Probablemente haya cometido algunos de estos errores cuando estaba comenzando su carrera de diseño de bases de datos. Tal vez todavía los estés haciendo, o harás algunos en el futuro. No podemos retroceder en el tiempo y ayudarlo a deshacer sus errores, pero podemos evitarle algunos dolores de cabeza futuros (o presentes).
Leer este artículo puede ahorrarle muchas horas dedicadas a solucionar problemas de código y diseño, así que profundicemos. He dividido la lista de errores en dos grupos principales:aquellos que son no técnicos de naturaleza y aquellos que son estrictamente técnicos . Ambos grupos son una parte importante del diseño de la base de datos.
Obviamente, si no tienes habilidades técnicas, no sabrás cómo hacer algo. No es sorprendente ver estos errores en la lista. ¿Pero habilidades no técnicas? La gente puede olvidarse de ellos, pero estas habilidades también son una parte muy importante del proceso de diseño. Agregan valor a su código y relacionan la tecnología con el problema del mundo real que necesita resolver.
Entonces, comencemos con los problemas no técnicos primero, luego pasemos a los técnicos.
Errores de diseño de base de datos no técnicos
#1 Mala planificación
Este es definitivamente un problema no técnico, pero es un problema importante y común. Todos nos emocionamos cuando comienza un nuevo proyecto y, al entrar en él, todo pinta muy bien. Al principio, el proyecto sigue siendo una página en blanco y tú y tu cliente están felices de comenzar a trabajar en algo que creará un futuro mejor para ambos. Todo esto es genial, y un gran futuro probablemente será el resultado final. Pero aún así, tenemos que mantenernos enfocados. Esta es la parte del proyecto donde podemos cometer errores cruciales.
Antes de sentarse a dibujar un modelo de datos, debe asegurarse de que:
- Eres completamente consciente de lo que hace tu cliente (es decir, sus planes comerciales relacionados con este proyecto y también su panorama general) y lo que quiere que este proyecto logre ahora y en el futuro.
- Comprende el proceso comercial y, si es necesario o cuando sea necesario, está listo para hacer sugerencias para simplificarlo y mejorarlo (por ejemplo, para aumentar la eficiencia y los ingresos, reducir los costos y las horas de trabajo, etc.).
- Comprende el flujo de datos en la empresa del cliente. Idealmente, conocería todos los detalles:quién trabaja con los datos, quién realiza los cambios, qué informes se necesitan, cuándo y por qué sucede todo esto.
- Puede usar el lenguaje o la terminología que usa su cliente. Si bien usted puede o no ser un experto en su área, su cliente definitivamente lo es. Pídeles que expliquen lo que no entiendes. Y cuando explique los detalles técnicos al cliente, use un lenguaje y una terminología que entiendan.
- Sabe qué tecnologías usará, desde el motor de la base de datos y los lenguajes de programación hasta otras herramientas. Lo que decida usar está estrechamente relacionado con el problema que resolverá, pero es importante incluir las preferencias del cliente y su infraestructura de TI actual.
Durante la fase de planificación, debe obtener respuestas a estas preguntas:
- ¿Qué mesas serán las mesas centrales en su modelo? Probablemente tendrá algunos de ellos, mientras que las otras tablas serán algunas de las habituales (por ejemplo, cuenta_usuario, función). No te olvides de los diccionarios y las relaciones entre tablas.
- ¿Qué nombres se usarán para las tablas en el modelo? Recuerde mantener la terminología similar a la que usa actualmente el cliente.
- ¿Qué reglas se aplicarán al nombrar tablas y otros objetos? (Consulte el punto 4 sobre las convenciones de nomenclatura).
- ¿Cuánto tiempo llevará todo el proyecto? Esto es importante, tanto para su horario como para el cronograma del cliente.
Solo cuando tenga todas estas respuestas estará listo para compartir una solución inicial al problema. Esa solución no necesita ser una aplicación completa, tal vez un documento breve o incluso algunas oraciones en el idioma de la empresa del cliente.
