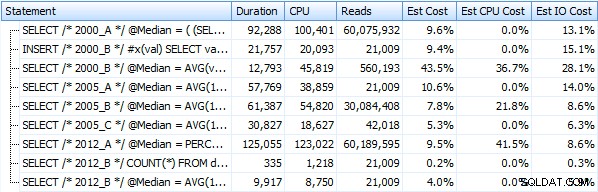
Y estas métricas no cambian mucho si operamos contra un montón. El mayor cambio porcentual fue el método que terminó siendo el más rápido:el truco de paginación usando OFFSET / FETCH:
Aquí hay una representación gráfica de los resultados. Para que quede más claro, resalté en rojo el de menor rendimiento y en verde el de enfoque más rápido.
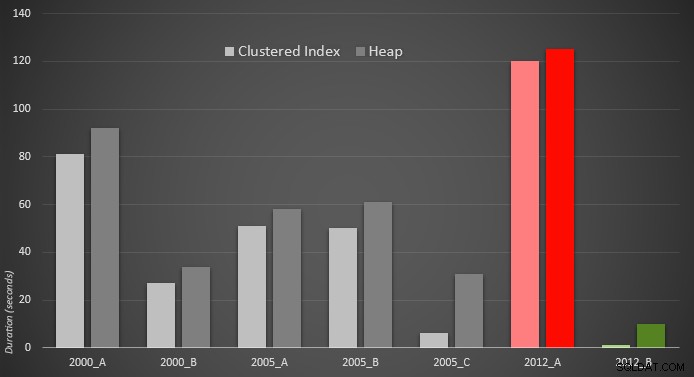
Me sorprendió ver que, en ambos casos, PERCENTILE_CONT() – que fue diseñado para este tipo de cálculo – en realidad es peor que todas las otras soluciones anteriores. Supongo que solo demuestra que, si bien a veces la sintaxis más nueva puede facilitar nuestra codificación, no siempre garantiza que el rendimiento mejore. También me sorprendió ver OFFSET / FETCH demuestra ser tan útil en escenarios que normalmente no parecerían cumplir su propósito:la paginación.
En cualquier caso, espero haber demostrado qué enfoque debe usar, dependiendo de su versión de SQL Server (y que la elección debe ser la misma, ya sea que tenga o no un índice de soporte para el cálculo).