En la Parte 1 de esta serie, usó Flask y Connexion para crear una API REST que proporciona operaciones CRUD a una estructura simple en memoria llamada PEOPLE . Eso funcionó para demostrar cómo el módulo Connexion lo ayuda a crear una buena API REST junto con documentación interactiva.
Como algunos señalaron en los comentarios de la Parte 1, la PEOPLE La estructura se reinicializa cada vez que se reinicia la aplicación. En este artículo, aprenderá a almacenar las PEOPLE estructura y las acciones que proporciona la API a una base de datos mediante SQLAlchemy y Marshmallow.
SQLAlchemy proporciona un modelo relacional de objetos (ORM), que almacena objetos de Python en una representación de base de datos de los datos del objeto. Eso puede ayudarlo a seguir pensando de una manera pitónica y no preocuparse por cómo se representarán los datos del objeto en una base de datos.
Marshmallow proporciona funcionalidad para serializar y deserializar objetos de Python a medida que fluyen desde y hacia nuestra API REST basada en JSON. Marshmallow convierte las instancias de la clase Python en objetos que se pueden convertir a JSON.
Puede encontrar el código de Python para este artículo aquí.
Bono Gratis: Haga clic aquí para descargar una copia de la guía "Ejemplos de API REST" y obtener una introducción práctica a los principios de Python + API REST con ejemplos prácticos.
Para quién es este artículo
Si disfrutó de la Parte 1 de esta serie, este artículo amplía aún más su cinturón de herramientas. Usará SQLAlchemy para acceder a una base de datos de una manera más pitónica que SQL directo. También utilizará Marshmallow para serializar y deserializar los datos administrados por la API REST. Para hacer esto, utilizará las funciones básicas de Programación Orientada a Objetos disponibles en Python.
También utilizará SQLAlchemy para crear una base de datos e interactuar con ella. Esto es necesario para poner en funcionamiento la API REST con PEOPLE datos utilizados en la Parte 1.
La aplicación web presentada en la Parte 1 tendrá sus archivos HTML y JavaScript modificados de forma menor para admitir los cambios también. Puede revisar la versión final del código de la Parte 1 aquí.
Dependencias adicionales
Antes de comenzar a crear esta nueva funcionalidad, deberá actualizar el virtualenv que creó para ejecutar el código de la Parte 1 o crear uno nuevo para este proyecto. La forma más sencilla de hacerlo después de haber activado su virtualenv es ejecutar este comando:
$ pip install Flask-SQLAlchemy flask-marshmallow marshmallow-sqlalchemy marshmallow
Esto agrega más funcionalidad a su virtualenv:
-
Flask-SQLAlchemyagrega SQLAlchemy, junto con algunos enlaces a Flask, lo que permite que los programas accedan a las bases de datos. -
flask-marshmallowagrega las partes Flask de Marshmallow, que permite que los programas conviertan objetos de Python hacia y desde estructuras serializables. -
marshmallow-sqlalchemyagrega algunos ganchos Marshmallow en SQLAlchemy para permitir que los programas serialicen y deserialicen objetos de Python generados por SQLAlchemy. -
marshmallowagrega la mayor parte de la funcionalidad de Marshmallow.
Datos de personas
Como se mencionó anteriormente, las PEOPLE La estructura de datos del artículo anterior es un diccionario Python en memoria. En ese diccionario, usó el apellido de la persona como clave de búsqueda. La estructura de datos se veía así en el código:
# Data to serve with our API
PEOPLE = {
"Farrell": {
"fname": "Doug",
"lname": "Farrell",
"timestamp": get_timestamp()
},
"Brockman": {
"fname": "Kent",
"lname": "Brockman",
"timestamp": get_timestamp()
},
"Easter": {
"fname": "Bunny",
"lname": "Easter",
"timestamp": get_timestamp()
}
}
Las modificaciones que hará al programa moverán todos los datos a una tabla de base de datos. Esto significa que los datos se guardarán en su disco y existirán entre ejecuciones de server.py programa.
Debido a que el apellido era la clave del diccionario, el código restringía cambiar el apellido de una persona:solo se podía cambiar el primer nombre. Además, pasar a una base de datos le permitirá cambiar el apellido, ya que ya no se utilizará como clave de búsqueda para una persona.
Conceptualmente, una tabla de base de datos se puede considerar como una matriz bidimensional donde las filas son registros y las columnas son campos en esos registros.
Las tablas de la base de datos suelen tener un valor entero de incremento automático como clave de búsqueda para las filas. Esto se llama la clave principal. Cada registro de la tabla tendrá una clave principal cuyo valor es único en toda la tabla. Tener una clave principal independiente de los datos almacenados en la tabla le permite modificar cualquier otro campo de la fila.
La clave principal de incremento automático significa que la base de datos se encarga de:
- Incrementar el campo de clave principal existente más grande cada vez que se inserta un nuevo registro en la tabla
- Usar ese valor como clave principal para los datos recién insertados
Esto garantiza una clave principal única a medida que crece la tabla.
Vas a seguir una convención de base de datos de nombrar la tabla como singular, por lo que la tabla se llamará person . Traduciendo nuestra PEOPLE estructura anterior en una tabla de base de datos llamada person te da esto:
| id_persona | nombre | fname | marca de tiempo |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Pascua | Conejito | 2018-08-08 21:16:01.886834 |
Cada columna de la tabla tiene un nombre de campo de la siguiente manera:
person_id: campo de clave principal para cada personalname: apellido de la personafname: nombre de la personatimestamp: marca de tiempo asociada con las acciones de inserción/actualización
Interacción con la base de datos
Vas a utilizar SQLite como motor de base de datos para almacenar las PEOPLE datos. SQLite es la base de datos más ampliamente distribuida en el mundo y viene con Python de forma gratuita. Es rápido, realiza todo su trabajo utilizando archivos y es adecuado para una gran cantidad de proyectos. Es un RDBMS (Sistema de gestión de bases de datos relacionales) completo que incluye SQL, el lenguaje de muchos sistemas de bases de datos.
