En el primer artículo, "Uso de Jenkins con Kubernetes AWS, parte 1", sobre la automatización de la instalación de Kubernetes con Jenkins, instalamos Jenkins en CoreOS, creamos los artefactos de requisitos previos para instalar Kubernetes y creamos un nodo de Jenkins. En el segundo artículo, "Uso de Jenkins con Kubernetes AWS, Parte 2", configuramos un archivo Jenkins y creamos una canalización de Jenkins. En este artículo, ejecutaremos la canalización de Jenkins para instalar Kubernetes y, posteriormente, probaremos el clúster de Kubernetes. Este artículo tiene las siguientes secciones:
- Ejecución de la canalización de Jenkins
- Prueba del clúster de Kubernetes
- Conclusión
Ejecución de la canalización de Jenkins
Haz clic en Crear ahora para ejecutar Jenkins Pipeline, como se muestra en la Figura 1.
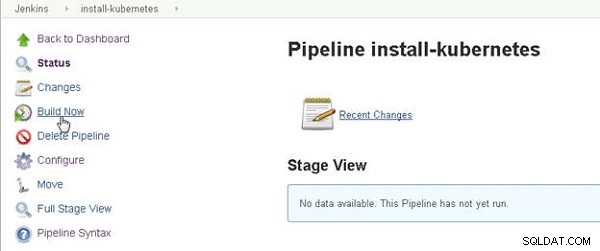
Figura 1: Build Now inicia Jenkins Pipeline
Jenkins Pipeline se inicia y una barra de progreso indica el progreso de la canalización. Una vista de escenario para las diversas etapas en la canalización también se muestra, como se muestra en la Figura 2. El Kube-aws la etapa de procesamiento en la Vista de etapa tiene un enlace "en pausa" porque solicitamos la entrada del usuario para el recuento de trabajadores (y la entrada del usuario del tipo de instancia, que se solicitará posteriormente) en el archivo Jenkins. Haga clic en el enlace "en pausa".
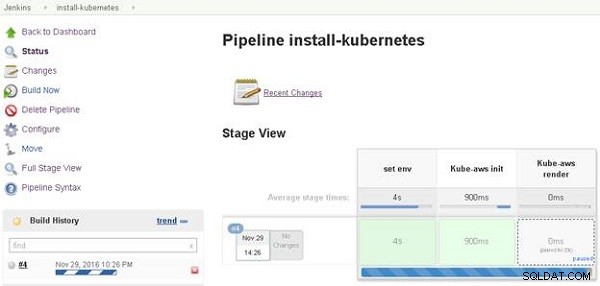
Figura 2: Obtención de la dirección IP pública
En la salida de la consola para Jenkins Pipeline, haga clic en Entrada solicitada enlace, como se muestra en la Figura 3.
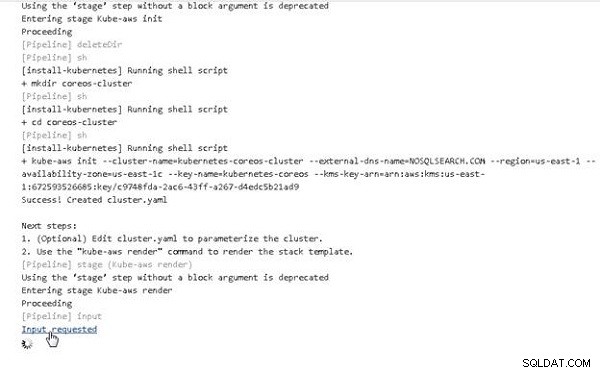
Figura 3: Entrada solicitada para el número de nodos
Un número de nodos Se muestra el cuadro de diálogo, que solicita la entrada del usuario para la cantidad de nodos, como se muestra en la Figura 4. También se establece un valor predeterminado como se configuró en el archivo Jenkins. Haz clic en Continuar después de especificar un valor.
