¿Alguna vez se ha encontrado con una situación en la que necesita administrar el estado de una entidad que cambia con el tiempo? Hay muchos ejemplos por ahí. Comencemos con uno fácil:fusionar registros de clientes.
Supongamos que estamos fusionando listas de clientes de dos fuentes diferentes. Podríamos tener cualquiera de los siguientes estados:Duplicados identificados – el sistema ha encontrado dos entidades potencialmente duplicadas; Duplicados confirmados – un usuario valida que las dos entidades son efectivamente duplicados; o Único confirmado – el usuario decide que las dos entidades son únicas. En cualquiera de estas situaciones, el usuario solo tiene que tomar una decisión de sí o no.
Pero, ¿qué pasa con las situaciones más complejas? ¿Hay alguna manera de definir el flujo de trabajo real entre estados? Sigue leyendo…
Cómo las cosas pueden salir mal fácilmente
Muchas organizaciones necesitan gestionar solicitudes de empleo. En un modelo simple, podría tener una tabla llamada JOB_APPLICATION y podría realizar un seguimiento del estado de la aplicación mediante una tabla de datos de referencia que contenga valores como estos:
| Estado de la solicitud |
|---|
APPLICATION_RECEIVED |
APPLICATION_UNDER_REVIEW |
APPLICATION_REJECTED |
INVITED_TO_INTERVIEW |
INVITATION_DECLINED |
INVITATION_ACCEPTED |
INTERVIEW_PASSED |
INTERVIEW_FAILED |
REFERENCES_SOUGHT |
REFERENCES_ACCEPTABLE |
REFERENCES_UNACCEPTABLE |
JOB_OFFER_MADE |
JOB_OFFER_ACCEPTED |
JOB_OFFER_DECLINED |
APPLICATION_CLOSED |
Estos valores se pueden seleccionar en cualquier orden en cualquier momento. Depende de los usuarios finales para garantizar que se realice una selección lógica y correcta en cada etapa. Nada prohíbe una secuencia ilógica de estados.
Por ejemplo, digamos que una solicitud ha sido rechazada. El estado actual obviamente sería APPLICATION_REJECTED . No hay nada que se pueda hacer a nivel de la aplicación para evitar que un usuario sin experiencia seleccione posteriormente INVITED_TO_INTERVIEW o algún otro estado ilógico.
Lo que se necesita es algo que guíe al usuario a seleccionar el siguiente estado lógico, algo que defina un flujo de trabajo lógico .
¿Y si tiene diferentes requisitos para diferentes tipos de solicitudes de empleo? Por ejemplo, algunos trabajos pueden requerir que el solicitante realice una prueba de aptitud. Claro, puede agregar más valores a la lista para cubrirlos, pero no hay nada en el diseño actual que impida que el usuario final realice una selección incorrecta para el tipo de aplicación en cuestión. La realidad es que hay diferentes flujos de trabajo para diferentes contextos .
Otro punto a tener en cuenta:¿son realmente todas las opciones enumeradas estados ? O son algunos de hecho resultados ? Por ejemplo, la oferta de un trabajo puede ser aceptada o rechazada por el solicitante. Por lo tanto, JOB_OFFER_MADE realmente tiene dos resultados:JOB_OFFER_ACCEPTED y JOB_OFFER_DECLINED .
Otro resultado podría ser que se retire una oferta de trabajo. Es posible que desee registrar la razón por la que se retiró utilizando un calificador. Si solo agrega estas razones a la lista anterior, nada guía al usuario final a realizar selecciones lógicas.
En realidad, cuanto más complejos se vuelven los estados, los resultados y los calificadores, más necesita definir el flujo de trabajo de un proceso .
Organización de procesos, estados y resultados
Es importante entender qué está pasando con sus datos antes de intentar modelarlos. Al principio, puede sentirse inclinado a pensar que aquí hay una estricta jerarquía de tipos:
Cuando miramos más de cerca el ejemplo anterior, vemos que el INVITED_TO_INTERVIEW y el JOB_OFFER_MADE los estados comparten los mismos resultados posibles, a saber, ACCEPTED y DECLINED . Esto nos dice que hay una relación de muchos a muchos entre estados y resultados. Esto suele ser cierto para otros estados, resultados y calificadores.