Por el momento, imagina a la person la tabla ya existe en una base de datos SQLite. Si ha tenido alguna experiencia con RDBMS, probablemente conozca SQL, el lenguaje de consulta estructurado que la mayoría de los RDBMS utilizan para interactuar con la base de datos.
A diferencia de los lenguajes de programación como Python, SQL no define cómo para obtener los datos:describe qué se desean los datos, dejando el cómo hasta el motor de la base de datos.
Una consulta SQL obteniendo todos los datos en nuestra person la tabla, ordenada por apellido, se vería así:
SELECT * FROM person ORDER BY 'lname';
Esta consulta le dice al motor de la base de datos que obtenga todos los campos de la tabla de personas y los ordene en el orden ascendente predeterminado usando el lname campo.
Si ejecutara esta consulta en una base de datos SQLite que contiene la person tabla, los resultados serían un conjunto de registros que contienen todas las filas de la tabla, con cada fila que contiene los datos de todos los campos que forman una fila. A continuación se muestra un ejemplo que utiliza la herramienta de línea de comandos de SQLite que ejecuta la consulta anterior contra la person tabla de base de datos:
sqlite> SELECT * FROM person ORDER BY lname;
2|Brockman|Kent|2018-08-08 21:16:01.888444
3|Easter|Bunny|2018-08-08 21:16:01.889060
1|Farrell|Doug|2018-08-08 21:16:01.886834
El resultado anterior es una lista de todas las filas en person tabla de la base de datos con caracteres de canalización ('|') que separan los campos en la fila, lo que SQLite realiza con fines de visualización.
Python es completamente capaz de interactuar con muchos motores de bases de datos y ejecutar la consulta SQL anterior. Lo más probable es que los resultados sean una lista de tuplas. La lista externa contiene todos los registros en la person mesa. Cada tupla interna individual contendría todos los datos que representan cada campo definido para una fila de la tabla.
Obtener datos de esta manera no es muy Pythonic. La lista de registros está bien, pero cada registro individual es solo una tupla de datos. Depende del programa conocer el índice de cada campo para recuperar un campo en particular. El siguiente código de Python usa SQLite para demostrar cómo ejecutar la consulta anterior y mostrar los datos:
1import sqlite3
2
3conn = sqlite3.connect('people.db')
4cur = conn.cursor()
5cur.execute('SELECT * FROM person ORDER BY lname')
6people = cur.fetchall()
7for person in people:
8 print(f'{person[2]} {person[1]}')
El programa anterior hace lo siguiente:
-
Línea 1 importa el
sqlite3módulo. -
Línea 3 crea una conexión con el archivo de la base de datos.
-
Línea 4 crea un cursor a partir de la conexión.
-
Línea 5 usa el cursor para ejecutar un
SQLconsulta expresada como una cadena. -
Línea 6 obtiene todos los registros devueltos por
SQLconsulta y los asigna a laspeoplevariables. -
Líneas 7 y 8 iterar sobre las
peopleenumera la variable e imprime el nombre y apellido de cada persona.
Las people variable de Línea 6 arriba se vería así en Python:
people = [
(2, 'Brockman', 'Kent', '2018-08-08 21:16:01.888444'),
(3, 'Easter', 'Bunny', '2018-08-08 21:16:01.889060'),
(1, 'Farrell', 'Doug', '2018-08-08 21:16:01.886834')
]
La salida del programa anterior se ve así:
Kent Brockman
Bunny Easter
Doug Farrell
En el programa anterior, debe saber que el nombre de una persona está en el índice 2 , y el apellido de una persona está en el índice 1 . Peor aún, la estructura interna de person también debe conocerse siempre que pase la variable de iteración person como parámetro de una función o método.
Sería mucho mejor si lo que obtuviste para person era un objeto de Python, donde cada uno de los campos es un atributo del objeto. Esta es una de las cosas que hace SQLAlchemy.
Mesas Little Bobby
En el programa anterior, la instrucción SQL es una cadena simple que se pasa directamente a la base de datos para que se ejecute. En este caso, eso no es un problema porque el SQL es un literal de cadena completamente bajo el control del programa. Sin embargo, el caso de uso de su API REST tomará la entrada del usuario de la aplicación web y la usará para crear consultas SQL. Esto puede abrir su aplicación para atacar.
Recordarás de la Parte 1 que la API REST para obtener una sola person de las PEOPLE los datos se veían así:
GET /api/people/{lname}
Esto significa que su API espera una variable, lname , en la ruta del extremo de la URL, que utiliza para encontrar una sola person . Modificar el código Python SQLite desde arriba para hacer esto se vería así:
1lname = 'Farrell'
2cur.execute('SELECT * FROM person WHERE lname = \'{}\''.format(lname))
El fragmento de código anterior hace lo siguiente:
-
Línea 1 establece el
lnamevariable a'Farrell'. Esto vendría de la ruta del extremo de la URL de la API REST. -
Línea 2 utiliza el formato de cadena de Python para crear una cadena SQL y ejecutarla.
