Introducción
- Hay algunas reglas específicas que deben seguirse al crear los objetos de la base de datos. Para mejorar el rendimiento de una base de datos, se debe asignar a una tabla una clave principal, índices agrupados y no agrupados y restricciones. Aunque seguimos todas estas reglas, aún pueden aparecer filas duplicadas en una tabla.
- Siempre es una buena práctica hacer uso de las claves de la base de datos. El uso de las claves de la base de datos reducirá las posibilidades de obtener registros duplicados en una tabla. Pero si los registros duplicados ya están presentes en una tabla, existen formas específicas que se utilizan para eliminar estos registros duplicados.
Formas de eliminar filas duplicadas
Uso de DELETE JOIN instrucción para eliminar filas duplicadas
La declaración DELETE JOIN se proporciona en MySQL que ayuda a eliminar filas duplicadas de una tabla.
Considere una base de datos con el nombre "studentdb". Crearemos una tabla estudiante en ella.
mysql> USE studentdb;
Database changed
mysql> CREATE TABLE student (Stud_ID INT, Stud_Name VARCHAR(20), Stud_City VARCHAR(20), Stud_email VARCHAR(255), Stud_Age INT);
Query OK, 0 rows affected (0.15 sec)
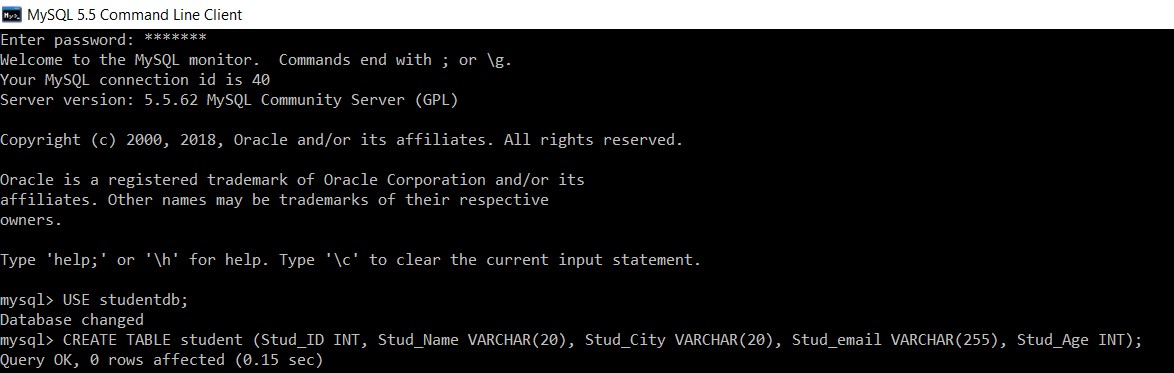
Hemos creado con éxito una tabla 'student' en la base de datos 'studentdb'.
Ahora, escribiremos las siguientes consultas para insertar datos en la tabla de estudiantes.
mysql> INSERT INTO student VALUES (1, "Ankit", "Nagpur", "[email protected]", 32);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (2, "Soham", "Nanded", "[email protected]", 35);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (3, "Soham", "Nanded", "[email protected]", 26);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (4, "Ravi", "Chandigarh", "[email protected]", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (5, "Ravi", "Chandigarh", "[email protected]", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (6, "Shyam", "Dehradun", "[email protected]", 22);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (7, "Manthan", "Ambala", "[email protected]", 24);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (8, "Neeraj", "Noida", "[email protected]", 25);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (9, "Anand", "Kashmir", "[email protected]", 20);