Entonces, a nivel conceptual, esto es lo que realmente sucede con nuestros metadatos:
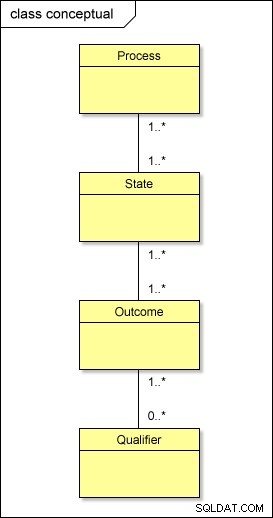
Si tuviera que transformar este modelo al mundo físico usando el enfoque estándar, tendría tablas llamadas PROCESS , STATE , OUTCOME y QUALIFIER; también necesitarías tener tablas intermedias entre ellos – PROCESS_STATE , STATE_OUTCOME y OUTCOME_QUALIFIER – para resolver las relaciones de muchos a muchos . Esto complica el diseño.
Si bien se debe mantener la jerarquía lógica de niveles (proceso → estado → resultado → calificador), existe una forma más sencilla de organizar físicamente nuestros metadatos.
El patrón de flujo de trabajo
El siguiente diagrama define los componentes principales de un modelo de base de datos de flujo de trabajo:
Las tablas amarillas de la izquierda contienen metadatos de flujo de trabajo y las tablas azules de la derecha contienen datos comerciales.
Lo primero que hay que señalar es que cualquier entidad puede gestionarse sin requerir grandes cambios a este modelo. El YOUR_ENTITIY_TO_MANAGE table es la que se encuentra bajo administración de flujo de trabajo. En términos de nuestro ejemplo, este sería el JOB_APPLICATION mesa.
A continuación, simplemente necesitamos agregar el wf_state_type_process_id columna a cualquier tabla que queramos administrar. Esta columna apunta al proceso de flujo de trabajo real que se utiliza para administrar la entidad. Esta no es estrictamente una columna de clave externa, pero nos permite consultar rápidamente WORKFLOW_STATE_TYPE para el proceso correcto. La tabla que contendrá el historial de estado es MANAGED_ENTITY_STATE . Nuevamente, elegiría su propio nombre de tabla específico aquí y lo modificaría según sus propios requisitos.
Los metadatos
Los diferentes niveles de flujo de trabajo se definen en WORKFLOW_LEVEL_TYPE . Esta tabla contiene lo siguiente:
| Escribir clave | Descripción |
|---|---|
| PROCESO | Proceso de flujo de trabajo de alto nivel. |
| ESTADO | Un estado en el proceso. |
| RESULTADO | Cómo termina un estado, su resultado. |
| CALIFICADOR | Un calificador opcional y más detallado para un resultado. |
WORKFLOW_STATE_TYPE y WORKFLOW_STATE_HIERARCHY formar una estructura clásica de lista de materiales (BOM) . Esta estructura, que es muy descriptiva de una lista de materiales de fabricación real, es bastante común en el modelado de datos. Puede definir jerarquías o aplicarse a muchas situaciones recursivas. Lo usaremos aquí para definir nuestra jerarquía lógica de procesos, estados, resultados y calificadores opcionales.
Antes de que podamos definir una jerarquía, necesitamos definir los componentes individuales. Estos son nuestros bloques de construcción básicos. Voy a hacer referencia a estos mediante TYPE_KEY (que es único) en aras de la brevedad. Para nuestro ejemplo, tenemos:
| Tipo de nivel de flujo de trabajo | Tipo de estado de flujo de trabajo.Escriba clave |
|---|---|
| RESULTADO | APROBADO |
| RESULTADO | FALLIDO |
| RESULTADO | ACEPTADO |
| RESULTADO | RECHAZADO |
| RESULTADO | CANDIDATE_CANCELLED |
| RESULTADO | EMPLEADOR_CANCELADO |
| RESULTADO | RECHAZADO |
| RESULTADO | EMPLOYER_WITHDRAWN |
| RESULTADO | NO_SHOW |
| RESULTADO | CONTRATADO |
| RESULTADO | NO_CONTRATADO |
| ESTADO | APLICACIÓN_RECIBIDA |
| ESTADO | REVISIÓN_DE_APLICACIÓN |
| ESTADO | INVITADO_A_ENTREVISTA |
| ESTADO | ENTREVISTA |
| ESTADO | PRUEBA_APTITUD |
| ESTADO | BUSCAR_REFERENCIAS |
| ESTADO | HACER_OFERTA |
| ESTADO | APLICACIÓN_CERRADA |
| PROCESO | APLICACIÓN_DE_TRABAJO_ESTÁNDAR |
| PROCESO | APLICACIÓN_TRABAJO_TÉCNICO |
Ahora podemos empezar a definir nuestra jerarquía. Aquí es donde tomamos nuestros bloques de construcción y definimos nuestra estructura. Para cada estado, definimos los posibles resultados. De hecho, es una regla de este sistema de flujo de trabajo que cada estado debe terminar con un resultado:
| Tipo principal:ESTADOS | Tipo de niño:RESULTADOS |
|---|---|
| APLICACIÓN_RECIBIDA | ACEPTADO |
| APLICACIÓN_RECIBIDA | RECHAZADO |
| REVISIÓN_DE_LA_APLICACIÓN | APROBADO |
| REVISIÓN_DE_LA_APLICACIÓN | FALLIDO |
| INVITADO_A_ENTREVISTA | ACEPTADO |
| INVITADO_A_ENTREVISTA | RECHAZADO |
| ENTREVISTA | APROBADO |
| ENTREVISTA | FALLIDO |
| ENTREVISTA | CANDIDATE_CANCELLED |
| ENTREVISTA | NO_SHOW |
| HACER_OFERTA | ACEPTADO |
| HACER_OFERTA | RECHAZADO |
| BUSCAR_REFERENCIAS | APROBADO |
| BUSCAR_REFERENCIAS | FALLIDO |
| APLICACIÓN_CERRADA | CONTRATADO |
| APLICACIÓN_CERRADA | NO_CONTRATADO |
| PRUEBA_APTITUD | APROBADO |
| PRUEBA_APTITUD | FALLIDO |
Nuestros procesos son simplemente un conjunto de estados que existen cada uno durante un período de tiempo. En la siguiente tabla se presentan en un orden lógico, pero esto no define el orden real de procesamiento.
