“Las empresas se están dando cuenta de que pueden extraer valiosa inteligencia comercial para mejorar la toma de decisiones y obtener una ventaja competitiva. Herramientas como Hadoop y Cassandra están haciendo todo esto posible y, por eso, las habilidades de NoSQL en todos los niveles tienen una demanda extremadamente alta”. – Analistas en TechRepublic
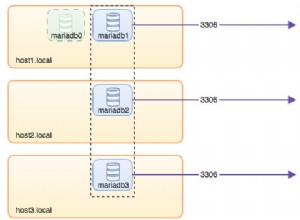
Desarrollado como un proyecto interno en Facebook para potenciar su función de búsqueda en la bandeja de entrada, Cassandra es un sistema de gestión de bases de datos distribuidas de código abierto . Fue lanzado como un proyecto de código abierto en Google Code en 2008 y posteriormente se ha convertido en un proyecto de primer nivel en la Fundación Apache Software desde 2010.
Cassandra es la próxima GRAN Cosa:
- Apache Cassandra está diseñado para manejar una enorme cantidad de datos (en términos de velocidad, volumen y variedad) a través de numerosos servidores básicos que garantizan una alta disponibilidad y no proporcionan SPOF (punto único de falla).
- Cassandra también ofrece un potente soporte para clústeres que abarcan varios centros de datos. La ausencia de una "estructura maestro-esclavo", como las arquitecturas tradicionales, permite un impacto cero en el sistema si un nodo en particular deja de funcionar.
- Los investigadores de la Universidad de Toronto que realizan un estudio sobre los sistemas NoSQL afirman que, en términos de escalabilidad y rendimiento máximo por nodo , Cassandra emerge como una clara ganadora. El enfoque principal de NoSQL DBMS es garantizar la escalabilidad , Rendimiento y Alta disponibilidad. Al igual que la mayoría de DBMS NoSQL, Cassandra puede manejar datos estructurados y no estructurados y funciona considerablemente bien en los parámetros anteriores.
- Cassandra puede funcionar como almacén de datos en tiempo real ("el Sistema de registro") para aplicaciones en línea/transaccionales y como una base de datos de lectura intensiva para los sistemas de Business Intelligence. Lea nuestra publicación de blog sobre las diversas ventajas que ofrece Cassandra para obtener más información.
¿Por qué optar por Hadoop con Cassandra?
En términos simples, tener:
- Carga de trabajo unificada
- Disponibilidad
- Implementación más sencilla
Cuando se trata de Hadoop, las empresas no están interesadas en la estructura de almacenamiento subyacente de Hadoop, sino en sus métodos de entrega rentables para analizar y procesar grandes cantidades de datos. Ser capaz de tomar decisiones a partir de la salida de MapReduce, Hive, Pig, Mahout y otras operaciones es lo más importante para estas organizaciones.
Puntos clave para recordar:
- El Sistema de archivos distribuidos de Hadoop (HDFS) es uno de los muchos componentes y proyectos diferentes contenidos en el ecosistema de Hadoop. El proyecto Apache Hadoop define HDFS como el sistema de almacenamiento principal utilizado por las aplicaciones Hadoop .HDFS puede almacenar conjuntos de datos no estructurados distribuidos de forma masiva. Los datos se pueden almacenar directamente en HDFS, o se pueden almacenar en un formato semiestructurado en HBase, lo que permite un acceso rápido a los datos de nivel de registro y se basa en el sistema BigTable de Google. Cassandra, por otro lado, es un no- sistema relacional que utiliza el modelo de datos BigTable , pero emplea el esquema Dynamo de Amazon para la distribución y agrupación de datos.
- Hadoop hace muchas cosas excelentes, sus capacidades principales de MapReduce son muy sólidas. Los expertos de la industria adoran Hive y su diseño similar a SQL. Sin embargo, el sistema de archivos HDFS es extremadamente complejo de configurar, tiene puntos únicos de falla y, según los comentarios de las principales empresas, simplemente no está listo para hacer lo que quieren que haga . Cassandra, por otro lado, proporciona todas las capacidades del nivel inferior de la pila de Hadoop. Cassandra, al mismo tiempo, también proporciona capacidades de aplicación en tiempo real de baja latencia en esa misma infraestructura.