La buena planificación no es específica del modelado de datos; es aplicable a casi cualquier proyecto de TI (y no TI). Omitir es solo una opción si 1) tiene un proyecto realmente pequeño; 2) las tareas y los objetivos son claros, y 3) tienes mucha prisa. Un ejemplo histórico es el de los ingenieros de lanzamiento del Sputnik 1 dando instrucciones verbales a los técnicos que lo estaban montando. El proyecto estaba apurado debido a la noticia de que EE. UU. planeaba lanzar su propio satélite pronto, pero supongo que no tendrás tanta prisa.
#2 Comunicación insuficiente con clientes y desarrolladores
Cuando comience el proceso de diseño de la base de datos, probablemente comprenderá la mayoría de los requisitos principales. Algunos son muy comunes independientemente del negocio, p. roles y estados de los usuarios. Por otro lado, algunas tablas de su modelo serán bastante específicas. Por ejemplo, si está creando un modelo para una empresa de taxis, tendrá tablas para vehículos, conductores, clientes, etc.
Aún así, no todo será obvio al comienzo de un proyecto. Es posible que no entiendas algunos requisitos, el cliente puede agregar algunas funcionalidades nuevas, verás algo que podría hacerse de otra manera, el proceso podría cambiar, etc. Todo esto provoca cambios en el modelo. La mayoría de los cambios requieren agregar nuevas tablas, pero a veces eliminará o modificará tablas. Si ya comenzó a escribir código que usa estas tablas, también deberá volver a escribir ese código.
Para reducir el tiempo dedicado a cambios inesperados, debe:
- Hable con desarrolladores y clientes y no tenga miedo de hacer preguntas comerciales vitales. Cuando crea que está listo para comenzar, pregúntese ¿La situación X está cubierta en nuestra base de datos? El cliente actualmente está haciendo Y de esta manera; ¿Esperamos un cambio en un futuro próximo? Una vez que estemos seguros de que nuestro modelo tiene la capacidad de almacenar todo lo que necesitamos de la manera correcta, podemos comenzar a codificar.
- Si enfrenta un cambio importante en su diseño y ya tiene mucho código escrito, no debe intentar una solución rápida. Hazlo como debería haberse hecho, sin importar la situación actual. Una solución rápida podría ahorrar algo de tiempo ahora y probablemente funcionaría bien por un tiempo, pero luego puede convertirse en una verdadera pesadilla.
- Si cree que algo está bien ahora pero que podría convertirse en un problema más adelante, no lo ignore. Analice esa área e implemente cambios si mejorarán la calidad y el rendimiento del sistema. Le costará algo de tiempo, pero entregará un mejor producto y dormirá mucho mejor.
Si intenta evitar hacer cambios en su modelo de datos cuando ve un problema potencial, o si opta por una solución rápida en lugar de hacerlo correctamente, pagará por eso tarde o temprano.
Además, manténgase en contacto con su cliente y los desarrolladores durante todo el proyecto. Siempre verifique y vea si se han realizado cambios desde su última discusión.
#3 Documentación deficiente o faltante
Para la mayoría de nosotros, la documentación llega al final del proyecto. Si estamos bien organizados, probablemente hayamos documentado las cosas en el camino y solo tendremos que cerrar todo. Pero, sinceramente, ese no suele ser el caso. La escritura de la documentación ocurre justo antes de que se cierre el proyecto, ¡y justo después de que hayamos terminado mentalmente con ese modelo de datos!
El precio que se paga por un proyecto mal documentado puede ser bastante alto, algunas veces más alto que el precio que pagamos por documentar todo correctamente. Imagine encontrar un error unos meses después de haber cerrado el proyecto. Debido a que no documentó correctamente, no sabe por dónde empezar.
Mientras trabajas, no olvides escribir comentarios. Explique todo lo que necesite una explicación adicional y, básicamente, escriba todo lo que crea que será útil algún día. Nunca se sabe si necesitará esa información adicional o cuándo.
Errores en el diseño de la base de datos técnica
#4 No usar una convención de nomenclatura
Nunca se sabe con certeza cuánto durará un proyecto y si tendrá más de una persona trabajando en el modelo de datos. Hay un punto en el que está muy cerca del modelo de datos, pero aún no ha comenzado a dibujarlo. Aquí es cuando es prudente decidir cómo nombrará los objetos en su modelo, en la base de datos y en la aplicación general. Antes de modelar, debes saber:
- ¿Los nombres de las tablas son singulares o plurales?