| Tipo principal:PROCESOS | Tipo de niño:ESTADOS |
|---|---|
| APLICACIÓN_TRABAJO_ESTÁNDAR | APLICACIÓN_RECIBIDA |
| APLICACIÓN_TRABAJO_ESTÁNDAR | REVISIÓN_DE_APLICACIÓN |
| APLICACIÓN_TRABAJO_ESTÁNDAR | INVITADO_A_ENTREVISTA |
| APLICACIÓN_TRABAJO_ESTÁNDAR | ENTREVISTA |
| APLICACIÓN_TRABAJO_ESTÁNDAR | HACER_OFERTA |
| APLICACIÓN_TRABAJO_ESTÁNDAR | BUSCAR_REFERENCIAS |
| APLICACIÓN_TRABAJO_ESTÁNDAR | APLICACIÓN_CERRADA |
| APLICACIÓN_TRABAJO_TÉCNICO | APLICACIÓN_RECIBIDA |
| APLICACIÓN_TRABAJO_TÉCNICO | REVISIÓN_DE_APLICACIÓN |
| APLICACIÓN_TRABAJO_TÉCNICO | INVITADO_A_ENTREVISTA |
| APLICACIÓN_TRABAJO_TÉCNICO | PRUEBA_APTITUD |
| APLICACIÓN_TRABAJO_TÉCNICO | ENTREVISTA |
| APLICACIÓN_TRABAJO_TÉCNICO | HACER_OFERTA |
| APLICACIÓN_TRABAJO_TÉCNICO | BUSCAR_REFERENCIAS |
| APLICACIÓN_TRABAJO_TÉCNICO | APLICACIÓN_CERRADA |
Hay un punto importante que hacer con respecto a una jerarquía de BOM. Así como una lista de materiales física define ensamblajes y subensamblajes hasta los componentes más pequeños, tenemos una disposición similar en nuestra jerarquía. Esto significa que podemos reutilizar "ensamblajes" y "subensamblajes".
A modo de ejemplo:Tanto la STANDARD_JOB_APPLICATION y TECHNICAL_JOB_APPLICATION procesos tener la INTERVIEW estado . A su vez, la INTERVIEW estado tiene el PASSED , FAILED , CANDIDATE_CANCELLED y NO_SHOW resultados definida para ello.
Cuando usa un estado en un proceso, obtiene automáticamente sus resultados secundarios porque ya es un ensamblaje. Esto significa que existen los mismos resultados para ambos tipos de solicitud de empleo en la INTERVIEW escenario. Si desea diferentes resultados de la entrevista para diferentes tipos de solicitudes de empleo, debe definir, por ejemplo, TECHNICAL_INTERVIEW y STANDARD_INTERVIEW establece que cada uno tiene sus propios resultados específicos.
En este ejemplo, la única diferencia entre los dos tipos de solicitudes de empleo es que una solicitud de empleo técnica incluye una prueba de aptitud.
Antes de ir
La Parte 1 de este artículo de dos partes ha presentado el patrón de base de datos de flujo de trabajo. Ha mostrado cómo puede incorporarlo para administrar el ciclo de vida de cualquier entidad en su base de datos.
La parte 2 le mostrará cómo definir el flujo de trabajo real utilizando tablas de configuración adicionales. Aquí es donde al usuario se le presentarán los próximos pasos permitidos. También demostraremos una técnica para eludir la reutilización estricta de "ensamblajes" y "subensamblajes" en las listas de materiales.