Tener tablas de referencia en su base de datos no es gran cosa, ¿verdad? Solo necesita vincular un código o ID con una descripción para cada tipo de referencia. Pero, ¿y si literalmente tienes docenas y docenas de tablas de referencia? ¿Existe una alternativa al enfoque de una tabla por tipo? Siga leyendo para descubrir un genérico y extensible diseño de base de datos para manejar todos sus datos de referencia.
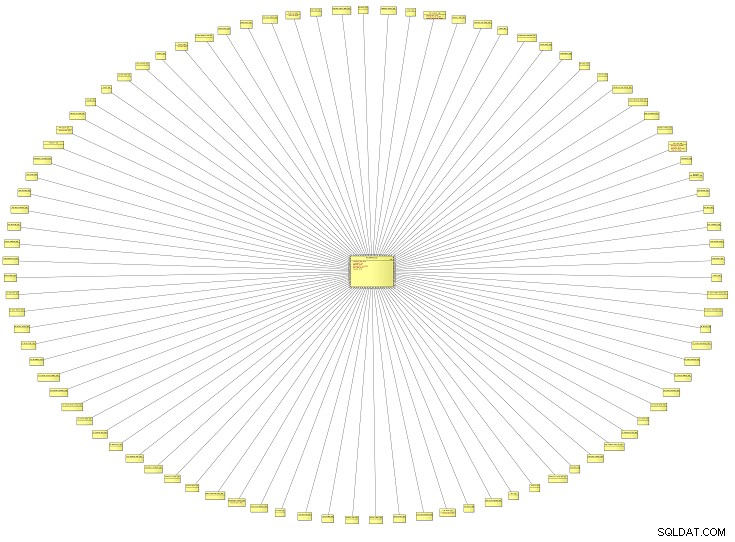
Este diagrama de aspecto inusual es una vista panorámica de un modelo de datos lógicos (LDM) que contiene todos los tipos de referencia para un sistema empresarial. Es de una institución educativa, pero podría aplicarse al modelo de datos de cualquier tipo de organización. Cuanto más grande sea el modelo, más tipos de referencia es probable que descubras.
Por tipos de referencia me refiero a datos de referencia, o valores de búsqueda o, si quieres ser flash, taxonomías. . Por lo general, los valores definidos aquí se usan en listas desplegables en la interfaz de usuario de su aplicación. También pueden aparecer como encabezados en un informe.
Este modelo de datos en particular tenía alrededor de 100 tipos de referencia. Acerquémonos y veamos solo dos de ellos.
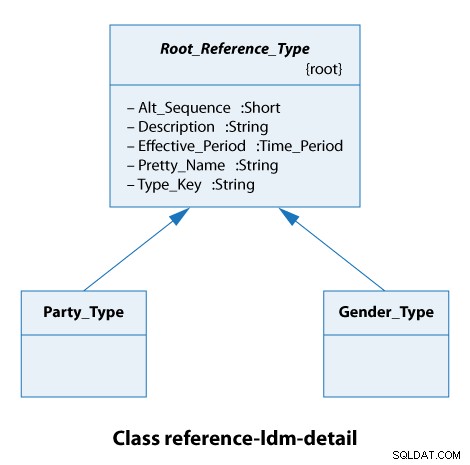
En este diagrama de clases, vemos que todos los tipos de referencia amplían el Root_Reference_Type . En la práctica, esto solo significa que todos nuestros tipos de referencia tienen los mismos atributos de Alt_Sequence hasta Type_Key inclusive, como se muestra a continuación.
| Atributo | Descripción |
|---|---|
Alt_Sequence | Se utiliza para definir una secuencia alternativa cuando se requiere un orden no alfabético. |
Description | La descripción del tipo. |
Effective_Period | Define efectivamente si la entrada de referencia está habilitada o no. Una vez que se ha utilizado una referencia, no se puede eliminar debido a restricciones referenciales; solo se puede deshabilitar. |
| El bonito nombre para el tipo. Esto es lo que el usuario ve en la pantalla. |
Type_Key | La CLAVE interna única para el tipo. Esto está oculto para el usuario, pero los desarrolladores de aplicaciones pueden hacer un uso extensivo de esto en su SQL. |
El tipo de partido aquí es una organización o una persona. Los tipos de género son masculino y femenino. Así que estos son casos realmente simples.