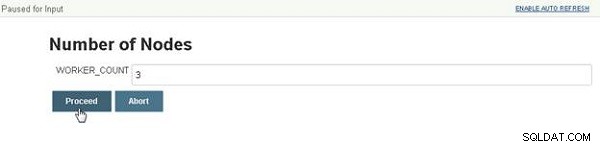
Figura 4: Especificación del número de nodos
Pipeline continúa ejecutándose y nuevamente se detiene en otra solicitud de entrada para el tipo de instancia. Haz clic en Entrada solicitada , como se muestra en la Figura 5.
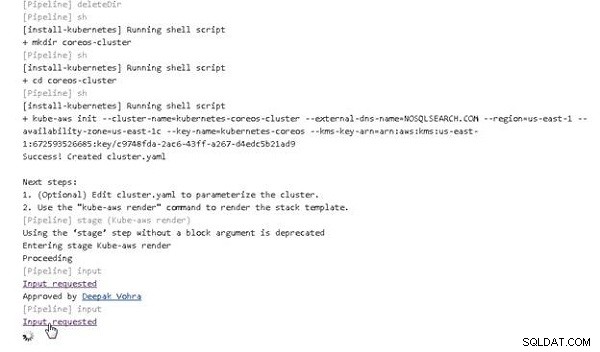
Figura 5: Entrada solicitada para el tipo de instancia
El tipo de instancia se muestra el cuadro de diálogo (ver Figura 6). Seleccione el valor predeterminado (o especifique un valor diferente) y haga clic en Continuar.

Figura 6: Especificación del tipo de instancia
La canalización sigue funcionando. En la etapa Implementar clúster, se presenta otro enlace Entrada solicitada, como se muestra en la Figura 7. Haga clic en el enlace.
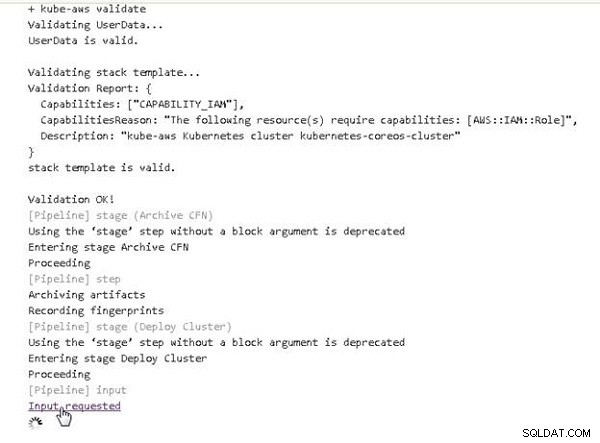
Figura 7: Entrada solicitada para ¿Debe implementarse el clúster?
En el clúster ¿Debería implementarse? cuadro de diálogo, seleccione el valor predeterminado de "sí" y haga clic en Continuar, como se muestra en la Figura 8.
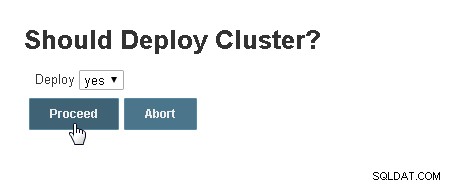
Figura 8: ¿Debería implementar un clúster?
La canalización sigue funcionando. La creación de los recursos de AWS para un clúster de Kubernetes podría llevar un tiempo, como lo indica el mensaje en la salida de la consola que se muestra en la Figura 9.