Para simplificar las cosas, el código anterior establece el lname variable a una constante, pero en realidad vendría de la ruta del extremo de la URL de la API y podría ser cualquier cosa proporcionada por el usuario. El SQL generado por el formato de cadena se ve así:
SELECT * FROM person WHERE lname = 'Farrell'
Cuando la base de datos ejecuta este SQL, busca la person tabla para un registro donde el apellido es igual a 'Farrell' . Esto es lo que se pretende, pero cualquier programa que acepte la entrada del usuario también está abierto a usuarios maliciosos. En el programa anterior, donde el lname variable se establece mediante la entrada proporcionada por el usuario, esto abre su programa a lo que se llama un ataque de inyección SQL. Esto es lo que se conoce cariñosamente como Little Bobby Tables:
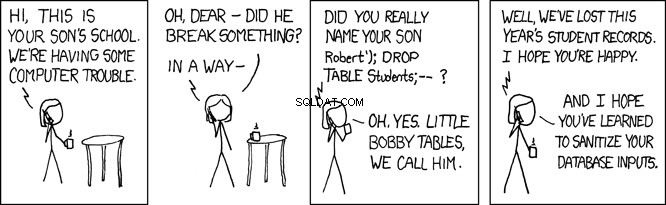
Por ejemplo, imagine que un usuario malicioso llamó a su API REST de esta manera:
GET /api/people/Farrell');DROP TABLE person;
La solicitud de API REST anterior establece el lname variable a 'Farrell');DROP TABLE person;' , que en el código anterior generaría esta instrucción SQL:
SELECT * FROM person WHERE lname = 'Farrell');DROP TABLE person;
La instrucción SQL anterior es válida y, cuando la ejecute la base de datos, encontrará un registro donde lname coincide con 'Farrell' . Luego, encontrará el carácter delimitador de sentencia SQL ; y seguirá adelante y dejará caer toda la tabla. Básicamente, esto arruinaría su aplicación.
Puede proteger su programa desinfectando todos los datos que obtiene de los usuarios de su aplicación. La desinfección de datos en este contexto significa que su programa examine los datos proporcionados por el usuario y se asegure de que no contenga nada peligroso para el programa. Esto puede ser complicado de hacer correctamente y tendría que hacerse en todos los lugares donde los datos del usuario interactúan con la base de datos.
Hay otra manera que es mucho más fácil:use SQLAlchemy. Desinfectará los datos del usuario antes de crear declaraciones SQL. Es otra gran ventaja y razón para usar SQLAlchemy cuando se trabaja con bases de datos.
Modelado de datos con SQLAlchemy
SQLAlchemy es un gran proyecto y proporciona muchas funciones para trabajar con bases de datos usando Python. Una de las cosas que proporciona es un ORM, u Object Relational Mapper, y esto es lo que vas a usar para crear y trabajar con la person. tabla de base de datos Esto le permite asignar una fila de campos de la tabla de la base de datos a un objeto de Python.
La programación orientada a objetos le permite conectar datos junto con el comportamiento, las funciones que operan en esos datos. Al crear clases de SQLAlchemy, puede conectar los campos de las filas de la tabla de la base de datos al comportamiento, lo que le permite interactuar con los datos. Aquí está la definición de la clase SQLAlchemy para los datos en person tabla de base de datos:
class Person(db.Model):
__tablename__ = 'person'
person_id = db.Column(db.Integer,
primary_key=True)
lname = db.Column(db.String)
fname = db.Column(db.String)
timestamp = db.Column(db.DateTime,
default=datetime.utcnow,
onupdate=datetime.utcnow)
La clase Person hereda de db.Model , al que llegará cuando empiece a construir el código del programa. Por ahora, significa que estás heredando de una clase base llamada Model , proporcionando atributos y funcionalidades comunes a todas las clases derivadas de él.
El resto de las definiciones son atributos de nivel de clase definidos de la siguiente manera:
-
__tablename__ = 'person'conecta la definición de clase a lapersontabla de base de datos. -
person_id = db.Column(db.Integer, primary_key=True)crea una columna de base de datos que contiene un número entero que actúa como la clave principal de la tabla. Esto también le dice a la base de datos queperson_idserá un valor entero autoincremental. -
lname = db.Column(db.String)crea el campo de apellido, una columna de la base de datos que contiene un valor de cadena. -
fname = db.Column(db.String)crea el campo de nombre, una columna de base de datos que contiene un valor de cadena. -
timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)crea un campo de marca de tiempo, una columna de base de datos que contiene un valor de fecha/hora. Eldefault=datetime.utcnowel parámetro establece por defecto el valor de la marca de tiempo en elutcnowactual valor cuando se crea un registro. Elonupdate=datetime.utcnowEl parámetro actualiza la marca de tiempo con elutcnowactual valor cuando se actualiza el registro.
Nota:marcas de tiempo UTC
Tal vez se pregunte por qué la marca de tiempo en la clase anterior es predeterminada y es actualizada por datetime.utcnow() que devuelve un UTC o tiempo universal coordinado. Esta es una forma de estandarizar la fuente de su marca de tiempo.
La fuente, o tiempo cero, es una línea que va de norte a sur desde el polo norte al sur de la Tierra a través del Reino Unido. Esta es la zona horaria cero a partir de la cual se compensan todas las demás zonas horarias. Al usar esto como la fuente de tiempo cero, sus marcas de tiempo son compensaciones de este punto de referencia estándar.
Si se accede a su aplicación desde diferentes zonas horarias, tiene una forma de realizar cálculos de fecha/hora. Todo lo que necesita es una marca de tiempo UTC y la zona horaria de destino.