- ¿Agruparemos las tablas usando nombres? (Por ejemplo, todas las tablas relacionadas con el cliente contienen "cliente_", todas las tablas relacionadas con la tarea contienen "tarea_", etc.)
- ¿Usaremos letras mayúsculas y minúsculas, o solo minúsculas?
- ¿Qué nombre usaremos para las columnas de ID? (Lo más probable es que sea "id".)
- ¿Cómo nombraremos las claves foráneas? (Lo más probable es que sea "id_" y el nombre de la tabla a la que se hace referencia).
Compare la parte de un modelo que no usa convenciones de nomenclatura con la misma parte que sí usa convenciones de nomenclatura, como se muestra a continuación:
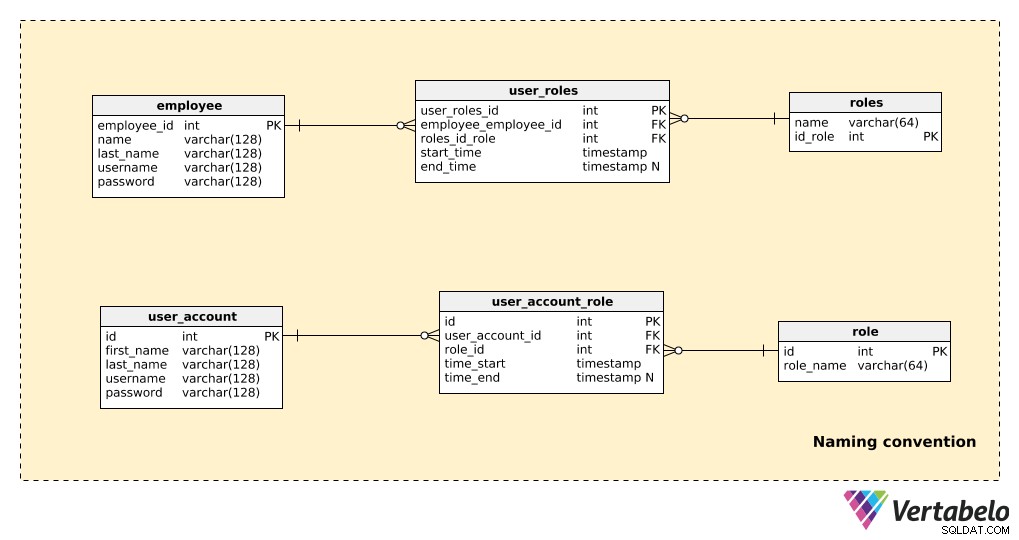
Aquí solo hay unas pocas tablas, pero aún es bastante obvio qué modelo es más fácil de leer. Tenga en cuenta que:
- Ambos modelos "funcionan", por lo que no hay problemas en el aspecto técnico.
- En el ejemplo de la no convención de nomenclatura (las tres tablas superiores), hay algunas cosas que afectan significativamente la legibilidad:usar formas singulares y plurales en los nombres de las tablas; nombres de clave principal no estandarizados (
employees_id,id_role); y los atributos en diferentes tablas comparten el mismo nombre (por ejemplo, el nombre aparece tanto en el "employee” y los “roles” tablas).
Ahora imagine el desorden que crearíamos si nuestro modelo contuviera cientos de tablas. Tal vez podríamos trabajar con un modelo de este tipo (si lo creamos nosotros mismos), pero sería muy desafortunado para alguien si tuviera que trabajar en él después de nosotros.
Para evitar futuros problemas con los nombres, no utilice palabras reservadas de SQL, caracteres especiales o espacios en ellos.
Por lo tanto, antes de comenzar a crear cualquier nombre, haga un documento simple (tal vez de unas pocas páginas) que describa la convención de nomenclatura que ha utilizado. Esto aumentará la legibilidad de todo el modelo y simplificará el trabajo futuro.
