En los blogs anteriores, mis colegas y yo le mostramos cómo puede monitorear el rendimiento, administrar e implementar clústeres, ejecutar copias de seguridad e incluso habilitar la conmutación por error automática para TimescaleDB.
En este blog, le mostraremos cómo escalar su única instancia de TimescaleDB a un clúster de varios nodos en solo unos pocos pasos.
Comenzaremos con una configuración común, una instancia de un solo nodo que se ejecuta en CentosOS. El nodo está funcionando y ya está siendo monitoreado y administrado por ClusterControl.
Si desea obtener información sobre cómo implementar o importar su instancia de TimescaleDB, consulte el blog escrito por mi colega Sebastian Insausti, "Cómo implementar fácilmente TimescaleDB".
La configuración es la siguiente...
 ClusterControl:instancia única de TimescaleDB
ClusterControl:instancia única de TimescaleDB Por lo tanto, es una única instancia de producción y queremos convertirla en un clúster sin tiempo de inactividad. Nuestro principal objetivo es escalar las operaciones de lectura de la aplicación a otras máquinas con la opción de usarlas como servidores HA provisionales cuando se bloquea el servidor de escritura.
Más nodos también deberían reducir el tiempo de inactividad por mantenimiento de aplicaciones. Al igual que la aplicación de parches en el modo de reinicio continuo:un nodo parcheado en ese momento mientras otros nodos están dando servicio a las conexiones de la base de datos.
El último requisito es crear una dirección única para nuestro nuevo clúster, de modo que nuestros nuevos nodos sean visibles para la aplicación desde un solo lugar.

Podemos resumir nuestro plan de acción en dos pasos principales:
- Añadir una réplica de lecturas
- Instalar y configurar Haproxy
Agregar una réplica de lecturas
Si vamos a las acciones del clúster y seleccionamos "Agregar esclavo de replicación", podemos crear una nueva réplica desde cero o agregar una base de datos TimescaleDB existente como réplica.
 ClusterControl:Agregar esclavo de replicación
ClusterControl:Agregar esclavo de replicación 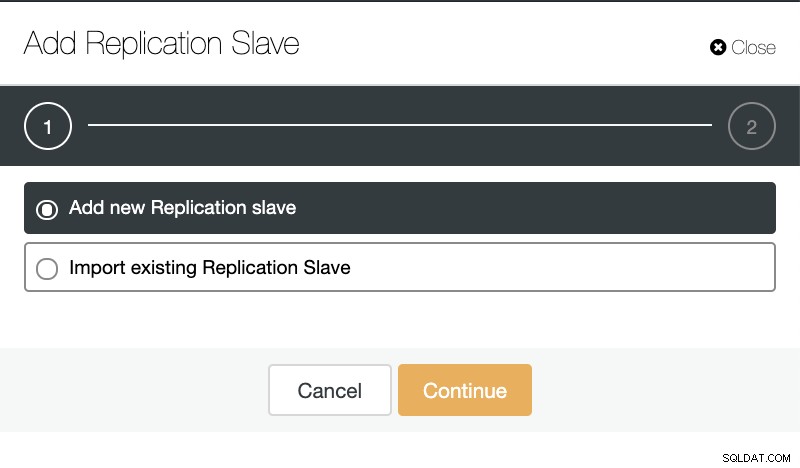 ClusterControl:agregar nuevo esclavo de replicación, importar esclavo de replicación existente
ClusterControl:agregar nuevo esclavo de replicación, importar esclavo de replicación existente Como puede ver en la imagen a continuación, solo necesitamos elegir nuestro servidor maestro, ingresar la dirección IP para nuestro nuevo servidor esclavo y el puerto de la base de datos.