Si tuviera que utilizar las zonas horarias locales como su fuente de marca de tiempo, entonces no podría realizar cálculos de fecha/hora sin información sobre las zonas horarias locales compensadas desde la hora cero. Sin la información de origen de la marca de tiempo, no podría hacer ninguna comparación de fecha/hora o matemáticas en absoluto.
Trabajar con marcas de tiempo basadas en UTC es un buen estándar a seguir. Aquí hay un sitio de herramientas para trabajar y comprenderlos mejor.
¿Hacia dónde te diriges con esta Person? definición de clase? El objetivo final es poder ejecutar una consulta usando SQLAlchemy y obtener una lista de instancias de Person clase. Como ejemplo, veamos la sentencia SQL anterior:
SELECT * FROM people ORDER BY lname;
Muestre el mismo programa de ejemplo pequeño de arriba, pero ahora usando SQLAlchemy:
1from models import Person
2
3people = Person.query.order_by(Person.lname).all()
4for person in people:
5 print(f'{person.fname} {person.lname}')
Ignorando la línea 1 por el momento, lo que quieres es toda la person registros ordenados en orden ascendente por el lname campo. Lo que obtiene de las declaraciones de SQLAlchemy Person.query.order_by(Person.lname).all() es una lista de Person objetos para todos los registros en la person tabla de la base de datos en ese orden. En el programa anterior, las people variable contiene la lista de Person objetos.
El programa itera sobre las people variable, tomando cada person a su vez e imprimiendo el nombre y apellido de la persona de la base de datos. Tenga en cuenta que el programa no tiene que usar índices para obtener el fname o lname valores:utiliza los atributos definidos en la Person objeto.
El uso de SQLAlchemy le permite pensar en términos de objetos con comportamiento en lugar de SQL sin procesar . Esto se vuelve aún más beneficioso cuando las tablas de su base de datos se vuelven más grandes y las interacciones más complejas.
Serializar/Deserializar datos modelados
Trabajar con datos modelados de SQLAlchemy dentro de sus programas es muy conveniente. Es especialmente conveniente en programas que manipulan los datos, tal vez haciendo cálculos o usándolos para crear presentaciones en pantalla. Su aplicación es una API REST que esencialmente proporciona operaciones CRUD en los datos y, como tal, no realiza mucha manipulación de datos.
La API REST funciona con datos JSON, y aquí puede encontrarse con un problema con el modelo SQLAlchemy. Debido a que los datos devueltos por SQLAlchemy son instancias de clase de Python, Connexion no puede serializar estas instancias de clase en datos con formato JSON. Recuerde de la Parte 1 que Connexion es la herramienta que usó para diseñar y configurar la API REST usando un archivo YAML y conectarle métodos de Python.
En este contexto, serializar significa convertir objetos de Python, que pueden contener otros objetos de Python y tipos de datos complejos, en estructuras de datos más simples que se pueden analizar en tipos de datos JSON, que se enumeran aquí:
string: un tipo de cadenanumber: números admitidos por Python (enteros, flotantes, largos)object: un objeto JSON, que es más o menos equivalente a un diccionario de Pythonarray: más o menos equivalente a una lista de Pythonboolean: representado en JSON comotrueofalse, pero en Python comoTrueoFalsenull: esencialmente unNoneen Python
Como ejemplo, su Person La clase contiene una marca de tiempo, que es un Python DateTime . No hay una definición de fecha/hora en JSON, por lo que la marca de tiempo debe convertirse en una cadena para que exista en una estructura JSON.
Tu Person class es lo suficientemente simple, por lo que obtener los atributos de datos de él y crear un diccionario manualmente para regresar desde nuestros puntos finales de URL REST no sería muy difícil. En una aplicación más compleja con muchos modelos SQLAlchemy más grandes, este no sería el caso. Una mejor solución es usar un módulo llamado Marshmallow para que haga el trabajo por ti.
Marshmallow te ayuda a crear un PersonSchema class, que es como SQLAlchemy Person clase que creamos. Aquí, sin embargo, en lugar de asignar tablas de bases de datos y nombres de campos a la clase y sus atributos, el PersonSchema class define cómo se convertirán los atributos de una clase en formatos compatibles con JSON. Aquí está la definición de la clase Marshmallow para los datos en nuestra person tabla:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
La clase PersonSchema hereda de ma.ModelSchema , al que llegará cuando empiece a construir el código del programa. Por ahora, esto significa PersonSchema hereda de una clase base Marshmallow llamada ModelSchema , proporcionando atributos y funcionalidades comunes a todas las clases derivadas de él.
El resto de la definición es la siguiente:
-
class Metadefine una clase llamadaMetadentro de tu clase. ElModelSchemaclase que elPersonSchemala clase hereda de busca esteMetainterno class y lo usa para encontrar el modelo SQLAlchemyPersony eldb.session. Así es como Marshmallow encuentra atributos en laPersonclass y el tipo de esos atributos para que sepa cómo serializarlos/deserializarlos. -
modelle dice a la clase qué modelo de SQLAlchemy usar para serializar/deserializar datos hacia y desde. -
db.sessionle dice a la clase qué sesión de base de datos usar para introspeccionar y determinar los tipos de datos de atributos.
¿Hacia dónde te diriges con esta definición de clase? Desea poder serializar una instancia de una Person class en datos JSON, y para deserializar datos JSON y crear una Person instancias de clase de él.
Crear la base de datos inicializada
SQLAlchemy maneja muchas de las interacciones específicas de bases de datos particulares y le permite concentrarse en los modelos de datos y en cómo usarlos.