La solución de tabla de referencia tradicional
Entonces, ¿cómo vamos a implementar el modelo lógico en el mundo físico de una base de datos real?
Podríamos considerar que cada tipo de referencia se asignará a su propia tabla. Puede referirse a esto como el más tradicional one-table-per-class solución. Es bastante simple y se vería así:
La desventaja de esto es que podría haber docenas y docenas de estas tablas, todas con las mismas columnas, todas haciendo prácticamente lo mismo.
Además, es posible que estemos creando mucho más trabajo de desarrollo . Si se requiere una interfaz de usuario para cada tipo para que los administradores mantengan los valores, la cantidad de trabajo se multiplica rápidamente. No existen reglas estrictas y rápidas para esto, realmente depende de su entorno de desarrollo, por lo que deberá hablar con sus desarrolladores para entender qué impacto tiene esto.
Pero dado que todos nuestros tipos de referencia tienen los mismos atributos o columnas, ¿existe una forma más genérica de implementar nuestro modelo de datos lógicos? ¡Sí hay! Y solo requiere dos mesas .
La solución de dos mesas
La primera discusión que tuve sobre este tema fue a mediados de los 90, cuando trabajaba para una compañía de seguros del Mercado de Londres. En aquel entonces, pasamos directamente al diseño físico y usamos principalmente claves naturales/comerciales, no identificaciones. Cuando existían datos de referencia, decidimos mantener una tabla por tipo que estaba compuesta por un código único (el VARCHAR PK) y una descripción. De hecho, había muchas menos tablas de referencia entonces. La mayoría de las veces, se usaría un conjunto restringido de códigos comerciales en una columna, posiblemente con una restricción de verificación de base de datos definida; no habría tabla de referencia en absoluto.
Pero el juego ha avanzado desde entonces. Esto es lo que una solución de dos mesas podría verse como:
Como puede ver, este modelo de datos físicos es muy simple. Pero es bastante diferente del modelo lógico, y no porque algo se haya torcido. Es porque se hicieron varias cosas como parte del diseño físico .
El reference_type La tabla representa cada clase de referencia individual del LDM. Entonces, si tiene 20 tipos de referencia en su LDM, tendrá 20 filas de metadatos en la tabla. El reference_value la tabla contiene los valores permitidos para todos los tipos de referencia.
En el momento de este proyecto, hubo algunas discusiones bastante animadas entre los desarrolladores. Algunos preferían la solución de dos mesas y otros preferían la una-mesa-por-tipo método.
Hay ventajas y desventajas para cada solución. Como puede suponer, los desarrolladores estaban principalmente preocupados por la cantidad de trabajo que tomaría la interfaz de usuario. Algunos pensaron que crear una interfaz de usuario de administrador para cada tabla sería bastante rápido. Otros pensaron que crear una sola interfaz de usuario de administrador sería más complejo pero finalmente valdría la pena.
En este proyecto en particular, se favoreció la solución de dos mesas. Veámoslo con más detalle.
El patrón de datos de referencia extensible y flexible
A medida que su modelo de datos evoluciona con el tiempo y se requieren nuevos tipos de referencia, no necesita seguir realizando cambios en su base de datos para cada nuevo tipo de referencia. Solo necesita definir nuevos datos de configuración. Para hacer esto, agrega una nueva fila al reference_type y agregue su lista controlada de valores permitidos al reference_value mesa.
Un concepto importante contenido en esta solución es el de definir períodos de tiempo efectivos para ciertos valores. Por ejemplo, es posible que su organización necesite capturar un nuevo reference_value de 'Prueba de identificación' que será aceptable en una fecha futura. Es una simple cuestión de agregar ese nuevo reference_value con el effective_period_from fecha correctamente configurada. Esto se puede hacer con anticipación. Hasta que llegue esa fecha no aparecerá la nueva entrada en la lista desplegable de valores que ven los usuarios de su aplicación. Esto se debe a que su aplicación solo muestra valores que están actualizados o habilitados.
Por otro lado, es posible que deba evitar que los usuarios usen un reference_value . En ese caso, simplemente actualícelo con effective_period_to fecha correctamente configurada. Cuando pase ese día, el valor ya no aparecerá en la lista desplegable. Se desactiva a partir de ese momento. Pero debido a que todavía existe físicamente como una fila en la tabla, se mantiene la integridad referencial para aquellas tablas donde ya ha sido referenciado.