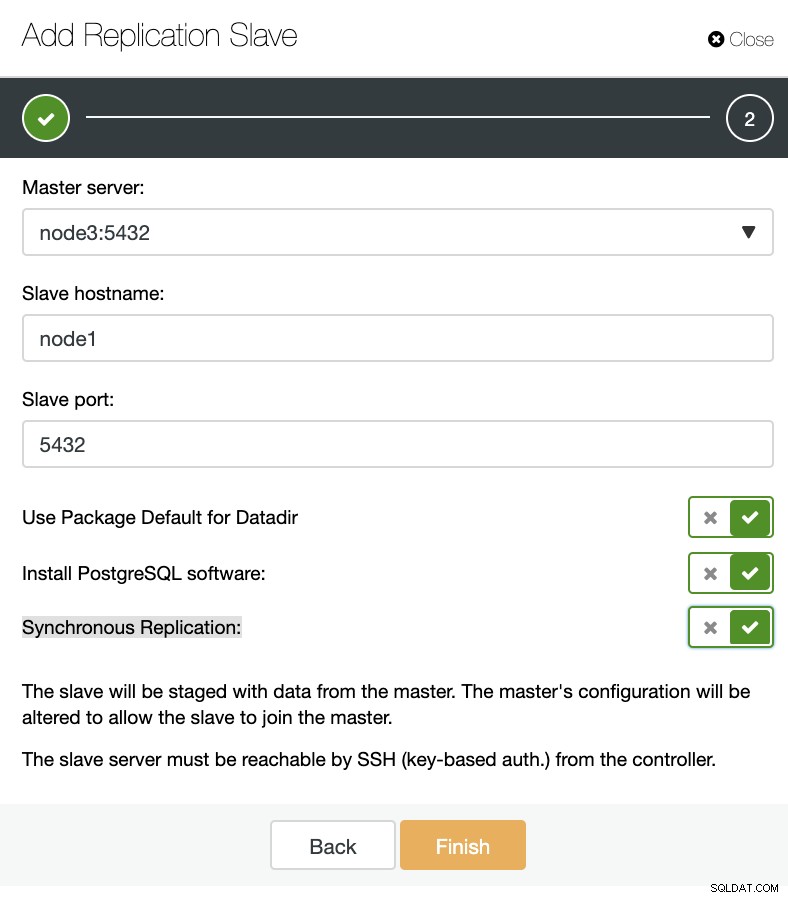 ClusterControl:Agregar esclavo de replicación
ClusterControl:Agregar esclavo de replicación Luego podemos elegir si queremos que ClusterControl instale el software por nosotros y si el esclavo de replicación debe ser síncrono o asíncrono. Cuando esté importando un servidor esclavo existente, puede usar la opción de importación de la siguiente manera:
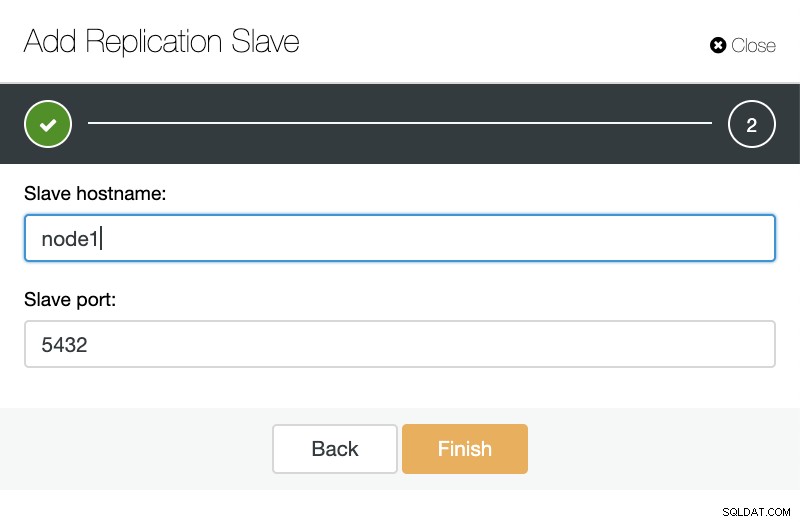 ClusterControl:importación de esclavo de replicación para TimescaleDB
ClusterControl:importación de esclavo de replicación para TimescaleDB En ambos sentidos, podemos añadir tantas réplicas como queramos. En nuestro caso de ejemplo, agregaremos dos nodos. CusterControl creará un trabajo interno y se encargará de todos los pasos necesarios uno por uno.