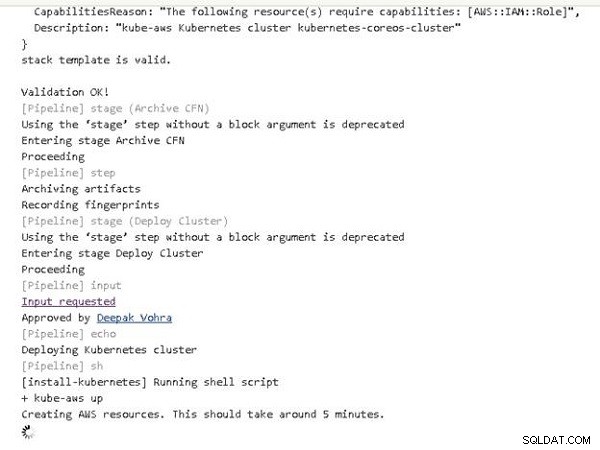
Figura 9: Creación de recursos de AWS
La tubería se ejecuta hasta su finalización. Un mensaje de "ÉXITO" indica que la canalización se ejecutó correctamente, como se muestra en la Figura 10.

Figura 10: La ejecución de canalización de Jenkins se completó con éxito
La Vista de etapa para la canalización de Jenkins muestra las diversas etapas de la canalización que se han completado, como se muestra en la Figura 11. La vista de etapa incluye enlaces para Última compilación, Última compilación estable, Última compilación exitosa y Última compilación completada.

Figura 11: Vista de escenario
Haga clic en Vista de escenario completo para mostrar la vista de escenario completo por separado, como se muestra en la Figura 12.
Figura 12: Selección de vista de escenario completo
Se muestra la Vista completa del escenario, como se muestra en la Figura 13.
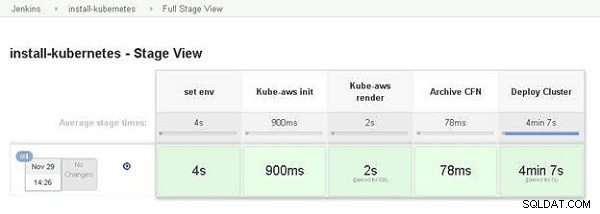
Figura 13: Vista de escenario completo
En el Tablero, el ícono adyacente a Jenkins Pipeline se vuelve verde para indicar que se completó con éxito, como se muestra en la Figura 14.
Figura 14: Jenkins Dashboard con Jenkins Pipeline listado como completado con éxito
Para mostrar la salida de la consola, seleccione Salida de la consola para la compilación, como se muestra en la Figura 15.
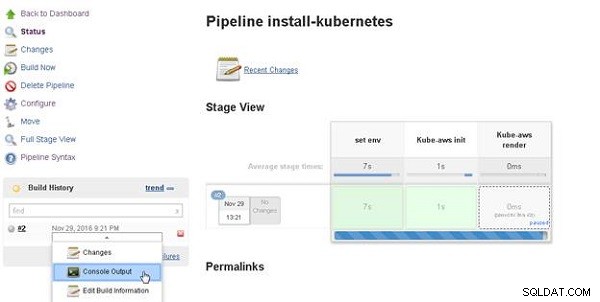
Figura 15: Historial de compilación>Salida de la consola
Se muestra la salida de la consola (consulte la Figura 16).

Figura 16: Salida de consola
Una salida de consola más detallada se incluye en el siguiente segmento de código:
Started by user Deepak Vohra
[Pipeline] node
Running on jenkins in /var/jenkins/workspace/install-kubernetes
[Pipeline] {
[Pipeline] stage (set env)
Using the 'stage' step without a block argument is deprecated
Entering stage set env
Proceeding
[Pipeline] sh
[install-kubernetes] Running shell script
+ sudo yum install gnupg2
Loaded plugins: priorities, update-motd, upgrade-helper
Package gnupg2-2.0.28-1.30.amzn1.x86_64 already installed and
latest version
Nothing to do
[Pipeline] sh
[install-kubernetes] Running shell script
+ gpg2 --keyserver pgp.mit.edu --recv-key FC8A365E
gpg: directory '/home/ec2-user/.gnupg' created
gpg: new configuration file '/home/ec2-user/.gnupg/gpg.conf'
created
...
...