Puede leer más sobre las convenciones de nomenclatura en estos dos artículos:
- Convenciones de nomenclatura en el modelado de bases de datos
- Una mirada lógica sin emociones a las convenciones de nomenclatura de SQL Server
#5 Problemas de normalización
La normalización es una parte esencial del diseño de la base de datos. Cada base de datos debe normalizarse a al menos 3NF (las claves primarias están definidas, las columnas son atómicas y no hay grupos repetitivos, dependencias parciales o dependencias transitivas). Esto reduce la duplicación de datos y garantiza la integridad referencial.
Puede leer más sobre la normalización en este artículo. En resumen, siempre que hablamos del modelo de base de datos relacional, estamos hablando de la base de datos normalizada. Si una base de datos no está normalizada, nos encontraremos con un montón de problemas relacionados con la integridad de los datos.
En algunos casos, es posible que queramos desnormalizar nuestra base de datos. Si haces esto, tienes una muy buena razón. Puede leer más sobre la desnormalización de la base de datos aquí.
#6 Uso del modelo de entidad-atributo-valor (EAV)
EAV significa entidad-atributo-valor. Esta estructura se puede usar para almacenar datos adicionales sobre cualquier cosa en nuestro modelo. Echemos un vistazo a un ejemplo.
Supongamos que queremos almacenar algunos atributos de clientes adicionales. El “customer ” tabla es nuestra entidad, el “attribute ” es obviamente nuestro atributo, y el “attribute_value ” contiene el valor de ese atributo para ese cliente.
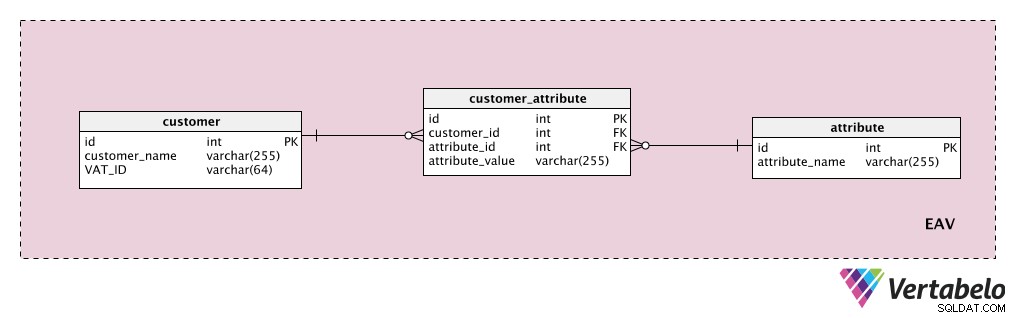
Primero, agregaremos un diccionario con una lista de todas las posibles propiedades que podríamos asignar a un cliente. Este es el “attribute " mesa. Podría contener propiedades como "valor del cliente", "detalles de contacto", "información adicional", etc. El "customer_attribute La tabla ” contiene una lista de todos los atributos, con valores, para cada cliente. Para cada cliente, solo tendremos registros de los atributos que tienen y almacenaremos el "attribute_value ” para ese atributo.
Esto podría parecer realmente genial. Nos permitiría agregar nuevas propiedades fácilmente (porque las agregamos como valores en el "customer_attribute " mesa). Así evitaríamos hacer cambios en la base de datos. Casi demasiado bueno para ser verdad.
Y es demasiado bueno. Si bien el modelo almacenará los datos que necesitamos, trabajar con dichos datos es mucho más complicado. Y eso incluye casi todo, desde escribir consultas SELECT simples hasta obtener todos los valores relacionados con el cliente para insertar, actualizar o eliminar valores.
En resumen, debemos evitar la estructura EAV. Si tiene que usarlo, úselo solo cuando esté 100% seguro de que realmente lo necesita.
#7 Uso de un GUID/UUID como clave principal
Un GUID (identificador único global) es un número de 128 bits generado de acuerdo con las reglas definidas en RFC 4122. A veces también se conocen como UUID (identificadores únicos universales). La principal ventaja de un GUID es que es único; la posibilidad de que pulses el mismo GUID dos veces es muy poco probable. Por lo tanto, los GUID parecen un gran candidato para la columna de clave principal. Pero ese no es el caso.