Ahora que realmente va a crear una base de datos, como se mencionó anteriormente, usará SQLite. Estás haciendo esto por un par de razones. Viene con Python y no tiene que instalarse como un módulo separado. Guarda toda la información de la base de datos en un solo archivo y, por lo tanto, es fácil de configurar y usar.
La instalación de un servidor de base de datos separado como MySQL o PostgreSQL funcionaría bien, pero requeriría instalar esos sistemas y ponerlos en funcionamiento, lo cual está más allá del alcance de este artículo.
Debido a que SQLAlchemy maneja la base de datos, en muchos sentidos realmente no importa cuál sea la base de datos subyacente.
Vas a crear un nuevo programa de utilidad llamado build_database.py para crear e inicializar SQLite people.db archivo de base de datos que contiene su person tabla de base de datos En el camino, creará dos módulos de Python, config.py y models.py , que será utilizado por build_database.py y el server.py modificado de la Parte 1.
Aquí es donde puede encontrar el código fuente de los módulos que está a punto de crear, que se presentan aquí:
-
config.pyobtiene los módulos necesarios importados en el programa y configurados. Esto incluye Flask, Connexion, SQLAlchemy y Marshmallow. Porque será utilizado por ambosbuild_database.pyyserver.py, algunas partes de la configuración solo se aplicarán aserver.pyaplicación. -
models.pyes el módulo donde creará laPersonSQLAlchemy yPersonSchemaLas definiciones de clase Marshmallow descritas anteriormente. Este módulo depende deconfig.pypara algunos de los objetos creados y configurados allí.
Módulo de configuración
El config.py El módulo, como su nombre lo indica, es donde se crea e inicializa toda la información de configuración. Vamos a usar este módulo tanto para nuestro build_database.py archivo de programa y el próximo a ser actualizado server.py archivo del artículo de la Parte 1. Esto significa que vamos a configurar Flask, Connexion, SQLAlchemy y Marshmallow aquí.
Aunque el build_database.py El programa no utiliza Flask, Connexion o Marshmallow, utiliza SQLAlchemy para crear nuestra conexión a la base de datos SQLite. Aquí está el código para config.py módulo:
1import os
2import connexion
3from flask_sqlalchemy import SQLAlchemy
4from flask_marshmallow import Marshmallow
5
6basedir = os.path.abspath(os.path.dirname(__file__))
7
8# Create the Connexion application instance
9connex_app = connexion.App(__name__, specification_dir=basedir)
10
11# Get the underlying Flask app instance
12app = connex_app.app
13
14# Configure the SQLAlchemy part of the app instance
15app.config['SQLALCHEMY_ECHO'] = True
16app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////' + os.path.join(basedir, 'people.db')
17app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
18
19# Create the SQLAlchemy db instance
20db = SQLAlchemy(app)
21
22# Initialize Marshmallow
23ma = Marshmallow(app)
Esto es lo que hace el código anterior:
-
Líneas 2 – 4 importa Connexion como lo hiciste en
server.pyprograma de la Parte 1. También importaSQLAlchemydelflask_sqlalchemymódulo. Esto le da a su programa acceso a la base de datos. Por último, importaMarshmallowdelflask_marshamllowmódulo. -
Línea 6 crea la variable
basedirapuntando al directorio en el que se está ejecutando el programa. -
Línea 9 utiliza el
basedirvariable para crear la instancia de la aplicación Connexion y darle la ruta aswagger.ymlarchivo. -
Línea 12 crea una variable
app, que es la instancia de Flask inicializada por Connexion. -
Líneas 15 usa la
appvariable para configurar los valores utilizados por SQLAlchemy. Primero estableceSQLALCHEMY_ECHOaTrue. Esto hace que SQLAlchemy haga eco de las declaraciones SQL que ejecuta en la consola. Esto es muy útil para depurar problemas al crear programas de base de datos. Establézcalo enFalsepara entornos de producción. -
Línea 16 establece
SQLALCHEMY_DATABASE_URIasqlite:////' + os.path.join(basedir, 'people.db'). Esto le dice a SQLAlchemy que use SQLite como base de datos y un archivo llamadopeople.dben el directorio actual como el archivo de la base de datos. Diferentes motores de base de datos, como MySQL y PostgreSQL, tendrán diferentesSQLALCHEMY_DATABASE_URIcadenas para configurarlos. -
Línea 17 establece
SQLALCHEMY_TRACK_MODIFICATIONSaFalse, desactivando el sistema de eventos SQLAlchemy, que está activado de forma predeterminada. El sistema de eventos genera eventos útiles en programas controlados por eventos, pero agrega una sobrecarga significativa. Dado que no está creando un programa basado en eventos, desactive esta función. -
Línea 19 crea el
dbvariable llamando aSQLAlchemy(app). Esto inicializa SQLAlchemy pasando laappinformación de configuración recién configurada. Eldbvariable es lo que se importa enbuild_database.pyprograma para darle acceso a SQLAlchemy y la base de datos. Tendrá el mismo propósito enserver.pyprograma ypeople.pymódulo. -
Línea 23 crea el
mavariable llamando aMarshmallow(app). Esto inicializa Marshmallow y le permite realizar una introspección de los componentes de SQLAlchemy adjuntos a la aplicación. Esta es la razón por la que Marshmallow se inicializa después de SQLAlchemy.