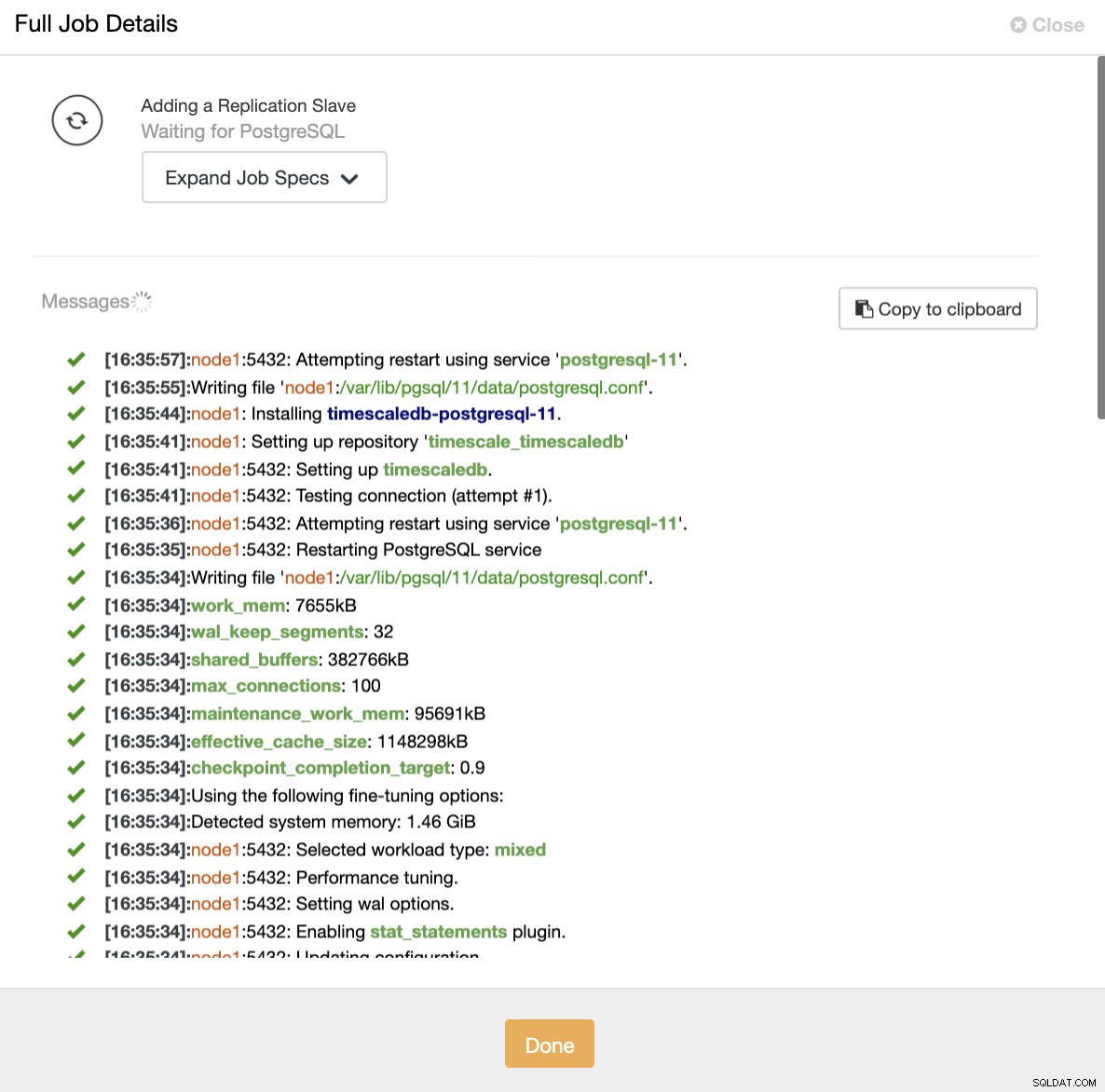 ClusterControl:agregar réplica de lectura
ClusterControl:agregar réplica de lectura Agregar un balanceador de carga a TimescaleDB
En este punto, nuestros datos se distribuyen en varios nodos o centros de datos si elige agregar nodos esclavos de replicación en una ubicación diferente. El clúster se amplía con dos nodos de réplica de lectura adicionales.