[Pipeline] sh
[install-kubernetes] Running shell script
+ gpg2 --fingerprint FC8A365E
pub 4096R/FC8A365E 2016-03-02 [expires: 2021-03-01]
Key fingerprint = 18AD 5014 C99E F7E3 BA5F 6CE9 50BD
D3E0 FC8A 365E
uid [ unknown] CoreOS Application Signing Key
<[email protected]>
sub 2048R/3F1B2C87 2016-03-02 [expires: 2019-03-02]
sub 2048R/BEDDBA18 2016-03-08 [expires: 2019-03-08]
sub 2048R/7EF48FD3 2016-03-08 [expires: 2019-03-08]
[Pipeline] sh
[install-kubernetes] Running shell script
+ wget https://github.com/coreos/coreos-kubernetes/releases/
download/v0.7.1/kube-aws-linux-amd64.tar.gz
--2016-11-29 21:22:04-- https://github.com/coreos/
coreos-kubernetes/releases/download/v0.7.1/
kube-aws-linux-amd64.tar.gz
Resolving github.com (github.com)... 192.30.253.112,
192.30.253.113
Connecting to github.com (github.com)|192.30.253.112|:443...
connected.
HTTP request sent, awaiting response... 302 Found
Location: https://github-cloud.s3.amazonaws.com/releases/
41458519/309e294a-29b1-
...
...
2016-11-29 21:22:05 (62.5 MB/s) - 'kube-aws-linux-amd64.tar.gz'
saved [4655969/4655969]
[Pipeline] sh
[install-kubernetes] Running shell script
+ wget https://github.com/coreos/coreos-kubernetes/releases/
download/v0.7.1/kube-aws-linux-amd64.tar.gz.sig
--2016-11-29 21:22:05-- https://github.com/coreos/
coreos-kubernetes/releases/download/v0.7.1/kube-aws-linux-
amd64.tar.gz.sig
Resolving github.com (github.com)... 192.30.253.113,
192.30.253.112
Connecting to github.com (github.com)|192.30.253.113|:443...
connected.
HTTP request sent, awaiting response... 302 Found
Location: https://github-cloud.s3.amazonaws.com/releases/
41458519/0543b716-2bf4-
...
...
Saving to: 'kube-aws-linux-amd64.tar.gz.sig'
0K 100% 9.21M=0s
2016-11-29 21:22:05 (9.21 MB/s) -
'kube-aws-linux-amd64.tar.gz.sig' saved [287/287]
[Pipeline] sh
[install-kubernetes] Running shell script
+ gpg2 --verify kube-aws-linux-amd64.tar.gz.sig kube-aws-
linux-amd64.tar.gz
gpg: Signature made Mon 06 Jun 2016 09:32:47 PM UTC using RSA
key ID BEDDBA18
gpg: Good signature from "CoreOS Application Signing Key
<[email protected]>" [unknown]
gpg: WARNING: This key is not certified with a trusted
signature!
gpg: There is no indication that the signature belongs to the
owner.
Primary key fingerprint: 18AD 5014 C99E F7E3 BA5F 6CE9 50BD
D3E0 FC8A 365E
Subkey fingerprint: 55DB DA91 BBE1 849E A27F E733 A6F7
1EE5 BEDD BA18
[Pipeline] sh
[install-kubernetes] Running shell script
+ tar zxvf kube-aws-linux-amd64.tar.gz
linux-amd64/
linux-amd64/kube-aws
[Pipeline] sh
[install-kubernetes] Running shell script
+ sudo mv linux-amd64/kube-aws /usr/local/bin
[Pipeline] sh
[install-kubernetes] Running shell script
...
...