Ahora que estábamos trabajando en la solución de dos tablas, se hizo evidente que algunas columnas adicionales serían útiles en el reference_type mesa. Estos se centraron principalmente en preocupaciones de interfaz de usuario.
Por ejemplo, pretty_name en el reference_type La tabla se agregó para su uso en la interfaz de usuario. Es útil para taxonomías grandes usar una ventana con una función de búsqueda. Entonces pretty_name podría usarse para el título de la ventana.
Por otro lado, si una lista desplegable de valores es suficiente, pretty_name podría usarse para el indicador LOV. De manera similar, la descripción podría usarse en la interfaz de usuario para completar la ayuda dinámica.
Echar un vistazo al tipo de configuración o metadatos que se incluyen en estas tablas ayudará a aclarar un poco las cosas.
Cómo administrar todo eso
Si bien el ejemplo utilizado aquí es muy simple, los valores de referencia para un proyecto grande pueden volverse bastante complejos rápidamente. Por lo tanto, puede ser recomendable mantener todo esto en una hoja de cálculo. Si es así, puede usar la propia hoja de cálculo para generar el SQL mediante la concatenación de cadenas. Esto se pega en scripts, que se ejecutan en las bases de datos de destino que respaldan el ciclo de vida del desarrollo y la base de datos de producción (en vivo). Esto inicia la base de datos con todos los datos de referencia necesarios.
Aquí están los datos de configuración para los dos tipos de LDM, Gender_Type y Party_Type :
PROMPT Gender_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Gender Type', 'GENDER_TYPE', ' Identifies the gender of a person.', 13000000, 13999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000010,'Female', 'Female', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000020,'Male', 'Male', TRUNC(SYSDATE), 20, rety_seq.currval); PROMPT Party_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Party Type', 'PARTY_TYPE', A controlled list of reference values that identifies the type of party.', 23000000, 23999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000010,'Organisation', 'Organisation', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000020,'Person', 'Person', TRUNC(SYSDATE), 20, rety_seq.currval);
Hay una fila en reference_type para cada subtipo LDM de Root_Reference_Type . La descripción en reference_type se toma de la descripción de la clase LDM. Para Gender_Type , se leería “Identifica el género de una persona”. Los fragmentos de DML muestran las diferencias en las descripciones entre el tipo y el valor, que se pueden usar en la interfaz de usuario o en los informes.
Verá que reference_type llamado Gender_Type se le ha asignado un rango de 13000000 a 13999999 para su reference_value.ids asociado . En este modelo, cada reference_type se le asigna un rango de ID único que no se superpone. Esto no es estrictamente necesario, pero nos permite agrupar ID de valor relacionados. De alguna manera imita lo que obtendrías si tuvieras mesas separadas. Es bueno tenerlo, pero si no crees que hay ningún beneficio en esto, entonces puedes prescindir de él.
Otra columna que se agregó al PDM es admin_role . Este es el motivo.
¿Quiénes son los administradores?
Algunas taxonomías pueden tener valores agregados o eliminados con poco o ningún impacto. Esto ocurrirá cuando ningún programa haga uso de los valores en su lógica, o cuando el tipo no esté interconectado con otros sistemas. En tales casos, es seguro que los administradores de usuarios los mantengan actualizados.
Pero en otros casos, se debe tener mucho más cuidado. Un nuevo valor de referencia puede causar consecuencias no deseadas en la lógica del programa o en los sistemas posteriores.
Por ejemplo, supongamos que agregamos lo siguiente a la taxonomía de tipo de género:
INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000040,'Not Known', 'Gender has not been recorded. Covers gender of unborn child, when someone has refused to answer the question or when the question has not been asked.', TRUNC(SYSDATE), 30, (SELECT id FROM reference_type WHERE ref_type_key = 'GENDER_TYPE'));
Esto se convierte rápidamente en un problema si tenemos la siguiente lógica incorporada en alguna parte:
IF ref_key = 'MALE' THEN RETURN 'M'; ELSE RETURN 'F'; END IF;
Claramente, la lógica de "si no eres hombre, debes ser mujer" ya no se aplica en la taxonomía extendida.