Una regla general para las claves primarias es que usamos una columna de enteros con la propiedad de incremento automático establecida en "sí". Esto agregará datos en orden secuencial a la clave principal y proporcionará un rendimiento óptimo. Sin una clave secuencial o una marca de tiempo, no hay forma de saber qué datos se insertaron primero. Este problema también surge cuando usamos valores ÚNICOS del mundo real (por ejemplo, una ID de IVA). Si bien tienen valores ÚNICOS, no son buenas claves primarias. En su lugar, utilícelas como claves alternativas.
Una nota adicional: Prefiero usar atributos enteros generados automáticamente de una sola columna como clave principal. Definitivamente es la mejor práctica. Le recomiendo que evite usar claves primarias compuestas.
#8 Indexación insuficiente
Los índices son una parte muy importante del trabajo con bases de datos, pero una discusión exhaustiva de ellos está fuera del alcance de este artículo. Afortunadamente, ya tenemos algunos artículos relacionados con los índices que puede consultar para obtener más información:- ¿Qué es un índice de base de datos?
- Todo sobre los índices:los conceptos básicos
- Todo sobre los índices, parte 2:estructura y rendimiento de índices de MySQL
La versión corta es que te recomiendo que agregues un índice donde sea que esperes que sea necesario. También puede agregarlos después de que la base de datos esté en producción si ve que agregar un índice en un lugar determinado mejorará el rendimiento.
#9 Datos redundantes
En general, se deben evitar los datos redundantes en cualquier modelo. No solo ocupa espacio adicional en el disco, sino que también aumenta en gran medida las posibilidades de problemas de integridad de datos. Si algo tiene que ser redundante, debemos cuidar que los datos originales y la “copia” estén siempre en estados consistentes. De hecho, hay algunas situaciones en las que se desean datos redundantes:
- En algunos casos, tenemos que asignar prioridad a una determinada acción, y para que esto suceda, tenemos que realizar cálculos complejos. Estos cálculos podrían usar muchas tablas y consumir muchos recursos. En tales casos, sería conveniente realizar estos cálculos fuera del horario laboral (evitando así problemas de rendimiento durante el horario laboral). Si lo hacemos de esta forma, podríamos almacenar ese valor calculado y usarlo más tarde sin tener que volver a calcularlo. Por supuesto, el valor es redundante; sin embargo, lo que ganamos en rendimiento es mucho más de lo que perdemos (algo de espacio en el disco duro).
- También podemos almacenar un pequeño conjunto de datos de informes dentro de la base de datos. Por ejemplo, al final del día, almacenaremos la cantidad de llamadas que hicimos ese día, la cantidad de ventas exitosas, etc. Los datos de informes solo deben almacenarse de esta manera si necesitamos usarlos con frecuencia. Una vez más, perderemos un poco de espacio en el disco duro, pero evitaremos volver a calcular los datos o conectarnos a la base de datos de informes (si tenemos una).
En la mayoría de los casos, no deberíamos usar datos redundantes porque:
- Almacenar los mismos datos más de una vez en la base de datos podría afectar la integridad de los datos. Si almacena el nombre de un cliente en dos lugares diferentes, debe realizar cualquier cambio (insertar/actualizar/eliminar) en ambos lugares al mismo tiempo. Esto también complica el código que necesitará, incluso para las operaciones más simples.
- Si bien podemos almacenar algunos números agregados en nuestra base de datos operativa, debemos hacerlo solo cuando realmente lo necesitemos. Una base de datos operativa no está destinada a almacenar datos de informes, y mezclar estos dos suele ser una mala práctica. Cualquiera que produzca informes tendrá que utilizar los mismos recursos que los usuarios que trabajan en tareas operativas; las consultas de informes suelen ser más complejas y pueden afectar al rendimiento. Por lo tanto, debe separar su base de datos operativa y su base de datos de informes.
Ahora es su turno de opinar
Espero que la lectura de este artículo le haya brindado nuevos conocimientos y lo anime a seguir las mejores prácticas de modelado de datos. ¡Te ahorrarán tiempo!
¿Has experimentado alguno de los problemas mencionados en este artículo? ¿Crees que nos hemos perdido algo importante? ¿O crees que deberíamos eliminar algo de nuestra lista? Cuéntanos en los comentarios a continuación.