Módulo de Modelos
Los models.py se crea el módulo para proporcionar la Person y PersonSchema clases exactamente como se describe en las secciones anteriores sobre el modelado y la serialización de los datos. Aquí está el código para ese módulo:
1from datetime import datetime
2from config import db, ma
3
4class Person(db.Model):
5 __tablename__ = 'person'
6 person_id = db.Column(db.Integer, primary_key=True)
7 lname = db.Column(db.String(32), index=True)
8 fname = db.Column(db.String(32))
9 timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
10
11class PersonSchema(ma.ModelSchema):
12 class Meta:
13 model = Person
14 sqla_session = db.session
Esto es lo que hace el código anterior:
-
Línea 1 importa el
datetimeobjeto deldatetimemódulo que viene con Python. Esto le brinda una forma de crear una marca de tiempo en laPersonclase. -
Línea 2 importa el
dbymavariables de instancia definidas enconfig.pymódulo. Esto le da al módulo acceso a los atributos y métodos SQLAlchemy adjuntos aldby los atributos y métodos de Marshmallow adjuntos almavariables. -
Líneas 4 a 9 definir la
Personclase como se discutió en la sección de modelado de datos anterior, pero ahora sabe dónde está eldb.Modelque la clase hereda de origina. Esto le da a laPersonfunciones de clase SQLAlchemy, como una conexión a la base de datos y acceso a sus tablas. -
Líneas 11 a 14 definir el
PersonSchemaclass como se discutió en la sección de serialización de datos anterior. Esta clase hereda dema.ModelSchemay da elPersonSchemaclass Marshmallow features, like introspecting thePersonclass to help serialize/deserialize instances of that class.
Creating the Database
You’ve seen how database tables can be mapped to SQLAlchemy classes. Now use what you’ve learned to create the database and populate it with data. You’re going to build a small utility program to create and build the database with the People datos. Here’s the build_database.py program:
1import os
2from config import db
3from models import Person
4
5# Data to initialize database with
6PEOPLE = [
7 {'fname': 'Doug', 'lname': 'Farrell'},
8 {'fname': 'Kent', 'lname': 'Brockman'},
9 {'fname': 'Bunny','lname': 'Easter'}
10]
11
12# Delete database file if it exists currently
13if os.path.exists('people.db'):
14 os.remove('people.db')
15
16# Create the database
17db.create_all()
18
19# Iterate over the PEOPLE structure and populate the database
20for person in PEOPLE:
21 p = Person(lname=person['lname'], fname=person['fname'])
22 db.session.add(p)
23
24db.session.commit()
Here’s what the above code is doing:
-
Line 2 imports the
dbinstance from theconfig.pymódulo. -
Line 3 imports the
Personclass definition from themodels.pymódulo. -
Lines 6 – 10 create the
PEOPLEdata structure, which is a list of dictionaries containing your data. The structure has been condensed to save presentation space. -
Lines 13 &14 perform some simple housekeeping to delete the
people.dbfile, if it exists. This file is where the SQLite database is maintained. If you ever have to re-initialize the database to get a clean start, this makes sure you’re starting from scratch when you build the database. -
Line 17 creates the database with the
db.create_all()llamar. This creates the database by using thedbinstance imported from theconfigmódulo. Thedbinstance is our connection to the database. -
Lines 20 – 22 iterate over the
PEOPLElist and use the dictionaries within to instantiate aPersonclase. After it is instantiated, you call thedb.session.add(p)función. This uses the database connection instancedbto access thesessionobjeto. The session is what manages the database actions, which are recorded in the session. In this case, you are executing theadd(p)method to add the newPersoninstance to thesessionobjeto. -
Line 24 calls
db.session.commit()to actually save all the person objects created to the database.
session objeto. Only when you execute the db.session.commit() call at Line 24 does the session interact with the database and commit the actions to it.
In SQLAlchemy, the session is an important object. It acts as the conduit between the database and the SQLAlchemy Python objects created in a program. The session helps maintain the consistency between data in the program and the same data as it exists in the database. It saves all database actions and will update the underlying database accordingly by both explicit and implicit actions taken by the program.
Now you’re ready to run the build_database.py program to create and initialize the new database. You do so with the following command, with your Python virtual environment active:
python build_database.py
When the program runs, it will print SQLAlchemy log messages to the console. These are the result of setting SQLALCHEMY_ECHO to True in the config.py expediente. Much of what’s being logged by SQLAlchemy is the SQL commands it’s generating to create and build the people.db SQLite database file. Here’s an example of what’s printed out when the program is run:
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("person")
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine
CREATE TABLE person (
person_id INTEGER NOT NULL,
lname VARCHAR,
fname VARCHAR,
timestamp DATETIME,
PRIMARY KEY (person_id)
)
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,975 INFO sqlalchemy.engine.base.Engine COMMIT
2018-09-11 22:20:29,980 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine ('Farrell', 'Doug', '2018-09-12 02:20:29.983143')
2018-09-11 22:20:29,984 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Brockman', 'Kent', '2018-09-12 02:20:29.984821')
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Easter', 'Bunny', '2018-09-12 02:20:29.985462')
2018-09-11 22:20:29,986 INFO sqlalchemy.engine.base.Engine COMMIT
Using the Database
Once the database has been created, you can modify the existing code from Part 1 to make use of it. All of the modifications necessary are due to creating the person_id primary key value in our database as the unique identifier rather than the lname valor.