Query OK, 1 row affected (0.07 sec)
mysql> INSERT INTO student VALUES (10, "Raju", "Shimla", "[email protected]", 29);
Query OK, 1 row affected (0.13 sec)
mysql> INSERT INTO student VALUES (11, "Raju", "Shimla", "[email protected]", 29);
Query OK, 1 row affected (0.08 sec)
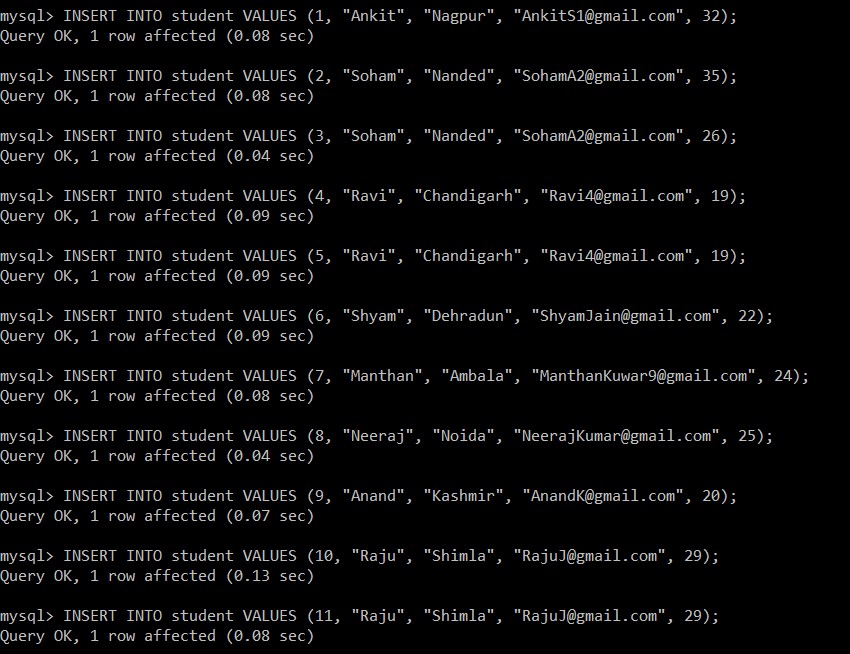
Ahora, recuperaremos todos los registros de la tabla de estudiantes. Consideraremos esta tabla y base de datos para todos los siguientes ejemplos.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | [email protected] | 32 |
| 2 | Soham | Nanded | [email protected] | 35 |
| 3 | Soham | Nanded | [email protected] | 26 |
| 4 | Ravi | Chandigarh | [email protected] | 19 |
| 5 | Ravi | Chandigarh | [email protected] | 19 |
| 6 | Shyam | Dehradun | [email protected] | 22 |
| 7 | Manthan | Ambala | [email protected] | 24 |
| 8 | Neeraj | Noida | [email protected] | 25 |
| 9 | Anand | Kashmir | [email protected] | 20 |
| 10 | Raju | Shimla | [email protected] | 29 |
| 11 | Raju | Shimla | [email protected] | 29 |
+---------+-----------+------------+-------------------------+----------+
11 rows in set (0.00 sec)
Ejemplo 1:
Escriba una consulta para eliminar filas duplicadas de la tabla de estudiantes usando DELETE JOIN declaración.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Hemos utilizado la consulta DELETE con INNER JOIN. Para implementar INNER JOIN en una sola tabla, hemos creado dos instancias s1 y s2. Luego, con la ayuda de la cláusula WHERE, verificamos dos condiciones para encontrar las filas duplicadas en la tabla de estudiantes. Si la identificación de correo electrónico en dos registros diferentes es la misma y la identificación del estudiante es diferente, se tratará como un registro duplicado de acuerdo con la condición de la cláusula WHERE.
Salida:
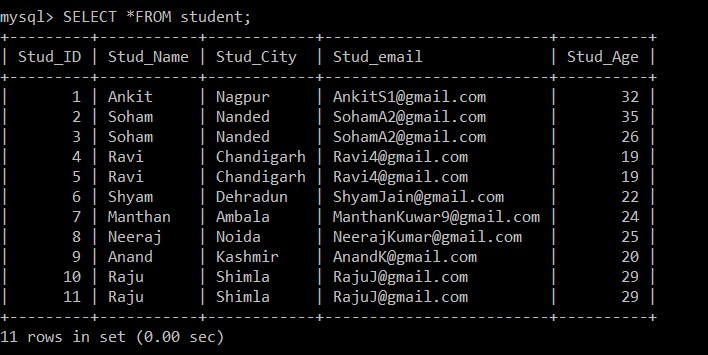
Query OK, 3 rows affected (0.20 sec)Los resultados de la consulta anterior muestran que hay tres registros duplicados presentes en la tabla de estudiantes.

