Los índices son aceleradores de velocidad en las bases de datos SQL. Pueden estar agrupados o no agrupados. Pero, ¿qué significa y dónde debe aplicar cada uno?
Sé como te sientes. He estado allí. Los novatos a menudo se confunden acerca de qué índice usar en qué columnas. Sin embargo, incluso los expertos deben pensar en este tema antes de tomar una decisión, y diferentes situaciones requieren decisiones diferentes. Como verá más adelante, hay consultas en las que un índice agrupado brillará en comparación con un índice no agrupado y viceversa.
Aún así, primero, tenemos que conocer cada uno de ellos. Si buscas la misma información, hoy es tu día de suerte.
Este artículo le dirá cuáles son estos índices y cuándo usar cada uno. Por supuesto, habrá ejemplos de código para que los pruebe en la práctica. Entonces, tome sus papas fritas o pizza y un refresco o café, y prepárese para sumergirse en este viaje revelador.
¿Listo?
¿Qué es el índice agrupado?
Un índice agrupado es un índice que define el orden de clasificación físico de las filas en una tabla o vista.
Para ver esto en forma real, tomemos el Empleado tabla en AdventureWorks2017 base de datos.
La clave principal también es un índice agrupado y la clave se basa en el BusinessEntityID columna. Cuando haga una SELECCIÓN en esta tabla sin un ORDEN POR, verá que está ordenada por la clave principal.
Pruébelo usted mismo usando el siguiente código:
USE AdventureWorks2017
GO
SELECT TOP 10 * FROM HumanResources.Employee
GO
Ahora, vea el resultado en la Figura 1:
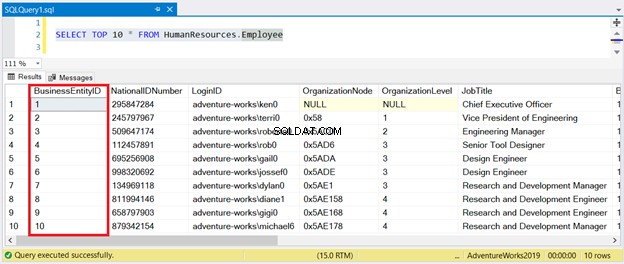
Como puede ver, no necesita ordenar el conjunto de resultados con BusinessEntityID . El índice agrupado se encarga de eso.
A diferencia de los índices no agrupados, solo puede tener 1 índice agrupado por tabla. ¿Qué pasa si probamos esto en el Empleado? mesa?
CREATE CLUSTERED INDEX IX_Employee_NationalID
ON HumanResources.Employee (NationalIDNumber)
GO
Tenemos un error similar a continuación:
Msg 1902, Level 16, State 3, Line 4
Cannot create more than one clustered index on table 'HumanResources.Employee'. Drop the existing clustered index 'PK_Employee_BusinessEntityID' before creating another.
¿Cuándo usar un índice agrupado?
Una columna es el mejor candidato para un índice agrupado si se cumple una de las siguientes condiciones:
- Se usa en un gran número de consultas en la cláusula WHERE y se une.
- Se usará como clave externa para otra tabla y, en última instancia, para uniones.
- Valores de columna únicos.
- Es menos probable que el valor cambie.
- Esa columna se usa para consultar un rango de valores. Los operadores como>, <,>=, <=o BETWEEN se utilizan con la columna en la cláusula WHERE.
Pero los índices agrupados no son buenos si la columna o columnas
- cambiar con frecuencia
- son claves anchas o una combinación de columnas con un tamaño de clave grande.
Ejemplos
Los índices agrupados se pueden crear utilizando código T-SQL o cualquier herramienta GUI de SQL Server. Puede hacerlo en T-SQL al crear la tabla, así:
CREATE TABLE [Person].[Person](
[BusinessEntityID] [int] NOT NULL,
[PersonType] [nchar](2) NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL,
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailPromotion] [int] NOT NULL,
[AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL,
[Demographics] [xml](CONTENT [Person].[IndividualSurveySchemaCollection]) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED
(
[BusinessEntityID] ASC
)
GO
O bien, puede hacerlo usando ALTER TABLE después de creando la tabla sin un índice agrupado:
ALTER TABLE Person.Person ADD CONSTRAINT [PK_Person_BusinessEntityID] PRIMARY KEY CLUSTERED (BusinessEntityID)
GO
Otra forma es usando CREAR ÍNDICE CLUSTERADO:
CREATE CLUSTERED INDEX [PK_Person_BusinessEntityID] ON Person.Person (BusinessEntityID)
GO
Una alternativa más es usar una herramienta de SQL Server como SQL Server Management Studio o dbForge Studio para SQL Server.