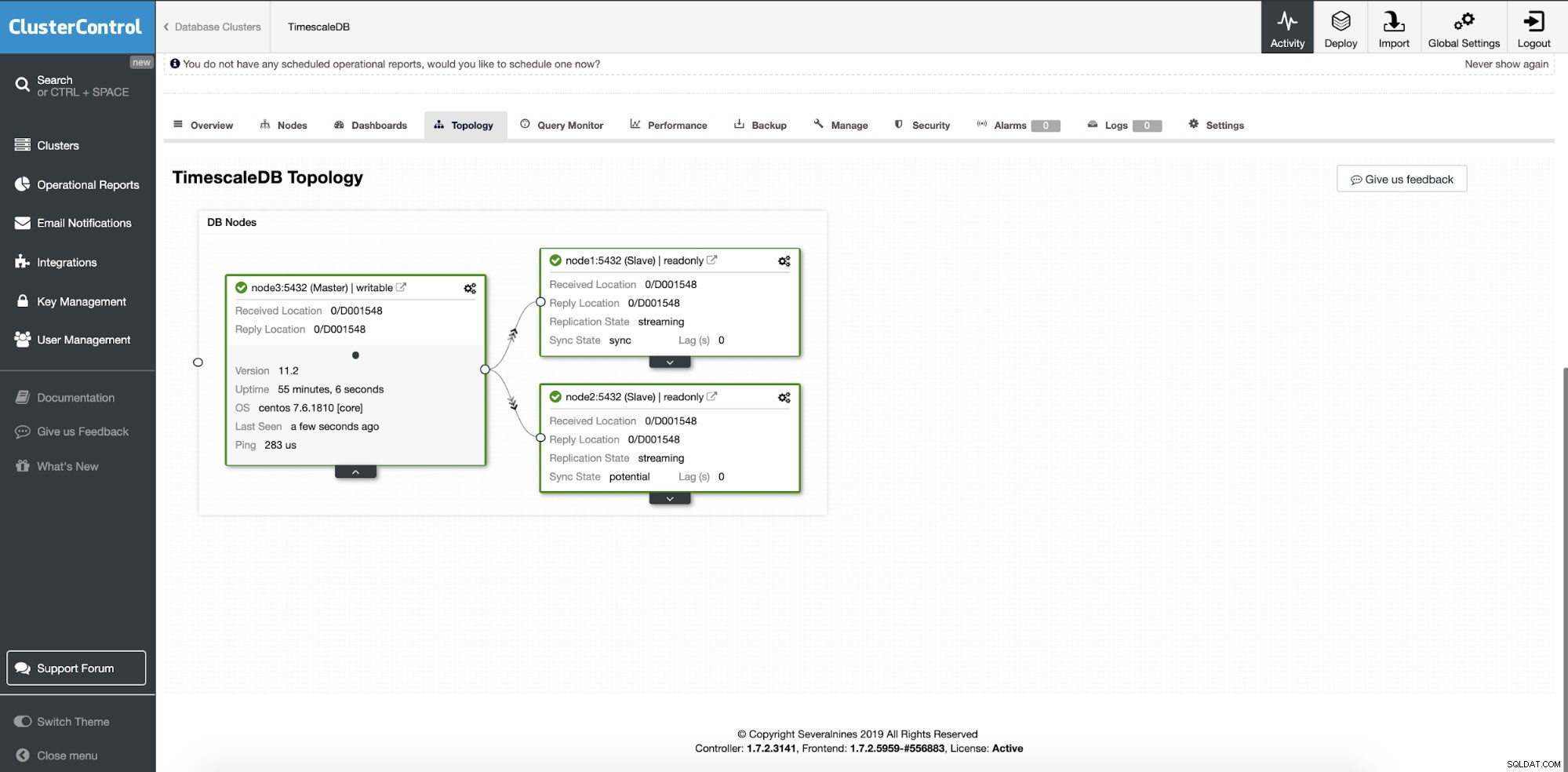 ClusterControl:dos nodos agregados
ClusterControl:dos nodos agregados La pregunta es ¿cómo sabe la aplicación a qué nodo de la base de datos acceder? Usaremos HAProxy y diferentes puertos para operaciones de escritura y lectura.
En el clúster de TimescaleDB, seleccione en el menú contextual Agregar balanceador de carga.

Ahora debemos proporcionar la ubicación del servidor donde se debe instalar Haproxy, qué política queremos usar para las conexiones de la base de datos y qué nodos forman parte de la configuración de Haproxy.