[Pipeline] sh
[install-kubernetes] Running shell script
+ aws ec2 create-volume --availability-zone us-east-1c
--size 10 --volume-type gp2
{
"AvailabilityZone": "us-east-1c",
"Encrypted": false,
"VolumeType": "gp2",
"VolumeId": "vol-b325332f",
"State": "creating",
"Iops": 100,
"SnapshotId": "",
"CreateTime": "2016-11-29T21:22:07.949Z",
"Size": 10
}
[Pipeline] sh
[install-kubernetes] Running shell script
+ aws ec2 create-key-pair --key-name kubernetes-coreos
--query KeyMaterial --output text
[Pipeline] sh
[install-kubernetes] Running shell script
+ chmod 400 kubernetes-coreos.pem
[Pipeline] stage (Kube-aws init)
Using the 'stage' step without a block argument is deprecated
Entering stage Kube-aws init
Proceeding
[Pipeline] deleteDir
[Pipeline] sh
[install-kubernetes] Running shell script
+ mkdir coreos-cluster
[Pipeline] sh
[install-kubernetes] Running shell script
+ cd coreos-cluster
[Pipeline] sh
[install-kubernetes] Running shell script
+ kube-aws init --cluster-name=kubernetes-coreos-cluster
--external-dns-name=NOSQLSEARCH.COM --region=us-east-1
--availability-zone=us-east-1c --key-name=kubernetes-coreos
--kms-key-arn=arn:aws:kms:us-east-1:672593526685:key/
c9748fda-2ac6-43ff-a267-d4edc5b21ad9
Success! Created cluster.yaml
Next steps:
1. (Optional) Edit cluster.yaml to parameterize the cluster.
2. Use the "kube-aws render" command to render the stack
template.
[Pipeline] stage (Kube-aws render)
Using the 'stage' step without a block argument is deprecated
Entering stage Kube-aws render
Proceeding
[Pipeline] input
Input requested
Approved by Deepak Vohra
[Pipeline] input
Input requested
Approved by Deepak Vohra
[Pipeline] sh
[install-kubernetes] Running shell script
+ kube-aws render
Success! Stack rendered to stack-template.json.
Next steps:
1. (Optional) Validate your changes to cluster.yaml with
"kube-aws validate"
2. (Optional) Further customize the cluster by modifying
stack-template.json or files in ./userdata.
3. Start the cluster with "kube-aws up".
[Pipeline] sh
[install-kubernetes] Running shell script
+ sed -i 's/#workerCount: 1/workerCount: 3/' cluster.yaml
[Pipeline] sh
[install-kubernetes] Running shell script
+ sed -i 's/#workerInstanceType: m3.medium/
workerInstanceType: t2.micro/' cluster.yaml
[Pipeline] sh
[install-kubernetes] Running shell script
+ kube-aws validate
Validating UserData...
UserData is valid.
Validating stack template...
Validation Report: {
Capabilities: ["CAPABILITY_IAM"],
CapabilitiesReason: "The following resource(s) require
capabilities: [AWS::IAM::Role]",
Description: "kube-aws Kubernetes cluster
kubernetes-coreos-cluster"
}
stack template is valid.
Validation OK!
[Pipeline] stage (Archive CFN)
Using the 'stage' step without a block argument is deprecated
Entering stage Archive CFN
Proceeding
[Pipeline] step
Archiving artifacts
Recording fingerprints
[Pipeline] stage (Deploy Cluster)
Using the 'stage' step without a block argument is deprecated
Entering stage Deploy Cluster
Proceeding
[Pipeline] input
Input requested
Approved by Deepak Vohra
[Pipeline] echo
Deploying Kubernetes cluster
[Pipeline] sh
[install-kubernetes] Running shell script
+ kube-aws up
Creating AWS resources. This should take around 5 minutes.
Success! Your AWS resources have been created:
Cluster Name: kubernetes-coreos-cluster
Controller IP: 34.193.183.134
The containers that power your cluster are now being downloaded.
You should be able to access the Kubernetes API once the
containers finish downloading.