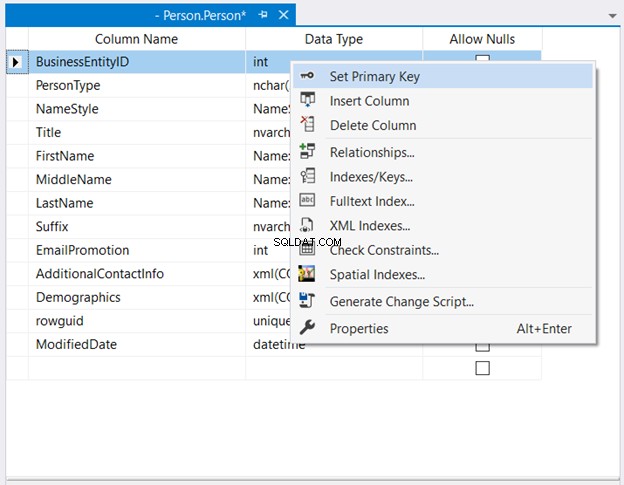
En Explorador de objetos , expanda los nodos de la base de datos y la tabla. Luego, haga clic derecho en la tabla deseada y seleccione Diseño . Finalmente, haga clic con el botón derecho en la columna que desea que sea la clave principal> Establecer clave principal> Guarde los cambios en la tabla.
La figura 2 a continuación muestra dónde BusinessEntityID se establece como la clave principal.
Además de crear un índice agrupado de una sola columna, puede usar varias columnas. Vea un ejemplo en T-SQL:
CREATE CLUSTERED INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person]
(
[LastName] ASC,
[FirstName] ASC,
[MiddleName] ASC
)
GO
Después de crear este índice agrupado, la Persona la tabla se ordenará físicamente por Apellido , Nombre y Segundo Nombre .
Una de las ventajas de este enfoque es el rendimiento mejorado de las consultas basadas en el nombre. Además, ordena los resultados por nombre sin especificar ORDER BY. Pero tenga en cuenta que si el nombre cambia, la tabla deberá reorganizarse. Aunque esto no sucederá todos los días, el impacto puede ser enorme si la tabla es muy grande.
Qué es el índice no agrupado
Un índice no agrupado es un índice con una clave y un puntero a las filas o las claves del índice agrupado. Este índice puede aplicarse tanto a tablas como a vistas.
A diferencia de los índices agrupados, aquí la estructura está separada de la tabla. Como está separado, necesita un puntero a las filas de la tabla, también llamado localizador de filas. Por lo tanto, cada entrada en un índice no agrupado contiene un localizador y un valor clave.
Los índices no agrupados no ordenan físicamente la tabla en función de la clave.
Las claves de índice para índices no agrupados tienen un tamaño máximo de 1700 bytes. Puede omitir este límite agregando columnas incluidas. Este método es bueno si su consulta necesita cubrir más columnas sin aumentar el tamaño de la clave.
También puede crear índices no agrupados filtrados. Esto reducirá el costo de mantenimiento y almacenamiento del índice y mejorará el rendimiento de las consultas.
¿Cuándo usar un índice no agrupado?
Una columna o columnas son buenas candidatas para índices no agrupados si se cumple lo siguiente:
- La columna o columnas se utilizan en una cláusula WHERE o unión.
- La consulta no devolverá un gran conjunto de resultados.
- Se necesita la coincidencia exacta en la cláusula WHERE usando el operador de igualdad.
Ejemplos
Este comando creará un índice único no agrupado en el Empleado tabla:
CREATE UNIQUE NONCLUSTERED INDEX [AK_Employee_NationalIDNumber] ON [HumanResources].[Employee]
(
[NationalIDNumber] ASC
)
GO
Además de una tabla, puede crear un índice no agrupado para una vista:
CREATE NONCLUSTERED INDEX [IDX_vProductAndDescription_ProductModel] ON [Production].[vProductAndDescription]
(
[ProductModel] ASC
)
GO
Otras preguntas comunes y respuestas satisfactorias
¿Cuáles son las diferencias entre el índice agrupado y no agrupado?