¿Cómo pueden Cassandra y Hadoop trabajar juntos?
Varios proveedores están ofreciendo alternativas a HDFS. Un artículo reciente de una organización llamada GigaOM proporciona una descripción general de alto nivel de cómo se puede usar Apache Cassandra File System para reemplazar HDFS, con cambios mínimos de programación requeridos desde una perspectiva de desarrollo, y cómo se pueden obtener una serie de beneficios en este proceso. Impuesto de datos , un proveedor comercial líder en distribuciones de Cassandra ha combinado Cassandra con Hadoop y lo ha llamado Brisk. Con Brisk, HDFS se reemplaza por Cassandra File System. Explore más sobre los conceptos de HDFS. Echa un vistazo a este Curso de Big Data en línea , que fue creado por Top Industrial Working Experts.
Ventaja de Cassandra – Combinación de Hadoop:
- También se puede implementar Cassandra con Hadoop en el mismo clúster. Esto significa que puede tener lo mejor de ambos mundos.
- Basado en tiempo y en tiempo real ejecutándose bajo las aplicaciones de Cassandra (el tiempo real es el punto fuerte de Cassandra) mientras que análisis por lotes y consultas que no requieren una marca de tiempo pueden ejecutarse en Hadoop. En este tipo de ecosistema, HDFS es reemplazado por Cassandra y esto es invisible para el desarrollador. Uno puede reasignar dinámicamente los nodos entre los entornos de Cassandra y Hadoop según corresponda.
- Cassandra File System elimina los puntos únicos de falla que están asociados con HDFS, es decir, los puntos de falla de NameNode y Job Tracker que están asociados con HDFS.
Por lo tanto, la idea es combinar Cassandra, que es pionera en sí misma en el procesamiento de transacciones en tiempo real de gran volumen , con Hadoop que sobresale en soluciones analíticas más orientadas a lotes .
Cassandra y los Biggies:
Muchas organizaciones de los sectores verticales de la industria están adoptando a Cassandra para lograr diversos objetivos comerciales. Algunos destacados son:
- Netflix – Utiliza Cassandra como su base de datos back-end para sus servicios de transmisión.
- WebEx de Cisco – Utiliza Cassandra para almacenar el feed y la actividad de los usuarios casi en tiempo real.
- SoundCloud – Utiliza Cassandra para almacenar el tablero de sus usuarios.
- IBM – Ha investigado en la construcción de un sistema de correo electrónico escalable basado en Cassandra
Títulos de trabajo que involucran habilidades de Hadoop y Cassandra:
Estudio realizado por Simplyhired muestra que los trabajos de Cassandra tienen una gran demanda debido a su alta tasa de adopción en la industria, especialmente en los últimos años. Y el futuro parece muy prometedor.

Veamos algunos de los títulos de trabajo relacionados con las habilidades de Hadoop-Cassandra y sus salarios mencionados en Indeed.com:
- Arquitecto de datos: Esta posición genera un salario promedio de $ 107,000. Los arquitectos de datos deben tener cierta experiencia en la creación de modelos de datos, el almacenamiento de datos, el análisis de datos y la migración de datos
- Científico de datos: Recopilan datos, los analizan, los presentan visualmente y los usan para hacer predicciones/pronósticos. El salario medio de un científico de datos es de 104 000 $
- Ingeniero de Sistemas: El salario promedio de los ingenieros de sistemas es de $89,000.
- DBA: Los DBA ganan un promedio de más de $100,000.
- Desarrollador de aplicaciones de software: Los desarrolladores de software ganan un salario promedio de $ 107,000 y los desarrolladores de aplicaciones $ 93,000. Las personas con estas habilidades pueden obtener un amplio trabajo independiente o pueden lanzar su propia empresa si tienen el espíritu emprendedor.
Publicaciones relacionadas:
Elegir la base de datos NoSQL correcta.
¿Cómo abrir CQLSH de Cassandra instalado en Windows?