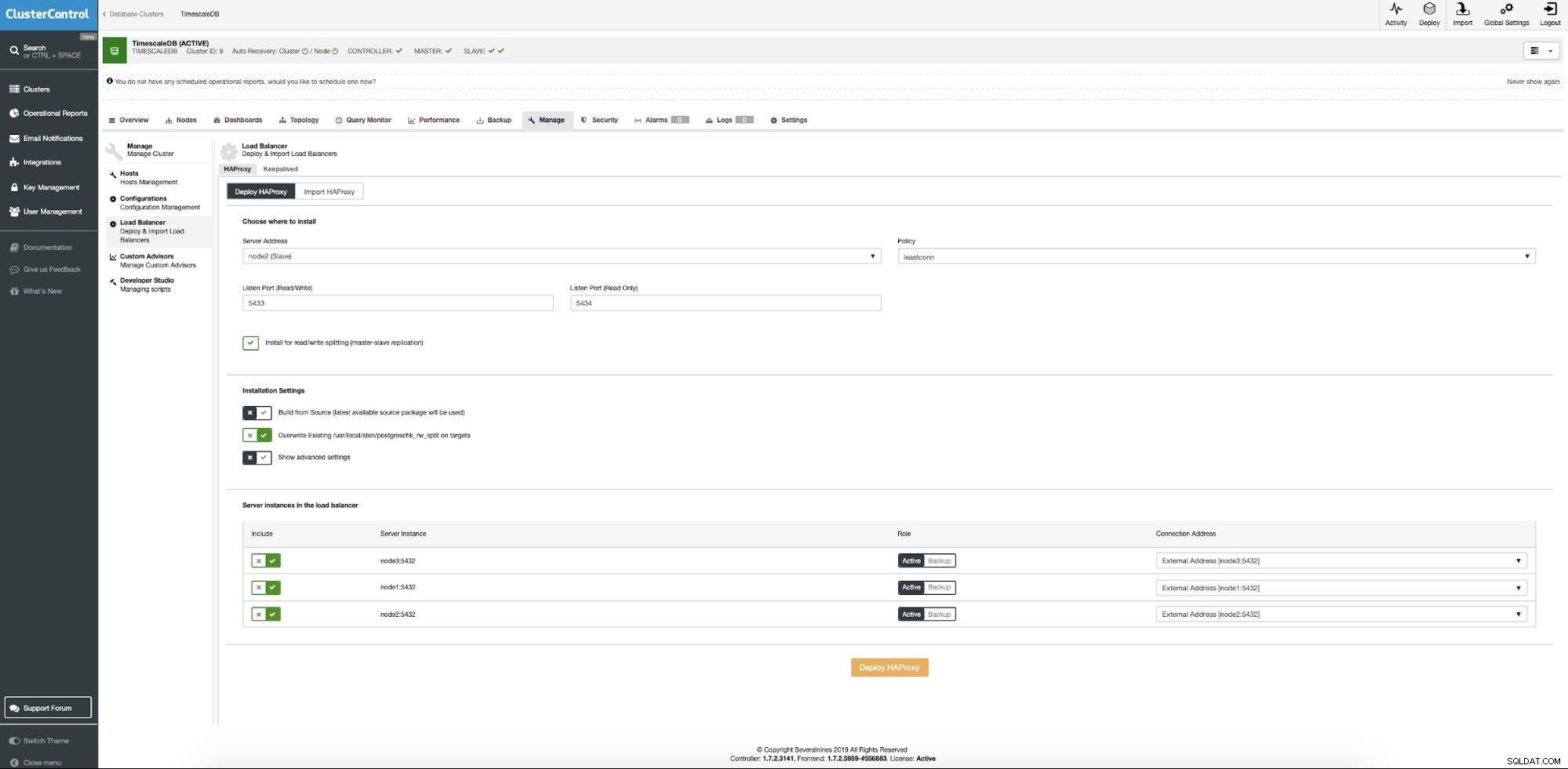
Cuando todo esté listo, presione el botón de implementación. Después de unos minutos, deberíamos tener lista la configuración de nuestro clúster. ClusterControl se encargará de todos los requisitos previos y configuraciones para implementar el balanceador de carga.
Después de una implementación exitosa, podemos ver la topología de nuestro nuevo clúster; con equilibrio de carga y nodos de lectura adicionales. Con más nodos integrados, ClusterControl habilita automáticamente la recuperación automática. De esta forma, cuando el nodo maestro se cae, la operación de conmutación por error se iniciará por sí misma.