Por lo que vio anteriormente, ya puede formarse ideas sobre cómo son los diferentes índices agrupados y no agrupados. Pero pongámoslo en una mesa para una fácil referencia.
| Información | Índice agrupado | Índice no agrupado |
| Se aplica a | Tablas y vistas | Tablas y vistas |
| Permitido por tabla | 1 | 999 |
| Tamaño de clave | 900 bytes | 1700 bytes |
| Columnas por clave de índice | 32 | 32 |
| Bueno para | Consultas de rango (>,<,>=, <=, ENTRE) | Coincidencias exactas (=) |
| Columnas sin clave incluida | No permitido | Permitido |
| Filtrar con condición | No permitido | Permitido |
¿Deberían las claves primarias ser un índice agrupado o no agrupado?
Una clave principal es una restricción. Una vez que convierte una columna en una clave principal, se crea automáticamente un índice agrupado a partir de ella, a menos que ya exista un índice agrupado.
¡No confunda una clave principal con un índice agrupado! Una clave principal también puede ser la clave de índice agrupado. Pero una clave de índice agrupado puede ser otra columna que no sea la clave principal.
Tomemos otro ejemplo. En la Persona tabla de AdventureWorks201 7, tenemos el BusinessEntityID Clave primaria. También es la clave de índice agrupado. Puede eliminar ese índice agrupado. Luego, cree un índice agrupado basado en Lastname , Nombre y segundo nombre . La clave principal sigue siendo BusinessEntityID columna.
Pero, ¿sus claves principales siempre deben estar agrupadas?
Depende. Vuelva a consultar la pregunta sobre cuándo usar un índice agrupado.
Si una columna o columnas aparecen en su cláusula WHERE en muchas consultas, esta es una candidata para un índice agrupado. Pero otra consideración es qué tan ancha es la clave del índice agrupado. Demasiado ancho, y el tamaño de cada índice no agrupado aumentará si existen. Recuerde que los índices no agrupados también usan la clave de índice agrupado como puntero. Por lo tanto, mantenga su clave de índice agrupado lo más estrecha posible.
Si una gran cantidad de consultas utilizan la clave principal en la cláusula WHERE, déjela también como clave de índice agrupado. De lo contrario, cree su clave principal como un índice no agrupado.
Pero, ¿y si aún no estás seguro? Luego, puede evaluar el beneficio de rendimiento de una columna cuando está agrupada o no agrupada. Por lo tanto, sintonice la siguiente sección al respecto.
¿Cuál es más rápido:índice agrupado o no agrupado?
Buena pregunta. No hay una regla general. Debe verificar las lecturas lógicas y el plan de ejecución de sus consultas.
Nuestro breve experimento incluirá copias de las siguientes tablas de AdventureWorks2017 base de datos:
- Persona
- Dirección de entidad comercial
- Dirección
- Tipo de dirección
Aquí está el guión:
IF NOT EXISTS(SELECT name FROM sys.databases WHERE name = 'TestDatabase')
BEGIN
CREATE DATABASE TestDatabase
END
USE TestDatabase
GO
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkClustered FROM AdventureWorks2017.Person.Person
ALTER TABLE Person_pkClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID2] PRIMARY KEY CLUSTERED (BusinessEntityID)
CREATE NONCLUSTERED INDEX [IX_Person_Name2] ON Person_pkClustered (LastName, FirstName, MiddleName, Suffix)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Person_pkNonClustered')
BEGIN
SELECT
BusinessEntityID
,LastName
,FirstName
,MiddleName
,Suffix
,PersonType
,Title
INTO Person_pkNonClustered FROM AdventureWorks2017.Person.Person
CREATE CLUSTERED INDEX [IX_Person_Name1] ON Person_pkNonClustered (LastName, FirstName, MiddleName, Suffix)
ALTER TABLE Person_pkNonClustered
ADD CONSTRAINT [PK_Person_BusinessEntityID1] PRIMARY KEY NONCLUSTERED (BusinessEntityID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'AddressType')
BEGIN
SELECT * INTO AddressType FROM AdventureWorks2017.Person.AddressType
ALTER TABLE AddressType
ADD CONSTRAINT [PK_AddressType] PRIMARY KEY CLUSTERED (AddressTypeID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'Address')
BEGIN
SELECT * INTO Address FROM AdventureWorks2017.Person.Address
ALTER TABLE Address
ADD CONSTRAINT [PK_Address] PRIMARY KEY CLUSTERED (AddressID)
END
IF NOT EXISTS(SELECT name FROM sys.tables WHERE name = 'BusinessEntityAddress')
BEGIN
SELECT * INTO BusinessEntityAddress FROM AdventureWorks2017.Person.BusinessEntityAddress
ALTER TABLE BusinessEntityAddress
ADD CONSTRAINT [PK_BusinessEntityAddress] PRIMARY KEY CLUSTERED (BusinessEntityID, AddressID, AddressTypeID)
END
GO
Usando la estructura anterior, compararemos las velocidades de consulta para índices agrupados y no agrupados.