Usaremos la consulta SELECT para encontrar los registros duplicados que fueron eliminados.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | [email protected] | 32 |
| 3 | Soham | Nanded | [email protected] | 26 |
| 5 | Ravi | Chandigarh | [email protected] | 19 |
| 6 | Shyam | Dehradun | [email protected] | 22 |
| 7 | Manthan | Ambala | [email protected] | 24 |
| 8 | Neeraj | Noida | [email protected] | 25 |
| 9 | Anand | Kashmir | [email protected] | 20 |
| 11 | Raju | Shimla | [email protected] | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
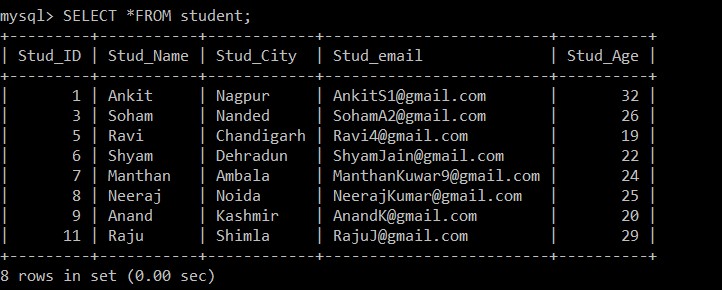
Ahora, solo hay 8 registros que están presentes en la tabla de estudiantes ya que los tres registros duplicados se eliminan de la tabla seleccionada actualmente. Según la siguiente condición:
s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Si las identificaciones de correo electrónico de dos registros son iguales, dado que se usa el signo menor que entre la identificación del estudiante, solo se mantendrá el registro con identificaciones de empleados mayores, y el otro registro duplicado se eliminará entre los dos registros.
Ejemplo 2:
Escriba una consulta para eliminar filas duplicadas de la tabla de estudiantes usando la declaración de unión de eliminación mientras mantiene el registro duplicado con una identificación de empleado menor y elimina la otra.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Hemos utilizado la consulta DELETE con INNER JOIN. Para implementar INNER JOIN en una sola tabla, hemos creado dos instancias s1 y s2. Luego, con la ayuda de la cláusula WHERE, verificamos dos condiciones para encontrar las filas duplicadas en la tabla de estudiantes. Si la identificación de correo electrónico presente en dos registros diferentes es la misma y la identificación del estudiante es diferente, se tratará como un registro duplicado de acuerdo con la condición de la cláusula WHERE.
Salida:
Query OK, 3 rows affected (0.09 sec)Los resultados de la consulta anterior muestran que hay tres registros duplicados presentes en la tabla de estudiantes.

Usaremos la consulta SELECT para encontrar los registros duplicados que fueron eliminados.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | [email protected] | 32 |
| 2 | Soham | Nanded | [email protected] | 35 |
| 4 | Ravi | Chandigarh | [email protected] | 19 |
| 6 | Shyam | Dehradun | [email protected] | 22 |
| 7 | Manthan | Ambala | [email protected] | 24 |
| 8 | Neeraj | Noida | [email protected] | 25 |
| 9 | Anand | Kashmir | [email protected] | 20 |
| 10 | Raju | Shimla | [email protected] | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
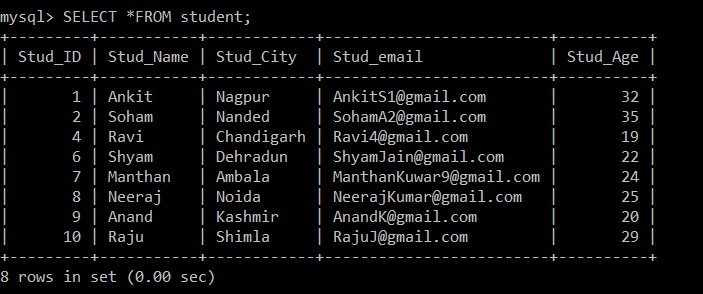
Ahora, solo hay 8 registros que están presentes en la tabla de estudiantes ya que los tres registros duplicados se eliminan de la tabla seleccionada actualmente. Según la siguiente condición:
s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Si las identificaciones de correo electrónico de dos registros cualesquiera son las mismas debido a que se usa el signo mayor que entre la identificación del estudiante, solo se mantendrá el registro con la identificación de empleado menor y el otro registro duplicado se eliminará entre los dos registros.