[Pipeline] sh
[install-kubernetes] Running shell script
+ kube-aws status
Cluster Name: kubernetes-coreos-cluster
Controller IP: 34.193.183.134
[Pipeline] step
Archiving artifacts
Recording fingerprints
[Pipeline] }
[Pipeline] // Node
[Pipeline] End of Pipeline
Finished: SUCCESS
Prueba del clúster de Kubernetes
Habiendo instalado Kubernetes, a continuación probaremos el clúster ejecutando alguna aplicación. Primero, necesitamos configurar la IP del controlador en el nombre de DNS público (el nosqlsearch.com dominio). Copie la IP del controlador desde la salida de la consola, como se muestra en la Figura 17.
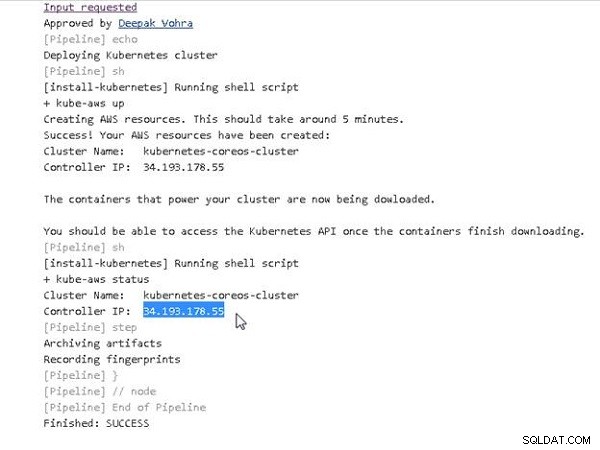
Figura 17: Obtención de la dirección IP pública
La Ip del controlador de Kubernetes también se puede obtener desde la consola de EC2, como se muestra en la Figura 18.
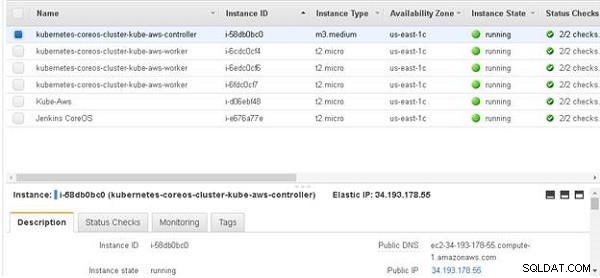
Figura 18: Obtención de la Ip del controlador de Kubernetes
Agregue una entrada A (Host) al archivo de zona DNS para el dominio nosqlsearch.com en el proveedor de alojamiento, como se muestra en la Figura 19. Agregar un registro A sería ligeramente diferente para diferentes proveedores de alojamiento.
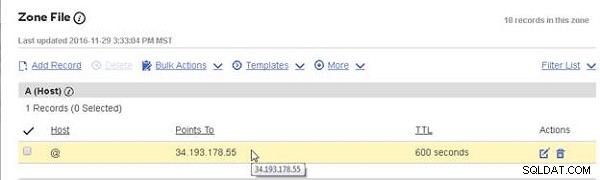
Figura 19: Obtención de la dirección IP pública
SSH Inicie sesión en Kubernetes Master utilizando la IP del maestro.
ssh -i "kubernetes-coreos.pem" [email protected]
Se muestra el símbolo del sistema de CoreOS, como se muestra en la Figura 20.
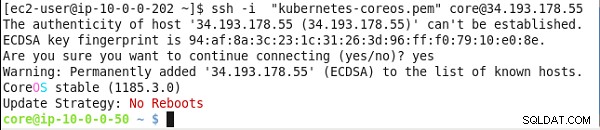
Figura 20: Obtención de la dirección IP pública
Instale el kubectl binarios:
sudo wget https://storage.googleapis.com/kubernetes-release/ release/v1.3.0/bin/linux/amd64/./kubectl sudo chmod +x ./kubectl
Enumere los nodos:
./kubectl get nodes
Los nodos del clúster de Kubernetes se enumeran (consulte la Figura 21).