Tenemos 2 copias de la Persona mesa. El primero utilizará BusinessEntityID como clave de índice principal y agrupada. El segundo todavía usa BusinessEntityID como clave principal. El índice agrupado se basa en Lastname , Nombre , Segundo nombre y Sufijo .
Comencemos.
CONSULTAR COINCIDENCIAS EXACTAS BASADAS EN EL APELLIDO
Primero, hagamos una consulta simple. Además, debe activar STATISTICS IO. Luego, pegamos los resultados en statisticsparser.com para una presentación tabular.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, p.Title
FROM Person_pkClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.LastName = 'Martinez' OR p.LastName = 'Smith'
SET STATISTICS IO OFF
GO
La expectativa es que el primer SELECT será más lento porque la cláusula WHERE no coincide con la clave del índice agrupado. Pero revisemos las lecturas lógicas.
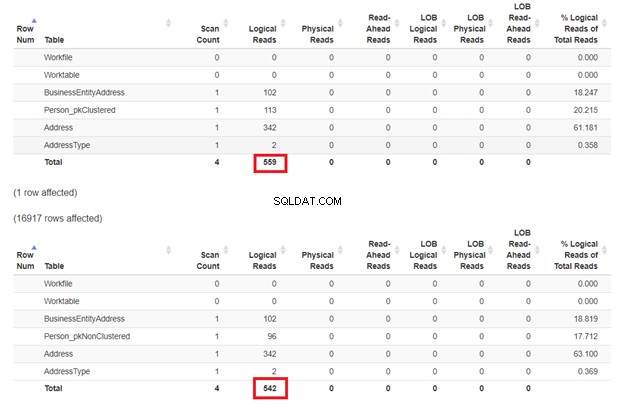
Como se esperaba en la Figura 3, Person_pkClustered tenía más lecturas lógicas. Por lo tanto, la consulta necesita más E/S. ¿La razón? La tabla está ordenada por BusinessEntityID . Sin embargo, la segunda tabla tiene el índice agrupado basado en el nombre. Dado que la consulta quiere un resultado basado en el nombre, Person_pkNonClustered gana Cuantas menos lecturas lógicas, más rápida será la consulta.
¿Qué más está pasando? Mira la Figura 4.
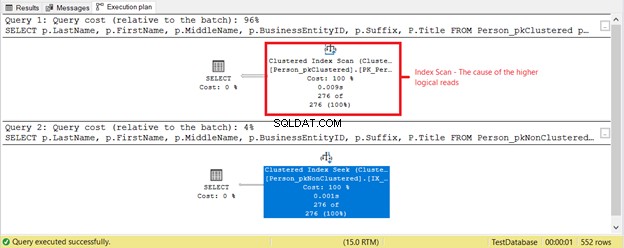
Algo más sucedió según el plan de ejecución de la Figura 4. ¿Por qué un escaneo de índice agrupado está en la primera SELECCIÓN en lugar de una búsqueda de índice? El culpable es el Título columna en SELECCIONAR. No está cubierto por ninguno de los índices existentes. El optimizador de SQL Server consideró más rápido usar el índice agrupado basado en BusinessEntityID. Luego, SQL Server lo escaneó en busca de los apellidos correctos y obtuvo el primer nombre, el segundo nombre y el título.
Eliminar el Título columna, y el operador utilizado será Buscar índice . ¿Por qué? Porque el resto de los campos están cubiertos por el índice no agrupado basado en Lastname , Nombre , Segundo nombre y Sufijo . También incluye BusinessEntityID como el localizador de clave de índice agrupado.
CONSULTA DE RANGO BASADA EN ID DE ENTIDAD COMERCIAL
Los índices agrupados pueden ser buenos para consultas de rango. ¿Es ese siempre el caso? Averigüémoslo usando el siguiente código.