Update the REST API
None of the changes are very dramatic, and you’ll start by re-defining the REST API. The list below shows the API definition from Part 1 but is updated to use the person_id variable in the URL path:
| Action | HTTP Verb | URL Path | Descripción |
|---|---|---|---|
| Create | POST | /api/people | Defines a unique URL to create a new person |
| Read | GET | /api/people | Defines a unique URL to read a collection of people |
| Read | GET | /api/people/{person_id} | Defines a unique URL to read a particular person by person_id |
| Update | PUT | /api/people/{person_id} | Defines a unique URL to update an existing person by person_id |
| Delete | DELETE | /api/orders/{person_id} | Defines a unique URL to delete an existing person by person_id |
Where the URL definitions required an lname value, they now require the person_id (primary key) for the person record in the people mesa. This allows you to remove the code in the previous app that artificially restricted users from editing a person’s last name.
In order for you to implement these changes, the swagger.yml file from Part 1 will have to be edited. For the most part, any lname parameter value will be changed to person_id , and person_id will be added to the POST and PUT responses. You can check out the updated swagger.yml archivo.
Update the REST API Handlers
With the swagger.yml file updated to support the use of the person_id identifier, you’ll also need to update the handlers in the people.py file to support these changes. In the same way that the swagger.yml file was updated, you need to change the people.py file to use the person_id value rather than lname .
Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people :
1from flask import (
2 make_response,
3 abort,
4)
5from config import db
6from models import (
7 Person,
8 PersonSchema,
9)
10
11def read_all():
12 """
13 This function responds to a request for /api/people
14 with the complete lists of people
15
16 :return: json string of list of people
17 """
18 # Create the list of people from our data
19 people = Person.query \
20 .order_by(Person.lname) \
21 .all()
22
23 # Serialize the data for the response
24 person_schema = PersonSchema(many=True)
25 return person_schema.dump(people).data
Here’s what the above code is doing:
-
Lines 1 – 9 import some Flask modules to create the REST API responses, as well as importing the
dbinstance from theconfig.pymódulo. In addition, it imports the SQLAlchemyPersonand MarshmallowPersonSchemaclasses to access thepersondatabase table and serialize the results. -
Line 11 starts the definition of
read_all()that responds to the REST API URL endpointGET /api/peopleand returns all the records in thepersondatabase table sorted in ascending order by last name. -
Lines 19 – 22 tell SQLAlchemy to query the
persondatabase table for all the records, sort them in ascending order (the default sorting order), and return a list ofPersonPython objects as the variablepeople. -
Line 24 is where the Marshmallow
PersonSchemaclass definition becomes valuable. You create an instance of thePersonSchema, passing it the parametermany=True. This tellsPersonSchemato expect an interable to serialize, which is what thepeoplevariable is. -
Line 25 uses the
PersonSchemainstance variable (person_schema), calling itsdump()method with thepeoplelista. The result is an object having adataattribute, an object containing apeoplelist that can be converted to JSON. This is returned and converted by Connexion to JSON as the response to the REST API call.
people list variable created on Line 24 above can’t be returned directly because Connexion won’t know how to convert the timestamp field into JSON. Returning the list of people without processing it with Marshmallow results in a long error traceback and finally this Exception:
TypeError: Object of type Person is not JSON serializable
Here’s another part of the person.py module that makes a request for a single person from the person base de datos. Here, read_one(person_id) function receives a person_id from the REST URL path, indicating the user is looking for a specific person. Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people/{person_id} :
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: ID of person to find
7 :return: person matching ID
8 """
9 # Get the person requested
10 person = Person.query \
11 .filter(Person.person_id == person_id) \
12 .one_or_none()
13
14 # Did we find a person?
15 if person is not None:
16
17 # Serialize the data for the response
18 person_schema = PersonSchema()
19 return person_schema.dump(person).data
20
21 # Otherwise, nope, didn't find that person
22 else:
23 abort(404, 'Person not found for Id: {person_id}'.format(person_id=person_id))
Here’s what the above code is doing:
-
Lines 10 – 12 use the
person_idparameter in a SQLAlchemy query using thefiltermethod of the query object to search for a person with aperson_idattribute matching the passed-inperson_id. Rather than using theall()query method, use theone_or_none()method to get one person, or returnNoneif no match is found. -
Line 15 determines whether a
personwas found or not. -
Line 17 shows that, if
personwas notNone(a matchingpersonwas found), then serializing the data is a little different. You don’t pass themany=Trueparameter to the creation of thePersonSchema()instance. Instead, you passmany=Falsebecause only a single object is passed in to serialize. -
Line 18 is where the
dumpmethod ofperson_schemais called, and thedataattribute of the resulting object is returned. -
Line 23 shows that, if
personwasNone(a matching person wasn’t found), then the Flaskabort()method is called to return an error.
Another modification to person.py is creating a new person in the database. This gives you an opportunity to use the Marshmallow PersonSchema to deserialize a JSON structure sent with the HTTP request to create a SQLAlchemy Person objeto. Here’s part of the updated person.py module showing the handler for the REST URL endpoint POST /api/people :
1def create(person):
2 """
3 This function creates a new person in the people structure
4 based on the passed-in person data
5
6 :param person: person to create in people structure
7 :return: 201 on success, 406 on person exists
8 """
9 fname = person.get('fname')
10 lname = person.get('lname')
11
12 existing_person = Person.query \
13 .filter(Person.fname == fname) \
14 .filter(Person.lname == lname) \
15 .one_or_none()
16
17 # Can we insert this person?