Aquí es donde el admin_role La columna entra en juego. Nació de conversaciones con los desarrolladores sobre el diseño físico y funcionó en conjunto con su solución de interfaz de usuario. Pero si se hubiera elegido la solución de una tabla por clase, entonces reference_type no hubiera existido. Los metadatos que contenía habrían sido codificados en la aplicación Gender_Type table – , que no es ni flexible ni extensible.
Solo los usuarios con los privilegios correctos pueden administrar la taxonomía. Es probable que esto se base en la experiencia en la materia (SME ). Por otro lado, es posible que TI deba administrar algunas taxonomías para permitir el análisis de impacto, las pruebas exhaustivas y cualquier cambio de código que se publique armoniosamente a tiempo para la nueva configuración. (Ya sea que esto se haga mediante solicitudes de cambio o de alguna otra manera, depende de su organización).
Es posible que haya notado que las columnas de auditoría created_by , created_date , updated_by y updated_date no se hace referencia en absoluto en el script anterior. Nuevamente, si no está interesado en estos, no tiene que usarlos. Esta organización en particular tenía un estándar que exigía tener columnas de auditoría en cada tabla.
Disparadores:Mantener las cosas consistentes
Los activadores garantizan que estas columnas de auditoría se actualicen constantemente, independientemente del origen del SQL (scripts, su aplicación, actualizaciones por lotes programadas, actualizaciones ad-hoc, etc.).
-------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_TYPE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER rety_bri BEFORE INSERT ON reference_type FOR EACH ROW DECLARE BEGIN IF (:new.id IS NULL) THEN :new.id := rety_seq.nextval; END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END rety_bri; / CREATE OR REPLACE TRIGGER rety_bru BEFORE UPDATE ON reference_type FOR EACH ROW DECLARE BEGIN :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END rety_bru; / -------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_VALUE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER reva_bri BEFORE INSERT ON reference_value FOR EACH ROW DECLARE BEGIN IF (:new.type_key IS NULL) THEN -- create the type_key from pretty_name: :new.type_key := function_to_create_key(new.pretty_name); END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END reva_bri; / CREATE OR REPLACE TRIGGER reva_bru BEFORE UPDATE ON reference_value FOR EACH ROW DECLARE BEGIN -- once the type_key is set it cannot be overwritten: :new.type_key := :old.type_key; :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END reva_bru; /
Mi experiencia es principalmente Oracle y, desafortunadamente, Oracle limita los identificadores a 30 bytes. Para evitar exceder esto, a cada tabla se le asigna un alias corto de tres a cinco caracteres y otros artefactos relacionados con la tabla usan ese alias en sus nombres. Entonces, reference_value El alias de es reva – los dos primeros caracteres de cada palabra. Antes de insertar fila y antes de la actualización de la fila se abrevia como bri y bru respectivamente. El nombre de la secuencia reva_seq , y así sucesivamente.
La codificación manual de disparadores como este, tabla tras tabla, requiere mucho trabajo desmoralizador para los desarrolladores. Afortunadamente, estos disparadores se pueden crear a través de la generación de código , ¡pero ese es el tema de otro artículo!
La importancia de las llaves
La ref_type_key y type_key las columnas están limitadas a 30 bytes. Esto les permite ser utilizados en consultas SQL tipo PIVOT (en Oracle. Otras bases de datos pueden no tener la misma restricción de longitud de identificador).
Debido a que la base de datos garantiza la exclusividad de la clave y el activador garantiza que su valor permanezca igual en todo momento, estas claves pueden, y deben, usarse en consultas y códigos para que sean más legibles. . ¿Qué quiero decir con esto? Bueno, en lugar de:
SELECT … FROM … INNER JOIN … WHERE reference_value.id = 13000020
Usted escribe:
SELECT … FROM … INNER JOIN … WHERE reference_value.type_key = 'MALE'
Básicamente, la clave explica claramente lo que está haciendo la consulta .
De LDM a PDM, con espacio para crecer
El viaje de LDM a PDM no es necesariamente un camino recto. Tampoco es una transformación directa de uno a otro. Es un proceso separado que introduce sus propias consideraciones y sus propias preocupaciones.
¿Cómo modelas los datos de referencia en tu base de datos?