SET STATISTICS IO ON
GO
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SELECT p.LastName, p.FirstName, p.MiddleName, p.BusinessEntityID, p.Suffix, P.Title
FROM Person_pkNonClustered p
WHERE p.BusinessEntityID >= 285 AND p.BusinessEntityID <= 290
SET STATISTICS IO OFF
GO
La lista necesita filas basadas en un rango de BusinessEntityIDs de 285 a 290. Nuevamente, los índices agrupados y no agrupados de las 2 tablas están intactos. Ahora, tengamos las lecturas lógicas en la Figura 5. El ganador esperado es Person_pkClustered porque la clave principal es también la clave del índice agrupado.

¿Ves lecturas lógicas más bajas en Person_pkClustered? ? Los índices agrupados demostraron su valor en las consultas de rango en este escenario. Veamos qué más revelará el plan de ejecución en la Figura 6.
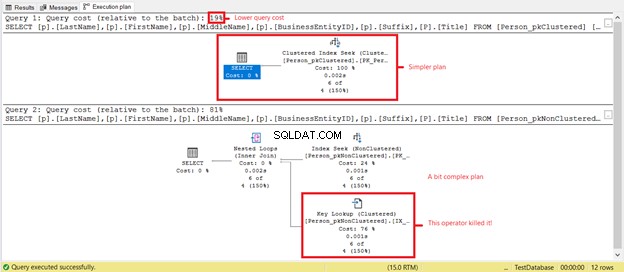
El primer SELECT tiene un plan más simple y un costo de consulta más bajo según la Figura 7. Esto también admite lecturas lógicas más bajas. Mientras tanto, el segundo SELECT tiene un operador Key Lookup que ralentiza la consulta. ¿El culpable? De nuevo, es el Título columna. Quite la columna de la consulta o agréguela como columna incluida en el índice no agrupado. Entonces, tendrá un mejor plan y menos lecturas lógicas.
CONSULTAR COINCIDENCIAS EXACTAS CON UNA UNIÓN
Muchas sentencias SELECT incluyen uniones. Hagamos algunas pruebas. Aquí comenzamos con coincidencias exactas:
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE P.LastName = 'Martinez'
SET STATISTICS IO OFF
GO
Esperamos que el segundo SELECT de Person_pkNonClustered con un índice agrupado en el nombre tendrá menos lecturas lógicas. ¿Pero es? Consulte la figura 7.
Parece que el índice no agrupado en el nombre funcionó bien. Las lecturas lógicas son las mismas. Si marca el plan de ejecución, la diferencia en los operadores es la búsqueda de índice agrupado en Person_pkNonClustered y la búsqueda de índice en Person_pkClustered .
Por lo tanto, debemos verificar las lecturas lógicas y el plan de ejecución para estar seguros.
CONSULTA DE RANGO CON UNIONES
Dado que nuestras expectativas pueden ser diferentes de la realidad, probemos con consultas de rango. Los índices agrupados son generalmente buenos con él. Pero, ¿y si incluyes una unión?
SET STATISTICS IO ON
GO
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SELECT
p.BusinessEntityID
,P.LastName
,P.FirstName
,P.MiddleName
,P.Suffix
,a.AddressLine1
,a.AddressLine2
,a.City
,a2.Name
FROM Person_pkNonClustered p
INNER JOIN BusinessEntityAddress bea ON P.BusinessEntityID = bea.BusinessEntityID
INNER JOIN Address a ON bea.AddressID = a.AddressID
INNER JOIN AddressType a2 ON bea.AddressTypeID = a2.AddressTypeID
WHERE p.BusinessEntityID BETWEEN 100 AND 19000
SET STATISTICS IO OFF
GO
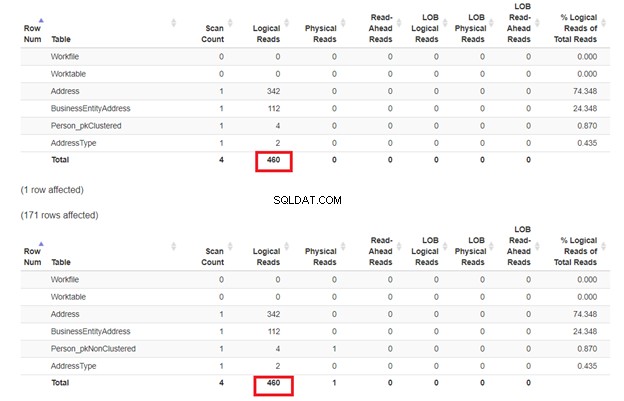
Ahora, inspeccione las lecturas lógicas de estas 2 consultas en la Figura 8:
¿Qué ha pasado? En la Figura 9, la realidad muerde a Person_pkClustered . Se observó un mayor costo de E/S en comparación con Person_pkNonClustered . Eso es diferente de lo que esperamos. Pero según la respuesta de este foro, una búsqueda de índice no agrupado puede ser más rápida que la búsqueda de índice agrupado cuando todas las columnas de la consulta están cubiertas al 100 % en el índice. En nuestro caso, la consulta de Person_pkNonClustered cubrió las columnas usando el índice no agrupado (BusinessEntityID - llave; Apellido , Nombre , Segundo nombre , Sufijo – puntero a clave de índice agrupado).