18 if existing_person is None:
19
20 # Create a person instance using the schema and the passed-in person
21 schema = PersonSchema()
22 new_person = schema.load(person, session=db.session).data
23
24 # Add the person to the database
25 db.session.add(new_person)
26 db.session.commit()
27
28 # Serialize and return the newly created person in the response
29 return schema.dump(new_person).data, 201
30
31 # Otherwise, nope, person exists already
32 else:
33 abort(409, f'Person {fname} {lname} exists already')
Here’s what the above code is doing:
-
Line 9 &10 set the
fnameandlnamevariables based on thePersondata structure sent as thePOSTbody of the HTTP request. -
Lines 12 – 15 use the SQLAlchemy
Personclass to query the database for the existence of a person with the samefnameandlnameas the passed-inperson. -
Line 18 addresses whether
existing_personesNone. (existing_personwas not found.) -
Line 21 creates a
PersonSchema()instance calledschema. -
Line 22 uses the
schemavariable to load the data contained in thepersonparameter variable and create a new SQLAlchemyPersoninstance variable callednew_person. -
Line 25 adds the
new_personinstance to thedb.session. -
Line 26 commits the
new_personinstance to the database, which also assigns it a new primary key value (based on the auto-incrementing integer) and a UTC-based timestamp. -
Line 33 shows that, if
existing_personis notNone(a matching person was found), then the Flaskabort()method is called to return an error.
Update the Swagger UI
With the above changes in place, your REST API is now functional. The changes you’ve made are also reflected in an updated swagger UI interface and can be interacted with in the same manner. Below is a screenshot of the updated swagger UI opened to the GET /people/{person_id} sección. This section of the UI gets a single person from the database and looks like this:
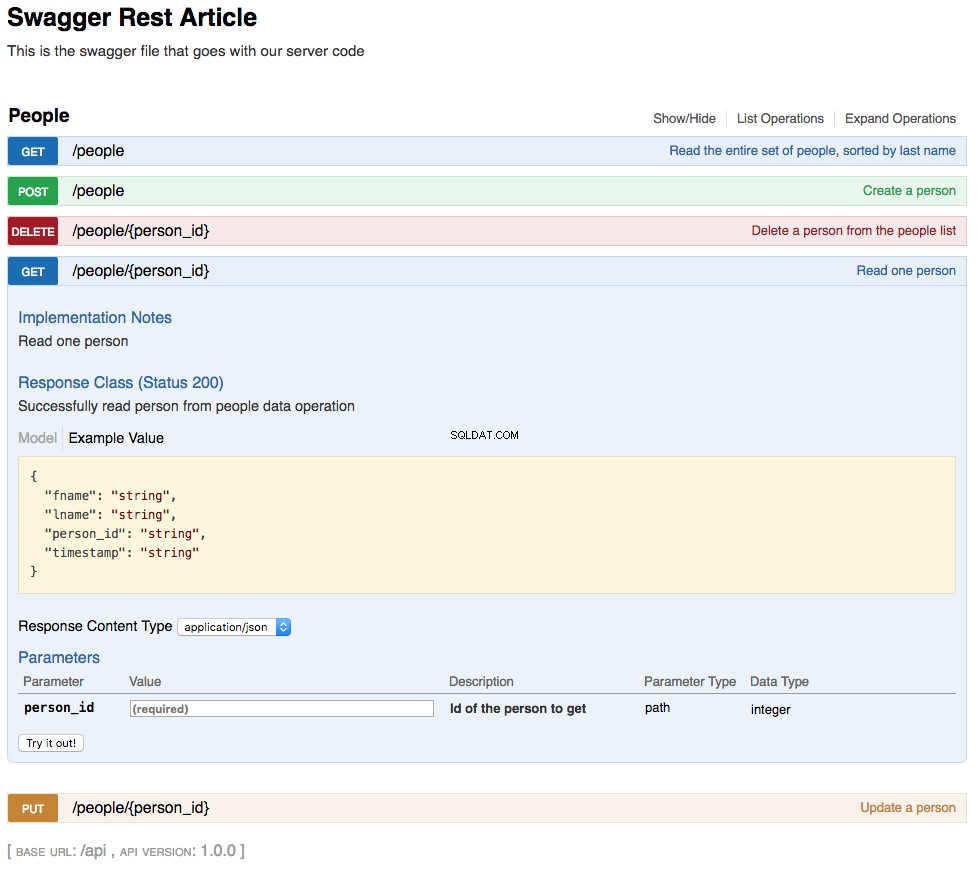
As shown in the above screenshot, the path parameter lname has been replaced by person_id , which is the primary key for a person in the REST API. The changes to the UI are a combined result of changing the swagger.yml file and the code changes made to support that.
Update the Web Application
The REST API is running, and CRUD operations are being persisted to the database. So that it is possible to view the demonstration web application, the JavaScript code has to be updated.
The updates are again related to using person_id instead of lname as the primary key for person data. In addition, the person_id is attached to the rows of the display table as HTML data attributes named data-person-id , so the value can be retrieved and used by the JavaScript code.
This article focused on the database and making your REST API use it, which is why there’s just a link to the updated JavaScript source and not much discussion of what it does.
Example Code
All of the example code for this article is available here. There’s one version of the code containing all the files, including the build_database.py utility program and the server.py modified example program from Part 1.
Conclusión
Congratulations, you’ve covered a lot of new material in this article and added useful tools to your arsenal!
You’ve learned how to save Python objects to a database using SQLAlchemy. You’ve also learned how to use Marshmallow to serialize and deserialize SQLAlchemy objects and use them with a JSON REST API. The things you’ve learned have certainly been a step up in complexity from the simple REST API of Part 1, but that step has given you two very powerful tools to use when creating more complex applications.
SQLAlchemy and Marshmallow are amazing tools in their own right. Using them together gives you a great leg up to create your own web applications backed by a database.
In Part 3 of this series, you’ll focus on the R part of RDBMS :relationships, which provide even more power when you are using a database.