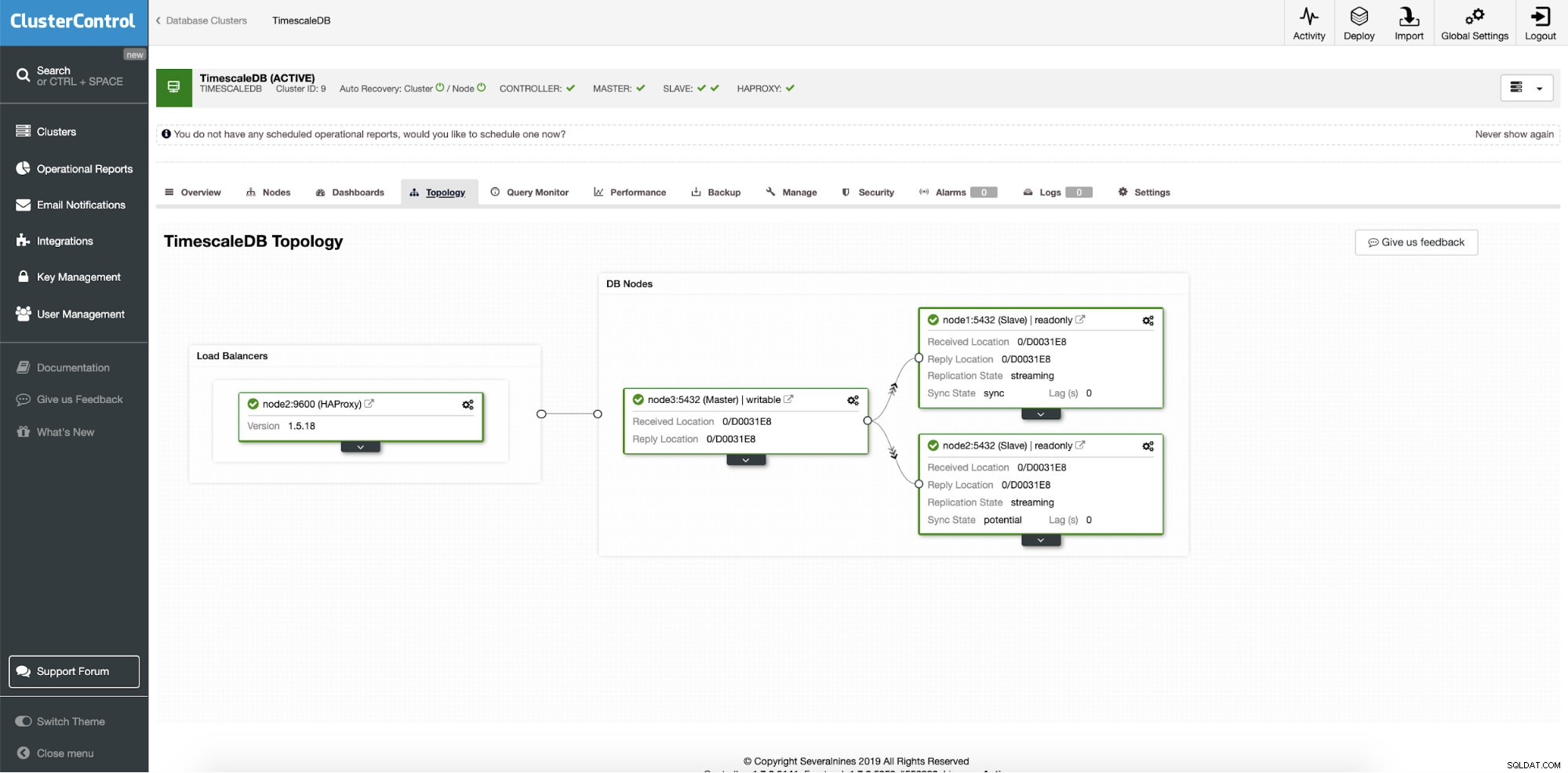 ClusterControl:topología final
ClusterControl:topología final Conclusión
TimescaleDB es una base de datos de código abierto inventada para hacer que SQL sea escalable para datos de series temporales. Tener una forma automatizada de ampliar su clúster es clave para lograr rendimiento y eficiencia. Como hemos visto anteriormente, ahora puede escalar TimescaleDB utilizando ClusterControl con facilidad.