INSERTAR RENDIMIENTO
Luego, intente probar el rendimiento de INSERT en las mismas tablas.
SET STATISTICS IO ON
GO
INSERT INTO Person_pkClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
INSERT INTO Person_pkNonClustered
(BusinessEntityID, LastName, FirstName, MiddleName, Suffix, PersonType, Title)
VALUES (20778, 'Sanchez','Edwin', 'Ilaya', NULL, N'SC', N'Mr.'),
(20779, 'Galilei','Galileo', '', NULL, N'SC', N'Mr.');
SET STATISTICS IO OFF
GO
La Figura 9 muestra las lecturas lógicas INSERT:

Ambos generaron la misma E/S. Por lo tanto, ambos realizaron lo mismo.
ELIMINAR RENDIMIENTO
Nuestra última prueba consiste en ELIMINAR:
SET STATISTICS IO ON
GO
DELETE FROM Person_pkClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
DELETE FROM Person_pkNonClustered
WHERE LastName='Sanchez'
AND FirstName = 'Edwin'
SET STATISTICS IO OFF
GO
La figura 10 muestra las lecturas lógicas. Note la diferencia.

¿Por qué tenemos lecturas lógicas más altas en Person_pkClustered? ? La cuestión es que la condición de la declaración DELETE se basa en una coincidencia exacta de un nombre. El optimizador tendrá que recurrir primero al índice no agrupado. Significa más E/S. Confirmemos usando el plan de ejecución en la Figura 11.
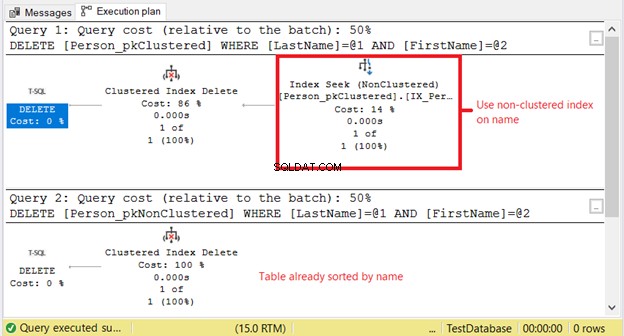
El primer SELECT necesita una búsqueda de índice en el índice no agrupado. El motivo es la cláusula WHERE en Lastname y Nombre . Mientras tanto, Person_pkNonClustered ya está ordenado físicamente por nombre debido al índice agrupado.
Puntos para llevar
Formar consultas de alto rendimiento no se trata de suerte. No puede simplemente poner un índice agrupado y no agrupado y luego, de repente, sus consultas tienen la fuerza de la velocidad. Debe seguir usando las herramientas como su lente para enfocarse en los pequeños detalles que no sean el conjunto de resultados.
Pero a veces simplemente no tienes tiempo para hacer todo esto. Creo que eso es normal. Pero mientras no te equivoques tanto, tienes tu trabajo al día siguiente y puedes resolverlo. Esto no será fácil al principio. En realidad será confuso. También tendrás muchas preguntas. Pero con práctica constante, puedes lograrlo. Así que mantén la barbilla en alto.
Recuerde, tanto los índices agrupados como los no agrupados son para aumentar las consultas. Conocer las diferencias clave, los escenarios de uso y las herramientas lo ayudará en su búsqueda para codificar consultas de alto rendimiento.
Espero que esta publicación responda a sus preguntas más urgentes sobre los índices agrupados y no agrupados. ¿Tienes algo más que agregar para nuestros lectores? La sección Comentarios está abierta.
Y si encuentra esta publicación esclarecedora, compártala en sus plataformas de redes sociales favoritas.
Puede encontrar más información sobre los índices y el rendimiento de las consultas en los siguientes artículos:
- 22 ingeniosos ejemplos de índice SQL para acelerar sus consultas
- Optimización de consultas SQL:5 datos básicos para impulsar sus consultas