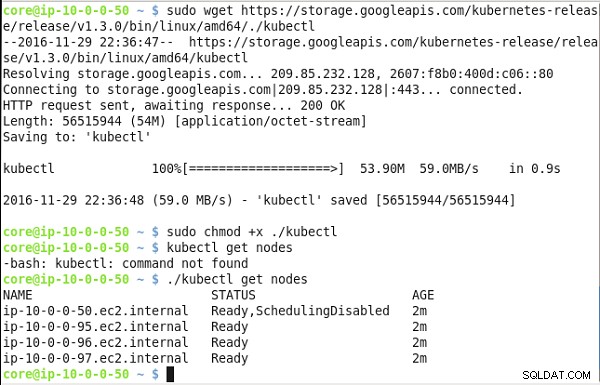
Figura 21: Obtención de la dirección IP pública
Para probar el clúster, cree una implementación para nginx compuesto por tres réplicas.
kubectl run nginx --image=nginx --replicas=3
Posteriormente, enumere las implementaciones:
kubectl get deployments
La implementación de "nginx" debería aparecer en la lista, como se muestra en la Figura 22.

Figura 22: Obtención de la dirección IP pública
Enumere los pods de todo el clúster:
kubectl get pods -o wide
Cree un servicio de tipo LoadBalancer del nginx despliegue:
kubectl expose deployment nginx --port=80 --type=LoadBalancer
Enumere los servicios:
kubectl get services
Los pods de todo el clúster se enumeran, como se muestra en la Figura 23. El servicio "nginx" se crea y se enumera, incluida la IP del clúster y la IP externa.
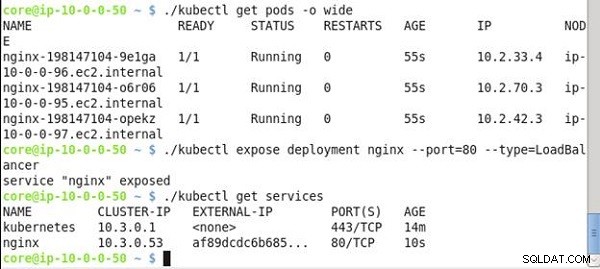
Figura 23: Obtención de la dirección IP pública
Invoca el nginx servicio en la IP del clúster. El nginx se muestra el marcado HTML de salida del servicio, como se muestra en la Figura 24.
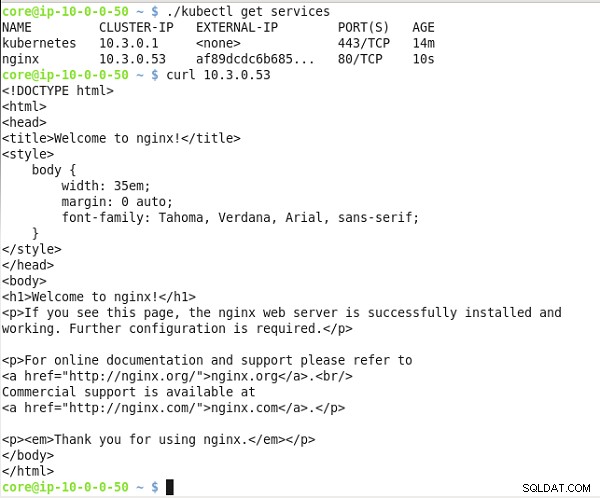
Figura 24: Obtención de la dirección IP pública
Conclusión
En tres artículos, analizamos la instalación del clúster de Kubernetes mediante un proyecto de Jenkins. Creamos un proyecto de canalización de Jenkins con un archivo Jenkins para instalar el clúster. Una canalización de Jenkins automatiza la instalación de Kubernetes, y la misma canalización de Jenkins puede modificarse según sea necesario y volver a ejecutarse para crear varios clústeres de Kubernetes.