- Uso de una tabla intermedia para eliminar filas duplicadas
Se deben seguir los siguientes pasos al eliminar las filas duplicadas con la ayuda de una tabla intermedia.
- Se debe crear una nueva tabla, que será la misma que la tabla real.
- Agregue filas distintas de la tabla real a la tabla recién creada.
- Elimine la tabla real y cambie el nombre de la nueva tabla con el mismo nombre que una tabla real.
Ejemplo:
Escriba una consulta para eliminar los registros duplicados de la tabla de estudiantes utilizando una tabla intermedia.
En primer lugar, crearemos una tabla intermedia que será igual a la tabla de empleados.
mysql> CREATE TABLE temp_student LIKE student;
Query OK, 0 rows affected (0.14 sec)

Aquí, 'empleado' es la tabla original y 'temp_student' es la tabla intermedia.
Ahora, buscaremos solo los registros únicos de la tabla de estudiantes e insertaremos todos los registros obtenidos en la tabla temp_student.
mysql> INSERT INTO temp_student SELECT *FROM student GROUP BY Stud_email;
Query OK, 8 rows affected (0.12 sec)
Records: 8 Duplicates: 0 Warnings: 0

Aquí, antes de insertar los distintos registros de la tabla de estudiantes en temp_student, Stud_email filtra todos los registros duplicados. Luego, solo los registros con una identificación de correo electrónico única se han insertado en temp_student.
Paso 3:
Luego, eliminaremos la tabla de estudiantes y cambiaremos el nombre de la tabla temp_student a la tabla de estudiantes.
mysql> DROP TABLE student;
Query OK, 0 rows affected (0.08 sec)
mysql> ALTER TABLE temp_student RENAME TO student;
Query OK, 0 rows affected (0.08 sec)
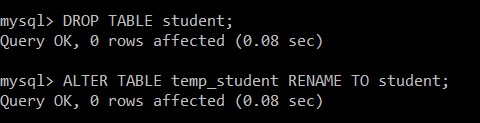
La tabla de estudiantes se eliminó con éxito y temp_student se renombró como la tabla de estudiantes, que contiene solo los registros únicos.
Luego, debemos verificar que la tabla de estudiantes ahora contiene solo los registros únicos. Para verificar esto, hemos utilizado la consulta SELECT para ver los datos contenidos en la tabla de estudiantes.
mysql> SELECT *FROM student;Salida:
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 9 | Anand | Kashmir | [email protected] | 20 |
| 1 | Ankit | Nagpur | [email protected] | 32 |
| 7 | Manthan | Ambala | [email protected] | 24 |
| 8 | Neeraj | Noida | [email protected] | 25 |
| 10 | Raju | Shimla | [email protected] | 29 |
| 4 | Ravi | Chandigarh | [email protected] | 19 |
| 6 | Shyam | Dehradun | [email protected] | 22 |
| 2 | Soham | Nanded | [email protected] | 35 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
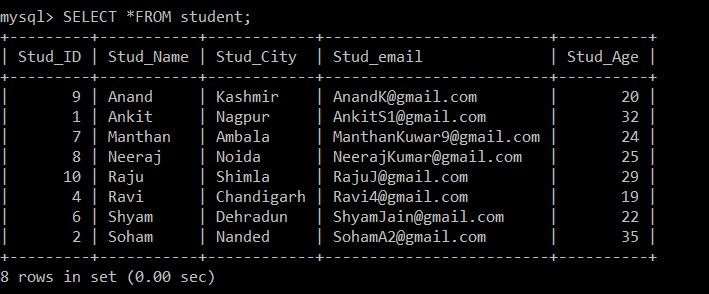
Ahora, solo hay 8 registros que están presentes en la tabla de estudiantes ya que los tres registros duplicados se eliminan de la tabla seleccionada actualmente. En el paso 2, mientras se obtenían los distintos registros de la tabla original y se los insertaba en una tabla intermedia, se utilizó una cláusula GROUP BY en Stud_email, por lo que todos los registros se insertaron en función de las identificaciones de correo electrónico de los estudiantes. Aquí, solo el registro con una identificación de empleado más baja se mantiene entre los registros duplicados de forma predeterminada, y el otro se elimina.